В своем последнем посте я развернул кластер MapR в облаке Azure, используя шаблон, доступный через Azure Marketplace. Моя цель состояла в том, чтобы как можно быстрее запустить кластер с поддержкой Drill и запустить его в Azure.
Мой акцент на Azure указывает на то, что я, вероятно, использую облако Microsoft для более широкого спектра действий, чем просто запуск этого одного кластера. Поэтому, хотя я буду загружать большую часть данных, которые намерен использовать с Drill, в собственную файловую систему кластера MapR, вполне вероятно, что я уже загрузил некоторые данные в другие ресурсы Azure и захочу также запросить их. Для этого все, что мне нужно, это загрузить соответствующие драйверы в среду Drill и настроить подключаемые модули хранения в кластере для каждого ресурса. Это тема этого блога.
Моя тестовая среда
Прежде чем переходить к техническим деталям, важно понять среду Azure, которую я настроил для этой демонстрации. В последнем посте я представил довольно детальную разбивку ресурсов, которые составляют мой кластер MapR с тремя узлами. Здесь я просто буду ссылаться на это как на единый ресурс, чтобы сосредоточиться на других ресурсах Azure, в которые я буду его интегрировать.
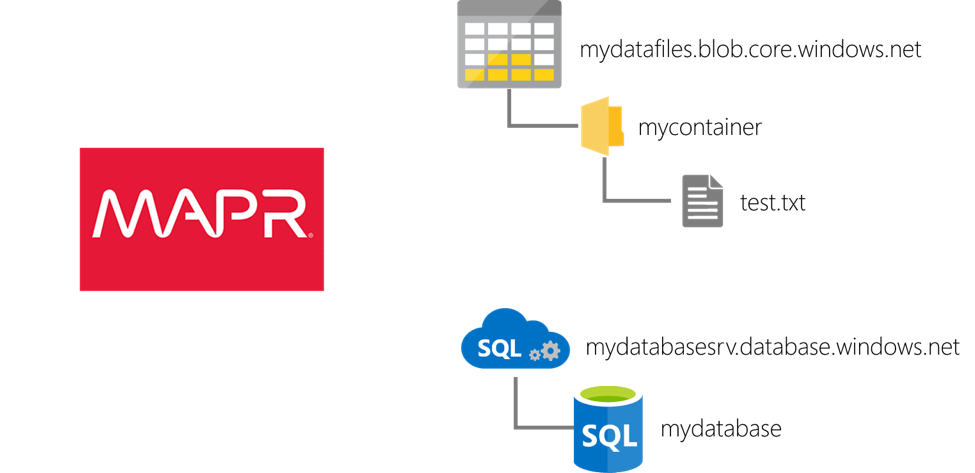
Первый актив, к которому я подключусь, — это учетная запись хранилища Azure . Учетная запись хранилища Azure — это логический контейнер для хранения различных активов данных. Для этой демонстрации я буду хранить файлы в блочной части учетной записи. Блочные BLOB-объекты — это самый дешевый вариант хранения в хранилище Azure. Они идеально подходят для чтения целых файлов (в отличие от случайного чтения файла, который поддерживается типом блоба страницы).
Учетные записи хранилища Azure идентифицируются уникальным именем: mydatafiles в этой среде. Поэтому часть блочного блога учетной записи адресуется как mydatafiles.blob.core.windows.net . BLOB-объекты размещаются в контейнерах: mycontainer в этой среде. И в этот контейнер я загрузил один файл с разделителями табуляции с именем test.txt. (Если вы создаете собственную среду, вашей учетной записи хранения потребуется другое имя, но вы можете использовать те же имена контейнера и файла.)
Второй ресурс, к которому я буду подключаться, — это база данных SQL Azure . База данных Azure SQL — это реляционная база данных Microsoft SQL Server, работающая в облаке таким образом, что устраняет большинство административных накладных расходов типичной базы данных. Он также имеет много других преимуществ, что делает его очень популярным выбором для структурированного хранения данных в облаке Azure.
Моя база данных SQL Azure называется mydatabase . Я не создавал никаких объектов внутри него, но просто сделаю запрос к некоторым ранее существующим таблицам в его каталоге, чтобы продемонстрировать возможность подключения. Эта база данных развернута в контексте логического сервера, который предоставляет базе данных адрес: mydatabasesrv.database.windows.net в моей среде. Я оставил брандмауэр на сервере с настройками по умолчанию, чтобы единственным трафиком, на который будет реагировать база данных, был трафик, исходящий из облака Azure. (Как и раньше, если вы создаете собственную среду, вашему серверу потребуется другое имя, но вы можете использовать то же имя базы данных.)
Подключение к хранилищу Azure
После установки тестовой среды я сначала подключу Drill к моей учетной записи хранилища Azure. Для этого я сначала введу SSH в узел 0 моего кластера, используя имя пользователя SysAdmin (по умолчанию mapradmin ) и пароль (или сертификат), созданные во время развертывания кластера.
ПРИМЕЧАНИЕ. Для этой последовательности шагов важно выполнять эти операции с узла 0.
После входа в систему мне нужно загрузить два драйвера, то есть драйверы hadoop-azure и azure-storage , в каталог /opt/mapr/drill/drill-1.6.0/jars/3rdparty/ на каждом узле моего кластера. , Чтобы помочь в этом, я воспользуюсь утилитой clusterterhell ( clush ), предварительно установленной в кластере MapR, с опцией -a, которая запускает закрытые команды в двойных кавычках для запуска на всех узлах кластера:
|
1
2
3
4
5
|
sudo clush -a "wget <a href="http://central.maven.org/maven2/org/apache/hadoop/hadoop-azure/2.7.3/hadoop-azure-2.7.3.jar">http://central.maven.org/maven2/org/apache/hadoop/hadoop-azure/2.7.3/had...</a>"sudo clush -a "wget <a href="http://central.maven.org/maven2/com/microsoft/azure/azure-storage/4.4.0/azure-storage-4.4.0.jar">http://central.maven.org/maven2/com/microsoft/azure/azure-storage/4.4.0/...</a>"sudo clush -a "mv *azure*.jar /opt/mapr/drill/drill-1.6.0/jars/3rdparty/" |
После установки драйверов мне нужно настроить Drill с ключом, используемым учетной записью хранилища Azure для управления доступом к его содержимому. Я делаю это, добавляя следующий блок под узлом конфигурации файла core-site.xml, расположенного в /opt/mapr/drill/drill-1.6.0/conf/, заменяя имя моей учетной записи хранилища Azure и ее ключ:
|
1
2
3
4
5
6
7
|
<property><name>fs.azure.account.key.<u>mydatafiles</u>.blob.core.windows.net</name><value><u>DrIhQUaOMvoydL0/+DcOuuWq8nj9TbwlLbFV4MIR7YdB1PihKQ==</u></value></property> |
На данный момент изменения в файле core-site.xml были сделаны только на узле 0, узле кластера, в который я вошел. Чтобы реплицировать эти изменения на оставшиеся узлы моего кластера, я могу использовать Снова утилита clusterterhell, на этот раз с помощью опции -w, чтобы контролировать, на каких узлах кластера выполнять предписанную операцию:
|
1
|
sudo clush -w maprclusternode[1-2] -c /opt/mapr/drill/drill-1.6.0/conf/core-site.xml --dest /opt/mapr/drill/drill-1.6.0/conf/ |
Обратите внимание, что я развернул кластер из трех узлов. Clustershell настроен на распознавание этих узлов как maprclusternode0, maprclusternode1 и maprclusternode2. После внесения изменений в файл core-site.xml на maprclusternode0 clush должен работать только с maprclusternode [1-2]. Если в вашем кластере другое количество узлов, вам нужно изменить значение, назначенное параметру -w. Кроме того, в этом экземпляре команды clustershell я дал команду clush использовать SCP, то есть параметр -c , чтобы скопировать локальную копию файла core-site.xml в соответствующее место назначения на целевых серверах.
ПРИМЕЧАНИЕ Если вы столкнулись с проблемой следующего набора шагов, попробуйте перезапустить службу Drill с помощью панели инструментов MapR (доступной через HTTPS через TCP-порт 8443).
Теперь, когда все компоненты драйвера установлены, я могу создать плагин хранения в Drill для своей учетной записи Azure Storage. Для этого я захожу в Drill Console, как описано в предыдущем посте, и перехожу на страницу Storage.
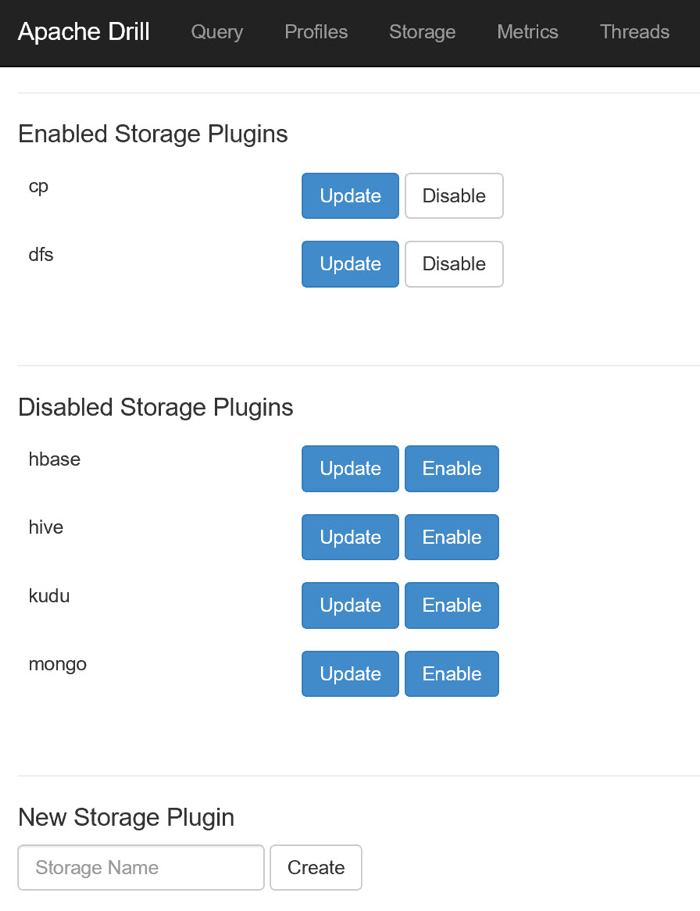
Конфигурация плагина, который я создам, будет очень похожа на конфигурацию плагина dfs по умолчанию. Поэтому перед созданием нового плагина я нажимаю кнопку «Обновить» рядом с плагином dfs, копирую информацию о его конфигурации и нажимаю кнопку «Назад», чтобы вернуться на страницу «Хранилище».
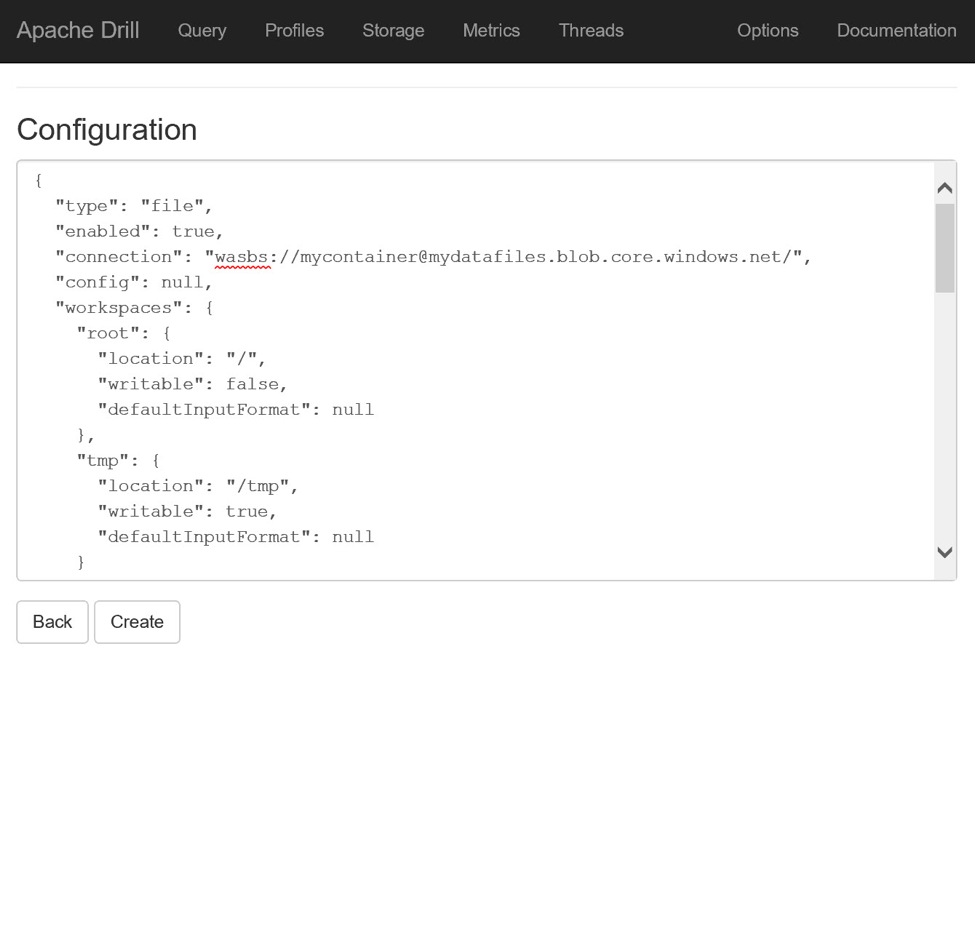
Имея информацию о конфигурации для плагина dfs, найдите раздел «Новый плагин хранения» в нижней части страницы «Хранилище», введите имя нового плагина, например, mydatafiles , и нажмите кнопку «Создать». На полученной странице конфигурации удалите ключевое слово null и замените его скопированной информацией о конфигурации. Найдите ключ подключения в конфигурации JSON и замените его значение на wasbs: // mycontainer@mydatafiles.blob.core.windows.net / , сделав соответствующие замены для учетной записи хранилища Azure и имен контейнеров. (Протокол wasbs: // инструктирует Drill использовать ранее загруженные драйверы и связывать их с учетной записью хранилища по протоколу HTTPS.)
Прежде чем покинуть эту страницу, прокрутите информацию о конфигурации, пока не найдете ключ форматов. Этот ключ содержит несколько дочерних пар ключ-значение, которые инструктируют Drill о том, как интерпретировать файлы в определенных форматах. Добавьте следующий ключ в форматы, указав Drill интерпретировать файлы с расширениями txt как текст с разделителями табуляции:
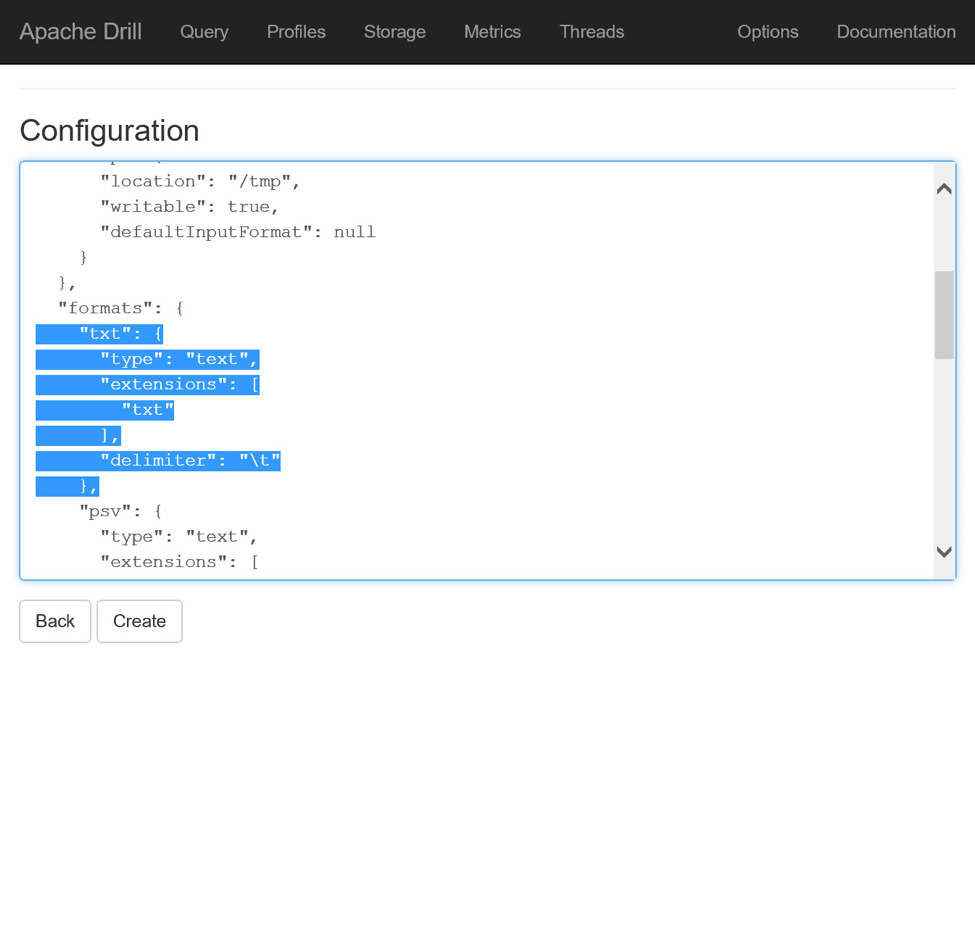
Нажмите кнопку Создать, чтобы создать плагин Storage. Вы должны увидеть баннерное сообщение с указанием успеха. Когда вы увидите это, нажмите «Назад», чтобы вернуться на страницу «Хранилище». Теперь вы должны увидеть свой плагин в списке в разделе Enabled Storage Plugins на странице.
Установив драйверы и настроив плагин, вы можете выполнить запрос к учетной записи хранилища Azure. Перейдите на страницу «Запрос» консоли Drill и отправьте следующий SQL-запрос, чтобы просмотреть список файлов в учетной записи хранения:
|
1
|
SHOW FILES FROM `mydatafiles`; |
ПРИМЕЧАНИЕ . Имя плагина в этом запросе заключено в обратные галочки, которые называются серьезными акцентами.
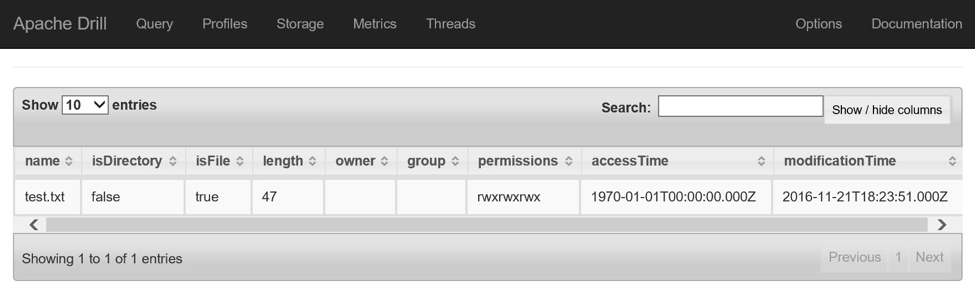
Чтобы запросить файл test.txt, загруженный в учетную запись хранения, введите запрос следующим образом:
|
1
|
SELECT columns[0] as FirstColumn, columns[1] as SecondColumn FROM mydatafiles.`test.txt` |
ПРИМЕЧАНИЕ. В этом запросе имя файла заключено в обратные галочки, но имя плагина не требует этого. Для получения дополнительной информации о запросах текстовых файлов, ознакомьтесь с этим документом .
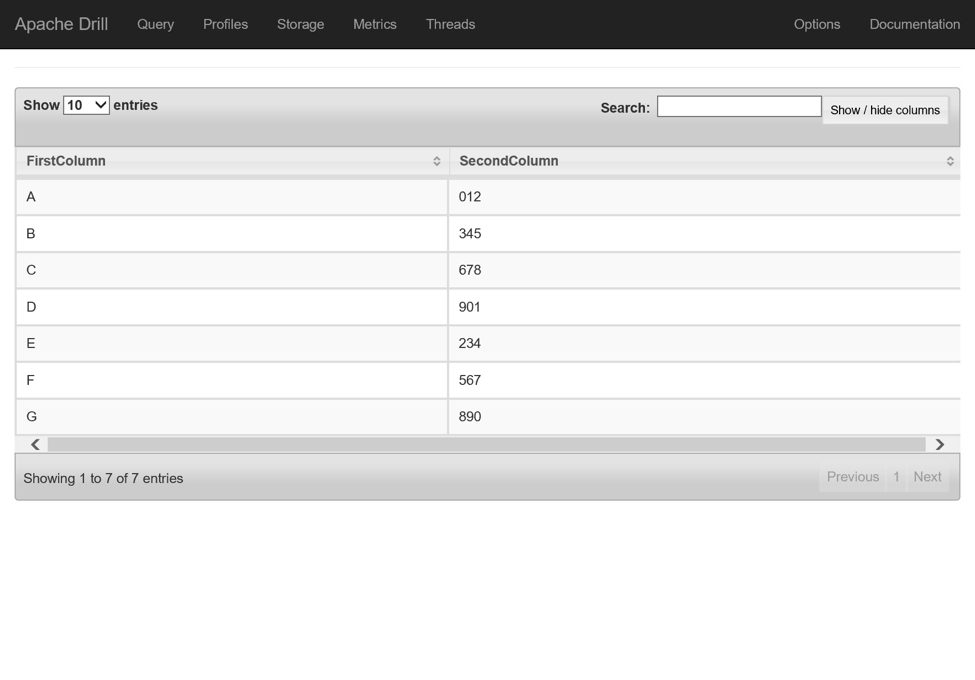
Подключение к базе данных SQL Azure
Шаги для подключения Drill к базе данных SQL Azure немного проще, чем для учетной записи хранилища Azure. Для начала я отправлю SSH к узлу 0 и загрузю последние версии драйверов JDBC для SQL Server для каждого из узлов кластера с использованием clustershell:
|
1
2
3
4
5
6
7
|
sudo clush -a "wget <a href="https://download.microsoft.com/download/0/2/A/02AAE597-3865-456C-AE7F-613F99F850A8/enu/sqljdbc_6.0.7728.100_enu.tar.gz">https://download.microsoft.com/download/0/2/A/02AAE597-3865-456C-AE7F-61...</a>"sudo clush -a "tar -xzvf sqljdbc_6.0.7728.199_enu.tar.gz"sudo clush -a "mv sqljdbc_6.0/enu/sqljdbc*.jar /opt/mapr/drill/drill-1.6.0/jars/3rdparty/"sudo clush -a "rm -r sqljdbc*" |
Затем я открою Консоль Drill, перейду на страницу «Хранилище» и создам новый плагин со следующей конфигурацией (используя соответствующие замены для имени сервера, имени базы данных, имени пользователя и пароля):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
{"type": "jdbc","driver": "com.microsoft.sqlserver.jdbc.SQLServerDriver","url": "jdbc:sqlserver://mydatabasesrv.database.windows.net:1433;databaseName=mydatabase","username": "<u>myusername</u>","password": "<u>mypassword</u>","enabled": true} |
После создания (с именем mydatabase) я могу проверить соединение с помощью простого запроса:
|
1
|
SELECT * FROM mydatabase.sys.objects; |
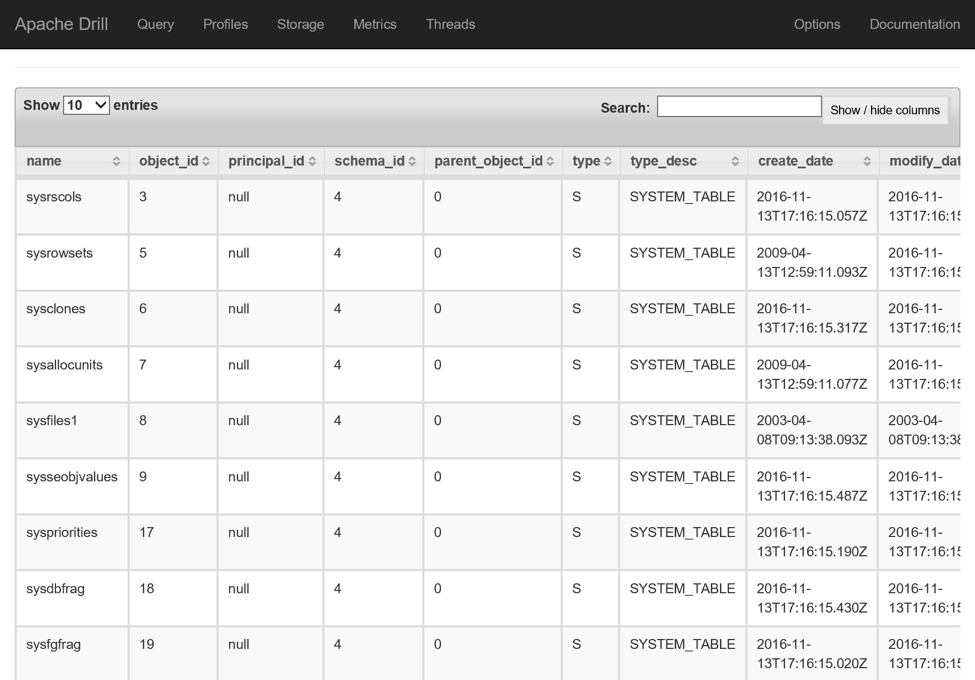
В этом посте вы узнали, как использовать кластер с поддержкой Drill для запроса учетной записи хранилища Azure, а также базы данных SQL Azure. В следующем посте мы рассмотрим, как использовать этот кластер в качестве источника данных в Microsoft Power BI .
| Ссылка: | Подключение кластера MapR с поддержкой Drill к ресурсам Azure (часть 2) от нашего партнера по JCG Брайана Смита в блоге Mapr . |