Машинное обучение, несомненно, было одной из самых горячих тем за последний год, и компании всех видов пытаются сделать свои продукты более интеллектуальными, чтобы улучшить взаимодействие с пользователем и дифференцировать свои предложения.
Теперь Apple вступила в гонку, чтобы обеспечить машинное обучение для разработчиков. Core ML позволяет разработчикам добавлять глубокое машинное обучение в свои приложения.
Просто взглянув на ваше устройство iOS, вы увидите машинное обучение, встроенное почти в каждое системное приложение, наиболее очевидным из которых является Siri. Например, при отправке текстовых сообщений Apple использует обработку естественного языка (NLP), чтобы либо предсказать ваше следующее слово, либо разумно предложить исправление при наборе слова. Ожидайте, что машинное обучение и НЛП продолжат становиться все более и более укоренившимися в нашем использовании технологий, от поиска до обслуживания клиентов.
Цели этого урока
Этот учебник познакомит вас с подмножеством машинного обучения: Natural Language Processing (NLP). Мы рассмотрим, что такое НЛП и почему его стоит реализовать, прежде чем рассматривать различные уровни или схемы, составляющие НЛП. Это включает:
- языковая идентификация
- лексический анализ
- часть речевой идентификации
- признание именованного объекта
Изучив теорию НЛП, мы применим наши знания на практике, создав простой клиент Twitter, который анализирует твиты. Идите вперед и клонируйте репозиторий GitHub из учебника и посмотрите.
Предполагаемые знания
В этом руководстве предполагается, что вы опытный разработчик iOS. Хотя мы будем работать с машинным обучением, вам не нужно иметь какой-либо опыт в этой области. Кроме того, в то время как другие компоненты Core ML требуют некоторых знаний Python, мы не будем работать с какими-либо аспектами, связанными с Python, с NLP.
Введение в машинное обучение и НЛП
Цель машинного обучения состоит в том, чтобы компьютер мог выполнять задачи, не будучи явно запрограммирован на это, — способность мыслить или интерпретировать самостоятельно. Известный современный сценарий использования — автономное вождение: автомобили могут визуально интерпретировать окружающую среду и вести машину без посторонней помощи.
Помимо визуального распознавания, машинное обучение также включает распознавание речи, интеллектуальный веб-поиск и многое другое. Поскольку Google, Microsoft, Facebook и IBM находятся на переднем крае популяризации машинного обучения и делают его доступным для обычных разработчиков, Apple также решила двигаться в этом направлении и упростить включение машинного обучения в сторонние приложения.
Core ML — новинка в семействе SDK от Apple, представленная как часть iOS 11, позволяющая разработчикам реализовывать широкий спектр режимов машинного обучения и типов уровней глубокого обучения.
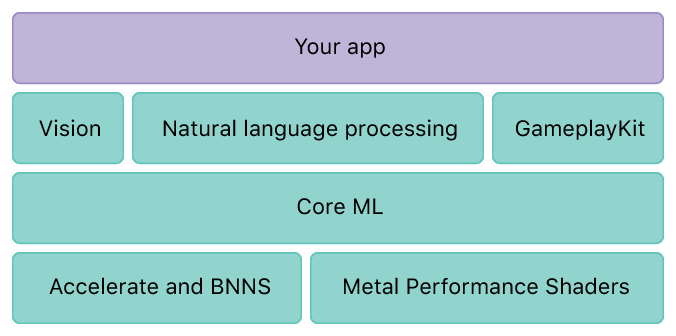
Обработка естественного языка (NLP) логически находится в структуре Core ML вместе с двумя другими мощными библиотеками, Vision и GameplayKit . Vision предоставляет разработчикам возможность реализовать машинное обучение компьютерному зрению для выполнения таких задач, как обнаружение лиц, ориентиров и других объектов, в то время как GameplayKit предоставляет разработчикам игр инструменты для разработки игр и определенных функций игрового процесса.
В этом уроке мы сосредоточимся на обработке естественного языка.
Обработка естественного языка (НЛП)
Обработка естественного языка — это наука, позволяющая анализировать и понимать текст, разбивать предложения и слова для выполнения таких задач, как анализ настроений, извлечение отношений, прохождение, обобщение текста или предложений и многое другое. Проще говоря, НЛП — это способность компьютеров понимать человеческий язык в его естественной устной или письменной форме.
Возможность извлекать и инкапсулировать слова и предложения контекстуально позволяет улучшить интеграцию между пользователями и устройствами, или даже между двумя устройствами, посредством значимых кусков контента. Вскоре мы подробно рассмотрим каждый из этих компонентов, но сначала важно понять, почему вы хотите внедрить NLP.
Зачем реализовывать обработку естественного языка?
Поскольку компании по-прежнему полагаются на хранение и обработку больших данных, NLP позволяет интерпретировать свободный и неструктурированный текст, делая его анализируемым. С большим количеством информации, хранящейся в неструктурированных текстовых файлах — например, в медицинских записях — НЛП может просеивать множество данных и предоставлять данные о контексте, намерениях и даже настроениях.
Помимо возможности анализировать устный и письменный текст, NLP теперь стала движущей силой ботов — от тех в Slack, с которыми вы можете почти полностью общаться с людьми, до инструментов для обслуживания клиентов. Если вы зайдете на веб-сайт поддержки Apple и попросите поговорить со службой поддержки, вам будет представлен веб-бот, который постарается указать вам правильное направление в зависимости от заданного вами вопроса. Это помогает клиентам чувствовать себя понятыми в режиме реального времени, без необходимости говорить с человеком.
Взглянув на спам в электронной почте и фильтры спама, НЛП позволила лучше понимать текст и лучше классифицировать электронные письма с большей уверенностью в их намерениях.
Обобщение — это важный метод НЛП для анализа настроений, который компании хотели бы использовать на данных своих учетных записей в социальных сетях, чтобы отслеживать восприятие продуктов компании.
Приложение Photos на iOS 11 — еще один хороший пример. При поиске фотографий машинное обучение работает на нескольких уровнях. Помимо использования машинного обучения и зрения для распознавания лица и типа фотографии (например, пляж, местоположение), поисковые термины фильтруются через НЛП, и если вы выполняете поиск по слову «пляжи», он также выполняет поиск фотографий, которые содержат описание ». пляж. Это называется лемматизацией, и вы узнаете больше об этом ниже, поскольку мы научимся ценить, насколько мощным является машинное обучение, и тем, насколько легко Apple делает ваши приложения более интеллектуальными.
Благодаря тому, что ваше приложение лучше понимает, например, строку поиска, оно сможет более разумно взаимодействовать с пользователями, понимая смысл поискового запроса, а не воспринимать слово в его буквальном смысле. Используя библиотеку Apple NLP, разработчики могут поддерживать согласованный подход к обработке текста и взаимодействие с пользователем по всей экосистеме Apple, от iOS до macOS, tvOS и watchOS.
Благодаря машинному обучению, выполняемому на устройстве, пользователи получают выгоду от использования процессора и графического процессора устройства для повышения эффективности вычислений вместо доступа к внешним API-интерфейсам машинного обучения. Это позволяет пользовательским данным оставаться на устройстве и уменьшает задержку из-за доступа к сети. Поскольку машинное обучение требует более глубоких знаний о пользователях для выработки предложений и прогнозов, возможности обработки на физическом устройстве и использования дифференциальной конфиденциальности для любых действий, связанных с сетью, вы можете предоставить интеллектуальные, но неинвазивные возможности для ваши пользователи.
Далее мы рассмотрим структуру движка Apple Natural Language Processing.
Представляем NSLinguisticTagger
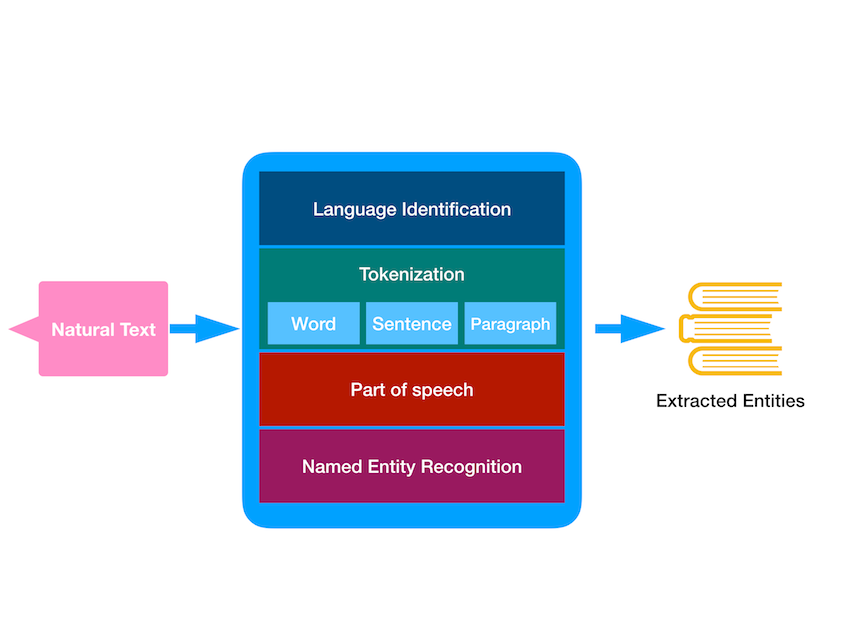
Основополагающий класс NSLinguisticTagger играет центральную роль в анализе и тегировании текста и речи, сегментируя контент на абзацы, предложения и слова, и состоит из следующих схем:
- языковая идентификация
- лексический анализ
- лемматизации
- часть речи (PoS)
- признание именованного объекта
Когда вы инициализируете NSLinguisticTagger , вы передаете NSLinguisticTagScheme вас интересует анализ. Например:
let tagger = NSLinguisticTagger(tagSchemes: [.language, .tokenType, ...], options: 0)
Затем вы должны настроить различные аргументы и свойства, включая передачу входного текста, перед перечислением через NSLinguisticTagger экземпляра NSLinguisticTagger , извлечением сущностей и токенов. Давайте погрузимся глубже и посмотрим, как реализовать каждую из схем, шаг за шагом, начиная со схемы идентификации языка.
Идентификация языка
Первый тип схемы тегов, идентификация языка , пытается идентифицировать язык BCP-47, наиболее заметный на уровне документа, абзаца или предложения. Вы можете получить этот язык, NSLinguisticTagger к свойству NSLinguisticTagger объекта экземпляра NSLinguisticTagger :
|
1
2
3
4
5
|
…
Let tagger = NSLinguisticTagger(tagSchemes: [.language], options: 0)
…
tagger.string = «Some text in a language or two»
let language = tagger.dominantLanguage //ie “en” returned for English.
|
Довольно просто. Далее мы рассмотрим классификацию текста с использованием метода токенизации.
лексемизацию
Токенизация — это процесс разграничения и, возможно, классификации разделов строки входных символов. Полученные токены затем передаются в другую форму обработки. (источник: Википедия )
Взяв блок текста, токенизация будет логически разлагаться и классифицировать этот текст на абзацы, предложения и слова. Мы начнем с установки соответствующей схемы ( .tokenType ) для тегера. В отличие от предыдущей схемы, мы ожидаем нескольких результатов, и нам нужно перечислить возвращаемые теги, как показано в примере ниже:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
let tagger = NSLinguisticTagger(tagSchemes: [.tokenType], options: 0)
tagger.string = textString
let range = NSRange(location: 0, length: textString.utf16.count)
//Setting various options, such as ignoring white spaces and punctuations
let options: NSLinguisticTagger.Options = [.omitPunctuation, .omitWhitespace]
//We enumerate through the tagger, using the properties set above
tagger.enumerateTags(in: range, unit: .word, scheme: .tokenType, options: options) { tag, tokenRange, stop in
let token = (text as NSString).substring(with: tokenRange)
// Handle each token, (ie add to array)
}
|
Теперь у нас есть список слов. Но разве не было бы интересно узнать происхождение этих слов? Так, например, если пользователь ищет такой термин, как «прогулки» или «ходьба», было бы очень полезно получить исходное слово «прогулка» и классифицировать все эти сочетания слов «прогулка» вместе. Это называется лемматизацией, и мы обсудим это позже.
лемматизации
Лемматизация группирует изогнутые формы слова для анализа как единичный элемент, что позволяет вывести предполагаемое значение. По сути, все, что вам нужно помнить, это то, что он выводит словарную форму слова.
Знание словарной формы слова действительно мощно и позволяет вашим пользователям искать с большей «нечеткостью». В предыдущем примере мы рассматриваем пользователя, который ищет термин «ходьба». Без лемматизации вы могли бы возвращать только буквальные упоминания об этом слове, но если бы вы могли рассматривать другие формы того же слова, вы могли бы также получить результаты, в которых упоминается «прогулка».
Аналогично предыдущему примеру, чтобы выполнить лемматизацию, мы бы установили схему в инициализации .lemma на .lemma , прежде чем перечислять тэги:
|
1
2
3
4
5
6
7
|
…
tagger.enumerateTags(in: range, unit: .word, scheme: .lemma, options: options) { tag, tokenRange, stop in
if let lemma = tag?.rawValue {
// Handle each lemma item
}
}
…
|
Далее мы рассмотрим часть речевого тегирования, которая позволяет нам классифицировать блок текста как существительные, глаголы, прилагательные или другие части.
Часть речи (PoS)
Пометка части речи нацелена на то, чтобы связать часть речи с каждым конкретным словом на основе как определения слова, так и контекста (его отношения к смежным и связанным словам). Как элемент НЛП, часть речевого тегирования позволяет нам сосредоточиться на существительных и глаголах, которые могут помочь нам понять намерения и значение текста.
Реализация части речевого тегирования включает в себя настройку свойства tagger для использования .lexicalClass и перечисления таким же образом, как показано в предыдущих примерах. Вы получите разложение вашего предложения на слова с ассоциативным тегом для каждого, классифицируя слово как принадлежащее существительному, предлогу, глаголу, прилагательному или определителю. Для получения дополнительной информации о том, что они означают, обратитесь к документации Apple, касающейся лексических типов .
Другим процессом в стеке NLP от Apple является распознавание именованных сущностей, которое разбивает блоки текста, извлекая конкретные типы сущностей, которые нас интересуют, такие как имена, местоположения, организации и люди. Давайте посмотрим на это дальше.
Признание именованного субъекта
Распознавание именованных объектов — это один из самых мощных компонентов тегов классификации НЛП, позволяющий вам классифицировать именованные объекты или объекты реального мира из вашего предложения (например, местоположения, люди, имена). Как пользователь iPhone, вы уже видели это в действии, когда отправляли текстовые сообщения своим друзьям, и наблюдали выделенные ключевые слова, такие как номера телефонов, имена или даты.
Вы можете реализовать распознавание именованных объектов так же, как и в других наших примерах, установив схему тегов в .nameType и циклически перебирая тегировщик в определенном диапазоне.
Затем вы приведете в действие то, что узнали, с помощью простого приложения, которое будет принимать заранее определенный набор твитов, когда вы будете вводить каждый твит через конвейер НЛП.
Реализация обработки естественного языка
Чтобы подвести итоги, рассмотрим простое клиентское приложение Twitter, которое извлекает пять твитов в виде таблицы и применяет некоторую обработку NLP для каждого из них.
На следующем снимке экрана мы использовали Распознавание именованных сущностей НЛП, чтобы выделить ключевые слова сущности (организации, местоположения и т. Д.) Красным цветом.
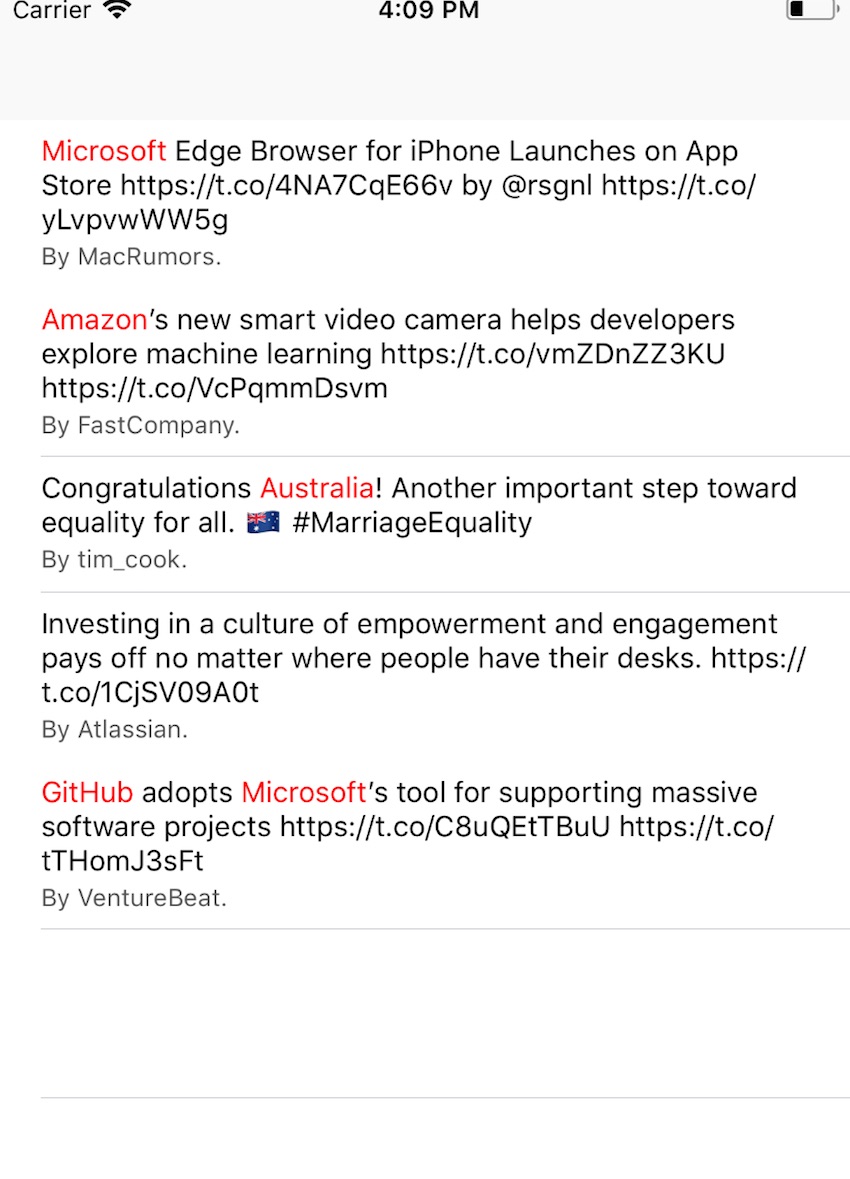
Идите вперед и клонируйте проект TwitterNLPExample из учебного репозитория GitHub и быстро взгляните на код. Класс, который нас больше всего интересует, это TweetsViewController.swift . Давайте посмотрим на его tableView(_ tableView: cellForRowAt) .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
override func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {
// Retrieve the Tweet cell.
let cell = tableView.dequeueReusableCell(withIdentifier: reuseIdentifier, for: indexPath)
// Retrieve the Tweet model from loaded Tweets.
let tweet = tweets[indexPath.row]
cell.textLabel?.text = tweet.text
cell.detailTextLabel?.text = «By \(tweet.author.screenName).»
self.range = NSRange(location:0, length: (tweet.text.utf16.count))
self.detectLanguage(with: cell.textLabel!)
self.getTokenization(with: cell.textLabel!)
self.getNamedEntityRecognition(with: cell.textLabel!)
self.getLemmatization(with: cell.textLabel!)
// Return the Tweet cell.
return cell
}
|
Для каждой ячейки (твит) мы вызываем четыре метода, которые мы вскоре определим:
-
detectLanguage() -
getTokenization() -
getNamedEntityRecognition() -
getLemmatization()
Для каждого из этих методов мы вызываем метод enumerate , передавая схему и текстовую метку для извлечения текста, как мы делаем для идентификации языка:
|
1
2
3
|
func detectLanguage(with textLabel:UILabel) {
let _ = enumerate(scheme: .language, label: textLabel)
}
|
Наконец, функция enumerate — это то, где все действия NLP действительно выполняются, принимая свойства и аргументы, основанные на типе обработки NLP, которую мы намереваемся выполнить, и сохраняя результаты в массивах, чтобы мы могли использовать их позже. Для целей этого примера мы просто выводим результаты на консоль, в целях наблюдения.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
func enumerate(scheme:NSLinguisticTagScheme, label: UILabel) -> [String]?{
var keywords = [String]()
var tokens = [String]()
var lemmas = [String]()
let tags: [NSLinguisticTag] = [.personalName, .placeName, .organizationName]
let tagger = NSLinguisticTagger(tagSchemes: [scheme], options: 0)
tagger.string = label.text
tagger.enumerateTags(in: range!, unit: .word, scheme: scheme, options: options) {
tag, tokenRange, _ in
switch(scheme){
case NSLinguisticTagScheme.lemma:
if let lemma = tag?.rawValue {
lemmas.append(lemma)
}
break
case NSLinguisticTagScheme.language:
print(«Dominant language: \(tagger.dominantLanguage ?? «Undetermined «)»)
break
case NSLinguisticTagScheme.nameType:
if let tag = tag, tags.contains(tag) {
let name = (label.text! as NSString).substring(with: tokenRange)
print(«entity: \(name)»)
keywords.append(name)
}
break
case NSLinguisticTagScheme.lexicalClass:
break
case NSLinguisticTagScheme.tokenType:
if let tagVal = tag?.rawValue {
tokens.append(tagVal.lowercased())
}
break
default:
break
}
}
if (scheme == .nameType){
let keywordAttrString = NSMutableAttributedString(string: tagger.string!, attributes: nil)
for name in keywords{
if let indices = label.text?.indicesOf(string: name){
for i in indices{
let range = NSRange(i..<name.count+i)
keywordAttrString.addAttribute(NSAttributedStringKey.foregroundColor, value: UIColor.red, range: range)
}
label.attributedText = keywordAttrString
}
}
return keywords
}else if (scheme == .lemma){
print(«lemmas \(lemmas)»)
return lemmas
}else if (scheme == .tokenType){
print(«tokens \(tokens)»)
return tokens
}
return nil
}
|
Для .nameType Named Entity Recognition мы берем ключевые слова сущностей, которые мы извлекли, и проходим, чтобы выделить слова, которые соответствуют этим сущностям. Вы могли бы даже сделать шаг вперед и сделать ссылки на эти ключевые слова — возможно, для поиска твитов, соответствующих этим ключевым словам.
Идите вперед, создайте и запустите приложение и посмотрите на результат, обращая особое внимание на леммы и сущности, которые мы извлекли.
Вывод
От Google, использующего Natural Language Processing в своих поисковых системах, до Apple Siri и ботов-мессенджеров Facebook, нет сомнений в том, что эта область растет в геометрической прогрессии. Но НЛП и машинное обучение больше не являются исключительной сферой деятельности крупных компаний. Внедрив Core Core Framework в начале этого года, Apple упростила для повседневных разработчиков, не имеющих глубоких знаний, возможность добавлять интеллект в свои приложения.
В этом руководстве вы увидели, как с помощью нескольких строк кода вы можете использовать Core ML для вывода контекста и намерений из неструктурированных предложений и абзацев, а также для определения доминирующего языка. Мы увидим дальнейшие улучшения в будущих итерациях SDK, но NLP уже обещает стать мощным инструментом, который будет широко использоваться в App Store.
Пока вы здесь, посмотрите другие наши посты о разработке приложений для iOS и машинном обучении!
-
 Машинное обучениеНачните с распознавания изображений в Core ML
Машинное обучениеНачните с распознавания изображений в Core ML -
БезопасностьБезопасное кодирование с параллелизмом в Swift 4
-
iOS SDKОбновление вашего приложения для iOS 11


