Для создания осмысленного визуального представления наших данных и дополнительных инструментов для анализа указанных данных важно иметь хорошо продуманную структуру управления данными. Это требует правильного внутреннего хранилища, парадигмы для доступа к данным и привлекательного внешнего интерфейса для представления и анализа. Существует множество инструментов, которые вы можете использовать для создания стека доступа к данным в своих веб-приложениях, которые мы будем изучать здесь.
Если вы собираете данные, которые относятся к вашим посетителям, они захотят каким-то образом их использовать. Наша обязанность заключается в обеспечении прозрачности для наших посетителей, предоставлении им наилучшего опыта и создании интуитивно понятных и эффективных инструментов, позволяющих им получить доступ к этим сведениям. Визуальное представление этих данных является лишь частью этого. Именно механизмы, которые мы используем для хранения, преобразования и транспортировки этих данных, играют важную роль в предоставлении такого богатого опыта.
Параметры хранения данных
В последние годы хранение данных стало огромным рынком. Решить, какую технологию вы хотите использовать для своего приложения, может быть непростой задачей. Есть несколько вещей, о которых стоит подумать: производительность, масштабируемость, простота реализации, а также особый набор навыков, которые вы и ваша команда. Этот последний пункт чрезвычайно важен и часто упускается из виду. Если в вашей команде есть команда разработчиков SQL, преимущества перехода на реализацию MongoDB должны быть огромными, чтобы убедить вас пойти по этому пути.
Кроме «придерживайтесь того, что вы знаете», нет простого и быстрого ответа, который вы должны использовать. С плоскими наборами данных может быть относительно легко работать. Они структурированы как одна таблица (например, файлы CSV) и могут быть относительно просты для понимания. Ограничения этих источников проявляются быстро, потому что они плохо работают по мере роста и их сложно поддерживать. Если у вас есть плоский набор данных, вы, скорее всего, захотите разбить его на один из других вариантов хранения.
Реляционные базы данных (MySQL, SQL Server) отлично подходят для хранения данных в отдельных таблицах, которые могут быть объединены с использованием уникальных ключей. Преимущества этого состоят в том, что они уменьшают размер наборов данных, работают лучше и могут быть доступны с помощью хорошо зарекомендовавшего себя языка запросов (SQL). Это решение также требует тщательного планирования, создания уникальных ключей для установления отношений и настройки производительности.
Все большую популярность приобретают документно-ориентированные базы данных (например, MongoDB ), которые позволяют хранить данные в объектах JSON. Это также более эффективно, чем плоские файлы, поскольку данные структурированы для уменьшения избыточности. Существует дополнительное преимущество хранения данных в формате, который является родным для JavaScript, но это может стать все более сложным, если вы пытаетесь объединить несколько наборов данных или суммировать / создавать агрегаты.
Неструктурированные базы данных (например, Hadoop) хороши для чрезвычайно больших наборов данных и выходят за рамки этого обсуждения. Если вы работаете с наборами данных такого размера, вы, вероятно, захотите использовать процесс ETL для нормализации данных перед их переносом в ваше приложение.
Возможность хранения данных на стороне клиента также привлекательна, но не лишена недостатков. Хранение файлов и кэширование данных на клиентском компьютере имеет некоторые преимущества в определенных случаях использования, но требует определенного уровня доверия между вами и пользователем. Если это доверенная служба или пользователь знает, что он будет работать с большими объемами данных, разумно ожидать, что он разрешит доступ к хранилищу файлов. Однако по умолчанию я бы не рекомендовал делать это ожидание в любых, кроме самых сложных случаях использования.
Создание слоев доступа
Есть несколько способов создания слоев доступа к вашим данным. Представления долгое время были стандартным способом сделать это в реляционных базах данных. Представления позволяют вам писать запросы вокруг ваших данных и представлять их в виде таблицы. Используя методы агрессии данных, такие как группировка, упорядочение, сумма и т. Д., Вы можете создавать меньшие, более целенаправленные наборы данных для визуализации и аналитики.
CREATE VIEW population_vw AS
SELECT country, age, year,
sum(total) AS TOTAL
FROM census_data
WHERE year IN ('2010')
AND country IN ('United States')
GROUP BY country, age, year;
Большинство реляционных баз данных также позволяют создавать материализованные представления, которые требуют ETL для создания представления, но работают лучше, потому что для них требуется доступ только к одной таблице.
Гибридный подход также может быть эффективным. Зачастую это может быть достигнуто путем создания более целевого слоя MongoDB для вашего большего набора данных, который хранится в SQL Server. Выгрузка наиболее важных данных в ориентированную на документы базу данных для быстрого доступа и потребления при сохранении всего объема данных в вашей внутренней базе данных SQL. Если вы используете Node, вы можете использовать Express, чтобы управлять созданием этих наборов данных и хранить их на вашем сервере MongoDB.
OLAP также позволяет вам создавать наборы данных, которые можно агрегировать, но при этом вы можете заранее установить измерения и показатели, которые вы хотите использовать для представления ваших данных. OLAP использует многомерные выражения (MDX) для доступа к типам данных, но не очень хорошо поддерживается в веб-приложениях.
Сетевые зависимости
Агрегирование ваших данных перед отправкой клиенту всегда считалось наилучшей практикой. Скорее всего, вы хотите максимально сократить объем данных на сервере, прежде чем представлять их своим пользователям. Однако это может быть проблематично, поскольку у вас часто возникает соблазн сократить его до наиболее агрегированной формы на сервере. Если пользователь хочет изменить макет данных, вы в конечном итоге перебиваете сеть, потому что вам постоянно нужно извлекать набор данных с сервера с соответствующим уровнем агрегирования.

Крайне важно найти тот носитель, где данные агрегированы до размера, который отвечает с точки зрения пропускной способности, но также предоставляет достаточные детали для анализа. Это может быть достигнуто путем сбора требований и установления ключевых метрик и измерений, которые требуются конечному пользователю для анализа.

Одним из распространенных способов доступа к данным является использование RESTful API. API RESTful позволяют запрашивать данные с удаленного сервера и использовать их в своих приложениях. Часто это будет в формате JSON. На практике рекомендуется уменьшить количество HTTP-вызовов, потому что каждый запрос будет иметь некоторую степень задержки. Вы должны попытаться сократить данные до менее подробного, но не полностью агрегированного уровня на сервере и сохранить набор данных на стороне клиента для дальнейшего сокращения.
Чтобы сделать запросы API более явными, вы можете использовать GraphQL , который позволяет вам сформулировать запрос к вашему API. Используя такой язык, как GraphQL, вы можете легко получить определенное подмножество данных. GraphQL быстро становится стандартом для приложений, которые имеют сложные отношения между несколькими таксономиями, такими как Facebook.
Функции, инструменты и методы
JavaScript имеет большой набор инструментов, встроенных в прототип массива, начиная с ES5. Это включает в себя filter()reduce()map() Они хорошо поддерживаются, не изменяют исходный массив и не требуют никаких дополнительных библиотек.
Чтобы узнать больше об этих встроенных функциях JavaScript, ознакомьтесь с нашим Премиум курсом по программированию на функциональном JavaScript.
Для представления данных я предпочитаю D3 , который позволяет вам манипулировать DOM, в частности элементами SVG, для представления ваших данных уникальными способами. Это может варьироваться от простых линейчатых, линейных и круговых диаграмм до сложных интерактивных визуализаций данных. Я создал демо полнофункциональной панели инструментов в D3 . Мы будем ссылаться на код из этого репозитория на протяжении оставшейся части статьи.
Другие инструменты, которые проще в использовании, но менее настраиваемые (например, Chart.js ), хороши , если вы просто хотите добавить некоторые быстрые визуализации без большого количества пользовательского кода.
Как правило, при визуализации визуализации на экране я буду привязывать событие к полю формы, которое вызовет нашу функцию рендеринга для объекта, связанного с нашим элементом SVG на странице:
document.getElementById("total").addEventListener('click', function() {
barGraph.render(d, "total")
});
к которому мы передадим наш набор данных dитого . Это позволит нам сделать две вещи:
- Взяв набор данных, мы можем изначально уменьшить и отфильтровать данные, а также сопоставить значения с «дружественными» именами.
- Это позволит нам выбрать метрику из множества разных метрик в наборе данных
В функции рендеринга мы будем обрабатывать добавление оси, всплывающих подсказок, визуализацию и обновление. Обычно это происходит в три этапа:
render: function(d, m) {
this._init(d, m);
this._enter(d);
this._update(d);
this._exit();
}
Вот четыре основных шага в приложении D3:
- init — Инициализировать масштабы, ось и набор данных
- enter — генерировать начальное обновление вида
- обновить — вид при изменении набора данных
- выход — уборка
Другие API, такие как Chart.js, позволят вам создавать диаграммы с использованием конфигурации, а не строить диаграммы с нуля. Это можно сделать, вызвав его API и передав необходимую конфигурацию:
var chartInstance = new Chart(ctx, {
type: "bar",
data: data,
options: {
legend: {
display: true,
labels: {
fontColor: "rgb(255, 99, 132)"
}
}
}
});
Разница здесь в том, что вы ограничены формой и функцией, которые были определены в API, и не обладаете такой большой гибкостью при создании уникальных и настраиваемых визуализаций.
Это две библиотеки (D3 и Chart.js), с которыми я работал больше всего, но есть много других доступных вариантов (как бесплатных, так и платных), которые можно использовать для предоставления данных вашим пользователям. Несколько советов, которые я бы порекомендовал при выборе продукта:
- Получить что-то, что построено с Canvas / SVG. По-прежнему на удивление существует множество приложений на основе Flash (и даже SilverLight). Они не созданы с учетом стандартов HTML, и вы будете сожалеть о них, когда пытаетесь интегрировать свое приложение.
- Рассмотрим набор навыков вашей команды. Нечто подобное D3 отлично подходит для команды опытных разработчиков JavaScript, но что-то менее настраиваемое (например, ChartJS) может быть достаточно и лучше соответствовать набору навыков вашей команды.
- Программа для интерфейса. Если в конечном итоге вы слишком тесно свяжете свои данные с вашим приложением, если вам придется менять инструменты, это будет значительно больше работы.
Часто вы обнаружите, что работаете с несколькими наборами данных. Важно, что если вы собираетесь объединять их на внешнем интерфейсе, вы загружаете их асинхронно и ждете полной загрузки всех, прежде чем присоединиться к ним. D3 имеет встроенные методы для обработки нескольких наборов данных:
d3.queue()
.defer(d3.json, "data/age.json")
.defer(d3.json, "data/generation.json")
.await(function(error, d, g) {
Если вы собираетесь представлять данные в накопительном пакете, есть функции гнезд и накопления D3, которые предоставляют эту функциональность. Это позволит вам легко выбрать измерение (ключ) и метрику, которую вы будете обобщать
var grp = d3.nest()
.key(function(d) {
return d.generation;
})
.rollup(function(v) {
return d3.sum(v, function(d) {
return d.total;
})
})
.entries(dg);
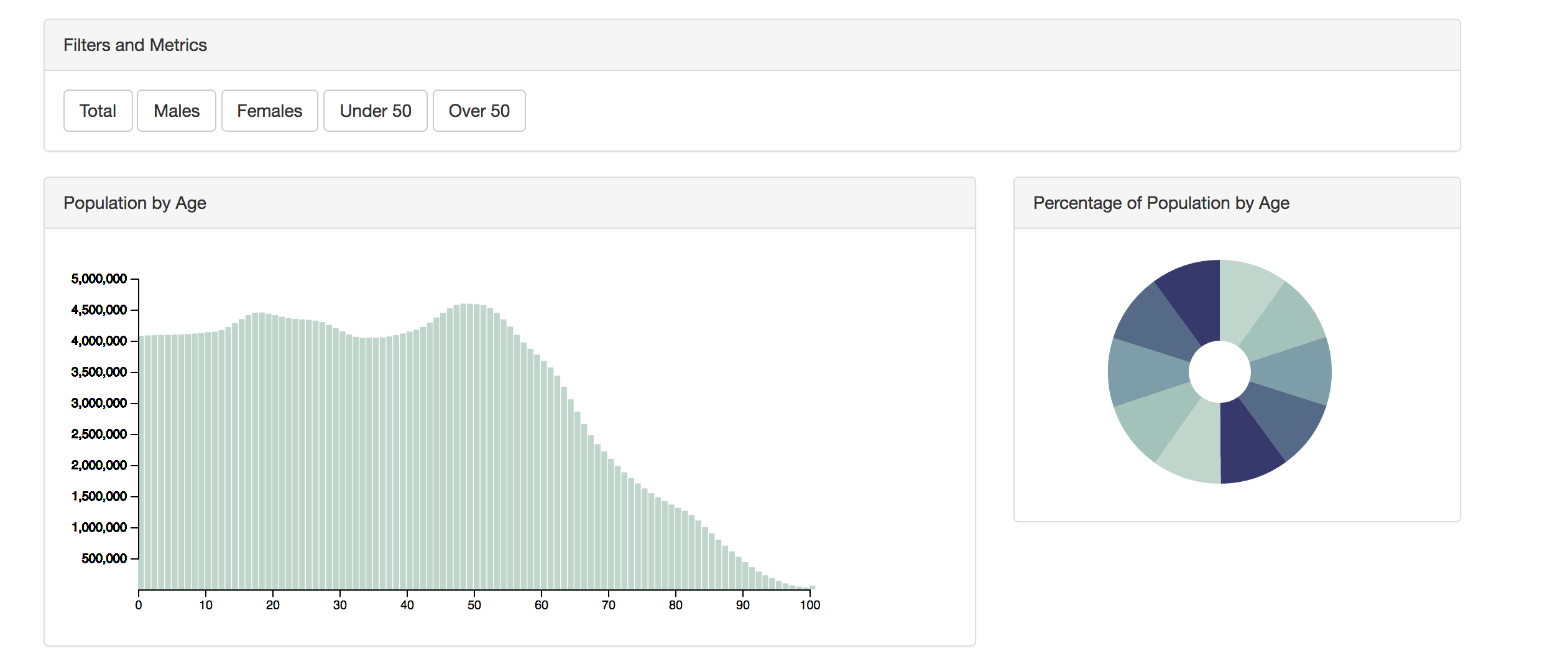
Производительность и особенности
Что нужно учитывать при передаче данных пользователям? Дайте им возможность анализировать данные, не давая им возможности облажаться. Это означает контроль над тем, сколько разных измерений / мер им нужно поиграть. Это поможет с точки зрения производительности, так как вы не передаете большие наборы данных по проводам, а также ограничивает количество сокращений чисел, которое необходимо выполнить на стороне клиента.
Будьте осторожны: это не означает, что набор данных должен быть полностью агрегированным. Вы хотите, чтобы это было гибким. Укажите набор из четырех или пяти ключевых показателей, которые можно выбрать. Сохраняйте несколько разных измерений в наборе данных, чтобы можно было группировать ваши данные и агрегировать, используя такие вещи, как функции массива JavaScript ( filterreducemap Следует учитывать производительность и возможности пользователей в том, как они могут анализировать свои данные.
После того, как у вас есть набор данных, важно знать, как вы собираетесь представлять свои данные. Вот пример набора данных JSON в сборе:
[{
"females": 1994141,
"country": "United States",
"age": 0,
"males": 2085528,
"year": 2010,
"total": 4079669
}, {
"females": 1997991,
"country": "United States",
"age": 1,
"males": 2087350,
"year": 2010,
"total": 4085341
}, {
"females": 2000746,
"country": "United States",
"age": 2,
"males": 2088549,
"year": 2010,
"total": 4089295
}, {
// ...
Из этого набора данных видно, что у нас есть несколько измерений (возраст, год, страна) и несколько метрик (женщины, мужчины и общее количество). Это даст нам достаточно информации для графического отображения, а также даст возможность разрезать данные несколькими различными способами.
Скажем, например, что мы хотим сгруппировать данные в соответствующие возрастные группы. Мы можем использовать функции массива JavaScript, чтобы свернуть возрастные группы в Gen X, Baby Boomers и т. Д. Без необходимости делать какие-либо дополнительные вызовы на сервер и повторно отображать его в SVG непосредственно на клиентском компьютере.
Как вы можете видеть из демонстрации , мы представляем данные с несколькими различными визуальными опциями, а также предоставляем несколько кнопок для фильтрации данных и выбора метрик. Это ключ к предоставлению пользователю возможности анализировать свои данные.
Настройте функции для визуализации ваших данных и установите необходимую метрику:
document.getElementById("total").addEventListener('click', function() {
barGraph.render(d, "total")
});
Используйте filter()
document.getElementById("over50").addEventListener('click', function() {
const td = d.filter(function(a) {
return a.age >= 50
});
barGraph.render(td, "total");
});
Присвойте их функциям фильтрам в вашем документе, и вы сможете фильтровать ваш набор данных, изменять метрики и разбивать данные на части по своему усмотрению.
Резюме
В конце концов, вы должны использовать методологию доступа к данным, которая подходит для вашей команды и их конкретных навыков. Благодаря продуманно разработанному уровню хранения данных, надлежащему уровню доступа к данным и подходящим интерфейсным инструментам для представления данных ваши пользователи получат прочную основу для составления отчетов.
Я надеюсь, что эта статья предоставила вам обзор важных соображений при создании приложений, управляемых данными. Если есть что-то, о чем вы хотели бы узнать больше, пожалуйста, дайте мне знать в комментариях!