С технологическим прогрессом мы находимся в точке, где наши устройства могут использовать свои встроенные камеры для точной идентификации и маркировки изображений с использованием предварительно обученного набора данных. Вы также можете обучать свои собственные модели, но в этом руководстве мы будем использовать модель с открытым исходным кодом для создания приложения для классификации изображений.
Я покажу вам, как создать приложение, которое может идентифицировать изображения. Мы начнем с пустого проекта XCode и внедрим распознавание изображений на основе машинного обучения по одному шагу за раз.
Начиная
Версия XCode
Прежде чем мы начнем, убедитесь, что на вашем Mac установлена последняя версия Xcode. Это очень важно, потому что Core ML будет доступен только на Xcode 9 или новее. Вы можете проверить свою версию, открыв Xcode и перейдя в Xcode > About Xcode на верхней панели инструментов.
Если ваша версия Xcode старше, чем Xcode 9, вы можете зайти в Mac App Store и обновить ее, или, если у вас ее нет, загрузить ее бесплатно.
Пример проекта
Новый проект
После того, как вы убедитесь, что у вас есть правильная версия Xcode, вам нужно будет создать новый проект Xcode.
Запустите Xcode и нажмите « Создать новый проект XCode».
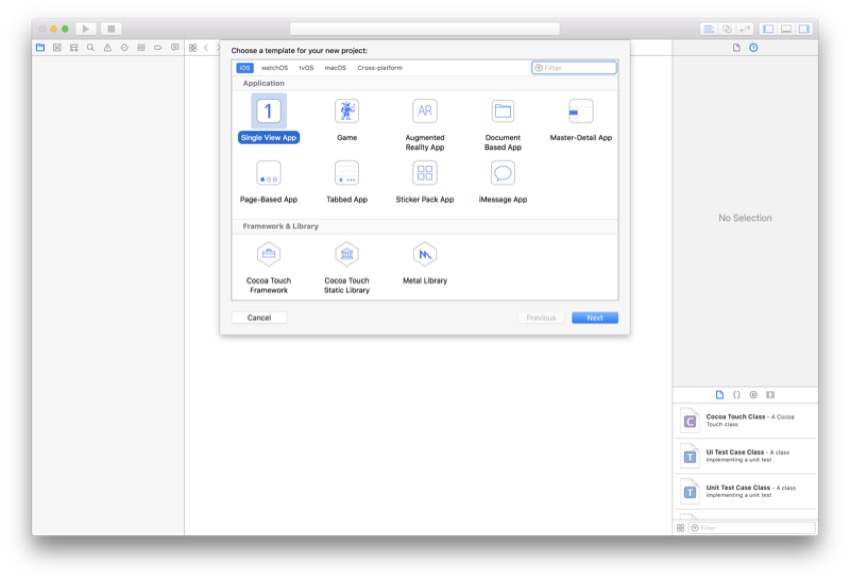
Затем вам нужно будет выбрать шаблон для вашего нового проекта XCode. Обычно используется приложение Single View , поэтому выберите его и нажмите кнопку « Далее».
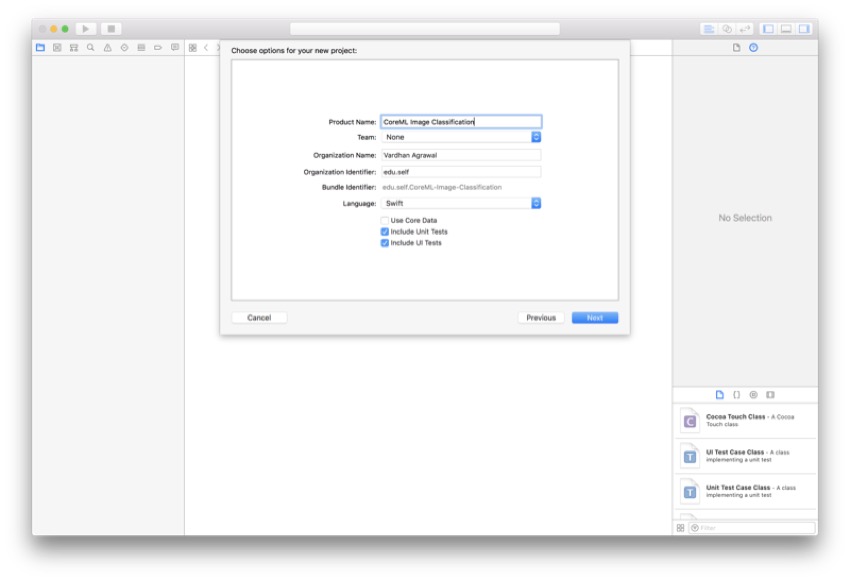
Вы можете назвать свой проект как угодно, но я буду называть мою CoreML Image Classification. Для этого проекта мы будем использовать Swift, поэтому убедитесь, что он выбран в раскрывающемся списке « Язык» .
Подготовка к отладке
Подключение iPhone
Поскольку Xcode Simulator не имеет камеры, вам нужно подключить свой iPhone. К сожалению, если у вас нет iPhone, вам понадобится его взять, чтобы иметь возможность следовать этому руководству (и другим приложениям, связанным с камерой). Если у вас уже есть iPhone, подключенный к Xcode, вы можете перейти к следующему шагу.
Отличная новая функция в Xcode 9 заключается в том, что вы можете отлаживать свое приложение по беспроводной связи на устройстве, поэтому давайте потратим время, чтобы настроить это сейчас:
В верхней строке меню выберите « Окно» > « Устройства и симуляторы» . В появившемся окне убедитесь, что устройства выбраны сверху.
Теперь подключите устройство с помощью кабеля молнии. Это должно привести к тому, что ваше устройство появится в левой панели окна « Устройства и симуляторы» . Просто щелкните свое устройство и установите флажок Подключаться через сеть .
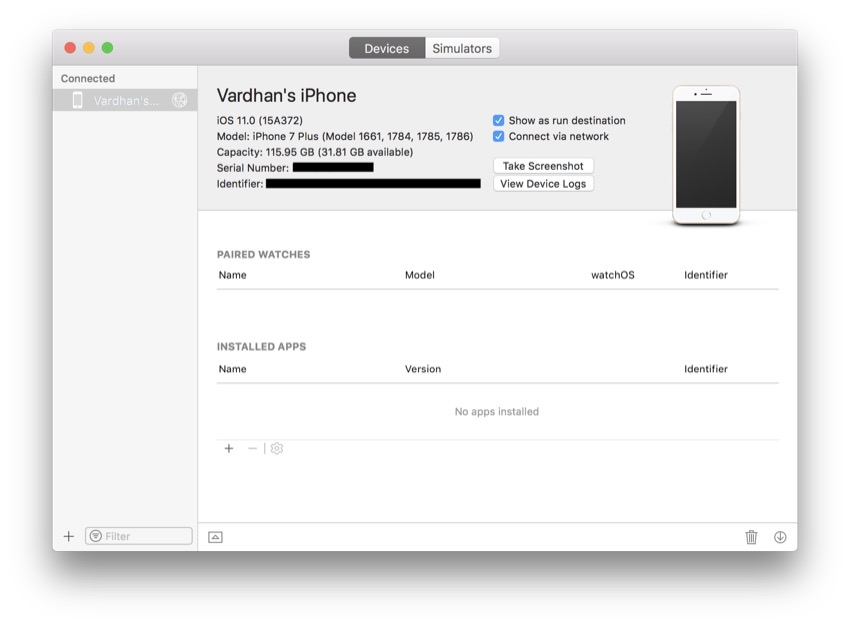
Теперь вы сможете выполнять беспроводную отладку на этом iPhone для всех будущих приложений. Чтобы добавить другие устройства, вы можете выполнить аналогичный процесс.
Выбор симулятора
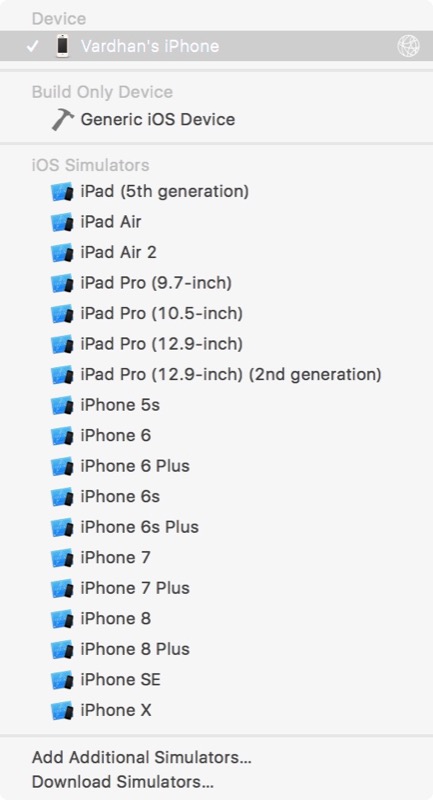
Если вы хотите, наконец, использовать свой iPhone для отладки, просто выберите его в раскрывающемся списке рядом с кнопкой « Выполнить» . Рядом с ним должен появиться значок сети, показывающий, что он подключен для беспроводной отладки. Я выбрал iPhone от Vardhan, но вам нужно выбрать конкретное устройство.
Дайвинг глубже
Теперь, когда вы создали свой проект и настроили свой iPhone в качестве симулятора, мы немного углубимся и начнем программировать приложение для классификации изображений в реальном времени.
Подготовка вашего проекта
Получение модели
Чтобы начать создавать приложение для классификации изображений Core ML, сначала необходимо получить модель Core ML с веб-сайта Apple. Как я упоминал ранее, вы также можете тренировать свои собственные модели, но это требует отдельного процесса. Если вы перейдете к нижней части сайта Apple по машинному обучению , вы сможете выбрать и загрузить модель.
В этом руководстве я буду использовать модель MobileNet.mlmodel , но вы можете использовать любую модель, если вы знаете ее имя и можете убедиться, что она заканчивается на .mlmodel .
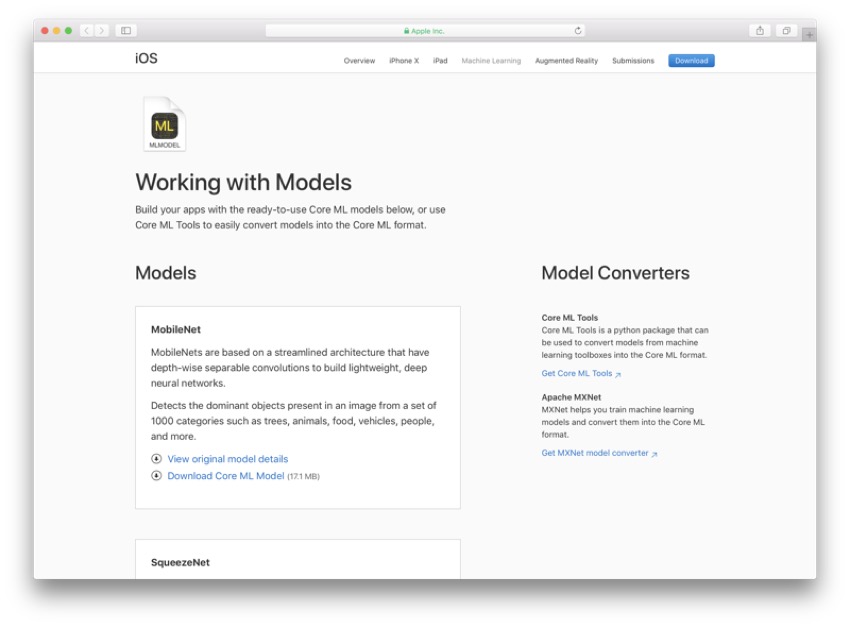
Импорт библиотек
Есть пара фреймворков, которые вам нужно импортировать вместе с обычными UIKit . Вверху файла убедитесь, что присутствуют следующие операторы импорта:
|
1
2
3
|
import UIKit
import AVKit
import Vision
|
Нам понадобится AVKit потому что мы будем создавать AVCaptureSession для отображения прямой трансляции при классификации изображений в реальном времени. Кроме того, поскольку для этого используется компьютерное зрение, нам необходимо импортировать инфраструктуру Vision .
Разработка вашего пользовательского интерфейса
Важной частью этого приложения является отображение меток данных классификации изображений, а также прямой трансляции видео с камеры устройства. Чтобы приступить к разработке вашего пользовательского интерфейса, перейдите к файлу Main.storyboard .
Добавление представления изображения
Отправляйтесь в библиотеку объектов и найдите представление изображений . Просто перетащите его на свой View Controller, чтобы добавить его. Если хотите, вы также можете добавить изображение-заполнитель, чтобы получить общее представление о том, как будет выглядеть приложение при его использовании.
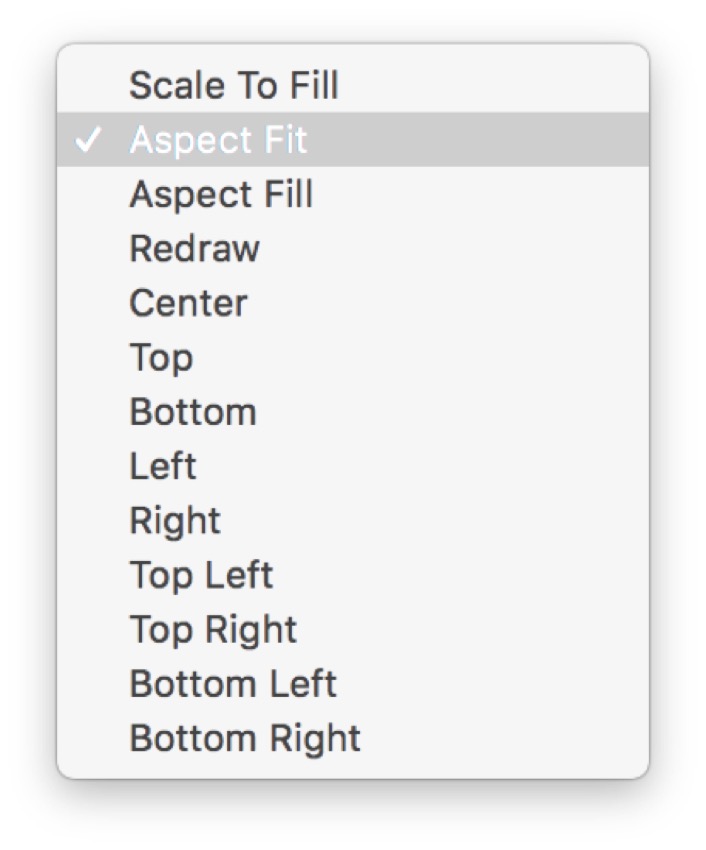
Если вы решили использовать изображение-заполнитель, убедитесь, что для параметра « Режим содержимого» установлено значение « Подгонка по размеру» и установлен флажок « Зарезать границы» . Таким образом, изображение не будет выглядеть растянутым и не будет отображаться за пределами поля UIImageView .
Вот как должна выглядеть ваша раскадровка:
Добавление представления
Вернитесь в библиотеку объектов , найдите вид и перетащите его на свой контроллер вида. Это послужит хорошим фоном для наших ярлыков, так что они не будут скрыты в отображаемом изображении. Мы сделаем этот вид полупрозрачным, чтобы часть слоя предварительного просмотра оставалась видимой (это просто приятный штрих для пользовательского интерфейса приложения).
Перетащите его в нижнюю часть экрана, чтобы он коснулся контейнера с трех сторон. Неважно, какую высоту вы выберете, потому что здесь мы установим для этого ограничения.
Добавление ярлыков
Это, пожалуй, самая важная часть нашего пользовательского интерфейса. Нам нужно отобразить, что наше приложение считает объектом, и насколько оно действительно (уровень достоверности). Как вы уже догадались, вам нужно перетащить две метки из библиотеки объектов в представление, которое мы только что создали. Перетащите эти ярлыки где-то рядом с центром, сложенными друг на друга.
Для верхней метки перейдите в инспектор атрибутов и нажмите кнопку T рядом со стилем и размером шрифта и во всплывающем окне выберите System в качестве шрифта . Чтобы отличить это от метки доверия, выберите Черный как стиль. Наконец, измените размер до 24 .
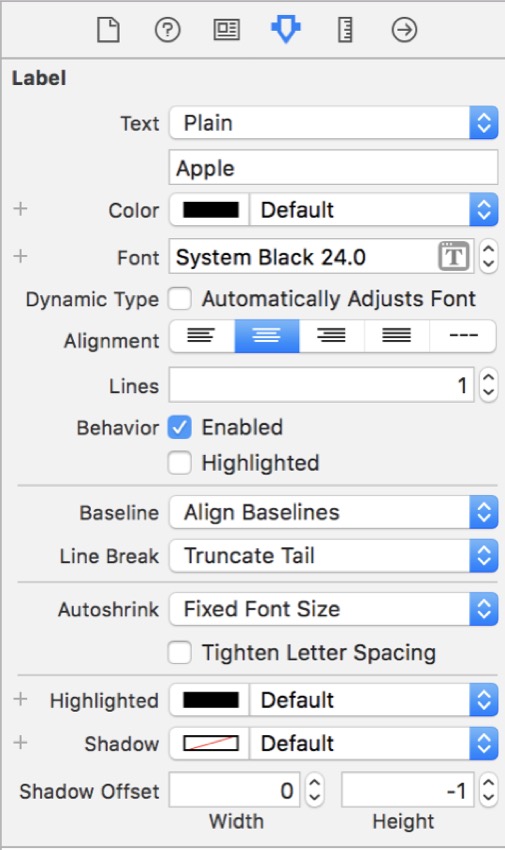
Для нижнего ярлыка выполните те же шаги, но вместо того, чтобы выбрать Черный в качестве стиля , выберите Обычный, а для размера выберите 17 .
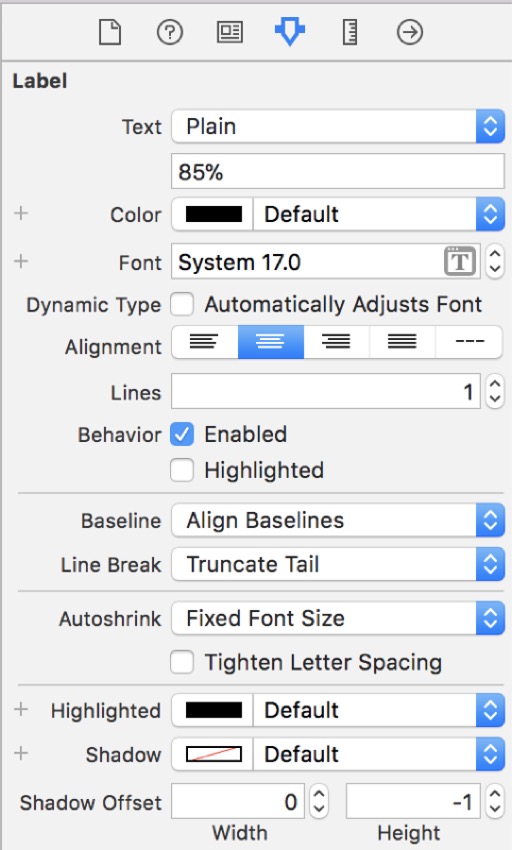
Изображение ниже показывает, как ваш Раскадровка должна выглядеть, когда вы добавили все эти виды и метки. Не беспокойтесь, если они не такие же, как у вас; мы добавим к ним ограничения на следующем шаге.
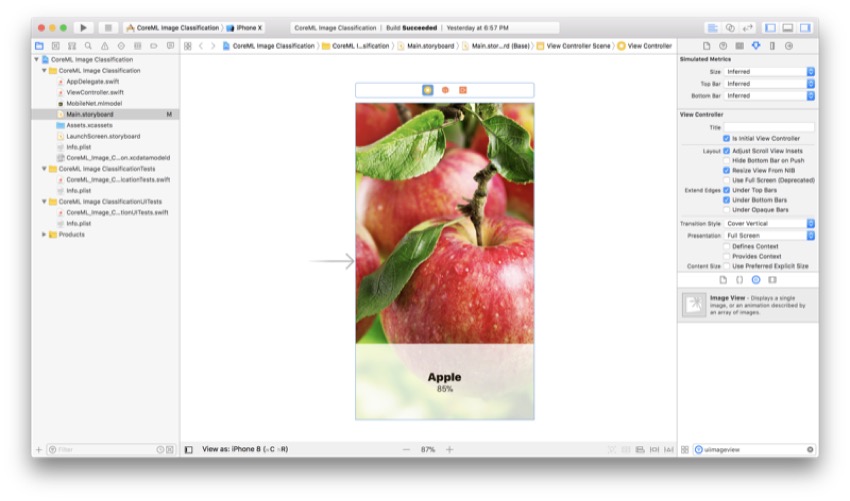
Добавление ограничений
Чтобы приложение работало на экранах разных размеров, важно добавить ограничения. Этот шаг не имеет решающего значения для остальной части приложения, но настоятельно рекомендуется делать это во всех приложениях iOS.
Ограничения просмотра изображений
Первое, что нужно ограничить — это наш UIImageView . Для этого выберите вид изображения и откройте меню «Закрепление» на нижней панели инструментов (это выглядит как квадрат с ограничениями и второй справа). Затем вам нужно добавить следующие значения:
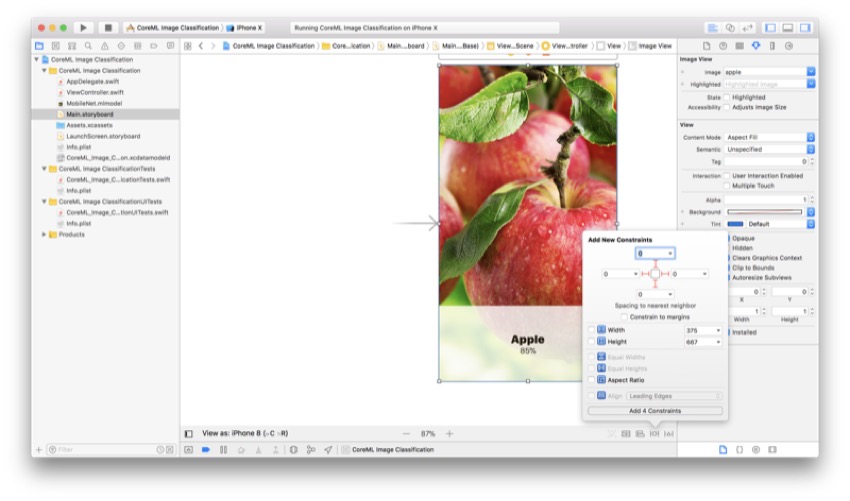
Прежде чем продолжить, убедитесь, что флажок « Ограничить поля» не установлен, так как это создаст разрыв между экраном и фактическим изображением. Затем нажмите Enter . Теперь ваш UIImageView находится в центре экрана, и он должен выглядеть правильно на всех размерах устройства.
Просмотреть ограничения
Теперь следующим шагом будет ограничение представления, на котором появляются метки. Выберите вид, а затем снова перейдите в меню Pin . Добавьте следующие значения:
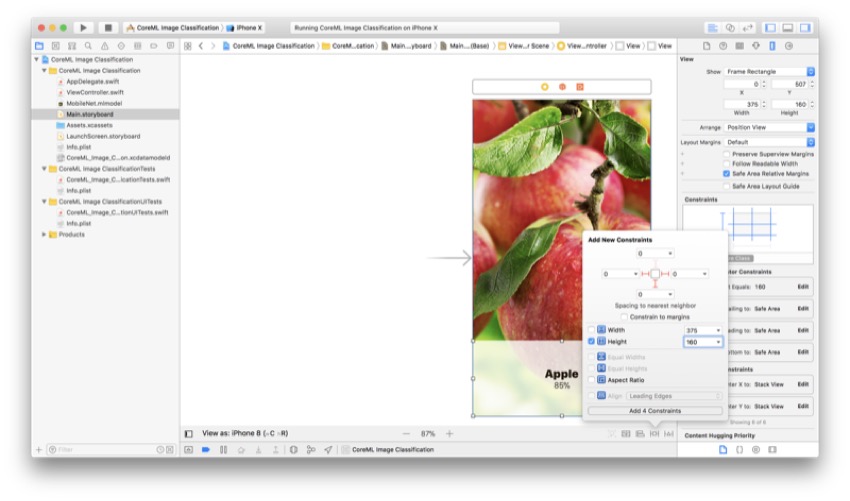
Теперь просто нажмите Enter, чтобы сохранить значения. Ваш вид теперь ограничен нижней частью экрана.
Ограничения метки
Поскольку представление теперь ограничено, вы можете добавить ограничения к меткам относительно вида вместо экрана. Это полезно, если позже вы решите изменить положение меток или вида.
Выберите обе метки и поместите их в вид стека. Если вы не знаете, как это сделать, вам просто нужно нажать кнопку (вторая слева), которая выглядит как стопка книг со стрелкой вниз. Затем вы увидите, что кнопки становятся одним выбираемым объектом.
Нажмите на ваш вид стека, а затем нажмите на меню выравнивания (третье слева) и убедитесь, что установлены следующие флажки:
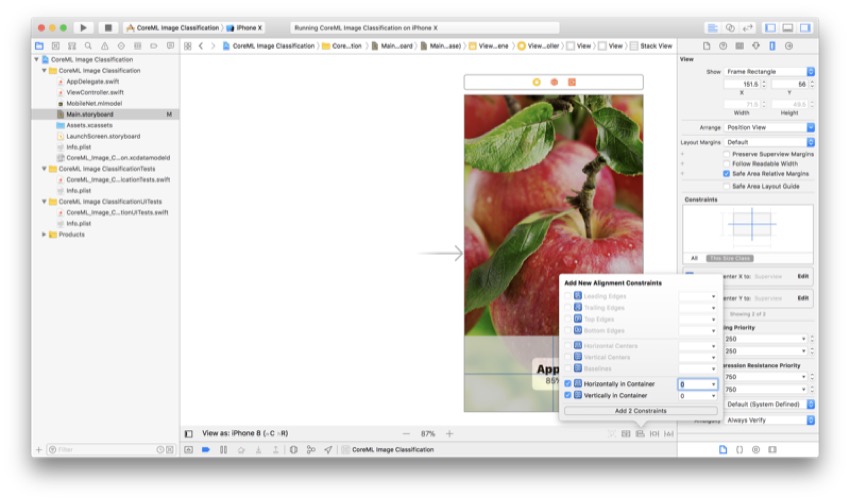
Теперь нажмите Enter. Ваши метки должны быть центрированы на виде из предыдущего шага, и теперь они будут одинаковыми на всех размерах экрана.
Интерфейсные магазины
Последним шагом в пользовательском интерфейсе будет подключение элементов к вашему ViewController() . Просто откройте Ассистентский редактор, а затем нажмите Control-Click и перетащите каждый элемент в начало вашего класса внутри ViewController.swift . Вот что я буду называть их в этом уроке:
-
UILabel:objectLabel -
UILabel:confidenceLabel -
UIImageView:imageView
Конечно, вы можете называть их как угодно, но эти имена вы найдете в моем коде.
Подготовка сессии захвата
Для прямой трансляции видео потребуется AVCaptureSession , поэтому давайте создадим его сейчас. Мы также будем отображать вход нашей камеры пользователю в режиме реального времени. Создание сеанса захвата является довольно длительным процессом, и важно, чтобы вы понимали, как это сделать, потому что он будет полезен для любой другой разработки, которую вы выполняете, используя встроенную камеру на любом из устройств Apple.
Расширение класса и функция
Для начала мы можем создать расширение класса, а затем привести его в соответствие с протоколом AVCaptureVideoDataOutputSampleBufferDelegate . Вы можете легко сделать это в реальном классе ViewController , но мы используем лучшие практики, чтобы код был аккуратным и организованным (именно так вы и поступили бы с производственными приложениями).
Чтобы мы могли вызвать это внутри viewDidLoad() , нам нужно создать функцию с именем setupSession() которая не принимает никаких параметров. Вы можете назвать это как угодно, но помните об именах, когда мы вызовем этот метод позже.
Когда вы закончите, ваш код должен выглядеть следующим образом:
|
1
2
3
4
5
6
|
// MARK: — AVCaptureSession
extension ViewController: AVCaptureVideoDataOutputSampleBufferDelegate {
func setupSession() {
// Your code goes here
}
}
|
Сеанс ввода и захвата устройства
Первый шаг в создании сеанса захвата — проверить, есть ли на устройстве камера. Другими словами, не пытайтесь использовать камеру, если камеры нет. Затем нам нужно создать фактическую сессию захвата.
Добавьте следующий код в ваш setupSession() :
|
1
2
3
4
5
|
guard let device = AVCaptureDevice.default(for: .video) else { return }
guard let input = try?
let session = AVCaptureSession()
session.sessionPreset = .hd4K3840x2160
|
Здесь мы используем оператор guard let чтобы проверить, есть ли на устройстве ( AVCaptureDevice ) камера. Когда вы пытаетесь получить камеру устройства, вы также должны указать mediaType , который в данном случае является .video .
Затем мы создаем AVCaptureDeviceInput , который является входом, который доставляет медиа с устройства в сеанс захвата.
Наконец, мы просто создаем экземпляр класса AVCaptureSession , а затем назначаем его переменной с именем session . Мы настроили битрейт и качество сессии Сверхвысокое разрешение (UHD), которое составляет 3840 на 2160 пикселей. Вы можете поэкспериментировать с этим параметром, чтобы увидеть, что работает для вас.
Предварительный просмотр слоя и вывода
Следующим шагом в настройке AVCaptureSession является создание слоя предварительного просмотра, где пользователь может видеть входные данные с камеры. Мы добавим это в UIImageView мы создали ранее в нашей раскадровке. Однако самая важная часть — это создание выходных данных для модели Core ML для последующей обработки в этом руководстве, что мы и сделаем на этом шаге.
Добавьте следующий код прямо под кодом из предыдущего шага:
|
1
2
3
4
5
6
7
|
et previewLayer = AVCaptureVideoPreviewLayer(session: session)
previewLayer.frame = view.frame
imageView.layer.addSublayer(previewLayer)
let output = AVCaptureVideoDataOutput()
output.setSampleBufferDelegate(self, queue: DispatchQueue(label: «videoQueue»))
session.addOutput(output)
|
Сначала мы создаем экземпляр класса AVCaptureVideoPreviewLayer , а затем инициализируем его сеансом, который мы создали на предыдущем шаге. После того, как это сделано, мы присваиваем его переменной с именем previewLayer . Этот слой используется для отображения входных данных с камеры.
Далее мы сделаем слой предварительного просмотра заполненным на весь экран, установив размеры кадра в соответствии с размерами вида. Таким образом, желаемый вид будет сохраняться для всех размеров экрана. Чтобы фактически показать слой предварительного просмотра, мы добавим его в качестве UIImageView который мы создали, когда создавали пользовательский интерфейс.
Теперь важная часть: мы создаем экземпляр класса AVCaptureDataOutput и присваиваем его переменной с именем output .
Вход и начало сеанса
Наконец, мы закончили с нашей сессией захвата. Все, что осталось сделать до фактического кода Core ML, это добавить вход и начать сеанс захвата.
Добавьте следующие две строки кода непосредственно под предыдущим шагом:
|
1
2
3
4
|
// Sets the input of the AVCaptureSession to the device’s camera input
session.addInput(input)
// Starts the capture session
session.startRunning()
|
Это добавляет вход, который мы создали ранее, в AVCaptureSession , потому что до этого мы только создавали вход и не добавляли его. Наконец, эта строка кода запускает сеанс, который мы так долго создавали.
Интеграция модели Core ML
Мы уже загрузили модель, поэтому следующим шагом будет ее использование в нашем приложении. Итак, начнем с его использования для классификации изображений.
Метод делегата
Для начала вам нужно добавить следующий метод делегата в ваше приложение:
|
1
2
3
|
func captureOutput(_ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) {
// Your code goes here
}
|
Этот метод делегата запускается при записи нового видеокадра. В нашем приложении это происходит каждый раз, когда кадр записывается через нашу прямую трансляцию видео (скорость зависит исключительно от аппаратного обеспечения, на котором работает приложение).
Пиксельный буфер и модель
Теперь мы будем превращать изображение (один кадр из прямой трансляции) в пиксельный буфер, который распознается моделью. Благодаря этому мы сможем позже создать VNCoreMLRequest .
Добавьте следующие две строки кода в метод делегата, который вы создали ранее:
|
1
2
|
guard let pixelBuffer: CVPixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else { return }
guard let model = try?
|
Сначала мы создаем пиксельный буфер (формат, который принимает Core ML) из аргумента, переданного через метод делегата, а затем назначаем его переменной с именем pixelBuffer . Затем мы присваиваем нашу модель MobileNet константе, называемой model .
Обратите внимание, что оба они созданы с использованием операторов guard let , и что функция возвратит, если любое из этих значений будет nil .
Создание запроса
После выполнения двух предыдущих строк кода мы точно знаем, что у нас есть пиксельный буфер и модель. Следующим шагом будет создание VNCoreMLRequest с использованием их обоих.
Прямо под предыдущим шагом вставьте следующие строки кода в метод делегата:
|
1
2
3
|
let request = VNCoreMLRequest(model: model) { (data, error) in {
// Your code goes here
}
|
Здесь мы создаем константу с именем request и присваиваем ей возвращаемое значение метода VNCoreMLRequest при передаче в нее нашей модели.
Получение и сортировка результатов
Мы почти закончили! Все, что нам нужно сделать сейчас, это получить наши результаты (то, что модель считает нашим изображением), а затем отобразить их пользователю.
Добавьте следующие две строки кода в обработчик завершения вашего запроса:
|
1
2
3
4
|
// Checks if the data is in the correct format and assigns it to results
guard let results = data.results as?
// Assigns the first result (if it exists) to firstObject
guard let firstObject = results.first else { return }
|
Если результаты из данных (из обработчика завершения запроса) доступны в виде массива VNClassificationObservations , эта строка кода получает первый объект из массива, который мы создали ранее. Затем он будет присвоен константе с именем firstObject . Первый объект в этом массиве — тот, для которого механизм распознавания изображений имеет наибольшее доверие.
Отображение данных и обработка изображений
Помните, когда мы создали две метки (доверие и объект)? Теперь мы будем использовать их для отображения того, что модель считает изображением.
Добавьте следующие строки кода после предыдущего шага:
|
1
2
3
4
|
if firstObject.confidence * 100 >= 50 {
self.objectLabel.text = firstObject.identifier.capitalized
self.confidenceLabel.text = String(firstObject.confidence * 100) + «%»
}
|
Оператор if гарантирует, что алгоритм по крайней мере на 50% уверен в своей идентификации объекта. Затем мы просто устанавливаем firstObject в качестве текста objectLabel потому что мы знаем, что уровень достоверности достаточно высок. Мы просто отобразим процент достоверности, используя текстовое свойство confidenceLabel . Поскольку firstObject.confidence представляется в виде десятичной дроби, нам нужно умножить на 100, чтобы получить процент.
Последнее, что нужно сделать, это обработать изображение по алгоритму, который мы только что создали. Для этого вам необходимо набрать следующую строку кода непосредственно перед выходом captureOutput(_:didOutput:from:) метода делегата captureOutput(_:didOutput:from:) :
|
1
|
try?
|
Вывод
Концепции, которые вы изучили в этом руководстве, могут быть применены ко многим видам приложений. Я надеюсь, вам понравилось учиться классифицировать изображения с помощью телефона. Хотя это может быть еще не идеально, вы можете обучать свои собственные модели в будущем, чтобы быть более точным.
Вот как приложение должно выглядеть, когда оно готово:

Пока вы здесь, ознакомьтесь с некоторыми другими нашими статьями о машинном обучении и разработке приложений для iOS!
-
 XcodeЧто нового в Xcode 9?
XcodeЧто нового в Xcode 9? -
iOS SDKОбновление вашего приложения для iOS 11
-
iOS SDKПередача данных между контроллерами в Swift