В современном мире технологий возможности синтаксического анализа XML необходимы для большого числа приложений, будь то мобильные, корпоративные или облачные. Несмотря на то, что XML раздутый и очень многословный, он все еще остается королем в области обмена данными (JSON — хорошая альтернатива, посмотрите наше руководство по интеграции JSON с GWT ).
Существует два основных подхода к синтаксическому анализу XML: SAX и DOM. Спецификация SAX определяет основанный на событиях подход, при котором реализованные анализаторы сканируют данные XML и используют обработчики обратного вызова при достижении определенных частей документа. С другой стороны, спецификация DOM определяет древовидный подход к навигации по документу XML.
В предыдущем уроке мы видели, как анализировать XML-документы, используя SAX. Объект DOM относительно ресурсоемкий и, возможно, не подходит для использования в мобильной среде. Синтаксический анализатор SAX довольно легкий и использует меньше памяти. SAX — это API push-разбора, но подход, который он использует, несколько «сломан» в том смысле, что SAXParser вместо того, чтобы вызывать его, использует обработчик сообщений с «обратными вызовами».
Альтернативой этому является использование сравнительно новой практики, подхода «парсинга». Короче говоря, основным отличием этого подхода является то, что пользовательский код находится под контролем и может получить больше данных, когда он будет готов к их обработке. Вы можете найти отличную статью по обработке XML с помощью XML Pull Parser, а также некоторые шаблоны синтаксического анализа XML .
Android SDK включает поддержку синтаксического анализа XML Pull (что удивительно существует в API уровня 1) через пакет XML Pull . Основной используемый класс — это XmlPullParser со страницей Javadoc, включающей простой пример использования синтаксического анализатора. В этом уроке я собираюсь показать вам, как добавить возможности разбора по запросу в ваше приложение Android и как реализовать более сложный синтаксический анализатор, чем тот, который предоставляется в документации API.
Если вы обычный читатель JavaCodeGeeks , вы, вероятно, знаете, что я начал серию учебных пособий, в которых я создаю полное приложение с нуля. В третьей части ( «Android Full App, часть 3: анализ ответа XML» ) я использую внешний API на основе XML для выполнения поиска фильмов. Пример XML-ответа следующий:
Поиск фильмов «Трансформеры» и (год) «2007»
В этом уроке я представил подход, основанный на SAX, но знаю, что мы собираемся улучшить ситуацию с помощью Android pull-парсера XML. Во-первых, давайте создадим новый проект Android внутри Eclipse. Я называю это «AndroidXmlPullParserProject». Вот скриншот используемой конфигурации:

Первым шагом в использовании API XML Pull является получение нового экземпляра класса XmlPullParserFactory. Этот класс используется для создания реализаций XML Pull Parser, определенного в XMPULL V1 API. Мы отключим понимание фабрики пространства имен, так как это не требуется потребностями приложения. Обратите внимание, что это также улучшит скорость разбора.
Затем мы создаем новый XmlPullParser , вызывая фабричный метод newPullParser . Входные данные должны быть предоставлены нашему анализатору, и это выполняется с помощью метода setInput, который требует InputStream и кодировку в качестве аргументов. Мы предоставляем входной поток, полученный с помощью URL-соединения (поскольку наш XML-документ является интернет-ресурсом), но мы не предоставляем входную кодировку (null просто отлично).
Синтаксический анализ XML Pull основан на событиях, и для анализа всего документа нужно создать цикл, внутри которого мы последовательно получаем все события синтаксического анализа, пока не достигнем события END_DOCUMENT . В качестве демонстрационного примера код будет просто печатать операторы журнала, когда встречаются следующие события:
- START_TAG : начальный тег XML прочитан.
- Текст : текстовое содержание было прочитано.
- END_TAG : конечный тег XML был прочитан.
- START_DOCUMENT : анализатор находится в начале документа.
- END_DOCUMENT : логический конец документа xml.
Вот исходный код нашей первой простой реализации:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
package com.javacodegeeks.android.xml.pull;import java.io.InputStream;import java.net.URL;import java.net.URLConnection;import org.xmlpull.v1.XmlPullParser;import org.xmlpull.v1.XmlPullParserFactory;import android.app.Activity;import android.os.Bundle;import android.util.Log;public class XmlPullParserActivity extends Activity { private static final String xmlUrl = private final String TAG = getClass().getSimpleName(); @Override public void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.main); try { parseFromUrl(); } catch (Exception e) { Log.e(TAG, "Error while parsing", e); } } private void parseFromUrl() throws Exception { XmlPullParserFactory factory = XmlPullParserFactory.newInstance(); factory.setNamespaceAware(false); XmlPullParser xpp = factory.newPullParser(); URL url = new URL(xmlUrl); URLConnection ucon = url.openConnection(); InputStream is = ucon.getInputStream(); xpp.setInput(is, null); int eventType = xpp.getEventType(); while (eventType != XmlPullParser.END_DOCUMENT) { if (eventType == XmlPullParser.START_DOCUMENT) { Log.d(TAG, "Start document"); } else if (eventType == XmlPullParser.END_DOCUMENT) { Log.d(TAG, "End document"); } else if (eventType == XmlPullParser.START_TAG) { Log.d(TAG, "Start tag " + xpp.getName()); } else if (eventType == XmlPullParser.END_TAG) { Log.d(TAG, "End tag " + xpp.getName()); } else if (eventType == XmlPullParser.TEXT) { Log.d(TAG, "Text " + xpp.getText()); } eventType = xpp.next(); } } |
Включите разрешение ИНТЕРНЕТ в свой файл манифеста Android и запустите проект. Перейдите в представление DDMS Eclipse и создайте новый фильтр, используя имя класса «XmlPullParserActivity», как показано на следующем рисунке:
Затем вы должны найти различные сообщения журнала в представлении LogCat:
Обратите внимание, что никакого специального анализа не произошло. Мы только что получили уведомление, когда парсер нашел новый тег, достиг конца документа и т. Д. Однако, поскольку мы уверены, что у нас есть готовая базовая инфраструктура, мы можем немного ее увеличить. Сначала взглянем на образец XML (предоставляемый API TMDb ):
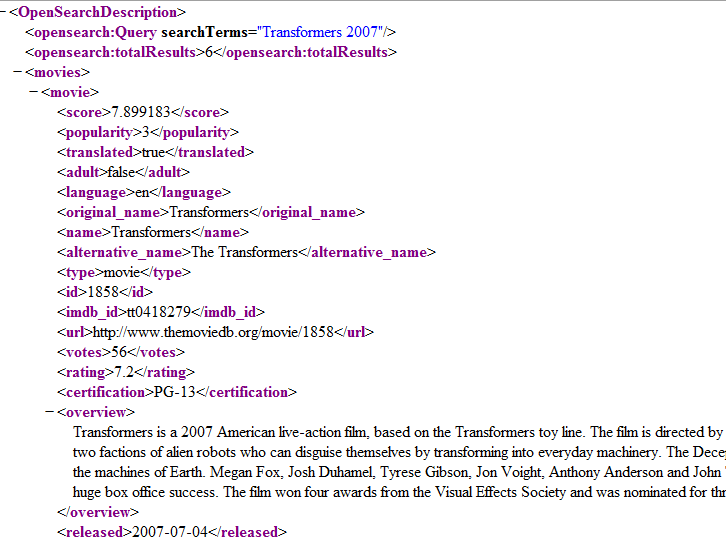
Это ваш типичный XML-документ с вложенными элементами и т. Д. Интересующие нас данные находятся внутри элемента «movies». Мы создадим класс Movie и отобразим каждый дочерний элемент в соответствующее поле класса. Кроме того, мы также создадим класс Image, используя тот же подход. Обратите внимание, что фильм может иметь ноль или более изображений. Таким образом, два класса модели предметной области:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
package com.javacodegeeks.android.xml.pull.model;import java.util.ArrayList;public class Movie { public String score; public String popularity; public boolean translated; public boolean adult; public String language; public String originalName; public String name; public String type; public String id; public String imdbId; public String url; public String votes; public String rating; public String certification; public String overview; public String released; public String version; public String lastModifiedAt; public ArrayList<Image> imagesList;} |
|
01
02
03
04
05
06
07
08
09
10
11
|
package com.javacodegeeks.android.xml.pull.model;public class Image { public String type; public String url; public String size; public int width; public int height;} |
Теперь мы готовы начать разбор. Сначала мы создаем фабрику и синтаксический анализатор так же, как и раньше. Обратите внимание, что документ не начинается непосредственно с элемента «movies», но есть несколько элементов, которые мы хотим пропустить. Это достигается с помощью методов nextTag (для событий START_TAG и END_TAG ) и nextText (для событий TEXT ).
Теперь мы готовы приступить к интересному разбору. Мы собираемся использовать «рекурсивный» подход. Элемент «movies» содержит несколько элементов «movie», где элемент «movie» содержит несколько элементов «image». Таким образом, мы «углубляемся» от родительских элементов к дочерним, используя специальный метод для разбора каждого элемента. От одного метода к другому мы передаем экземпляр XmlPullParser в качестве аргумента, поскольку существует уникальный анализатор, реализующий синтаксический анализ. Результатом каждого метода является экземпляр класса модели и, наконец, список фильмов. Чтобы проверить имя текущего элемента, мы используем метод getName, а для извлечения вложенного текста мы используем метод nextText . Для атрибутов мы используем метод getAttributeValue, где первый аргумент — это пространство имен (в нашем случае — null), а второй — имя атрибута.
Хватит говорить, давайте посмотрим, как все это переводится в код:
|
001
002
003
004
005
006
007
008
009
010
011
012
013
014
015
016
017
018
019
020
021
022
023
024
025
026
027
028
029
030
031
032
033
034
035
036
037
038
039
040
041
042
043
044
045
046
047
048
049
050
051
052
053
054
055
056
057
058
059
060
061
062
063
064
065
066
067
068
069
070
071
072
073
074
075
076
077
078
079
080
081
082
083
084
085
086
087
088
089
090
091
092
093
094
095
096
097
098
099
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
|
package com.javacodegeeks.android.xml.pull;import java.io.IOException;import java.io.InputStream;import java.net.URL;import java.net.URLConnection;import java.util.ArrayList;import java.util.LinkedList;import java.util.List;import org.xmlpull.v1.XmlPullParser;import org.xmlpull.v1.XmlPullParserException;import org.xmlpull.v1.XmlPullParserFactory;import android.app.Activity;import android.os.Bundle;import android.util.Log;import com.javacodegeeks.android.xml.pull.model.Image;import com.javacodegeeks.android.xml.pull.model.Movie;public class XmlPullParserActivity extends Activity { private static final String xmlUrl = private final String TAG = getClass().getSimpleName(); @Override public void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.main); try { List<Movie> movies = parseFromUrl(); for (Movie movie : movies) { Log.d(TAG, "Movie:"+movie); } } catch (Exception e) { Log.e(TAG, "Error while parsing", e); } } private List<Movie> parseFromUrl() throws XmlPullParserException, IOException { List<Movie> moviesList = null; XmlPullParserFactory factory = XmlPullParserFactory.newInstance(); factory.setNamespaceAware(false); XmlPullParser parser = factory.newPullParser(); URL url = new URL(xmlUrl); URLConnection ucon = url.openConnection(); InputStream is = ucon.getInputStream(); parser.setInput(is, null); parser.nextTag(); parser.nextTag(); parser.nextTag(); parser.nextTag(); parser.nextText(); parser.nextTag(); moviesList = parseMovies(parser); return moviesList; } private List<Movie> parseMovies(XmlPullParser parser) throws XmlPullParserException, IOException { List<Movie> moviesList = new LinkedList<Movie>(); Log.d(TAG, "parseMovies tag " + parser.getName()); while (parser.nextTag() == XmlPullParser.START_TAG) { Log.d(TAG, "parsing movie"); Movie movie = parseMovie(parser); moviesList.add(movie); } return moviesList; } private Movie parseMovie(XmlPullParser parser) throws XmlPullParserException, IOException { Movie movie = new Movie(); Log.d(TAG, "parseMovie tag " + parser.getName()); while (parser.nextTag() == XmlPullParser.START_TAG) { if (parser.getName().equals("name")) { movie.name = parser.nextText(); } else if (parser.getName().equals("score")) { movie.score = parser.nextText(); } else if (parser.getName().equals("images")) { Image image = parseImage(parser); movie.imagesList = new ArrayList<Image>(); movie.imagesList.add(image); } else if (parser.getName().equals("version")) { movie.version = parser.nextText(); } else { parser.nextText(); } } return movie; } private Image parseImage(XmlPullParser parser) throws XmlPullParserException, IOException { Image image = new Image(); Log.d(TAG, "parseImage tag " + parser.getName()); while (parser.nextTag() == XmlPullParser.START_TAG) { if (parser.getName().equals("image")) { image.type = parser.getAttributeValue(null, "type"); image.url = parser.getAttributeValue(null, "url"); image.size = parser.getAttributeValue(null, "size"); image.width = Integer.parseInt(parser.getAttributeValue(null, "width")); image.height = Integer.parseInt(parser.getAttributeValue(null, "height")); } parser.next(); } return image; } } |
Код довольно прост, просто помните, что мы используем подход «детализации», чтобы проанализировать более глубокий элемент (фильмы? Фильмы? Изображения). Обратите внимание, что в методе разбора Movie мы включили только некоторые поля для краткости. Кроме того, не забудьте вызвать метод parser.nextText (), чтобы разрешить анализатору перемещать и извлекать следующий тег (иначе вы получите некоторые неприятные исключения, поскольку текущее событие не будет иметь тип START_TAG ).
Запустите конфигурацию проекта еще раз и убедитесь, что LogCat содержит правильные операторы отладки:
Это оно! Возможности синтаксического анализа XML Pull прямо в ваше приложение для Android. Вы можете скачать проект Eclipse, созданный для этой статьи, здесь .
- Серия «Android Full Tutorial»
- Android-приложение для преобразования текста в речь
- Обратное геокодирование Android с помощью Yahoo API — PlaceFinder
- Приложение для определения местоположения Android — GPS местоположение
- Установите ОС Android на свой компьютер с VirtualBox
- Охватывая Android-удивительность: краткий обзор