1. Введение
В этой последней части урока мы поговорим о теме, где сходятся все столпы наблюдаемости : мониторинг и оповещение. Для многих эта тема строго относится к операциям, и единственный способ узнать, как он работает, — это когда вы по вызову и вас вовлекают.
Содержание
Цель нашего обсуждения — демистифицировать, по крайней мере, некоторые аспекты мониторинга, узнать об оповещениях и понять, как метрики , распределенные трассы и иногда даже журналы используются для постоянного наблюдения за состоянием системы и уведомления о предстоящих проблемах, аномалиях, потенциальные сбои или неправильное поведение.
2. Философия мониторинга и оповещения
Существует множество различных метрик, которые можно (и нужно) собирать при работе с более или менее реалистичной системой программного обеспечения, особенно с учетом принципов архитектуры микросервиса . В этом контексте процесс сбора и хранения таких данных о состоянии обычно называется мониторингом.
Так что именно вы должны контролировать? Чтобы быть справедливым, нелегко представить все возможные аспекты системы, которые необходимо отслеживать, и, следовательно, решить, какие метрики (и другие сигналы) вам нужно собирать, а какие нет. но золотое правило «больше данных лучше, чем никаких данных», безусловно, применимо здесь. Конечная цель — когда что-то пойдет не так, подсистема мониторинга должна сразу же сообщить вам об этом. Это то, что является предупреждением.
Оповещение (или оповещение) — это общение между людьми, которое является важным или чувствительным ко времени.
Очевидно, что вы можете оповещать о чем угодно, но есть определенные правила, которым рекомендуется следовать при определении ваших собственных оповещений. Лучшее изложение философии оповещения изложено в этих прекрасных статьях: « Философия оповещения» от Netflix и « Моя философия оповещения» от Роба Эващука . Пожалуйста, постарайтесь найти время, чтобы просмотреть эти ресурсы, идеи, представленные там, бесценны.
Подводя итог некоторым лучшим практикам, когда срабатывает оповещение, должно быть легко понять, почему, поэтому поддержание правил оповещений как можно проще — хорошая идея. Как только предупреждение срабатывает, кто-то должен быть уведомлен и изучить его. Как таковые, оповещения должны указывать реальную причину, быть действенными и значимыми, шумных следует избегать любой ценой (и они все равно будут игнорироваться).
И последнее, но не менее важное: независимо от того, сколько метрик вы собираете, сколько панелей мониторинга и настроенных вами настроений, всегда будет что-то пропущено. Считайте этот процесс непрерывным улучшением, периодически переоценивайте свои решения по мониторингу, ведению журналов, распределенной трассировке, сбору метрик и оповещениям.
3. Мониторинг инфраструктуры
Мониторинг компонентов и уровней инфраструктуры является несколько решенной проблемой. С точки зрения открытого исходного кода , правящие имена, такие как Nagios , Zabbix , Riemann , OpenNMS и Icinga , правят там, и очень вероятно, что ваша операционная команда уже делает ставку на одно из них.
4. Мониторинг приложений
Инфраструктура, безусловно, подпадает под категорию «должны контролироваться», но прикладная сторона мониторинга, возможно, гораздо интереснее и ближе к предмету. Итак, давайте направим разговор к этому.
4.1 Прометей и Оповещатель
Мы уже говорили о Prometheus , в первую очередь как хранилище метрик, но факт в том, что он также включает компонент оповещения, называемый AlertManager, который возвращает его.
AlertManager обрабатывает предупреждения, отправляемые клиентскими приложениями, такими как сервер Prometheus. Он заботится о дедупликации, группировании и маршрутизации их для правильных интеграций получателя, таких как электронная почта, PagerDuty или OpsGenie. Он также заботится о глушении и подавлении предупреждений. — https://prometheus.io/docs/alerting/alertmanager/
На самом деле, AlertManager является автономным двоичным процессом, который обрабатывает предупреждения, отправленные экземпляром сервера Prometheus . Поскольку платформа JCG Car Rentals выбрала Prometheus в качестве платформы для оценки и мониторинга, она также становится логичным выбором для управления оповещениями.
По сути, есть несколько шагов для подражания. Процедура состоит из настройки и запуска экземпляра AlertManager , настройки Prometheus для связи с этим экземпляром AlertManager и, наконец, определения правил оповещения в Prometheus . Делая шаг за шагом, давайте сначала начнем с настройки AlertManager .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
|
global: resolve_timeout: 5m smtp_smarthost: 'localhost:25' smtp_from: 'alertmanager@jcg.org'route: receiver: 'jcg-ops' group_wait: 30s group_interval: 5m repeat_interval: 1h group_by: [cluster, alertname] routes: - receiver: 'jcg-db-ops' group_wait: 10s match_re: service: postgresql|cassandra|mongodbreceivers:- name: 'jcg-ops' email_configs: - to: 'ops-alerts@jcg.org'- name: 'jcg-db-ops' email_configs: - to: 'db-alerts@jcg.org' |
Если мы предоставим этот фрагмент конфигурации процессу AlertManager (обычно сохраняя его в alertmanager.yml ), он должен запуститься успешно, открыв свой веб-интерфейс на порту 9093 .
Отлично, теперь мы должны сказать Прометею, где искать экземпляр AlertManager . Как обычно, это делается через файл конфигурации.
|
1
2
3
4
5
6
7
8
|
rule_files: - alert.rules.yml alerting: alertmanagers: - static_configs: - targets: - 'alertmanager:9093' |
Приведенный выше фрагмент также включает в себя наиболее интересную часть, правила оповещения, и это то, что мы собираемся в следующем. Итак, что было бы хорошим, простым и полезным примером значимого оповещения в контексте платформы JCG Car Rentals ? Поскольку большинство сервисов JCG Car Rentals работают на JVM, первое, что приходит на ум, это использование кучи: слишком близкое ограничение является хорошим признаком проблемы и возможной утечки памяти.
|
01
02
03
04
05
06
07
08
09
10
11
|
groups:- name: jvm rules: - alert: JvmHeapIsFillingUp expr: jvm_memory_used_bytes{area="heap"} / jvm_memory_max_bytes{area="heap"} > 0.8 for: 5m labels: severity: warning annotations: description: 'JVM heap usage for {{ $labels.instance }} of job {{ $labels.job }} is close to 80% for last 5 minutes.' summary: 'JVM heap for {{ $labels.instance }} is filling up' |
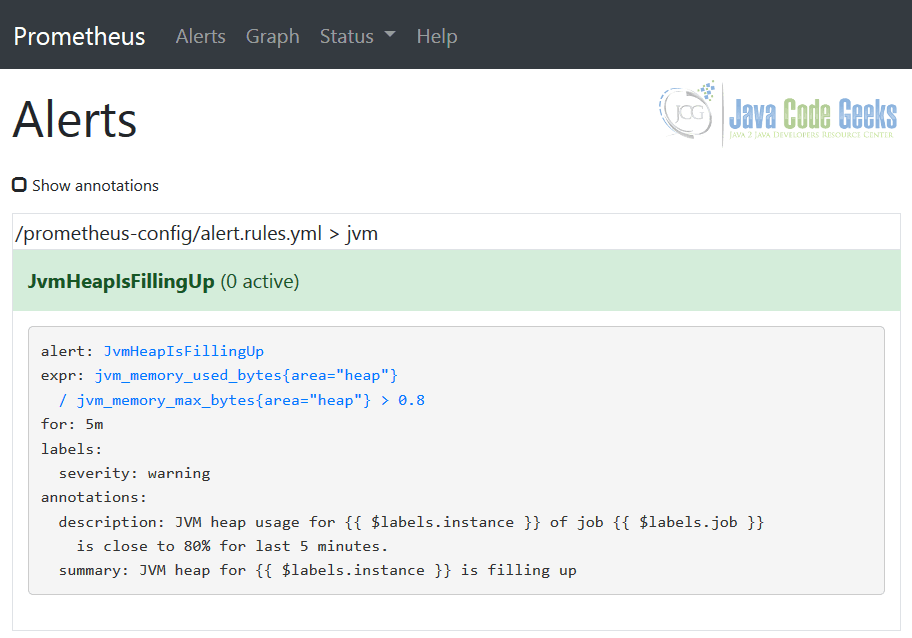
Те же правила оповещения можно увидеть в Prometheus, используя представление « Предупреждения» , подтверждая, что конфигурация выбрана правильно.
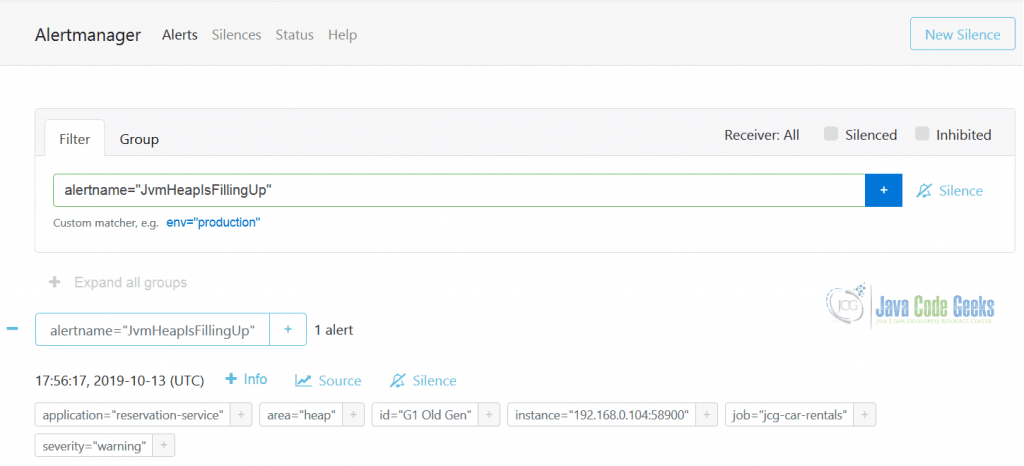
Как только предупреждение сработает, оно сразу же появится в AlertManager , одновременно уведомляя всех затронутых получателей (получателей). На картинке ниже вы можете увидеть пример сработавшего предупреждения JvmHeapIsFillingUp .
Как вы можете согласиться с этим, Prometheus действительно является полноценной платформой мониторинга, охватывающей вас не только с точки зрения сбора метрик, но и с точки зрения оповещения.
4.2. Стек тиков: хронограф
Если стек TICK звучит для вас знакомо, это потому, что он появился на нашем радаре в предыдущей части урока. Одним из компонентов стека TICK (который соответствует букве C в сокращении) является Chronograf .
Chronograf предоставляет пользовательский интерфейс для Kapacitor — встроенного механизма обработки данных, который может обрабатывать как потоковые, так и пакетные данные из InfluxDB . Вы можете создавать оповещения с помощью простого пошагового пользовательского интерфейса и просматривать свою историю оповещений в Chronograf .
InfluxDB 2.0 (все еще в альфа-версии), будущее стека InfluxDB и TICK в целом, будет включать Chronograf в свою платформу временных рядов.
4.3 Netfix Atlas
Netflix Atlas , последний из старых пользователей, о котором мы говорили ранее, также поддерживает встроенные в платформу оповещения .
4.4 Hawkular
Начиная с Hawkular , одного из проектов сообщества Red Hat , мы переключаемся на выделенные универсальные решения для мониторинга с открытым исходным кодом.
Hawkular — это набор проектов с открытым исходным кодом (Apache License v2), предназначенных для общего решения распространенных проблем мониторинга. Проекты Hawkular предоставляют REST-сервисы, которые могут использоваться для любых видов мониторинга.
Список компонентов Hawkular включает поддержку предупреждений, сбор метрик и распределенную трассировку (на основе Jaeger ).
4.5 Стадионмонитор
Stagemonitor является примером решения для мониторинга, специально предназначенного для серверных приложений на основе Java.
Stagemonitor — это агент мониторинга Java, который тесно интегрируется с базами данных временных рядов, такими как Elasticsearch , Graphite и InfluxDB, для анализа графических показателей и Kibana для анализа запросов и стеков вызовов. Он включает в себя предварительно настроенные информационные панели Grafana и Kibana, которые можно настраивать.
Подобно Hawkular , он поставляется с распределенной трассировкой, метриками и поддержкой предупреждений из коробки. Кроме того, поскольку он нацелен только на приложения Java, в платформу также поддерживаются многие специфические для Java идеи.
4.6 Графана
Это может показаться наименее ожидаемым, но Grafana — это не только потрясающий инструмент визуализации, но, начиная с версии 4.0 он поставляется с собственным механизмом оповещения и правилами оповещения. Оповещение в Grafana доступно на уровне панели для каждой панели (в данный момент только графики), и после сохранения правила оповещения будут извлечены в отдельное хранилище и запланированы для оценки. Если честно, есть определенные ограничения, которые заставляют Графану предупреждать об ограниченном использовании.
4.7 Адаптивное оповещение
До сих пор мы говорили о более или менее традиционных подходах к оповещению, основанных на метриках, правилах, критериях и / или выражениях. Однако более продвинутые методы, такие как обнаружение аномалий, постепенно внедряются в системы мониторинга. Одним из пионеров в этом пространстве является адаптивное оповещение Expedia .
Основная цель адаптивного оповещения — помочь сократить среднее время обнаружения (MTTD). Это достигается путем прослушивания потоковых метрических данных, выявления потенциальных аномалий, проверки их на предмет исключения ложных срабатываний и, наконец, передачи их в последующие системы обогащения и реагирования. — https://github.com/ExpediaDotCom/adaptive-alerting/wiki/Architectural-Overview
Адаптивное оповещение находится за подсистемой обнаружения аномалий в Haystack , гибкой, масштабируемой системе отслеживания и анализа, о которой мы говорили в предыдущей части руководства.
5. Оркестровка
Контейнерные оркестраторы, управляемые сервисными сетками, являются, вероятно, самой распространенной моделью развертывания микросервисов в настоящее время. Фактически, сервисная сетка играет роль «теневого кардинала», который отвечает и знает все. Извлекая все эти знания из сервисной сетки, вы получите полное представление о вашей микросервисной архитектуре . Одним из первых проектов, который решил реализовать эту простую, но мощную идею, был Kiali .
Kiali — это консоль наблюдаемости для Istio с возможностями настройки сервисной сетки. Это поможет вам понять структуру вашей сервисной сетки, сделав вывод о топологии, а также обеспечит работоспособность вашей сетки. Kiali предоставляет подробные метрики, а базовая интеграция Grafana доступна для сложных запросов. Распределенная трассировка обеспечивается за счет интеграции Jaeger .
Kiali объединяет большинство столпов наблюдаемости в одном месте, объединяя его с топологическим представлением вашего парка микросервисов в реальном времени. Если вы не используете Istio , Kiali может вам не сильно помочь, но другие сервисные сетки наверстывают упущенное, например, Linkerd поставляется с функциями телеметрии и мониторинга .
Так что насчет оповещения? Кажется, что возможности оповещения на данный момент не включены, и вам, возможно, придется подключиться к Prometheus или / и Grafana самостоятельно, чтобы настроить правила оповещения.
6. Облако
Облачная история оповещений является логическим продолжением дискуссии, которую мы начали, говоря о метриках . Те же самые предложения, которые заботятся о сборе оперативных данных, — это те, которые предназначены для управления оповещениями.
В случае AWS Amazon CloudWatch позволяет устанавливать сигналы тревоги (понятие предупреждений AWS ) и автоматизировать действия на основе либо предопределенных пороговых значений, либо алгоритмов машинного обучения (например, обнаружения аномалий).
Монитор Azure , который поддерживает метрики и коллекцию журналов в Microsoft Azure , позволяет настраивать различные виды предупреждений на основе журналов, метрик или действий.
В том же духе Google Cloud объединяет оповещения в Stackdriver Monitoring , который предоставляет способ определения политики оповещения: обстоятельства, о которых нужно предупредить, и способы получения уведомлений.
7. Без сервера
Оповещения так же важны в мире без серверов, как и везде. Но, как мы уже поняли, оповещения, связанные, например, с хостами, конечно же, не за горизонтом. Так что же происходит в безсерверной вселенной в отношении оповещения?
На самом деле это не простой вопрос. Очевидно, что если вы используете серверное предложение от облачных провайдеров, вы должны быть в значительной степени охвачены (или ограничены?) Их инструментами . На другом конце спектра у нас есть автономные структуры, делающие собственный выбор.
Например, OpenFaas использует Prometheus и AlertManager, так что вы можете свободно определять любые предупреждения, которые вам могут понадобиться. Аналогично, Apache OpenWhisk предоставляет ряд метрик, которые могут быть опубликованы в Prometheus и в дальнейшем дополнены правилами оповещения. Serverless Framework поставляется с набором предварительно сконфигурированных оповещений, но есть ограничения, связанные с их бесплатным уровнем.
8. Оповещения не только о метриках
В большинстве случаев метрики являются единственным входом, вводимым в правила оповещения. По большому счету, это имеет смысл, но есть и другие сигналы, которые вы можете использовать. Давайте рассмотрим журналы для примера. Что если вы хотите получить предупреждение, если в журналах появляется какое-то конкретное исключение?
К сожалению, ни Прометей, ни Графана , ни Netfix Atlas , ни Chronograf, ни Stagemonitor вам здесь не помогут. Положительным моментом является то, что у нас есть Hawkular, который может просматривать журналы, хранящиеся в Elasticsearch, и инициировать оповещения, используя сопоставление с образцом. Кроме того, Grafana Loki успешно продвигает поддержку предупреждений на основе журналов. В качестве последнего средства вам, возможно, придется применить собственное решение.
9. Микросервисы: мониторинг и оповещение — выводы
В этой последней части урока мы говорили о предупреждении, кульминации дискуссий о наблюдаемости . Как мы уже видели, очень легко создавать оповещения, но очень сложно придумать хорошие и действенные. Если вы получаете постраничный на ночь, должна быть реальная причина для этого. Вы не должны часами пытаться понять, что означает это предупреждение, почему оно сработало и что с этим делать.
10. В конце
Правда, это был долгий путь! По пути мы рассмотрели так много разных тем, что вы можете испугаться микросервисной архитектуры . Не бойтесь больше, есть огромные преимущества, которые он приносит на стол, однако он также требует от вас думать о системах, которые вы строите по-другому. Надеемся, что конец этого урока — это только начало вашего путешествия в увлекательный мир микросервисной архитектуры .
Но держи свои уши открытыми. Да, микросервисная архитектура — не серебряная пуля. Пожалуйста, не покупайте это как коммерческое предложение или попадите в ловушку обмана. Это решает реальные проблемы, но вы должны столкнуться с ними, прежде чем выбрать микросервисы в качестве решения. Пожалуйста, не инвертируйте эту простую формулу.
Желаем удачи и счастливого микросервиса!