Большинство статей о веб-разработке содержат примеры кода, и в Интернете мы видим большие различия в том, как они отформатированы и представлены.
Но многие из них не очень хороши — потому что код плохо отформатирован, плохо читается или не может быть скопирован и вставлен без нежелательного мусора. Поэтому в этой статье я хотел бы внимательно взглянуть на примеры кода, изучить общие проблемы, с которыми они сталкиваются, и попытаться найти некоторые рекомендации по их выполнению.
По мере продвижения вы неизбежно заметите, что примеры кода здесь, в SitePoint, не подходят к нулю! Это одна из вещей, которую мы будем улучшать в самое ближайшее время.
Для чего нужны примеры кода?
Назначение примеров кода в технических статьях и документации можно свести к двум основным принципам :
- чтобы проиллюстрировать концепцию или идею, или документировать синтаксис чего-либо
- предоставить код для копирования и вставки для читателя
Первая предпосылка заключается в том, как представлены примеры кода — они должны быть легко читаемыми, и должно быть очевидно, что они являются кодом. И все же, если это все, что имеет значение, почему бы просто не иметь картину? На самом деле, мне иногда кажется, что именно так многие сайты рассматривают свои примеры кода, уделяя особое внимание внешнему виду в ущерб их практическому использованию.
Но код — это не картинка, это важный текстовый контент, и поэтому вторая предпосылка — все о том, как реализованы примеры кода — их должно быть легко копировать и вставлять из них без потери форматирования и без ненужного ненужного мусора. текст. Примеры кода также должны иметь хорошую семантику, чтобы дать вспомогательным технологиям и роботам наилучшие возможности для их понимания.
Принципы хороших примеров кода
Основываясь на этих предпосылках, вот список того, что я считаю основными принципами хороших примеров кода . Мы начнем с этого списка, а затем по очереди рассмотрим каждый элемент, чтобы увидеть, как его можно достичь:
- Примеры кода должны использовать хорошую семантическую разметку.
- Вкладки в коде не должны быть преобразованы в пробелы.
- Код должен иметь базовую подсветку синтаксиса.
- Примеры кода могут иметь горизонтальную прокрутку, но не должны иметь вертикальную прокрутку.
- Примеры кода должны иметь номера строк, которые не включены в выделение текста.
Я также собираюсь добавить другую идею, которую вы, возможно, не рассматривали ранее, но которая на самом деле имеет огромное значение для удобства использования примеров кода (как мы увидим):
- Примеры кода должны быть редактируемыми.
Теперь некоторые из этих принципов могут показаться сложными для соблюдения. Например, очень часто можно видеть, как вкладки преобразуются в группы пробелов, потому что большинство браузеров отображают вкладки шириной 8 символов. Не менее распространенным является перенос каждой строки в <li> для номеров строк, но это, конечно, означает, что текст буфера обмена будет по-прежнему включать числа.
Многие сайты делают, чтобы компенсировать эти проблемы, — добавить отдельный значок в углу блока кода, который открывает всплывающее окно с исходным кодом, из которого можно копировать и вставлять. Но я не считаю, что приемлемое решение — честно говоря, оно раздражает — и открытие всплывающих окон никогда не будет полезным для доступности или удобства использования.
И в этом нет необходимости: как мы увидим, есть способы реализовать все эти требования в чистом, доступном и удобном виде.
1. Примеры должны использовать хорошую семантическую разметку
Почти каждый пример кода, который я видел, использует одни и те же базовые элементы — комбинацию <pre> и <code> — что является идеальным выбором.
Внутренний <code> обеспечивает семантическое значение и никогда не является неправильным выбором для кода, хотя есть также элемент <samp> который можно использовать для отображения результатов процесса (например, отображения образца заголовков HTTP, возвращаемых запросом). ). Внешний элемент <pre> является элементом уровня блока с собственным форматированием, сохраняющим пробелы, поэтому мы получаем такое форматирование даже тогда, когда CSS недоступен:
<pre><code>while(sheep != "zzz") { sleep ++; }</code></pre>
Поскольку <pre> сохраняет все пустое пространство в своем содержимом, это будет включать что угодно между тегами <pre> и <code> или между тегами <code> и текстом, поэтому они все выполняются вместе.
И, наконец, в HTML5 мы можем обернуть <figure> вокруг всего этого. Элемент <figure> был разработан для разметки таких вещей, как диаграммы, рисунки и примеры кода, и при желании может иметь подпись, используя элемент <figcaption> . Мы также можем улучшить доступность, добавив некоторые атрибуты ARIA — aria-labelledby в <pre> который указывает на <figcaption> (если он есть), и aria-describedby <figcaption> которая указывает на предыдущий текст (если он описывает пример) ,
Итак, давайте добавим и их, и тогда у нас будет солидная и доступная структура с превосходной всесторонней семантикой:
<p id="example1-description"> This is the descriptive text before the code example: </p> <figure> <figcaption id="example1-caption"> This is the caption </figcaption> <pre aria-labelledby="example1-caption" aria-describedby="example1-description"><code>function getToSleep() { while(noise <= 10 && sleep !== "zzz") { sheep ++; } if(noise > 10) { return false; } return true; }</code></pre> </figure>
Посмотрим, как выглядит наш пример кода. Демонстрация включает в себя столбец содержимого, который центрируется на странице, а сам кодовый блок не имеет определенной ширины, поэтому он занимает весь столбец. Я также определил некоторые базовые свойства дизайна и шрифта, и стоит отметить, как один и тот же основной шрифт применяется к элементам <pre> и <code> , что необходимо, чтобы избежать различий между браузерами (поскольку браузеры имеют разные значения по умолчанию), а затем позволяет управлять общим font-size из <pre> :
2. Вкладки в коде не должны быть преобразованы в пробелы
Когда читатель копирует и вставляет из примера кода, текст должен иметь такое же форматирование, как и в обычном редакторе. Никто разумно не пишет код с пробелами вместо вкладок, поэтому примеры кода также не должны этого делать.
Однако, как мы уже отмечали, проблема, с которой мы сталкиваемся, заключается в том, что браузеры отображают вкладки шириной 8 символов, и это намного больше места, чем требуется большинству людей. Это также усугубляет проблему ограниченного горизонтального пространства (что мы рассмотрим позже).
Но есть удобное решение со свойством CSS tab-size . Он поддерживается в Chrome, Firefox и Opera, причем последние два используют префикс вендора, поэтому для его работы нам понадобятся три варианта:
pre { -moz-tab-size:4; -o-tab-size:4; tab-size:4; }
Некоторые сайты предпочитают 2-символьные вкладки, хотя я думаю, что 4 более читабелен, но в любом случае это не имеет большого значения. Дело в том, что вкладки должны быть вкладками — насколько они велики, зависит от вас.
Конечно, браузеры, которые не поддерживают это свойство, будут по-прежнему отображать вкладки в размере по умолчанию; это неудачно, но это лучше, чем заменить их пробелами.
Пока мы говорим о пустом пространстве, я бы также сказал, что пустые строки не должны быть удалены . Мы добавляем пустые строки в код по определенной причине — чтобы создать логические разделы и сделать его более читабельным — и то же самое верно для примеров кода.
Теперь давайте посмотрим на нашу демонстрацию с добавлением tab-size :
3. Код должен иметь базовую подсветку синтаксиса
Смысл подсветки синтаксиса состоит в том, чтобы сделать код проще для понимания. Улучшение может быть значительным, особенно для начинающих.
Для его реализации у нас нет другого выбора, кроме как обернуть дополнительные элементы вокруг кусков кода, и это можно сделать с помощью PHP или JavaScript или жестко запрограммировать в примерах. Лично я думаю, что жесткое кодирование лучше (так как нет дополнительных затрат на обработку), но такие вопросы выходят за рамки этой статьи, поэтому я оставлю это решение вам. Что касается конечного результата, это не имеет никакого значения
Я хотел бы поговорить о том, какие элементы использовать, и я рекомендую следующее:
- используйте
<i>или<em>для комментариев - используйте
<b>или<strong>для программирования ключевых слов и констант, имен свойств CSS , а также тегов HTML и имен атрибутов - используйте
<u>для программирования строк, строк CSS и значений атрибутов HTML
Это утверждается в CSS несколькими комбинациями потомков, так что строки переопределяют ключевые слова, а комментарии переопределяют все:
pre b { font-weight:normal; color:#039; } pre u, pre ub { text-decoration:none; color:#083; } pre i, pre i *, pre i * * { letter-spacing:-0.1em; text-decoration:none; font-style:normal; color:#c55; }
Этот выбор элементов может быть спорным, и он, безусловно, довольно ограничительный — использование <span> с различными классами имеет гораздо больше возможностей, и если это решение, которое вы предпочитаете, я не могу сказать вам, что это неправильно. Но подсветка синтаксиса не должна быть настолько обширной, она должна быть достаточной только для улучшения понимания, и преимущество использования элементов, которые я предлагаю, состоит в том, что мы все еще получаем базовую подсветку даже без CSS .
Ну, на самом деле, есть и другая причина — но я оставлю это на потом!
Вы заметите из CSS, что я решил использовать <b> и <i> вместо <strong> и <em> , и этот выбор также спорен. Вы можете, например, утверждать, что правильно использовать <em> потому что это своего рода акцент, но в равной степени вы можете утверждать, что правильно использовать <i> потому что разница в основном визуальная. Лично я склоняюсь к последней точке зрения.
Итак, давайте посмотрим, как наша демонстрация улучшена с добавлением подсветки синтаксиса:
4. Примеры могут иметь горизонтальную прокрутку, но не должны иметь вертикальную прокрутку
Это противоположно тому, как мы относимся к страницам в целом, где горизонтальная прокрутка крайне нежелательна, но вертикальная прокрутка неизбежна. И именно потому, что мы делаем страницы таким образом, примеры кода должны делать обратное — потому что горизонтальное пространство ограничено, а вертикальное пространство нет.
Внутренние области прокрутки, как правило, не очень удобны для использования, поскольку с ними сложнее взаимодействовать, и ими нельзя управлять с помощью клавиатуры, если сам элемент не сфокусирован. Поэтому мы должны рассматривать горизонтальную прокрутку как запасной вариант в случае длинных линий.
Другими словами, лучше написать пример кода таким образом, чтобы избежать длинных строк , но если мы затем добавим overflow-x:auto мы будем готовы к случаям, когда это невозможно, или к просмотру на очень маленький экран.
Единственный случай, когда произойдет сбой, — это печать страницы, но в этом случае мы можем переопределить прокрутку и компенсировать white-space:pre-wrap :
pre { overflow-x:auto; } @media print { pre { overflow-x:visible; white-space:pre-wrap; } }
Я бы вообще не рекомендовал использовать pre-wrap — потому что перенос строк кода может усложнить понимание — но если мы не сделаем этого для печати, самые длинные строки будут полностью потеряны.
Вернитесь к нашей обновленной демонстрации, и если вы измените размер окна до гораздо меньшей ширины, вы увидите, когда включится горизонтальная прокрутка:
5. Примеры должны иметь номера строк, которые не включены в данные буфера обмена.
Почти все примеры кода, которые я видел, которые имеют номера строк вообще, реализуют их, оборачивая дополнительную разметку вокруг отдельных строк — либо используя элемент <ol> с <li> для каждой строки, либо используя разметку <table> как это:
<table> <tbody> <tr> <td><code>1</code></td> <td><code>while(sleep != "zzz")</code></td> </tr> <tr> <td><code>2</code></td> <td><code>{</code></td> </tr> <tr> <td><code>3</code></td> <td><code> sheep ++;</code></td> </tr> <tr> <td><code>4</code></td> <td><code>}</code></td> </tr> </tbody> </table>
Я думаю, что было бы очень трудно обосновать это семантически, но совершенно независимо от этого, реальная проблема заключается в том, что, когда читатель копирует и вставляет код, его номера по-прежнему включаются . Даже если числа реализованы с использованием сгенерированного контента CSS , некоторые браузеры по-прежнему будут включать их в данные буфера обмена.
Ранее я упоминал, что существует общее решение этой проблемы, которое заключается в добавлении значка в углу блока кода, который открывает всплывающее окно с исходным кодом. И я уже отклонил это как утомительное и неприемлемое решение!
Должен быть лучший путь — и он на самом деле довольно простой. Все, что нам нужно сделать, это реализовать числа с элементами вне кода . В основном это:

Боксы нам нужны для создания номеров строк, показывающих, как числовые элементы полностью находятся вне кода.
Сложность состоит в том, чтобы сохранять числа в вертикальной синхронизации со строками кода. Во-первых, это означает, что мы определенно не можем использовать форматирование перед переносом , потому что тогда у нас не будет фиксированной связи между строками кода и числами. Но вторая и самая важная вещь заключается в том, что мы должны убедиться, что все элементы используют одинаковый шрифт и высоту строки .
Таким образом, это подразумевает ряд изменений в стиле примеров кода. Во-первых, мы должны использовать элемент внутреннего кода в качестве основного блока макета, применяя padding , overflow и tab-size которые ранее были в <pre> . Мы также должны определить явное white-space для IE7 (который другие браузеры просто наследуют):
pre, pre code, pre samp { display:block; margin:0; } pre code, pre samp { white-space:pre; padding:10px; overflow-x:auto; }
Мы также должны расширить сброс шрифта, чтобы он применялся ко всему внутри <pre> , тогда как общий font-size прежнему контролируется таким же образом:
pre, pre * { font:normal normal normal 1em/1.4 monaco, courier, monospace; } pre { font-size:0.8em; }
Эти изменения освобождают <pre> для действия в качестве контекста позиционирования для контейнера чисел; контейнер скрыт по умолчанию, пока не будет применен дополнительный class (и я объясню причину этого через мгновение):
pre.line-numbers { position:relative; } pre.line-numbers code, pre.line-numbers samp { margin-left:3em; } pre div { display:none; } pre.line-numbers > div { display:block; position:absolute; top:0; left:0; }направоpre.line-numbers { position:relative; } pre.line-numbers code, pre.line-numbers samp { margin-left:3em; } pre div { display:none; } pre.line-numbers > div { display:block; position:absolute; top:0; left:0; }
Внутри этого контейнера мы создадим кучу пустых <span> , каждый из которых имеет block отображение, поэтому они образуют вертикальный стек с width и 3em которые в совокупности создают пространство 3em мы 3em в <pre> margin-left :
pre.line-numbers > div > span { display:block; width:2.5em; padding:0 0.5em 0 0; text-align:right; }
Сами числа реализованы с использованием сгенерированного CSS контента, который предпочтительнее обычного текста, потому что они не будут видны без CSS (тогда как нормальный текст будет отображаться в виде строки цифр над <pre> ):
pre.line-numbers > div { counter-reset:line; } pre.line-numbers > div > span { counter-increment:line; } pre.line-numbers > div > span::before { content:counter(line); }
Но это также связано с моим общим убеждением, что сгенерированный контент на самом деле не является контентом — потому что номера строк на самом деле тоже не контент, а презентация . Контейнер <div> также должен иметь aria-hidden , чтобы программы чтения с экрана не читали числа; некоторые программы чтения с экрана в любом случае не читают сгенерированный контент, но те, которые это делают, читают их все сразу и вне контекста, как будто это было одно большое число перед кодом.
Чтобы сгенерировать все это, я собираюсь использовать JavaScript — частично для простоты обслуживания, но в основном потому, что это даст нам возможность отфильтровать IE8 и более ранние версии (которые не поддерживают сгенерированный контент). Вот почему дополнительные стили определяются с помощью селектора class — поэтому они не будут применяться, если не поддерживаются сценарии:
(function() { if(typeof(window.getComputedStyle) == 'undefined') { return; } var pre = document.getElementsByTagName('pre'); for(var len = pre.length, i = 0; i < len; i ++) { var code = pre[i].getElementsByTagName('code').item(0); if(!code) { code = pre[i].getElementsByTagName('samp').item(0); if(!code) { continue; } } var column = document.createElement('div'); column.setAttribute('aria-hidden', 'true'); for(var n = 0; n < code.innerHTML.split(/[nr]/g).length; n ++) { column.appendChild(document.createElement('span')); } pre[i].insertBefore(column, code); pre[i].className = 'line-numbers'; } })();
Конечный результат — идеально выровненные числа, которые не появляются в скопированном тексте — когда вы выбираете код, это все, что вы получаете:
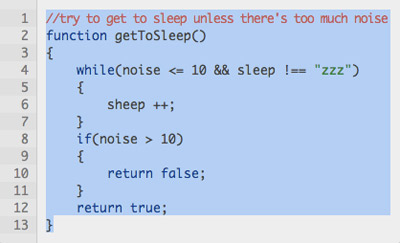
Код можно выбирать и копировать, не включая номера строк.
И если какие-либо строки достаточно длинные, чтобы вызвать горизонтальную прокрутку, цифры не будут прокручиваться вместе с ними — они будут оставаться в одном и том же положении, оставляя их видимыми все время!
Однако вы, возможно, помните ранее, как мы используем white-space:pre-wrap для печати, и мы не можем объединить это с этой техникой, потому что мы не можем компенсировать перенос строк. Нет простого способа определить, когда строка переносится, поэтому единственное, что мы можем сделать, это избавиться от чисел для печати:
@media print { pre code { overflow-x:visible; white-space:pre-wrap; } pre.line-numbers div { display:none; } pre.line-numbers > code, pre.line-numbers > samp { margin-left:0; } }
Взгляните на обновленную демонстрацию и посмотрите, как все это работает на практике:
6. Примеры кода должны быть редактируемыми
Нет особой причины, по которой читатели хотели бы редактировать примеры кода (если вы не создавали редактор кода, но это совсем другое).
Нет, причина того, что редактируемые примеры кода полезны, заключается в том, что редактируемые области имеют дополнительные элементы навигации и выбора , например:
- Вы можете щелкнуть внутри кода и использовать Ctrl + A, чтобы выделить все это.
- Вы можете использовать Shift + Arrow для частичного выделения текста с помощью клавиатуры.
- Вы можете перемещаться внутри, используя такие клавиши, как Home и End .
- Теперь можно прокручивать с клавиатуры (как следствие навигации).
К счастью, этого легко достичь, просто добавив contenteditable к внутреннему элементу <code> или <samp> . Он должен быть на внутреннем элементе, потому что это тот, который прокручивается, не говоря уже о том, что установка его в <pre> позволит пользователю случайно удалить все внутри него! Мы также добавим tabindex чтобы сделать его доступным с клавиатуры, и tabindex spellcheck поскольку она в основном бесполезна для кода (хотя это не остановит ее в Firefox):
<code contenteditable="true" tabindex="0" spellcheck="false">
Это не повлияет на нашу подсветку синтаксиса, так как редактируемые области все еще могут содержать разметку. На самом деле … вы помните, как я упомянул дополнительную убедительную причину использования <b> , <i> и <u> ? Ну вот причина — потому что использование этих элементов означает, что читатель может редактировать синтаксис, выделяя себя с помощью собственных нажатий клавиш редактора — Ctrl + B , Ctrl + I и Ctrl + U.
Однако браузеры различаются по элементам, которые они используют для реализации этих действий — например, некоторые браузеры реализуют Ctrl + B , оборачивая <strong> вокруг текста, в то время как другие используют <b> . Таким образом, чтобы заставить его работать в кросс-браузерном режиме, нам нужно удвоить правила синтаксиса (что также означает, что вопрос о том, является ли <strong> или <b> правильный выбор семантики, теперь несколько спорный!):
pre b, pre strong { font-weight:normal; color:#039; } pre u, pre ub, pre u strong { text-decoration:none; color:#083; } pre i, pre em, pre i *, pre em *, pre i * *, pre em * * { letter-spacing:-0.1em; text-decoration:none; font-style:normal; color:#c55; }
Конечно, я уже говорил, что мы не создаем здесь редактор, поэтому нет никакой реальной причины, почему важно иметь этот контроль. Это совсем не важно, просто приятное прикосновение! Поэтому, если вы предпочитаете использовать <span> для подсветки синтаксиса и не используете эти клавиши подсветки клавиш, не позвольте мне убедить вас в обратном.
Но причина использования contenteditable состоит в том, чтобы предоставить дополнительные средства выбора и навигации — редактируемые примеры кода значительно улучшили удобство использования и доступность. Возможность выбрать все
— сама по себе достаточная причина.
Итак, теперь давайте взглянем на демо с этим дополнением. Я также определил некоторые :focus стили :focus чтобы обеспечить визуальную подсказку, добавив белый фон и сильную тень вставки:
Вывод
И вот у нас это есть — шесть руководящих принципов для хороших примеров кода, которые гарантируют, что они доступны, применимы, семантически действительны, легко читаются и легко копируются и вставляются.
Вы можете скачать zip-файл со всеми демонстрациями этой статьи: