Код, созданный из дискретного источника без памяти, должен быть эффективно представлен, что является важной проблемой в коммуникации. Для этого существуют кодовые слова, которые представляют эти исходные коды.
Например, в телеграфии мы используем азбуку Морзе, в которой алфавиты обозначаются знаками и пробелами . Если рассматривается буква E , которая в основном используется, она обозначается как «.», Тогда как буква Q, которая используется редко, обозначается как «—.-»
Давайте посмотрим на блок-схему.
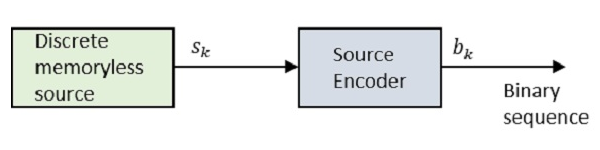
Где S k — это выход дискретного источника без памяти, а b k — это выход исходного кодера, который представлен 0 и 1 .
Кодированная последовательность такова, что она удобно декодируется в приемнике.
Предположим, что источник имеет алфавит с k различными символами и что k- й символ S k встречается с вероятностью P k , где k = 0, 1… k-1 .
Пусть двоичное кодовое слово, присвоенное символу S k кодером, имеющим длину l k , измеряется в битах.
Следовательно, мы определяем среднюю длину L кодового слова исходного кодера как
overlineL= displaystyle sum limitk−1k=0pklk
L представляет среднее количество битов на исходный символ
Если Lmin=минимумвозможнозначениеof overlineL
Тогда эффективность кодирования может быть определена как
eta= fracLmin overlineL
С overlineL geqLmin у нас будет eta leq1
Тем не менее, исходный кодер считается эффективным, когда eta=1
Для этого необходимо определить значение Lmin.
Обратимся к определению: «Для дискретного источника энтропии H( delta) без памяти средняя длина кодового слова L для любой исходной кодировки ограничена как overlineL geqH( delta) «.
Проще говоря, кодовое слово (например: азбука Морзе для слова QUEUE — это -.- ..-. ..-.) Всегда больше или равно исходному коду (в примере QUEUE). Это означает, что символы в кодовом слове больше или равны алфавиту в исходном коде.
Следовательно, при Lmin=H( delta) эффективность исходного кодера в терминах энтропии H( delta) может быть записана как
eta= fracH( delta) overlineL
Эта теорема кодирования источника называется теоремой кодирования без помех, поскольку она устанавливает кодирование без ошибок. Это также называется первой теоремой Шеннона .