В своем первом посте я показал, как можно быстро развернуть кластер с поддержкой Drill в облаке Azure, используя шаблон MapR, доступный в Azure Marketplace. В моем следующем посте я показал вам, как вы можете заставить этот кластер с поддержкой Drill запрашивать учетную запись хранилища Azure, а также базу данных SQL Azure . В этой статье я хочу сосредоточиться на использовании этого кластера в качестве источника данных с Power BI , инструментом обнаружения данных, который популярен среди пользователей технологий Microsoft.
Набор данных
Для начала я загружу набор данных в свой кластер Drill. Я сделаю это, сначала открыв сеанс SSH на узле 0 моего кластера, используя имя пользователя SysAdmin (по умолчанию mapradmin ) и пароль, созданный при развертывании кластера. После входа в систему я загружаю Список банков с ошибками , управляемый Федеральной корпорацией страхования депозитов, в локальную файловую систему и помещаю файл CSV в файловую систему кластера:
|
1
2
3
4
5
6
7
|
wget <a href="https://www.fdic.gov/bank/individual/failed/banklist.csv">http://www.fdic.gov/bank/individual/failed/banklist.csv</a>sudo hadoop fs -mkdir /fdic/sudo hadoop fs -put banklist.csv /fdic/banklist.csvrm banklist.csv |
Когда файл загружен в файловую систему MapR, теперь к нему можно получить доступ в Drill с помощью плагина dfs. В этом запросе я сосредоточусь на банках, закрытых с 2008 года:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
SELECTBank,City,State,AcquiringBank,CloseDateFROM (SELECTcolumns[0] as Bank,columns[1] as City,columns[2] as State,columns[4] as AcquiringBank,TO_DATE(columns[5], 'd-MMM-yy') as CloseDateFROM dfs.`fdic/banklist.csv`WHERE columns[0] <> 'Bank Name') aWHERE DATE_PART('year', CloseDate) >= 2008; |
& NBSP
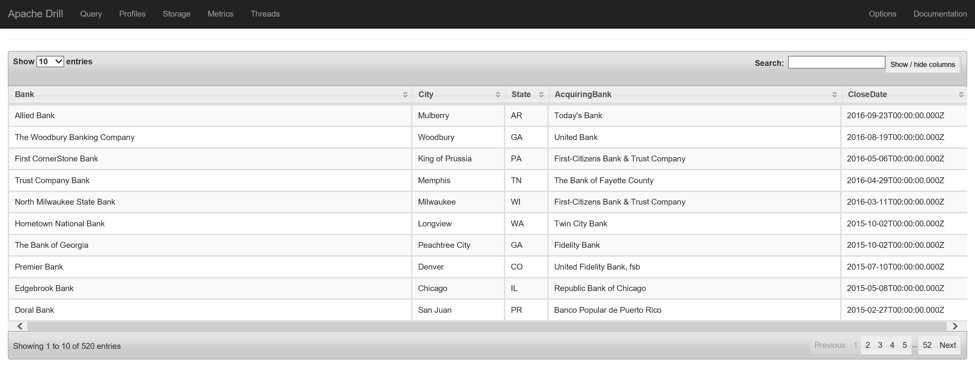
ПРИМЕЧАНИЕ. Рассмотрите возможность развертывания вашего запроса в виде представления в Drill . Это позволит некоторым инструментам BI легче получать информацию о схеме, например типы данных столбцов.
ПРИМЕЧАНИЕ Ваш плагин хранения может быть настроен для чтения строки заголовка из CSV (и других типов текстовых файлов). Это делается путем добавления свойства extractHeader к определению типа файла плагина хранения, как показано здесь . Эта конфигурация более производительна и позволит вам напрямую ссылаться на имена столбцов, не используя идентификаторы columns [n] . Тем не менее, для этого требуется, чтобы файлы этого типа, связанные с плагином хранилища, согласованно использовали строки заголовков.
Соединение с Power BI
Теперь, когда данные доступны через Drill, я могу сосредоточиться на подключении к ним через Power BI. Первое, что мне нужно сделать, это убедиться, что у меня установлена последняя версия инструмента Power BI Desktop, доступная бесплатно здесь .
Далее мне нужно определить, установлена ли на рабочем столе 32-разрядная или 64-разрядная версия инструмента Power BI Desktop. Для этого я запускаю Power BI, закрываю заставку и в меню « Файл» нажимаю « Справка», а затем « О программе» . В результате диалоговое окно идентифицирует разрядность приложения.
Теперь, когда известна разрядность Power BI, я могу загрузить соответствующий драйвер ODBC для Drill , сопоставляя разрядность драйвера с разрядностью приложения. (Если вы просматриваете инструкции, прилагаемые к драйверу ODBC, вам не нужно настраивать драйвер за пределами его базовой установки, поддерживаемой MSI.)
Теперь, когда все готово, я запускаю Power BI и на заставке выбираю « Получить данные» . В появившемся диалоговом окне « Получение данных » я выбираю « Другое» в левой навигационной панели, а затем в появившемся списке « ODBC» .
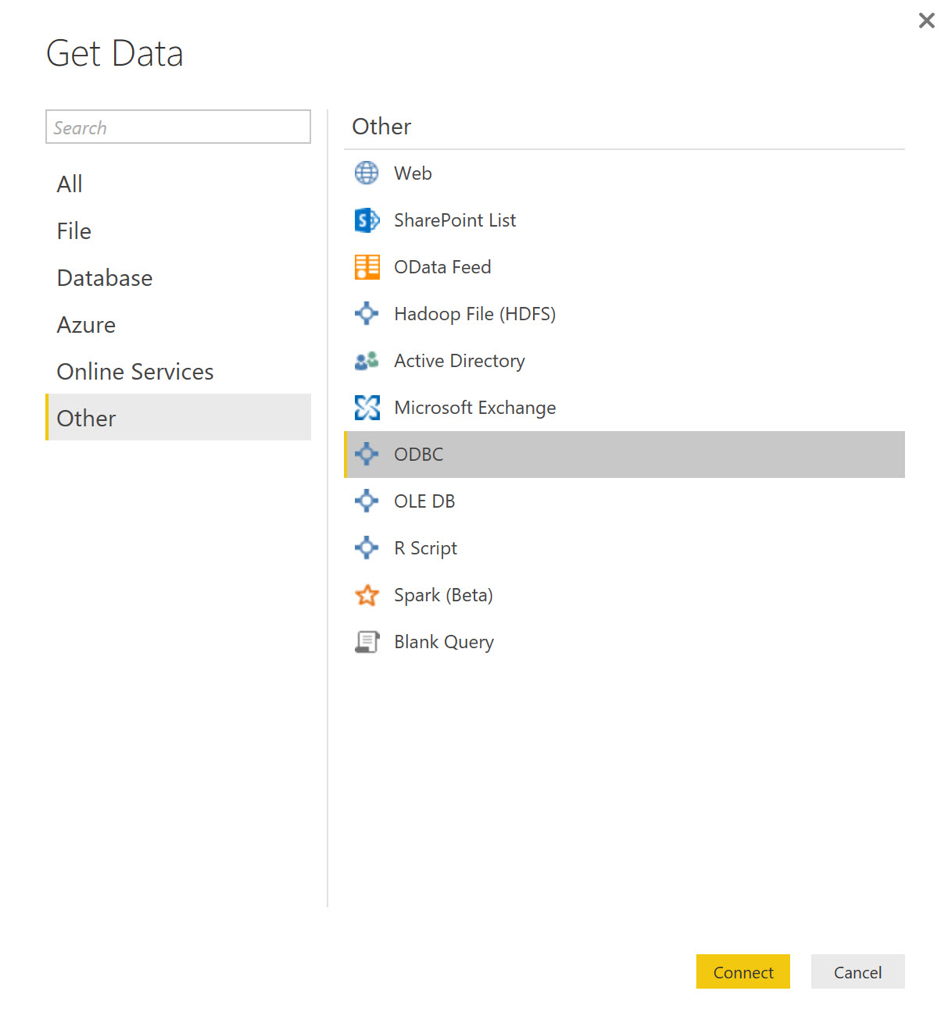
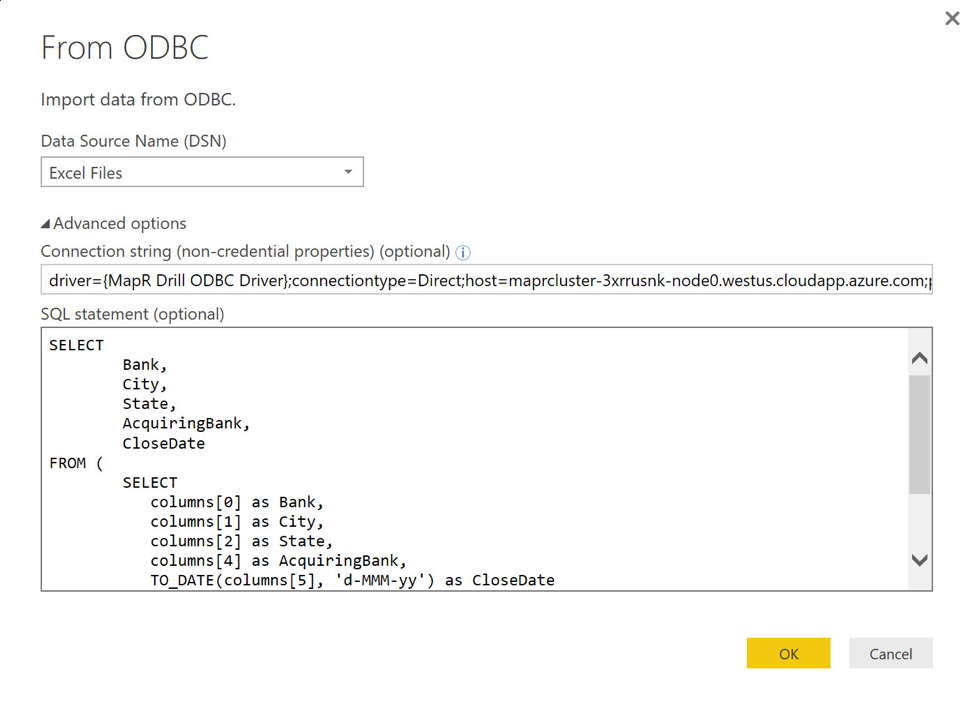
Нажатие Далее приведет меня в диалог From ODBC . Здесь я нажимаю на элемент « Дополнительные параметры» , игнорируя раскрывающийся список « Имя источника данных» (DSN) , и ввожу строку подключения с соответствующей заменой для параметра хоста:
driver = {MapR Drill ODBC Driver}; тип соединения = прямой; хост = maprcluster-3xrrusnk-node0.westus.cloudapp.azure.com; порт = 31010; тип аутентификации = нет аутентификации
Обратите внимание, что в строке подключения используется тип прямого подключения, указывающий, что приложение будет напрямую взаимодействовать с одним из узлов в кластере (как определено параметром хоста), а не со службой ZooKeeper. ZooKeeper используется в кластере, но не доступен извне, учитывая изменения в группе безопасности сети, сделанные во время моего более раннего развертывания. Даже если ZooKeeper был выставлен, он отслеживает узлы кластера, используя их внутренние имена, так что любое приложение вне виртуальной сети, содержащее кластер, не сможет использовать информацию в ZooKeeper для формирования соединения. Единственный вариант, который работает здесь, это прямой тип соединения.
ПРИМЕЧАНИЕ. Дополнительные сведения о сетевом подключении к развернутому Azure кластеру Drill см. В этом блоге .
Также обратите внимание на то, что опция No Authentication установлена, поскольку среда Drill, развернутая с шаблоном, по умолчанию использует этот тип аутентификации. Если вы измените тип аутентификации, используемый кластером, вам нужно будет выбрать другой параметр для этого параметра.
Возвращаясь к диалоговому окну From ODBC , я ввожу оператор SELECT сверху в текстовое поле оператора SQL (необязательно) . При вводе оператора SQL обязательно пропустите точку с запятой, использованную в предыдущем примере.
Нажатие ОК приводит меня к Доступу к источнику данных с помощью диалогового окна драйвера ODBC , где меня просят предоставить информацию о безопасности. Поскольку я использую тип аутентификации « Без аутентификации», я просто выбираю « По умолчанию» или «Пользовательский» в левой навигационной панели и не вводю дополнительную информацию в дополнительное текстовое поле.
Нажав на кнопку Connect, вы попадете на страницу предварительного просмотра данных. Если мне нужно сформировать данные дальше, используя возможности Power BI, я могу нажать кнопку « Изменить» , но, поскольку данные уже находятся в хорошем состоянии, я просто нажимаю « Загрузить», чтобы продолжить.
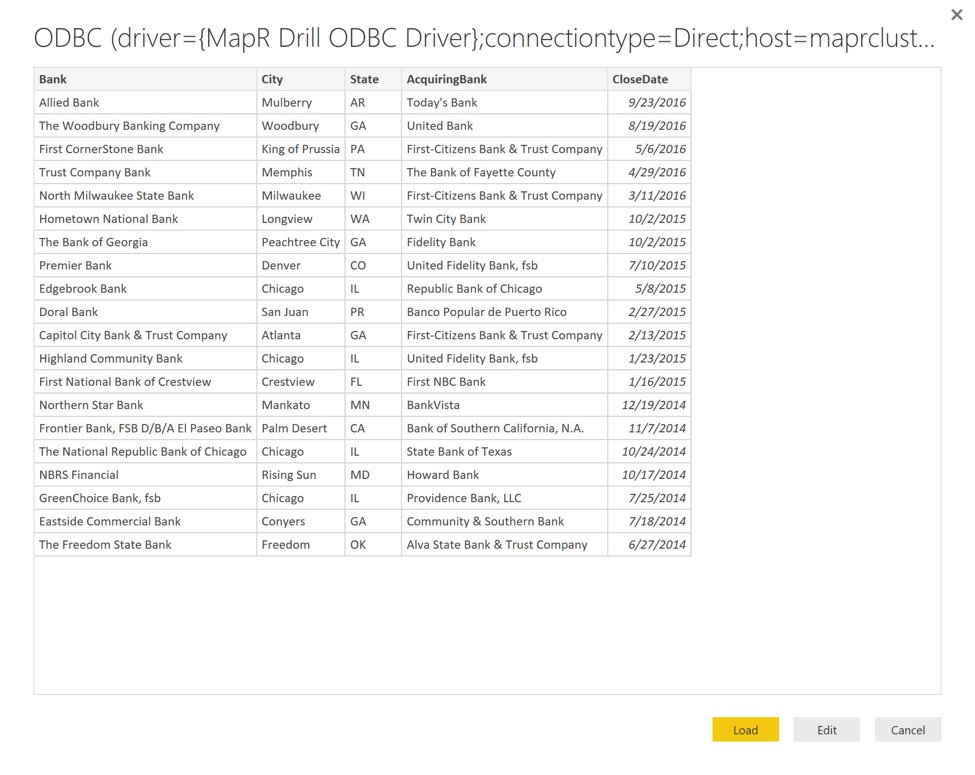
После загрузки данных в настольное приложение Power BI я могу приступить к созданию интерактивного отчета. Если вы новичок в Power BI и хотели бы узнать больше о том, как создавать отчеты, ознакомьтесь с видео и учебными пособиями, которые можно найти здесь .
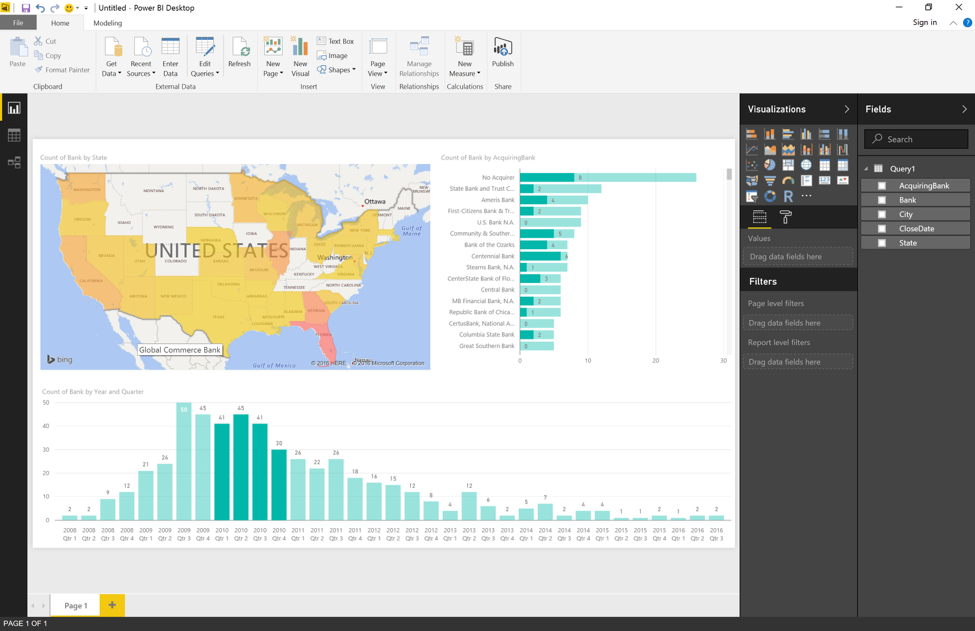
Несколько заключительных мыслей
Я очень люблю Power BI. Это отличный инструмент для формирования данных и моделирования, а возможности, которые вы получаете — даже с бесплатной версией — невероятны. Тем не менее, у меня есть два предложения для команды Power BI по улучшению интерактивности с помощью Drill.
Во-первых, я хотел бы, чтобы приложение обеспечивало встроенную поддержку драйвера ODBC для Drill. Это позволило бы пользователям подключаться к кластеру Drill, иметь инструмент Power BI для получения информации о схеме и позволять пользователям интерактивно создавать наборы данных без необходимости писать какие-либо операторы SQL.
Во-вторых, я хотел бы, чтобы приложение обеспечивало поддержку живых запросов к Drill. Режим по умолчанию для Power BI — извлечение данных в удивительно надежный кэш в памяти, что я и сделал в этой демонстрации. Но с некоторыми источниками данных, способными к быстрому ответу на запросы, такими как Spark, Power BI предоставляет возможность выполнять оперативные запросы к серверной части. Это позволяет немедленно видеть обновления для этого внутреннего сервера без необходимости планирования автоматического обновления кэша. Drill способен поддержать это, и поэтому я хотел бы, чтобы эта опция была доступна в Power BI.
Хорошая новость заключается в том, что команда Power BI поддерживает сайт UserVoice, где можно отправлять предложения по улучшению и голосовать за них. Информация, собранная на этом сайте, напрямую влияет на приоритеты разработки для команды Power BI, поэтому, если вы хотите, чтобы эти изменения были реализованы в продукте Power BI, проголосуйте за них здесь .
| Ссылка: | Подключение к Apache Drill с Power BI (часть 3) от нашего партнера по JCG Брайана Смита в блоге Mapr . |