В последних постах мы рассмотрели некоторые свойства использования Elasticsearch в качестве хранилища документов для поиска текстового содержимого и геопространственного поиска . В этом посте мы рассмотрим, как его можно использовать для индексации и хранения файлов журналов, очень полезного приложения, которое может помочь разработчикам и операциям в обслуживании приложений.
логирование
При обслуживании больших приложений, которые либо распределены по нескольким узлам, либо состоят из нескольких небольших приложений, поиск событий в файлах журналов может стать утомительным. Возможно, вы уже оказались в ситуации, когда вам нужно найти ошибку и вам необходимо войти на несколько компьютеров и просмотреть несколько файлов журнала. Использование инструментов Linux, таких как grep, может быть забавным, но есть более удобные способы. Elasticsearch и проекты Logstash и Kibana, обычно известные как стек ELK , могут помочь вам в этом.
С помощью стека ELK вы можете централизовать свои журналы, проиндексировав их в Elasticsearch. Таким образом, вы можете использовать Kibana для просмотра всех данных без необходимости входа в систему. Это также может порадовать Operations, поскольку им не нужно предоставлять доступ каждому разработчику, которому необходим доступ к журналам. Поскольку для всех журналов существует единое центральное место, вы можете даже увидеть различные приложения в контексте. Например, вы можете видеть журналы вашего веб-сервера Apache в сочетании с файлами журналов вашего сервера приложений, например Tomcat. Поскольку поиск является основным для того, что делает Elasticsearch, вы сможете найти то, что ищете, еще быстрее.
Наконец, Кибана также может помочь вам стать более активным. Поскольку вся информация доступна в режиме реального времени, у вас также есть визуальное представление о том, что происходит в вашей системе в режиме реального времени. Это может помочь вам быстрее находить проблемы, например, вы видите, что какой-то ресурс начинает выдавать исключения, а ваши клиенты не сообщают об этом вам.
Стек ELK
Для анализа лог-файлов вы можете использовать все три приложения стека ELK: Elasticsearch, Logstash и Kibana. Logstash используется для чтения и обогащения информации из файлов журналов. Elasticsearch используется для хранения всех данных, а Kibana — это интерфейс, предоставляющий информационные панели для просмотра данных.
Логи подаются в Elasticsearch с помощью Logstash, который объединяет различные источники. Kibana используется для просмотра данных в Elasticsearch. Эта настройка имеет то преимущество, что различные части системы обработки файлов журналов могут масштабироваться по-разному. Если вам нужно больше места для хранения данных, вы можете добавить больше узлов в кластер Elasticsearch. Если вам требуется больше вычислительной мощности для файлов журнала, вы можете добавить больше узлов для Logstash.
Logstash
Logstash — это приложение на JRuby, которое может читать входные данные из нескольких источников, изменять их и выдавать на множество выходов. Для запуска Logstash вам необходимо передать ему файл конфигурации, который определяет, где находятся данные и что с ними делать. Конфигурация обычно состоит из секции input и output секции дополнительного filter . Этот пример берет журналы доступа Apache, выполняет некоторую предопределенную обработку и сохраняет их в Elasticsearch:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
input { file { path => "/var/log/apache2/access.log" }}filter { grok { match => { message => "%{COMBINEDAPACHELOG}" } }}output { elasticsearch_http { host => "localhost" }} |
Входной файл читает файлы журнала по указанному пути. В разделе фильтра мы определили фильтр grok, который анализирует неструктурированные данные и структурирует их. Он поставляется с множеством предопределенных шаблонов для разных систем. В этом случае мы используем полный шаблон журнала Apache, но есть и более простой строительный блок, такой как парсинг электронной почты, IP-адресов и дат (что может быть очень забавно во всех различных форматах).
В разделе вывода мы говорим Logstash, что нужно отправить данные в Elasticsearch, используя http. Мы используем сервер на локальном хосте, для большинства реальных установок это будет кластер на отдельных машинах.
Kibana
Теперь, когда у нас есть данные в Elasticsearch, мы хотим посмотреть на них. Kibana — это JavaScript-приложение, которое можно использовать для создания панелей мониторинга. Он обращается к Elasticsearch из браузера, поэтому любой, кто использует Kibana, должен иметь доступ к Elasticsearch.
При использовании его с Logstash вы можете открыть предопределенную панель мониторинга, которая будет извлекать некоторую информацию из вашего индекса. Затем вы можете отобразить диаграммы, карты и таблицы для данных, которые вы проиндексировали. Этот снимок экрана отображает гистограмму и таблицу событий журнала, но есть больше доступных виджетов, таких как карты и круговые диаграммы.
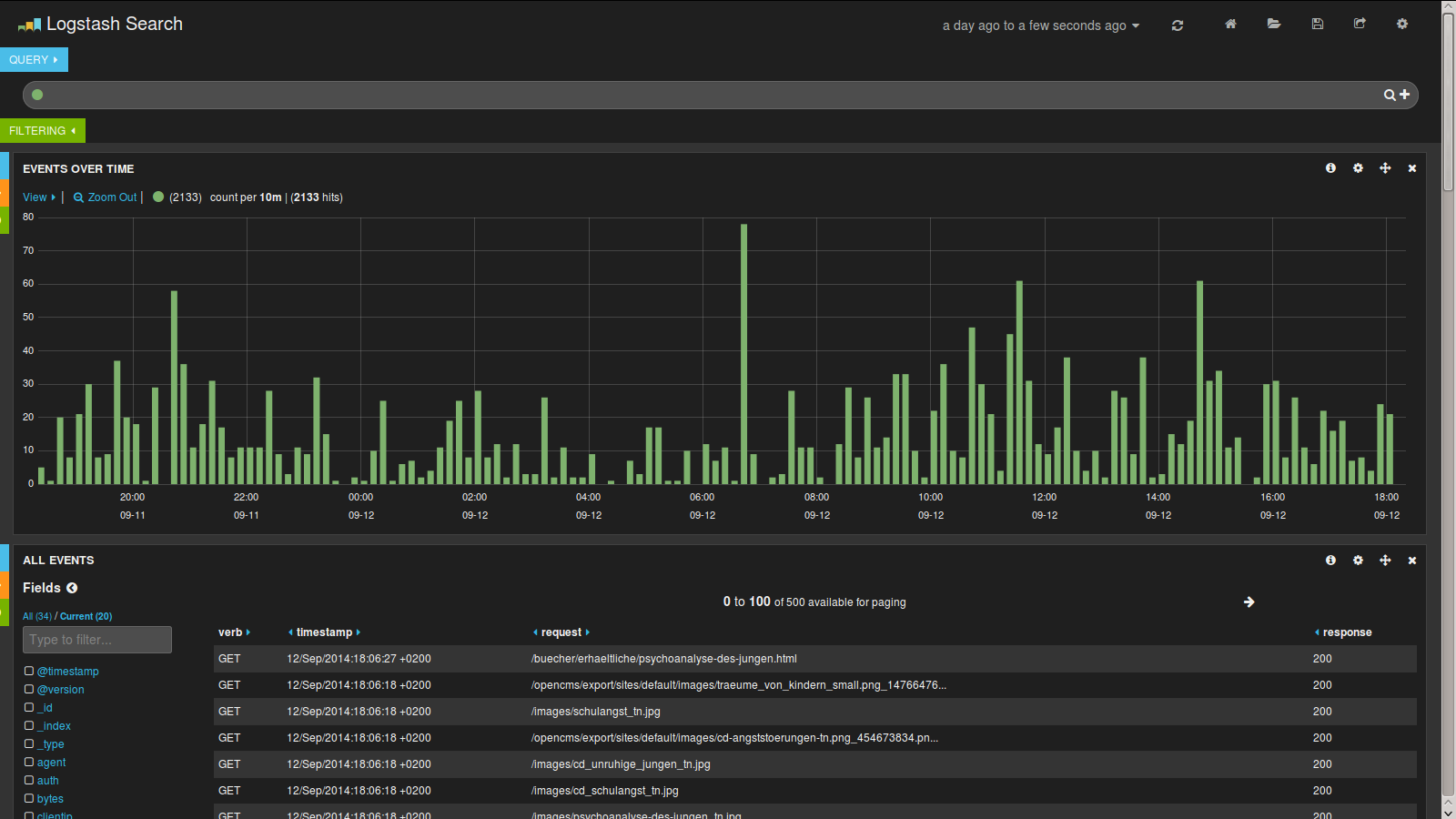
Как вы можете видеть, вы можете визуально извлечь много данных, которые в противном случае были бы помещены в несколько файлов журнала.
Вывод
Стек ELK может быть отличным инструментом для чтения, изменения и хранения событий журнала. Панели мониторинга помогают визуализировать происходящее. В Logstash много входных данных, а фильтр grok предоставляет множество различных форматов. Используя эти инструменты, вы можете консолидировать и централизовать все ваши файлы журналов.
Многие люди используют стек для анализа данных своего журнала. Одна из доступных статей — Mailgun, которая использует его для хранения миллиардов событий. И если этого недостаточно, прочитайте этот пост о том, как CERN использует стек ELK, чтобы помочь запустить Большой адронный коллайдер.
В следующем посте мы рассмотрим окончательный вариант использования Elasticsearch: Analytics.
| Ссылка: | Примеры использования Elasticsearch: индекс и файлы журнала поиска от нашего партнера JCG Флориана Хопфа в блоге Dev Time . |