В последнем посте этой серии о вариантах использования Elasticsearch мы рассмотрели функции, которые Elasticsearch предоставляет для хранения даже большого количества документов . В этом посте мы рассмотрим еще одну из его основных функций: поиск. Я опираюсь на некоторую информацию из предыдущего поста, поэтому, если вы ее еще не прочитали, вам следует сделать это сейчас.
Как мы уже видели, мы можем использовать Elasticsearch для хранения документов JSON, которые могут быть даже распределены по нескольким машинам. Индексы используются для группировки документов, и каждый документ хранится с использованием определенного типа. Осколки используются для распределения частей индекса по нескольким узлам, а реплики являются копиями осколков, которые используются для распределения нагрузки, а также для обеспечения отказоустойчивости.
Полнотекстовый поиск
Все используют полнотекстовый поиск. Количество информации стало слишком большим, чтобы получить к ней доступ только с помощью навигации и категорий. Google является наиболее ярким примером, предлагающим мгновенный поиск по ключевым словам в огромном количестве информации.
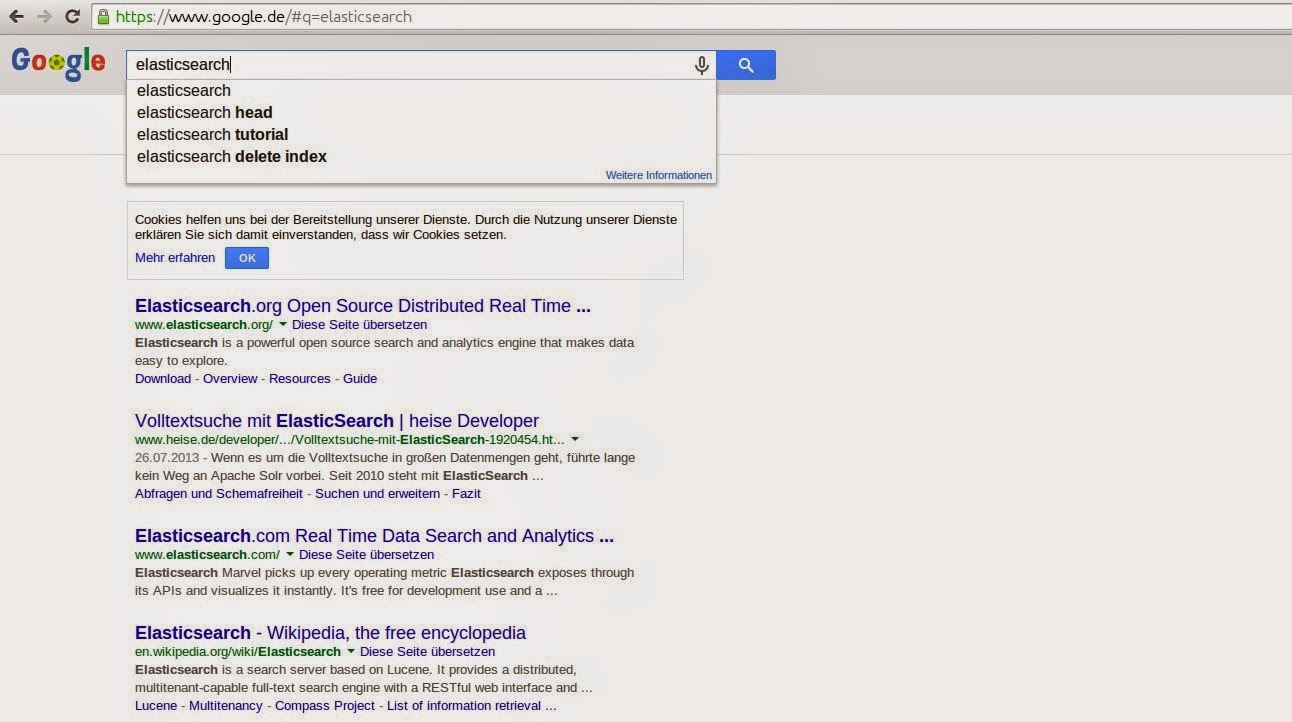
Глядя на то, что делает Google, мы уже можем видеть некоторые общие черты полнотекстового поиска. Пользователи предоставляют только ключевые слова и ожидают, что поисковая система даст хорошие результаты. Ожидается, что релевантность документов будет хорошей, и пользователям нужны результаты, которые они ищут на первой странице. Насколько релевантен документ, могут влиять различные факторы, такие как наличие запрашиваемого термина в документе. Помимо получения наилучших результатов, пользователь хочет, чтобы его поддерживали в процессе поиска. В этом могут помочь такие функции, как предложения и выделение результатов.
Другая область, где важен поиск, — это электронная коммерция, где Amazon является одним из доминирующих игроков.
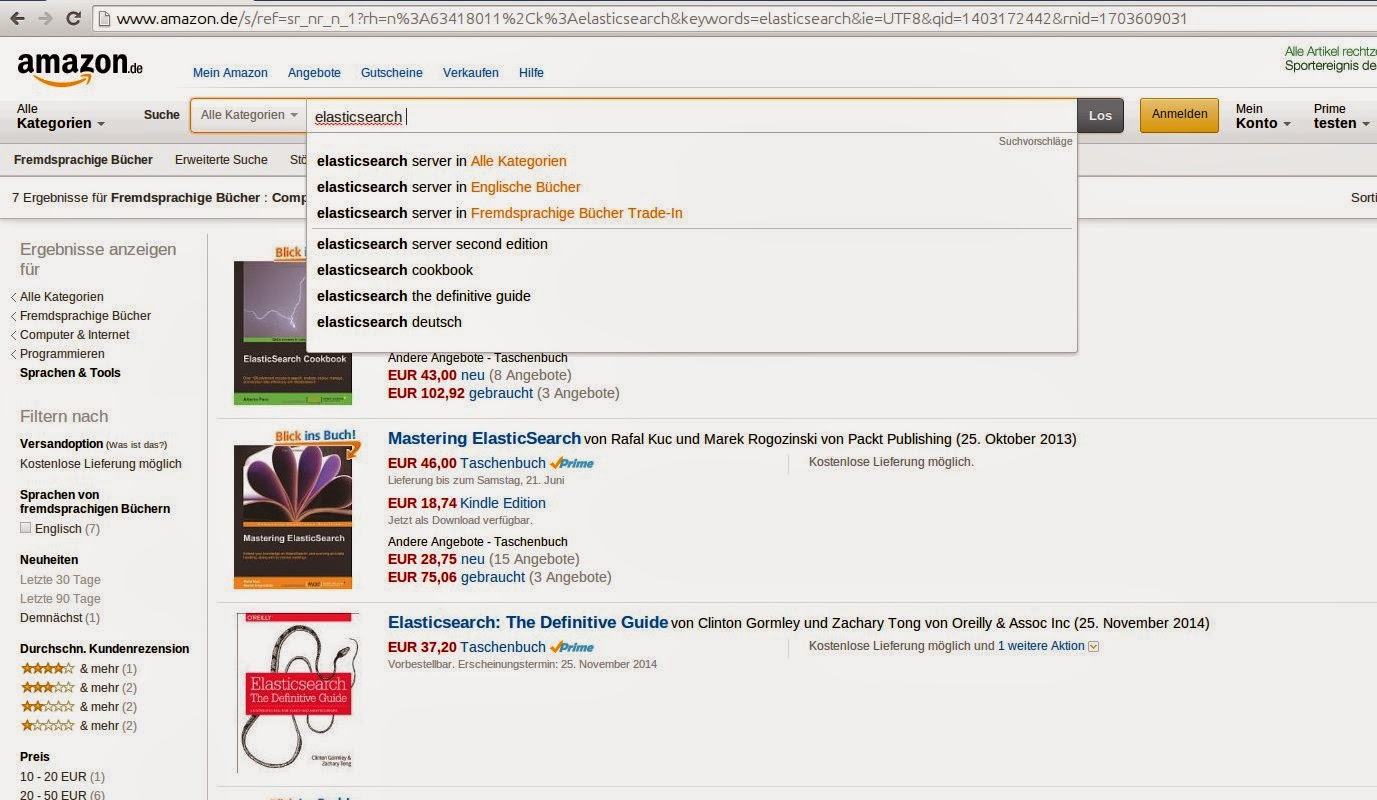
Интерфейс похож на Google. Пользователь может ввести ключевые слова, которые затем будут искать. Но есть и небольшие различия. Амазон предлагает более продвинутые предложения, также намекая на категории, в которых может быть найден термин. Кроме того, отображение результатов отличается, состоящим из более структурированного представления. Структура искомых документов также используется для определения граней слева, которые можно использовать для фильтрации текущего результата на основе определенных критериев, например, всех результатов, которые стоят от 10 до 20 €. Наконец, релевантность может означать нечто совершенно иное, когда речь идет о чем-то вроде интернет-магазина. Часто на порядок вывода результатов влияет поставщик, или пользователь может отсортировать результаты по таким критериям, как цена или дата выпуска.
Хотя ни Google, ни Amazon не используют Elasticsearch, вы можете использовать его для создания похожих решений.
Поиск в Elasticsearch
Как и все остальное, Elasticsearch можно искать с помощью HTTP. В самом простом случае вы можете добавить конечную точку _search к URL-адресу и добавить параметр : curl -XGET "http://localhost:9200/conferences/talk/_search?q=elasticsearch⪯tty=true" . Elasticsearch затем ответит результатами, упорядоченными по релевантности.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
{ "took" : 81, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "failed" : 0 }, "hits" : { "total" : 1, "max_score" : 0.067124054, "hits" : [ { "_index" : "conferences", "_type" : "talk", "_id" : "iqxb7rDoTj64aiJg55KEvA", "_score" : 0.067124054, "_source":{ "title" : "Anwendungsfälle für Elasticsearch", "speaker" : "Florian Hopf", "date" : "2014-07-17T15:35:00.000Z", "tags" : ["Java", "Lucene"], "conference" : { "name" : "Java Forum Stuttgart", "city" : "Stuttgart" }} } ] }} |
Несмотря на то, что мы провели поиск по определенному типу, вы также можете выполнять поиск по нескольким типам или нескольким индексам.
Добавить параметр легко, но поисковые запросы могут стать более сложными. Мы можем запросить выделение или отфильтровать документы в соответствии с критериями. Вместо использования параметров для всего, Elasticsearch предлагает так называемый Query DSL , API-интерфейс поиска, который передается в теле запроса и выражается с использованием JSON.
Этот запрос может быть результатом того, что пользователь попытался найти упругой поиск, но неправильно набрал его части. Результаты фильтруются так, что возвращаются только доклады для конференций в городе Штутгарт.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
{ "query": { "match": { "title" : { "query": "elasticsaerch", "fuzziness": 2 } } }, "filter": { "term": { "conference.city": "stuttgart" } }}' |
На этот раз мы запрашиваем все документы всех типов в индексных конференциях. Объект запроса запрашивает один из распространенных запросов — запрос на совпадение в поле заголовка документа. Атрибут запроса содержит поисковый термин, который будет передан пользователем. Атрибут fuzziness требует, чтобы мы также нашли документы, содержащие термины, похожие на запрошенный термин. Это позаботится о сроке с ошибкой, а также вернет результаты, содержащие эластичный поиск. Объект фильтра требует, чтобы все результаты были отфильтрованы в соответствии с городом конференции. Фильтры следует использовать всегда, когда это возможно, поскольку они могут кэшироваться и не рассчитывать релевантность, которая должна сделать их быстрее.
Нормализация текста
Поскольку поиск используется везде, у пользователей также есть некоторые ожидания относительно того, как он должен работать. Вместо точного соответствия ключевых слов они могут использовать термины, которые похожи только на те, которые есть в документе. Например, пользователь может запрашивать термин Anwendungsfall, который является единственным в curl -XGET "http://localhost:9200/conferences/talk/_search?q=title:anwendungsfall⪯tty=true" термином Anwendungsfälle, что означает варианты использования на немецком языке: curl -XGET "http://localhost:9200/conferences/talk/_search?q=title:anwendungsfall⪯tty=true"
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
{ "took" : 2, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "failed" : 0 }, "hits" : { "total" : 0, "max_score" : null, "hits" : [ ] }} |
Без результатов. Мы могли бы попытаться решить эту проблему, используя нечеткий поиск, который мы видели выше, но есть лучший способ. Мы можем нормализовать текст во время индексации, чтобы оба ключевых слова указывали на один и тот же термин в документе.
Lucene, библиотека поиска и хранения в Elasticsearch реализована с предоставлением базовой структуры данных для поиска, инвертированного индекса. Термины сопоставляются с документами, в которых они содержатся. Процесс, называемый анализом, используется для разделения входящего текста и добавления, удаления или изменения терминов.

Слева мы видим два документа, которые проиндексированы, справа мы видим инвертированный индекс, который отображает термины в документы, в которых они содержатся. В процессе анализа содержимое документов разбивается и преобразуется в зависимости от приложения. таким образом, это может быть помещено в индекс. Здесь текст сначала разбивается на пробел или пунктуацию. Тогда все символы в нижнем регистре. На последнем этапе используется зависящий от языка ствол, который пытается найти базовую форму терминов. Это то, что превращает нашу Anwendungsfälle в Anwendungsfall.
Какая логика выполняется во время анализа, зависит от данных вашего приложения. Процесс анализа является одним из основных факторов, определяющих качество вашего поиска, и вы можете потратить немало времени на него. Для более подробной информации вы можете посмотреть мой пост об абсолютных основах индексации данных.
В Elasticsearch способ анализа полей определяется отображением типа. На прошлой неделе мы видели, что мы можем индексировать документы различной структуры в Elasticsearch, но, как мы видим, теперь Elasticsearch не совсем свободен от схемы. Процесс анализа для определенного поля определяется один раз и не может быть легко изменен. Вы можете добавить дополнительные поля, но обычно вы не меняете способ хранения существующих полей.
Если вы не предоставите сопоставление, Elasticsearch проведет определенное предположение для документов, которые вы индексируете. Он будет смотреть на любое новое поле, которое он видит во время индексации, и делать то, что он считает лучшим. В случае нашего заголовка он использует StandardAnalyzer, потому что это строка. Elasticsearch не знает, на каком языке находится наша строка, поэтому он не выполняет никаких операций, что является хорошим значением по умолчанию.
Чтобы сказать Elasticsearch использовать GermanAnalyzer вместо этого, нам нужно добавить пользовательское отображение. Сначала мы удаляем индекс и создаем его снова:
|
1
2
3
|
Затем мы можем использовать API отображения PUT, чтобы передать отображение для нашего типа.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
{ "properties": { "tags": { "type": "string", "index": "not_analyzed" }, "title": { "type": "string", "analyzer": "german" } }}' |
Мы предоставили только пользовательское сопоставление для двух полей. Остальные поля снова будут угаданы Elasticsearch. При создании производственного приложения вы, скорее всего, заранее сопоставите все свои поля, но те, которые не имеют отношения, также могут быть сопоставлены автоматически. Теперь, если мы снова проиндексируем документ и найдем единственное число, документ будет найден.
Расширенный поиск
Помимо функций, которые мы видели здесь, Elasticsearch предоставляет гораздо больше. Вы можете автоматически собирать фасеты для результатов, используя агрегаты, которые мы рассмотрим в следующем посте. Подсказки могут быть использованы для выполнения автоматического предложения для пользователя, термины могут быть выделены, результаты могут быть отсортированы по полям, вы получаете разбиение на страницы с каждым запросом,…. Поскольку Elasticsearch опирается на Lucene, доступны все плюсы для создания расширенного поискового приложения.
Вывод
Поиск является основной частью Elasticsearch, которую можно комбинировать с ее возможностями распределенного хранения. Вы можете использовать Query DSL для создания выразительных запросов. Анализ является основной частью поиска и может зависеть от добавления настраиваемого сопоставления для типа. Lucene и Elasticsearch предоставляют множество расширенных функций для добавления поиска в ваше приложение.
Конечно, есть много пользователей, которые используют Elasticsearch из-за его функций поиска и распределенной природы. GitHub использует его, чтобы позволить пользователям осуществлять поиск в репозиториях , StackOverflow индексирует все свои вопросы и ответы в Elasticsearch, а SoundCloud предлагает поиск по метаданным песен.
В следующем посте мы рассмотрим еще один аспект Elasticsearch: его использование для индексации геоданных, что позволяет фильтровать и сортировать результаты по дате и расстоянию.
| Ссылка: | Примеры использования Elasticsearch: полнотекстовый поиск от нашего партнера JCG Флориана Хопфа в блоге Dev Time . |