Иногда, когда вы выполняете модульные или интеграционные тесты во время разработки кода, вы должны быть в состоянии сделать что-то экстремальное, например, многократное искажение тестовой базы данных или двух, каждый раз впоследствии восстанавливая ее в исходное состояние перед запуском следующего теста. Часто, особенно в интеграционных тестах, когда вы тестируете процессы, вам нужно запустить процесс «установки», чтобы установить известное состояние данных базы данных, а затем запустить процесс, проверить, что конечное состояние данных соответствует тому, которое согласно вашим бизнес-правилам должно быть и, наконец, запустить процесс «демонтажа», чтобы восстановить вещи такими, какими они были в начале.
Разница с модульным тестом заключается в том, что разработчик постоянно запускает тест и обижается на него, если процесс настройки или демонтажа занимает больше времени, чем то, что в моей неумелой юности мы бы назвали «временем, которое нужно, чтобы бросить сигарету». Интеграционные тесты, как правило, выполняются более достойно после сборки, поэтому время затрачивается меньше. В данном случае нам нужен модульный тест, хотя его можно адаптировать как интеграционный тест, если тестируемый компонент становится частью процесса.
Модульное тестирование выполняется для каждой подпрограммы изолированно, чтобы гарантировать, что она возвращает предсказуемый результат для каждого конкретного набора входных данных, которые используются. Они необходимы для всех модулей, таких как процедуры, функции, представления и правила.
Тестирование баз данных: что требуется?
Некоторый код мы можем протестировать только путем внесения изменений в базу данных, либо изменений схемы, либо изменений данных, либо обоих. Разработчики захотят запускать тесты повторно, так как они улучшают код. В таких случаях действительно нужна одноразовая база данных. Вы хотите иметь возможность создать известную версию базы данных на своем сервере разработки, возможно, снабженную стандартными тестовыми данными, а затем запустить модульный тест, который выполняет ваш код и проверяет, что результат в точности соответствует ожидаемому. После завершения теста мы немедленно запускаем процесс разрыва, который возвращает базу данных теста в исходное состояние.
Процессы настройки и демонтажа должны выполняться быстро, чтобы быть полезными для модульного тестирования. Скорость особенно важна, если, например, нам нужно проверить, что один и тот же код дает правильный результат на ряде разных версий базы данных, а это означает, что нам нужно пересоздать каждую отдельную версию и запустить тест на ней. Если, например, вам нужно запустить тесты на нескольких вариантах одной и той же версии выпуска (например, программы расчета заработной платы для различных законодательных областей), то вам нужен способ сделать это быстро.
Я столкнулся именно с этой проблемой при разработке подпрограммы, которая проверяла объекты, которые были добавлены, изменены или удалены в наборе баз данных. Я хотел быстро настроить требуемую версию тестовой базы данных, а затем запустить модульный тест для своей процедуры.
В отличие от регрессионных или интеграционных тестов, этот вид разработки не зависит от данных в базе данных, только с изменениями в метаданных, записанными в системной таблице sys.objects. Сначала модульному тесту необходимо внести серию изменений схемы в тестовую базу данных, записав в #WhatHasHappened таблицу каждое изменение, объект и действие. Например, если тест удаляет FOREIGN KEY ограничение, он запишет две записи в #WhatHasHappenedодин идентифицирует ограничение с действием «сброшен», а другой идентифицирует родительскую таблицу с действием «изменен». Затем модульный тест запускает подпрограмму, которая в данном случае представляет собой SQL, который сравнивает данные в системных таблицах «используемой» тестовой базы данных с данными в исходной базе данных, чтобы вернуть набор результатов, содержащий список изменений объекта. , Тест сравнивает этот набор результатов с содержимым, #WhatHasHappened чтобы убедиться, что они идентичны. Если они есть, тест проходит. Связав каждый тест с отчетом в #WhatHasHappened таблице, легче расширить диапазон тестов и убедиться, что все модификации представлены правильно.
Одноразовая база данных: «Настроить» и «Разорвать»
Существует множество способов настройки и снятия (сброса) базы данных. Если вам просто нужна пустая база данных (что в данном случае хорошо) или только скромный объем тестовых данных, то, возможно, вы можете использовать DACPAC или запустить автоматическую сборку и заполнение с использованием SQL Change Automation и JSON.
Для полноценной базы данных вы можете каждый раз восстанавливать из резервной копии или отсоединять «использованную» базу данных, а затем заново подключать исходную базу данных. Скорость этих методов будет зависеть от размера базы данных и не будет жизнеспособной для модульных тестов после определенной точки.
Как друг Redgate, мне посчастливилось использовать SQL Clone. Почему так везет? Создание или обновление клона, скажем, AdventureWorks, из существующего изображения занимает менее десяти секунд. Десять помехи на ваших серверах легко, сохраняя тестовые базы данных и утилиты только в виде образов и клонируя их только тогда, когда они вам нужны, и вы можете чувствовать себя беспрепятственно при их тестировании на уничтожение.
Для типа модульного теста, который я описывал, каждый раз, когда вы хотите запустить тест, вам нужен свежий клон, созданный из текущего образа. Если клон уже существует, вы удаляете его в предположении, что он уже был очищен вашим тестовым кодом. Затем вы создаете новый. Если вам нужно изменить все клоны стандартным способом или изменить отдельные клоны, перед запуском тестов вы можете запустить сценарии как часть создания образа или клона.
В листинге 1 показан код, который создаст новый клон, снесет и заменит любой существующий клон. Он проверит, есть ли у вас изображение для базы данных. Если нет, то это создает его. Если вам нужно новое изображение, просто удалите существующее, используя консоль SQL Clone, прежде чем запускать сценарий. Если изображение уже существует, скрипт проверяет, есть ли у вас клон. Если он есть, он удаляет его и создает новый, готовый к следующему тестовому запуску. На диаграмме исходная база данных находится в том же экземпляре, что и клон.
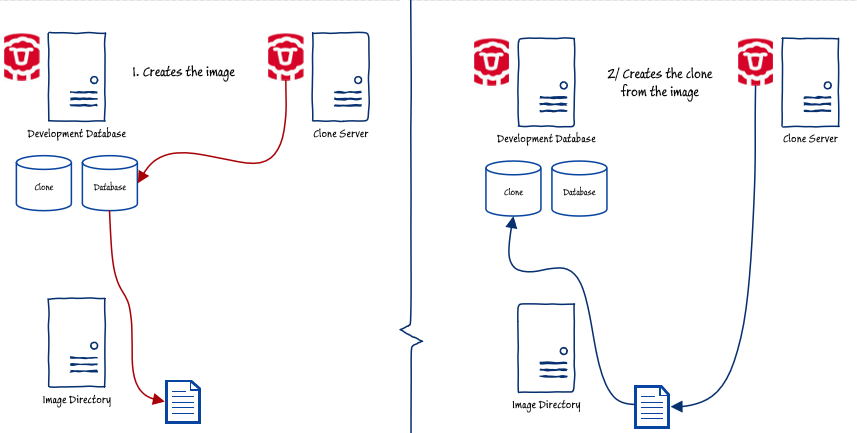
В этом коде я сохранил данные конфигурации со сценарием, чтобы упростить задачу. Можно использовать код из предыдущих статей о клонировании SQL с соответствующим файлом конфигурации, но он будет излишним для загруженного сеанса разработки, особенно если вам вряд ли понадобится модификация образа или клона и вам никогда не потребуется сохранять код от клона до демонтажа. Здесь все в одном легко модифицируемом скрипте.
$database = 'MyDatabase' #the name of the database we are cloning e,g, AdventureWorks
$Data = @{
"Database" = '$database';
#where we have SQL Compare installed. Yours could be a different version
"Original" = @{
#We will clone from this database. This is the original, maybe a build stocked with data
'Server' = 'MyUsefulServer'; #The SQL Server instance
'Instance' = ''; #The SQL Server instance
'Database' = "$($Database)"; #The name of the database
'username' = 'PhilFactor'; #leave blank if windows authentication
}
"Image" = @{
# this has the details of the image that each clone uses as its base
#we use these details to create an image of what we built
'Name' = "$($database)image"; #This is the name we want to call the image
#'Modifications' = @("$($env:USERPROFILE)\Clone\imageModificationScript.sql")
'ServerURL' = 'http://MyCloneServer:14145'; #the HTTP address of the Clone Server
'ImageDirectoryURL' = '\\MyFileStore\Clone'; #the URL of the image directory
#'CloneTemplates' = @{
# 'DatabaseProperties' = "$($env:USERPROFILE)\Clone\CloneModificationScript.sql"
#}
'Clone' =
@{
"NetName" = "MyDevServer"; #the network name of the server
"Database" = "$($database)Test"; #the name of the Database
'username' = 'PhilFactor'; #leave this blank for windows security
} #
}
}
$TheError = ''
Connect-SqlClone -ServerUrl $Data.Image.ServerURL # make a connectiuon to SQL Clone
<# If the image already exists, then use it, else create the image. If you need to
change the original database, then delete the image before running the script #>
# first test to see if the image is there
$Image = Get-SqlCloneImage | where Name -eq $Data.Image.Name
if ($image -eq $null) # tut. No image
{
$AllArgs = @{
'Name' = $Data.Image.Name; #what is specified for its name in the data file
'SqlServerInstance' = (Get-SqlCloneSqlServerInstance | Where server -eq $data.Original.Server);
# we fetch the SqlServerInstanceResource for passing to the New-SqlCloneImage cmdlets.
'DatabaseName' = "$($data.Original.Database)"; #the name of the database
'Destination' = (Get-SqlCloneImageLocation |
Where Path -eq $data.Image.ImageDirectoryURL) #where the image is stored
}
if ($Data.Image.Modifications -ne $null)
{
$ImageChangeScript = @();
$Data.Image.Modifications.GetEnumerator() | foreach{
$ImageChangeScript += New-SqlCloneSqlScript -Path $_
}
$AllArgs += @{ 'Modifications' = $ImageChangeScript }
}
# Starts creating a new image from either a live database or backup.
$ImageOperation = New-SqlCloneImage `
@AllArgs -ErrorAction silentlyContinue -ErrorVariable +Errors `
# gets the ImageResource which then enables us to wait until the process is finished
write-verbose "Creating the image called $(
$Data.Image.Name) from $(
$data.Original.Database) on $(
$data.Original.Server)"
Wait-SqlCloneOperation -Operation $ImageOperation
}
<# does the clone we want exist? #>
$clone = Get-SqlClone `
-ErrorAction silentlyContinue `
-Name "$($Data.Image.clone.Database)" `
-Location (Get-SqlCloneSqlServerInstance |
Where server -ieq $Data.Image.clone.NetName)
<# If the clone does exist then zap it #>
if (($clone) -ne $null) #one already exists!
{
write-warning "Removing Clone $(
$Data.Image.clone.Database) that already existed on $(
$Data.Image.clone.NetName)"
Remove-SqlClone $clone | Wait-SqlCloneOperation
}
<# Now Create the clone#>
$AllArgs = @{
'Name' = $Data.Image.clone.Database;
'Location' = (Get-SqlCloneSqlServerInstance |
Where server -ieq $Data.Image.clone.NetName)
}
if ($Data.Image.clone.Modifications -ne $null)
{
$AllArgs += @{ 'template' = (
Get-SqlCloneTemplate `
-Image $data.image.Name `
-Name $Data.Image.clone.Modifications) }
}
Get-SqlCloneImage -Name $data.Image.Name |
New-SqlClone @Allargs |
Wait-SqlCloneOperation
"Master, I have created your clone $(
$Data.Image.clone.Database) on $($Data.Image.clone.NetName)" Листинг 1: CloneForUnitTesting.ps1
Практическое использование для одноразовой базы данных
Теперь, когда у нас есть доступная база данных, как бы мы ее использовали? Здесь я собираюсь показать, как использовать его для многократного запуска модульного теста в базе данных, когда тест по необходимости каждый раз портит базу данных. В этом случае мы тестируем запрос, который находит все различия между двумя базами данных: одна называется MyTestDatabase: клон, а другая MyReferenceDatabase— исходная база данных, из которой мы берем изображение. В начале теста они идентичны.
Я начал разрабатывать этот код во время написания Отчетов о состоянии клонов во время разработки баз данных, где я использовал его для проверки активности целого ряда клонов разработки. Я объяснил, как работает код в посте блога Simple-Talk, поэтому я не буду повторять эти детали здесь. Версия кода, которую я показываю в блоге для общего использования, сравнивает системные данные в тестовой базе данных в реальном времени с копией этих данных из исходной базы данных, хранящейся в файле JSON. Он также аккуратно упаковывает все в универсальную табличную функцию. с конечным пользователем в виду.
Во время разработки лучше использовать CTE, как показано в листинге 2, но «внутренности» процедуры в каждом случае одинаковы. Я использовал запрос CTE во время разработки, потому что его гораздо проще отлаживать, чем функцию.
WITH
Cloned
AS (SELECT --the data you need from the test database's system views
Coalesce(--if it is a parent, then add the schema name
CASE WHEN parent_object_id=0 THEN Object_Schema_Name(object_id)+'.'
......ELSE Object_Name(parent_Object_id)+'.' END
......+ name,name --otherwise add the parent object name
......) AS [name], object_id, modify_date, parent_object_id
FROM MyTestDatabase.sys.objects
WHERE is_ms_shipped = 0),
Original
AS (SELECT --the data you need from the original database's system views
Coalesce(--if it is a parent, then add the schema name
... CASE WHEN parent_object_id=0 THEN Object_Schema_Name(object_id)+'.'
... ELSE Object_Name(parent_Object_id)+'.' END
... + name,name --otherwise add the parent object name
... ) AS [name], object_id, modify_date, parent_object_id
FROM MyReferenceDatabase.sys.objects
WHERE is_ms_shipped = 0)
SELECT Cloned.name, 'Added' AS action --all added base objects
FROM Cloned --get the modified
LEFT OUTER JOIN Original-- check if they are in the original
ON Cloned.object_id = Original.object_id
WHERE Original.object_id IS NULL AND cloned.parent_Object_id =0
--if they are base objects and they aren't in the original
UNION ALL --OK but what if just child objects were added ...
SELECT Clonedchildren.name, 'Added' -- to existing objects?
FROM Original-- check if they are in both the original
INNER join Cloned -- and also they are in the clone
ON Cloned.name = Original.name --not renamed
... AND Cloned.object_id = Original.object_id
......--for ALL surviving objects
...inner JOIN cloned Clonedchildren--get all the chil objects
...ON Clonedchildren.parent_object_id =cloned.object_id
...LEFT OUTER JOIN -- and compare what child objects there were
Original OriginalChildren
...ON Originalchildren.object_id=ClonedChildren.object_id
...WHERE OriginalChildren.object_id IS NULL
UNION ALL
--all deleted objects but not their children
SELECT Original.name, 'deleted'
FROM Original --all the objects in the original
LEFT OUTER JOIN Cloned --all the objects in the clone
ON Cloned.name = Original.name
... AND Cloned.object_id = Original.object_id
WHERE Cloned.object_id IS NULL AND original.parent_Object_id =0
--the original base objects that aren't in the clone
UNION ALL
--all child objects that were deleted where parents survive
SELECT children.name, 'deleted'
FROM Original
INNER join Cloned
ON Cloned.name = Original.name
... AND Cloned.object_id = Original.object_id
......--for ALL surviving objects
...inner JOIN Original children
...ON children.parent_object_id =original.object_id
...LEFT OUTER JOIN
cloned ClonedChildren ON children.object_id=ClonedChildren.object_id
...WHERE ClonedChildren.object_id IS NULL
UNION ALL
SELECT Original.name,
CASE WHEN Cloned.name <> Original.name THEN 'renamed'
WHEN Cloned.modify_date <> Original.modify_date THEN 'modified' ELSE '' END
FROM Original
INNER JOIN Cloned
ON Cloned.object_id = Original.object_id
WHERE Cloned.modify_date <> Original.modify_date
OR Cloned.name <> Original.name
ORDER BY name;Листинг 2: DifferencesBetweenObjects.sql
Итак, что нам нужно сделать, чтобы проверить этот код? Что ж, чтобы увидеть, работает ли он, давайте внесем несколько изменений в тестовую базу данных. (Я использую AdventureWorks здесь).
--DROP existing tables
DROP TABLE [dbo].[DatabaseLog]
DROP table [dbo].[AWBuildVersion]
--ADD tables
CREATE TABLE Dbo.Deleteme (theKey INT IDENTITY PRIMARY KEY)
--Add a Procedure
go
CREATE PROCEDURE [dbo].[LittleStoredProcedure] AS
BEGIN
SET NOCOUNT on
SELECT Count(*) FROM sys.indexes AS I
END
GO
Create FUNCTION [dbo].[MyInlineTableFunction]
( @param1 INT, @param2 CHAR(5) )
RETURNS TABLE
AS
RETURN
(
SELECT @param1 AS c1, @param2 AS c2
)
--add a scalar function
go
CREATE function [dbo].[LeftTrim] (@String varchar(max)) returns varchar(max)
as
begin
...return stuff(' '+@string,1,Patindex('%[^'+CHAR(0)+'- '+CHAR(160)+']%',' '+@string+'!'
... COLLATE SQL_Latin1_General_CP850_Bin)-1,'')
end
GO
--drop child objects
--drop a primary key constraint
ALTER TABLE Production.TransactionHistoryArchive
DROP CONSTRAINT PK_TransactionHistoryArchive_TransactionID
--drop a default constraint
ALTER TABLE [HumanResources].[Department]
DROP CONSTRAINT [DF_Department_ModifiedDate]
--drop a foreign key constraint
ALTER TABLE [HumanResources].[EmployeePayHistory]
DROP CONSTRAINT [FK_EmployeePayHistory_Employee_BusinessEntityID]
--drop a primary key constraint
ALTER TABLE [HumanResources].[EmployeePayHistory]
DROP CONSTRAINT [PK_EmployeePayHistory_BusinessEntityID_RateChangeDate]
--drop a check constraint
ALTER TABLE [Person].[person]
DROP CONSTRAINT [CK_Person_EmailPromotion]
--drop a trigger
--IF OBJECT_ID ('sales.uSalesOrderHeader', 'TR') IS NOT NULL
DROP trigger sales.uSalesOrderHeader
--drop a unique constraint
ALTER TABLE [production].[document]
DROP CONSTRAINT UQ__Document__F73921F744672977
--add a default constraint
ALTER TABLE [Person].[EmailAddress]
ADD CONSTRAINT NoAddress
DEFAULT '--' FOR EmailAddress ;
--add a default constraint
ALTER TABLE [Person].[CountryRegion] WITH NOCHECK
ADD CONSTRAINT NoName CHECK (Len(name) > 1)Листинг 3: Создание ряда различных изменений схемы
Затем вы должны выполнить запрос в листинге 2, и результат будет следующим:
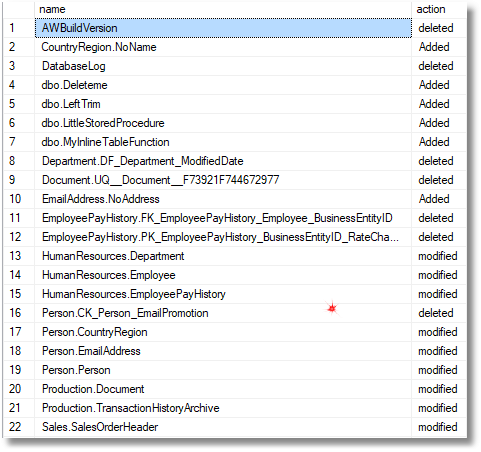
Хорошо, пока, но я могу вам сказать, что правильное тестирование такого рода запросов не совсем простое. В листинге 3 показан лишь небольшой пример тех изменений, которые мы хотели бы внести, чтобы проверить, что листинг 2 правильно отлавливает все возможные типы изменений. Есть много тестовых прогонов, прежде чем вы сможете почувствовать уверенность в том, что рутина работает, и для каждого из них вам нужно проверить, что фактический результат соответствует ожидаемому результату. Это то, что вам нужно автоматизировать, потому что проверка результатов на глаз слишком подвержена ошибкам.
Хитрость в автоматизации тестового прогона заключается в создании временной таблицы при выполнении изменений тестовой базы данных. После каждой модификации есть некоторый дополнительный код, который вставляет во временную таблицу все результаты, о которых вы ожидаете сообщить в тестовом запросе, для каждого оператора DDL. Сохраняя каждый тест вместе с ожидаемым результатом, вы, вероятно, сможете синхронизировать все, чтобы у каждого теста была одна соответствующая запись о том, что должно произойти.
--drop a default constraint
ALTER TABLE HumanResources.Department DROP CONSTRAINT DF_Department_ModifiedDate;
INSERT INTO #WhatHasHappened (object, action)
SELECT N'Department.DF_Department_ModifiedDate', 'deleted';
--drop a foreign key constraint
ALTER TABLE HumanResources.EmployeePayHistory
DROP CONSTRAINT FK_EmployeePayHistory_Employee_BusinessEntityID;
INSERT INTO #WhatHasHappened (object, action)
Values
(N'EmployeePayHistory.FK_EmployeePayHistory_Employee_BusinessEntityID',
'deleted'),-- When a FK constraint is changed, both ends are modified
(N'HumanResources.Employee', 'modified');
ALTER TABLE HumanResources.EmployeePayHistory
DROP CONSTRAINT PK_EmployeePayHistory_BusinessEntityID_RateChangeDate;
INSERT INTO #WhatHasHappened (object, action)
VALUES
(N'EmployeePayHistory.PK_EmployeePayHistory_BusinessEntityID_RateChangeDate',
'deleted'),
(N'HumanResources.EmployeePayHistory', 'modified');Листинг 4: Сохранение ожидаемого результата каждого изменения DDL в #WhatHasHappened
Затем вы просто сравниваете результат выполнения Листинга 2 с тем, что, как вы ожидаете, он будет храниться #WhatHasHappened, сравнивая две таблицы. Я использую EXCEPT для этого.
--CHECK the differences BETWEEN the two tables. It should be none
SELECT object COLLATE DATABASE_DEFAULT, action COLLATE DATABASE_DEFAULT
AS 'changes that were reported but not announced'
FROM @differences
EXCEPT
SELECT object COLLATE DATABASE_DEFAULT, action COLLATE DATABASE_DEFAULT
FROM #WhatHasHappened
SELECT object COLLATE DATABASE_DEFAULT, action COLLATE DATABASE_DEFAULT
AS 'changes that were announced but not reported'
FROM #WhatHasHappened
EXCEPT
SELECT object COLLATE DATABASE_DEFAULT, action COLLATE DATABASE_DEFAULT
FROM @differencesЛистинг 5: Проверка результата соответствует ожиданиям
Надеюсь, это будет пустой результат. Вы можете вызвать ошибку IF EXISTS, но я обычно не беспокоюсь. Результат можно использовать в любой системе, которую вы используете для своих сборок.
Весь процесс может быть написан в PowerShell. Единственное предостережение, которое у меня есть, заключается в том, что после того, как вы уничтожили существующий клон и заменили его новым, он платит за обновление окна запроса в SSMS; в противном случае соединение будет слегка запутанным из-за происходящего. Если вы установили соединение заново после процесса клонирования, тогда это нормально.
Я разместил весь код этого проекта на GitHub с полным исходным кодом.
Выводы
Если у вас есть SQL Clone, он может подкрасться к вам и предложить все виды использования, которые не сразу очевидны. Это потому, что это вызывает культурные изменения. Базы данных разработки перестают быть драгоценными и хрупкими вещами, которые необходимо сохранить любой ценой. Вместо этого вы получаете гораздо больше свободы для хранения баз данных в различных формах и версиях для различных целей, возникающих в процессе разработки баз данных. Теперь создание новой копии рабочей базы данных происходит так быстро, что едва ли есть время бросить сигарету.