В июле я дважды выступлю с вводным докладом о Elasticsearch, сначала на Неделе разработчиков в Нюрнберге , а затем на форуме Java в Штутгарте . Я показываю некоторые особенности Elasticsearch, рассматривая некоторые варианты использования. Чтобы подготовиться к беседе, я постараюсь описать каждый из вариантов использования в блоге. Когда дело доходит до Elasticsearch, первое, на что часто обращают внимание, это поисковая часть. Но в этом посте я хотел бы начать с его возможностей распределенного хранилища документов.
Начиная
Прежде чем начать, нам нужно установить Elasticsearch, который, к счастью, очень прост. Вы можете просто скачать архив, распаковать его и использовать скрипт для его запуска. Поскольку это приложение на основе Java, вам, конечно, нужно установить среду выполнения Java.
|
1
2
3
4
5
6
7
8
|
# download archivewget https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.2.1.zip # zip is for windows and linuxunzip elasticsearch-1.2.1.zip # on windows: elasticsearch.batelasticsearch-1.2.1/bin/elasticsearch |
С Elasticsearch можно поговорить, используя HTTP и JSON. Когда вы смотрите на примеры, вы часто увидите, что curl используется, потому что он широко доступен. (См. Этот пост по запросу Elasticsearch с использованием плагинов для альтернатив). Чтобы проверить, работает ли он, вы можете выполнить запрос GET на порт 9200: curl -XGET http://localhost:9200 . Если все настроено правильно, Elasticsearch ответит примерно так:
|
01
02
03
04
05
06
07
08
09
10
11
|
{ "status" : 200,"name" : "Hawkeye", "version" : { "number" : "1.2.1", "build_hash" : "6c95b759f9e7ef0f8e17f77d850da43ce8a4b364", "build_timestamp" : "2014-06-03T15:02:52Z", "build_snapshot" : false, "lucene_version" : "4.8" }, "tagline" : "You Know, for Search"} |
Хранение документов
Когда я говорю документ, это означает две вещи. Во-первых, Elasticsearch хранит документы JSON и даже часто использует JSON для внутреннего использования. Это пример простого документа, который описывает доклады для конференций.
|
01
02
03
04
05
06
07
08
09
10
|
{ "title" : "Anwendungsfälle für Elasticsearch", "speaker" : "Florian Hopf", "date" : "2014-07-17T15:35:00.000Z", "tags" : ["Java", "Lucene"], "conference" : { "name" : "Java Forum Stuttgart", "city" : "Stuttgart" } } |
Есть поля и значения, массивы и вложенные документы. Каждая из этих функций поддерживается Elasticsearch. Помимо документов JSON, которые используются для хранения данных в Elasticsearch, документ ссылается на базовую библиотеку Lucene, которая используется для сохранения данных и обработки данных как документов, состоящих из полей. Так что это идеальное совпадение: Elasticsearch использует JSON, который очень популярен и поддерживается множеством технологий. Но базовые структуры данных также используют документы. При индексации документа мы можем отправить запрос на публикацию определенного URL. Тело запроса содержит документ для хранения, файл, который мы передаем, содержит содержимое, которое мы видели выше.
|
1
|
curl -XPOST http://localhost:9200/conferences/talk/ --data-binary @talk-example-jfs.json |
При запуске Elasticsearch прослушивает порт 9200 по умолчанию. Для хранения информации нам необходимо предоставить некоторую дополнительную информацию в URL. Первый сегмент после порта — это имя индекса. Индексное имя — это логическая группировка документов. Если вы хотите сравнить его с реляционным миром, это можно рассматривать как базу данных. Следующий сегмент, который необходимо указать, — это тип. Тип может описывать структуру хранящихся в нем элементов. Вы можете снова сравнить это с реляционным миром, это может быть таблица, но это только немного верно. Документы любого вида могут храниться в Elasticsearch, поэтому его часто называют схемой без. Мы рассмотрим это поведение в следующем посте, где вы увидите, что свободная схема — не самый подходящий термин для этого. Пока достаточно знать, что в Elasticsearch можно хранить документы совершенно другой структуры. Это также означает, что вы можете развивать свои документы и добавлять новые поля по мере необходимости. Обратите внимание, что ни индекс, ни тип не должны существовать при запуске индексации документов. Они будут созданы автоматически, одна из многих функций, которая позволяет легко начать с Elasticsearch. Когда вы сохраняете документ в Elasticsearch, он автоматически генерирует для вас идентификатор, который также возвращается в результате.
|
1
2
3
4
5
6
7
|
{ "_index":"conferences", "_type":"talk", "_id":"GqjY7l8sTxa3jLaFx67_aw", "_version":1, "created":true} |
Если вы хотите определить идентификатор самостоятельно, вы также можете использовать PUT для того же URL, который мы видели выше, плюс идентификатор. Я не хочу попадать в неприятности, вызывая этот RESTful, но вы заметили, что Elasticsearch хорошо использует глаголы HTTP? В любом случае, как вы сохранили документ, вы всегда можете получить его, указав индекс, тип и идентификатор.
|
1
|
curl -XGET http://localhost:9200/conferences/talk/GqjY7l8sTxa3jLaFx67_aw?pretty=true |
который ответит примерно так:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
{ "_index" : "conferences", [...] "_source":{ "title" : "Anwendungsfälle für Elasticsearch", "speaker" : "Florian Hopf", "date" : "2014-07-17T15:35:00.000Z", "tags" : ["Java", "Lucene"], "conference" : { "name" : "Java Forum Stuttgart", "city" : "Stuttgart" } }} |
Вы можете видеть, что источник в ответе содержит именно тот документ, который мы проиндексировали ранее.
Распределенное хранилище
До сих пор мы видели, как Elasticsearch хранит и извлекает документы, и мы узнали, что вы можете развивать схему своих документов. Огромное преимущество, которого мы до сих пор не коснулись, заключается в том, что оно распространяется. Каждый индекс можно разбить на несколько сегментов, которые затем можно распределить по нескольким машинам. К счастью, чтобы увидеть распределенную природу в действии, нам не нужно несколько машин. Во-первых, давайте посмотрим на состояние нашего в настоящий момент запущенного экземпляра в плагине эластичном поиске-kopf (см. Этот пост, чтобы узнать, как установить и использовать его ):
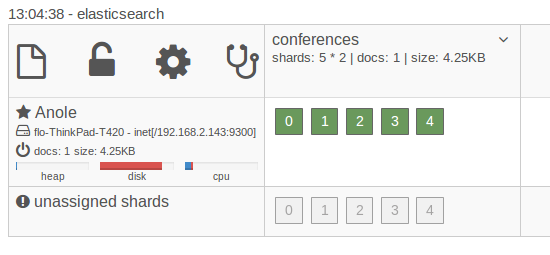
Слева вы видите, что работает одна машина. Строка сверху показывает, что она содержит наши индексные конференции. Несмотря на то, что мы не указали Elasticsearch в явном виде, он создал 5 сегментов для нашего индекса, которые в настоящее время все находятся в экземпляре, который мы запустили. Поскольку каждый из сегментов является индексом Lucene сам по себе, даже если вы запускаете индекс в одном экземпляре, документы, которые вы храните, уже распределены по нескольким индексам Lucene. Теперь мы можем использовать ту же установку для запуска другого узла. Через некоторое время мы также увидим экземпляр на приборной панели.
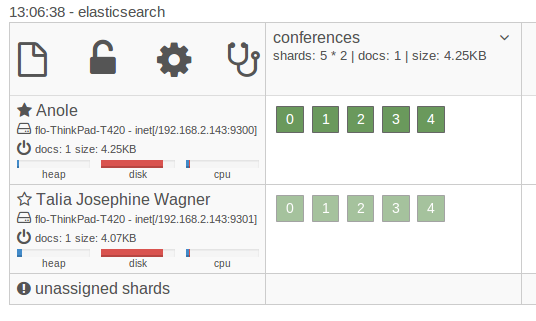
Когда новый узел присоединяется к кластеру (что по умолчанию происходит автоматически), Elasticsearch автоматически скопирует сегменты в новый узел. Это связано с тем, что по умолчанию используется не только 5 осколков, но и 1 копия, которая является копией осколка. Реплики всегда размещаются на разных узлах, чем их сегменты, и используются для распределения нагрузки и обеспечения отказоустойчивости. Если один из узлов выходит из строя, данные все еще доступны на другом узле. Теперь, если мы запустим другой узел, произойдет что-то еще. Elasticsearch восстановит баланс осколков. Он будет копировать и перемещать осколки в новый узел, чтобы осколки были равномерно распределены по машинам.
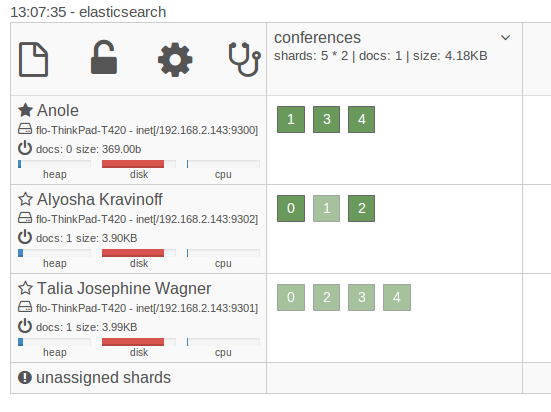
После определения индекса количество осколков не может быть изменено. Вот почему вы обычно перераспределяете (создаете больше осколков, чем вам нужно прямо сейчас) или, если ваши данные позволяют, вы можете создавать индексы на основе времени. Просто знайте, что шардинг обходится дорого, и тщательно продумайте, что вам нужно. Проектирование настроек дистрибутива все еще может быть трудным, даже если Elasticsearch многое сделает для вас из коробки.
Вывод
В этом посте мы увидели, как легко хранить и извлекать документы с помощью Elasticsearch. JSON и HTTP — это технологии, которые доступны во многих средах программирования. Схема ваших документов может изменяться по мере изменения ваших требований. Elasticsearch распределяет данные по умолчанию и позволяет масштабировать данные на несколько машин, поэтому он хорошо подходит даже для очень больших наборов данных. Хотя использование Elasticsearch в качестве хранилища документов является реальным вариантом использования, трудно найти пользователей, которые используют его только таким образом. Никто не получает документы только по идентификатору, как мы видели в этом посте, но использует богатые возможности запросов, которые мы рассмотрим на следующей неделе. Тем не менее, вы можете прочитать о том, как Hipchat использует Elasticsearch для хранения миллиардов сообщений и как Engagor использует Elasticsearch здесь и здесь . Оба они используют Elasticsearch в качестве основного хранилища. Хотя это звучит более радикально, чем это возможно: если вы планируете использовать Elasticsearch в качестве основного хранилища, вам также следует прочитать этот анализ поведения Elasticsearchs в случае сетевых разделов . На следующей неделе мы рассмотрим использование Elasticsearch для чего-то очевидного: поиска.
| Ссылка: | Примеры использования Elasticsearch: Хранение документов от нашего партнера JCG Флориана Хопфа в блоге Dev Time . |