1. Введение
В этой части урока мы продолжим наше путешествие в область наблюдательности и займемся ее следующей основой — метриками. В то время как журналы являются описательными, метрики черпают вдохновение из измерений.
Если вы не можете измерить это, вы не можете улучшить это. — Питер Друкер
Метрики служат множественным целям. Прежде всего, они дают вам быстрое представление о текущем состоянии вашей услуги или приложения. Во-вторых, метрики могут помочь коррелировать поведение различных приложений, служб и / или компонентов инфраструктуры в условиях большой нагрузки или простоев. Как следствие, они могут привести к более быстрой идентификации проблем и обнаружению узких мест. И наконец, что не менее важно, метрики могут помочь проактивно и эффективно смягчить потенциальные проблемы, сводя к минимуму риск того, что они перерастут в серьезные проблемы или повсеместные простои.
Еще больше есть. Одним из наиболее ценных свойств метрик является возможность фиксировать общие характеристики производительности системы, как таковые, устанавливая базовую линию для сравнения и определения тенденций. Опираясь на непрерывную интеграцию и практику доставки , они помогают обнаруживать любые нежелательные регрессии достаточно рано, до того, как они проникнут в производство.
Звучит действительно полезно, но какие метрики нужны нашим системам? Как мы могли бы использовать наши приложения и услуги? И что именно мы должны измерить? Это трудные вопросы, на которые мы будем пытаться ответить в этой части урока.
Содержание
2. Инструмент, собирать, визуализировать (и оповещение)
Метрики не отображаются из ниоткуда, приложения и / или службы должны быть оснащены инструментами, чтобы раскрыть соответствующие идеи. К счастью, здесь процветает экосистема JVM, есть несколько превосходных инструментальных библиотек (в частности, Micrometer и Dropwizard Metrics ), и большинство широко используемых сред имеют готовые интеграции, по крайней мере, с одной из них.
После раскрытия метрики необходимо собирать (помещать или очищать) и сохранять где-либо, чтобы обеспечить исторические тенденции с течением времени и агрегирование. Как правило, это выполняется с использованием одной из баз данных временных рядов .
База данных временных рядов создается специально для обработки метрик и событий или измерений с метками времени. TSDB оптимизирован для измерения изменений во времени. Свойства, которые делают данные временных рядов сильно отличающимися от других рабочих нагрузок данных, — это управление жизненным циклом данных, суммирование и сканирование большого количества записей. — https://www.influxdata.com/time-series-database/
Завершающим этапом жизненного цикла метрик является визуализация, обычно через предварительно созданные панели мониторинга, с использованием диаграмм / графиков, таблиц, тепловых карт и т. Д. С эксплуатационной точки зрения это, безусловно, полезно, но истинная ценность метрик заключается в том, чтобы служить основой для оповещения в режиме реального времени: возможность отслеживать тенденции и заблаговременно уведомлять об аномалиях или возникающих проблемах. Это так важно и важно для реальных производственных систем, что мы собираемся посвятить целую часть руководства тому, чтобы рассказать об оповещениях.
3. Операционный против приложения против бизнеса
Существует огромное количество метрик, которые могут быть собраны и обработаны. Грубо говоря, их можно разделить на три класса: операционные метрики, метрики приложений и бизнес-метрики.
Чтобы взглянуть в будущее, давайте сосредоточимся на платформе JCG Car Rentals, которая состоит из нескольких HTTP- сервисов , хранилищ данных и брокеров сообщений. Эти компоненты, вероятно, работают на каком-то виртуальном или физическом хосте, скорее всего, внутри контейнера. Как минимум, на каждом уровне нам было бы интересно собрать показатели для ЦП, памяти, дискового ввода-вывода и использования сети.
В случае микросервисов на основе HTTP , как минимум, мы хотим знать о следующих вещах:
- Запросов в секунду (RPS) . Это основной показатель, который показывает, сколько запросов проходит через приложение или службу.
- Время отклика Еще одна базовая метрика, показывающая, сколько времени требуется приложению или службе для ответа на запросы.
- Ошибки Этот показатель указывает на количество ошибочных ответов приложения или службы. В случае протокола HTTP нас больше всего интересуют ошибки
5xx(ошибки на стороне сервера), однако практически нельзя также пренебрегать ошибками4xx.
Это типичные примеры рабочих метрик, и, честно говоря, их сотни и сотни. Некоторые просты, другие нет. Например, что может быть хорошим, ориентировочным показателем для брокеров сообщений с учетом различий в их архитектуре? К счастью, в большинстве случаев поставщики и сопровождающие уже позаботились о раскрытии и документировании соответствующих метрик, а также о публикации информационных панелей и шаблонов для упрощения операций.
Так что насчет метрик приложения? Как вы можете догадаться, они действительно зависят от контекста реализации и различаются. Например, приложения, построенные поверх актерской модели, должны предоставлять ряд метрик, связанных с актерской системой и актерами. В том же духе приложениям на основе Tomcat может потребоваться предоставить метрики, относящиеся к пулам и очередям серверных потоков.
Бизнес-показатели, по сути, свойственны каждой области системы и значительно различаются. Например, для платформы JCG Car Rentals важная бизнес-метрика может включать количество бронирований за промежуток времени.
4. Особенности JVM
В мире Java между операционной системой и приложением есть одна вещь: JVM. Это потрясающая, но в равной степени сложная технология, которую нужно отслеживать: процессор, потребление кучи, сборка мусора, метапространство, загрузка классов, буферы вне кучи и т. Д. К счастью, JVM предоставляет множество метрик из коробки, поэтому становится вопросом их правильного использования.
Чтобы обобщить этот момент, всегда изучайте среду выполнения, в которой работают ваши приложения и службы, и убедитесь, что у вас есть правильные метрики для понимания того, что происходит.
5. Потяните или нажмите?
В зависимости от используемого вами бэкэнда мониторинга существуют две основные стратегии сбора метрик из приложений или служб: либо они периодически отправляются, либо извлекаются (очищаются). У каждой из этих стратегий есть свои плюсы и минусы (например, известная слабость стратегии, основанной на извлечении, — это эфемерные и пакетные задания, которые могут существовать недостаточно долго, чтобы их можно было удалить), поэтому потратьте некоторое время, чтобы понять, какая из них подходит лучше ваш контекст.
6. Хранение
Как мы уже упоминали ранее, для эффективного хранения и запроса метрик требуется использование специальной базы данных временных рядов . Есть немало хороших вариантов, о которых мы поговорим.
6.1. RRDTool
Если вы ищете что-то действительно простое, вероятно, вам нужен RRDtool (или более длинная версия, инструмент Round Robin Database ).
RRDtool — это отраслевой стандарт OpenSource, высокопроизводительная система регистрации и отображения данных для временных рядов. RRDtool может быть легко интегрирован в сценарии оболочки, приложения на perl, python, ruby, lua или tcl. — https://oss.oetiker.ch/rrdtool/
Идея создания циклических баз данных довольно проста и использует циклические буферы , таким образом, сохраняя постоянную площадь памяти системы.
6.2. Ганглиев
Когда-то довольно популярный, Ganglia , вероятно, является старейшей системой мониторинга с открытым исходным кодом. Хотя вы можете найти упоминания о ганглиях в дикой природе, к сожалению, он больше не активно развивается.
Ganglia — это масштабируемая распределенная система мониторинга для высокопроизводительных вычислительных систем, таких как кластеры и сети. — http://ganglia.info/
6.3. графитовый
Graphite — один из первых проектов с открытым исходным кодом, появившийся как полноценный инструмент мониторинга. Он был создан еще в 2006 году, но до сих пор активно поддерживается.
Graphite — это готовый к работе инструмент мониторинга, который одинаково хорошо работает на дешевом оборудовании или облачной инфраструктуре. Команды используют Graphite для отслеживания производительности своих веб-сайтов, приложений, бизнес-сервисов и сетевых серверов. Это ознаменовало начало нового поколения инструментов мониторинга, что стало проще, чем когда-либо, для хранения, извлечения, обмена и визуализации данных временных рядов. — https://graphiteapp.org/#overview
Интересно, что механизм хранения Graphite очень похож по дизайну и назначению на циклические базы данных, такие как RRDTool .
6.4. OpenTSDB
Некоторые базы данных временных рядов построены на основе более традиционного (реляционного или нереляционного) хранилища данных, как, например, OpenTSDB , которое опирается на Apache HBase .
OpenTSDB — это распределенная масштабируемая база данных временных рядов (TSDB), написанная поверх HBase . OpenTSDB был написан для удовлетворения общей потребности: хранить, индексировать и обслуживать показатели, собранные из компьютерных систем (сетевое оборудование, операционные системы, приложения) в большом масштабе, и сделать эти данные легко доступными и доступными для понимания. — https://github.com/OpenTSDB/opentsdb
6,5. TimescaleDB
TimescaleDB — это еще один пример базы данных временных рядов с открытым исходным кодом, созданной поверх проверенного хранилища данных, в данном случае PostgreSQL .
TimescaleDB — это база данных временных рядов с открытым исходным кодом, оптимизированная для быстрого приема и сложных запросов. Он говорит «полный SQL» и, соответственно, прост в использовании, как традиционная реляционная база данных, но масштабируется способами, ранее зарезервированными для баз данных NoSQL. — https://docs.timescale.com/latest/introduction
С точки зрения разработки, TimescaleDB реализован как расширение на PostgreSQL, так что это в основном означает запуск внутри экземпляра PostgreSQL .
6.6. KairosDB
KairosDB изначально был основан на OpenTSDB, но со временем превратился в независимую, перспективную базу данных временных рядов с открытым исходным кодом.
KairosDB — это быстро распространяемая масштабируемая база данных временных рядов, написанная поверх Cassandra . — https://github.com/kairosdb/kairosdb
6.7. InfluxDB (и стек TICK)
InfluxDB — это база данных временных рядов с открытым исходным кодом, которая разрабатывается и поддерживается InfluxData .
InfluxDB — это база данных временных рядов, предназначенная для обработки высокой нагрузки записи и запросов — https://www.influxdata.com/products/influxdb-overview/
InfluxDB редко используется отдельно, но как часть более комплексной платформы, называемой стеком TICK , в которую входят Telegraf , Chronograf и Kapacitor . Следующее поколение InfluxDB , в настоящее время находящееся в альфа- версии, намеревается объединить эту платформу временных рядов в один распространяемый двоичный файл.
6.8. Прометей
В настоящее время Prometheus является выбором номер один в качестве платформы для показателей, мониторинга и оповещения. Помимо простоты и легкости развертывания, он изначально интегрируется с оркестровщиками контейнеров, такими как, например, Kubernetes .
Prometheus — это набор инструментов для мониторинга и оповещения систем с открытым исходным кодом, изначально созданный в SoundCloud . — https://prometheus.io/docs/introduction/overview/
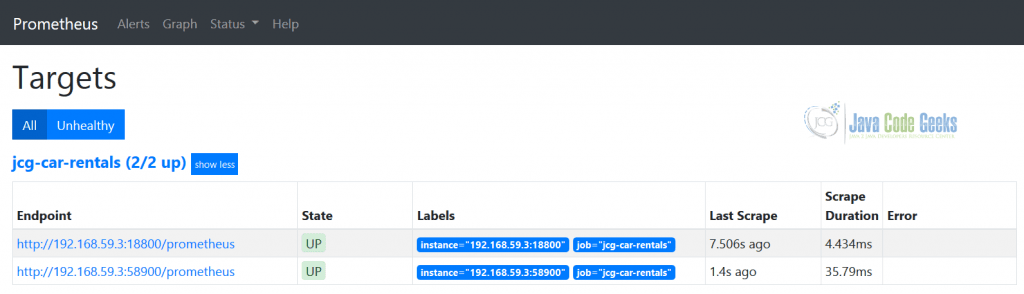
В 2016 году Прометей присоединился к Cloud Native Computing Foundation ( CNCF ). Для платформы JCG Car Rentals Prometheus станет очевидным выбором для сбора, хранения и запроса метрик. В случае простой статической конфигурации Prometheus (со статическими IP-адресами), вот как подмножество сервисов платформы JCG Car Rentals отображается на веб-странице Targets .
6,9. Netflix Atlas
Atlas родился (и был открыт с открытым исходным кодом) в Netflix , что обусловлено необходимостью справиться с увеличением количества метрик, которые должны собираться его потоковой платформой.
Atlas был разработан Netflix для управления данными пространственных временных рядов для оперативного анализа практически в реальном времени. Atlas поддерживает хранение данных в памяти, что позволяет собирать и сообщать очень большое количество показателей очень быстро. — https://github.com/Netflix/atlas/wiki
Это отличная система, но имейте в виду, что выбор использования хранилища данных в памяти является одной из проблем Atlas и может повлечь дополнительные расходы .
7. Контрольно-измерительные приборы
Выбор структуры играет важную роль, чтобы облегчить инструментарий приложений и сервисов. Например, поскольку служба резервирования использует Spring Boot , в стандартной комплектации поддерживается стандартный набор метрик для веб-серверов и веб-клиентов, запечиваемый Micrometer .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
management: endpoint: prometheus: enabled: true metrics: enabled: true metrics: distribution: percentiles-histogram: http.server.requests: true export: prometheus: enabled: true web: client: max-uri-tags: 150 requests-metric-name: http.client.requests server: auto-time-requests: true requests-metric-name: http.server.requests |
Более того, Spring Boot поставляется с удобными настройщиками для обогащения метрик дополнительной конфигурацией и метаданными (метками или / и метками).
|
1
2
3
4
5
6
7
|
@Configurationpublic class MetricsConfiguration { @Bean MeterRegistryCustomizer<MeterRegistry> metricsCommonTags(@Value("${spring.application.name}") String application) { return registry -> registry.config().commonTags("application", application); }} |
Интеграция с Prometheus , выбором для мониторинга платформы JCG Car Rentals , также проста и поставляется в комплекте с Micrometer .
|
1
2
3
4
|
<dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-registry-prometheus</artifactId></dependency> |
С другой стороны, Служба поддержки клиентов использует метрики Dropwizard и нуждается в небольшой настройке для сбора и представления нужных метрик в соответствии с протоколом Prometheus .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
|
@ApplicationScopedpublic class PrometheusServletProvider implements ServletContextAttributeProvider{ @Inject private MetricsConfig metricsConfig; @PostConstruct public void init() { CollectorRegistry.defaultRegistry.register(new DropwizardExports(metricsConfig.getMetricRegistry())); DefaultExports.initialize(); } @Produces public ServletDescriptor prometheusServlet() { String[] uris = new String[]{"/prometheus"}; WebInitParam[] params = null; return new ServletDescriptor("Prometheus", uris, uris, 1, params, false, MetricsServlet.class); } @Override public Map<String, Object> getAttributes() { return Collections.emptyMap(); }} |
7.1. Statsd
Помимо чисто специфичных для JVM опций стоит упомянуть statsd . По сути, это интерфейсный прокси для разных метрических бэкэндов .
Сетевой демон, который работает на платформе Node.js и прослушивает статистику, такую как счетчики и таймеры, отправляемую по UDP или TCP, и отправляет агрегаты одной или нескольким подключаемым внутренним службам (например, Graphite ). — https://github.com/statsd/statsd
Доступно большое количество клиентских реализаций , после чего statsd позиционируется как очень привлекательный выбор для микросервисных архитектур Polyglot .
7.2. OpenTelemetry
Как мы уже видели, существует довольно много мнений о том, как следует проводить инструментарий и сбор метрик. Недавно была объявлена новая общеотраслевая инициатива под зонтиком OpenTelemetry .
OpenTelemetry состоит из интегрированного набора API и библиотек, а также механизма сбора данных через агента и сборщика. Эти компоненты используются для генерации, сбора и описания телеметрии о распределенных системах. Эти данные включают в себя базовое распространение контекста, распределенные трассы, метрики и другие сигналы в будущем. OpenTelemetry разработан для того, чтобы упростить получение критических данных телеметрии из ваших служб в выбранные вами бэкэнды . Для каждого поддерживаемого языка предлагается один набор API, библиотек и спецификаций данных, и разработчики могут использовать любые компоненты, которые они считают подходящими. — https://opentelemetry.io/
Цели OpenTelemetry выходят далеко за рамки метрик, и о некоторых из них мы поговорим подробнее в следующих частях учебника. На данный момент OpenTelemetry доступна только в виде спецификации . Но если вы хотите попробовать, он основан на хорошо известном проекте OpenSensus , который также включает в себя инструментарий метрик .
7.3. JMX
Для приложений JVM существует еще один способ представления метрик в реальном времени с использованием Java Management Extensions ( JMX ). Честно говоря, JMX — довольно старая технология, и вам может показаться неудобным ее использование, однако это, вероятно, самый простой и быстрый способ получить представление о ваших приложениях и сервисах на основе JVM.
Стандартный способ подключения к приложениям JVM через JMX — это использование JConsole , JVisualVM или новейший способ, используя JDK Mission Control ( JMC ). Например, на приведенном ниже снимке экрана показан JVisualVM в действии, который визуализирует показатель запросов Apache Cassandra , предоставляемый службой бронирования через JMX .
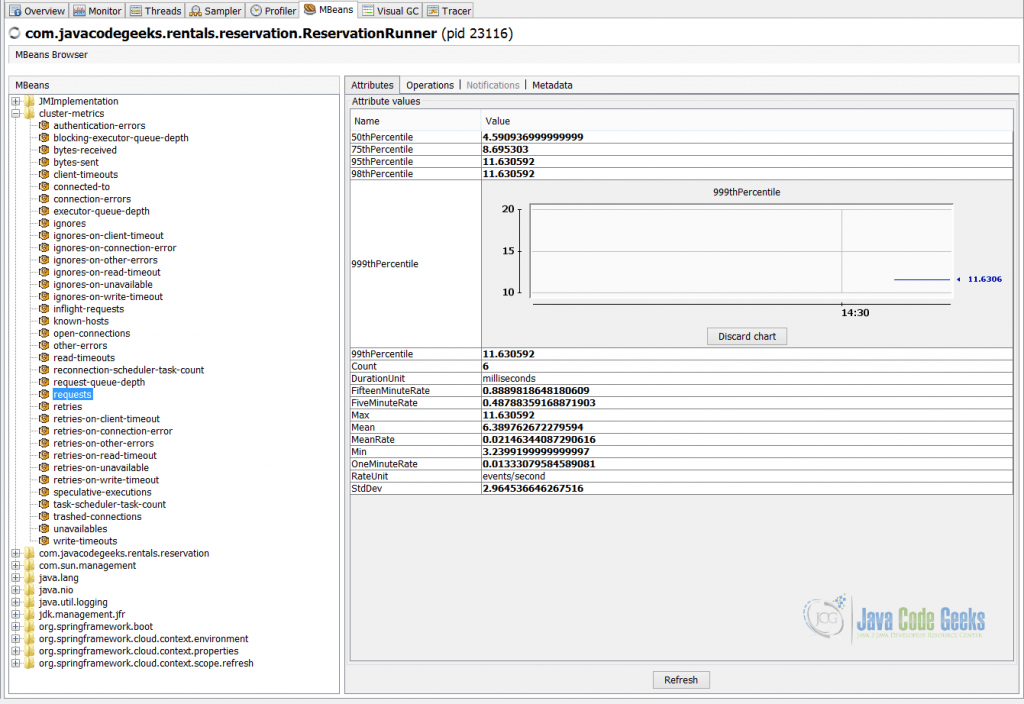
Метрики, предоставляемые через JMX, являются эфемерными и доступны только в то время, когда приложения и службы работают и работают (если быть точным, постоянство является необязательным, непереносимым и используется редко). Также имейте в виду, что сфера применения JMX не ограничивается метриками, а управлением в целом.
8. Визуализация
Как мы уже поняли, типичное приложение или служба JVM предоставляет множество метрик. Некоторые из них редко бывают полезными, тогда как другие являются критическими показателями работоспособности приложения или службы. Какие средства мы должны сделать это различие очевидным и, что более важно, значимым и полезным? Одним из ответов является визуализация и построение операционных и / или бизнес-панелей в реальном времени.
Платформы мониторинга и управления метриками, такие как Graphite , Prometheus и InfluxDB , поддерживают довольно сложные языки запросов и графики, поэтому вы даже не сможете копать дальше. Но в случае, если вы ищете создание современных инструментальных панелей или консолидацию по нескольким метрическим источникам, вам нужно поискать вокруг.
8.1. графана
Несомненно, что на сегодняшний день Grafana является универсальным магазином для визуализации метрик и создания действительно красивых панелей мониторинга (с большим количеством готовых уже доступных ).
Grafana — ведущий проект с открытым исходным кодом для визуализации метрик. Поддержка богатой интеграции для каждой популярной базы данных, такой как Graphite , Prometheus и InfluxDB . — https://grafana.com/ Для JCG
Grafana идеально подходит для платформы JCG Car Rentals , поскольку она отлично интегрирована с Prometheus . В случае Reservation Service , использующего библиотеку Micrometer , есть несколько инструментальных панелей, созданных сообществом для быстрого начала работы, одна из них показана ниже.
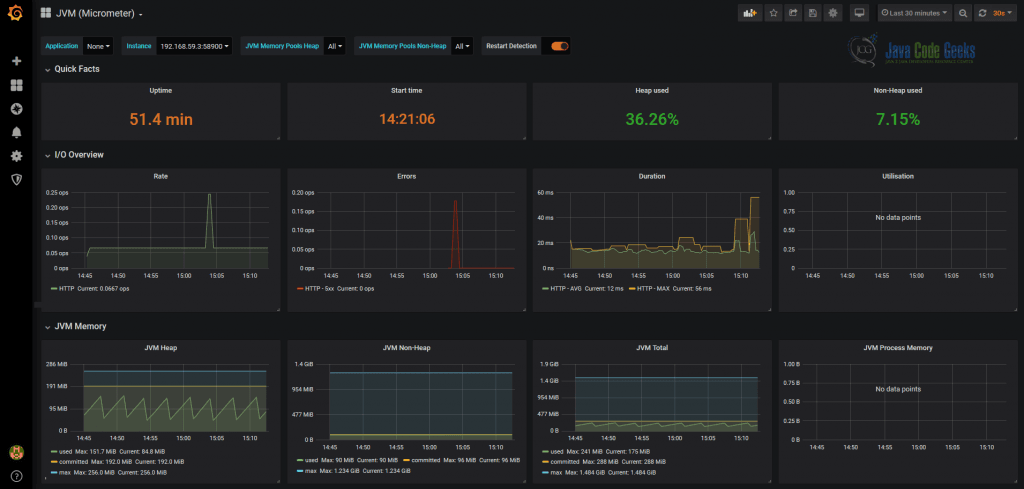
Стоит подчеркнуть, что Grafana обладает широкими возможностями настройки и расширения, поэтому, если вы решите использовать его в качестве платформы для визуализации метрик, маловероятно, что в будущем решение об этом будет сожалеть.
9. Облако
Для приложений и сервисов, развернутых в облаке, важность метрик (и оповещений, подробнее об этом в следующей части учебника) имеет первостепенное значение. Шаблон, который вы быстро обнаружите, состоит в том, что управление метриками сопровождается теми же предложениями, о которых мы говорили в предыдущей части учебного руководства , поэтому давайте быстро взглянем на них.
Если вы используете приложения, службы, шлюзы API или функции в AWS , Amazon CloudWatch автоматически собирает и отслеживает большое количество метрик (а также других рабочих данных) от вашего имени без какой-либо дополнительной настройки (включая инфраструктуру). Кроме того, если вы ищете только часть хранилища, безусловно, стоит изучить Amazon Timestream , быстрое, масштабируемое и полностью управляемое предложение для баз данных временных рядов .
Предложение Microsoft Azure для сбора и мониторинга метрик является частью платформы данных Azure Monitor .
Как и другие, Google Cloud не имеет автономного предложения только для управления метриками, а объединяет его со Stackdriver Monitoring , частью предложения Stackdriver .
10. Бессерверный
Наиболее существенный сдвиг мышления для безсерверных рабочих нагрузок заключается в том, что показатели, связанные с хост-системами, больше не являются вашей задачей. С другой стороны, вам нужно понять, какие метрики актуальны в мире без серверов, и собирать их. Так что они?
- Продолжительность вызова . Распределение времени выполнения функции (поскольку это то, за что вы в основном платите).
- Количество вызовов . Сколько раз была вызвана функция.
- Ошибочные счета вызовов . Сколько раз функция не завершалась успешно.
Это хорошая отправная точка, однако наиболее важными будут показатели бизнеса или приложения, которые являются неотъемлемой частью того, что должна делать каждая функция.
Большинство облачных провайдеров собирают и визуализируют метрики для своих серверных предложений, и хорошие новости заключаются в том, что популярные открытые серверные платформы с открытым исходным кодом, такие как jazz , Apache OpenWhisk , OpenFaas , Serverless Framework, имеют как минимум базовые инструменты и предоставляют ряд метрик из коробка также.
11. Какова стоимость?
До сих пор мы были сосредоточены на важности метрик для сбора идей, отслеживания тенденций и моделей. Однако мы не говорили о стоимости этого, как с точки зрения хранения, так и с точки зрения вычислений.
Сложно придумать модель универсальных издержек, но есть ряд факторов и компромиссов, которые необходимо учитывать. Самые важные из них:
- Общее количество метрик.
- Количество различных временных рядов, которые существуют для определенной метрики.
- Внутреннее хранилище (например, хранение всех данных в памяти дорого, диск — гораздо более дешевый вариант).
- Сбор необработанных показателей по сравнению с предварительно агрегированными.
Еще один риск, с которым вы можете столкнуться, связан с выполнением запросов и агрегатов на большом количестве временных рядов. В большинстве случаев это очень дорогая операция, и лучше планировать емкость заранее, если вам действительно необходимо это поддерживать.
Как вы можете догадаться, если оставить его на месте, вещи могут стать довольно дорогими.
12. Выводы
В этой части урока мы говорили о метриках, еще одном столпе наблюдаемости . Метрики и журналы представляют собой абсолютно необходимую основу для каждой распределенной системы, построенной по микросервисной архитектуре . Мы узнали, как используются приложения и сервисы, как собираются и хранятся метрики, и, наконец, что не менее важно, как они могут быть представлены в удобной для человека форме с помощью панелей мониторинга (после этого появится предупреждение).
В заключение было бы справедливо сказать, что в центре нашего внимания были в первую очередь платформы управления метриками, а не аналитические, такие как Apache Druid или ClickHouse , или контрольные, такие как Nagios или Hawkular (хотя здесь есть некоторые пересечения). Тем не менее, пожалуйста, следите за обновлениями, мы вернемся к более широкой теме мониторинга и оповещения в последней части руководства.
13. Что дальше
В следующей части урока мы поговорим о распределенной трассировке.