
GraphQL — это язык запросов для API. Хотя GraphQL принципиально отличается от REST, GraphQL может служить альтернативой REST, которая предлагает производительность, отличный опыт разработчика и очень мощные инструменты.
В этой статье мы рассмотрим, как можно решить несколько распространенных сценариев использования с REST и GraphQL. Эта статья поставляется в комплекте с тремя проектами. Вы найдете код для API REST и GraphQL, который предоставляет информацию о популярных фильмах и актерах, а также простое приложение с веб-интерфейсом, построенное на HTML и jQuery.
Мы собираемся использовать эти API, чтобы посмотреть, как эти технологии отличаются, чтобы мы могли определить их сильные и слабые стороны. Однако для начала давайте подготовим почву, кратко рассмотрев, как появились эти технологии.
Первые дни Интернета
Первые дни в Интернете были просты. Веб-приложения начинались как статические HTML-документы, которые обслуживались через Интернет Веб-сайты усовершенствованы, чтобы включать динамический контент, хранящийся в базах данных (например, SQL), и использовать JavaScript для добавления интерактивности Подавляющее большинство веб-контента просматривалось через веб-браузеры на настольных компьютерах, и все было хорошо с миром.
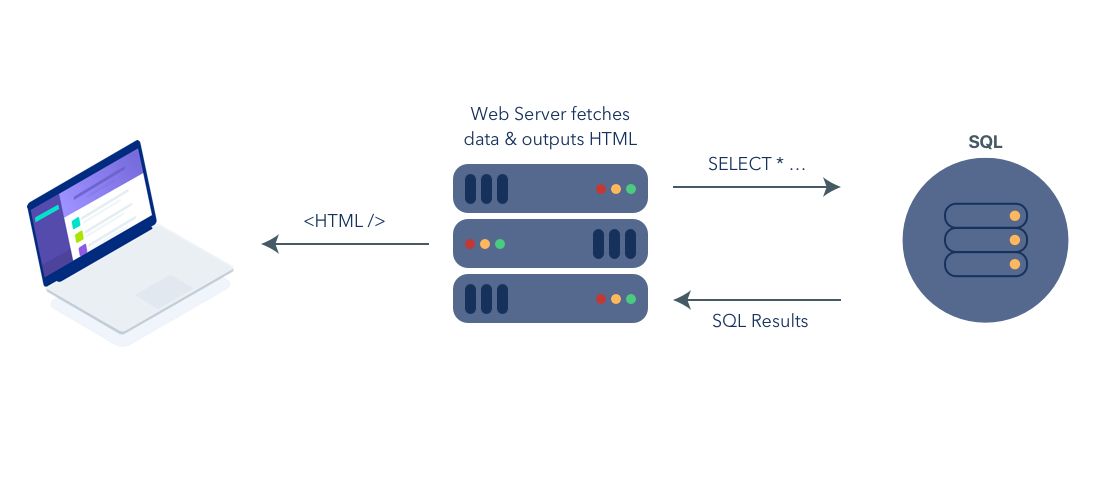
ОТДЫХ: рост API
Перенесемся в 2007 год, когда Стив Джобс представил iPhone. В дополнение к далеко идущим последствиям, которые смартфон может оказать на мир, культуру и коммуникации, он также значительно усложнил жизнь разработчиков. Смартфон нарушил статус-кво развития. Через несколько коротких лет у нас неожиданно появились настольные компьютеры, айфоны, Android и планшеты.
В ответ разработчики начали использовать API-интерфейсы RESTful для предоставления данных приложениям всех форм и размеров. Новая модель разработки выглядела примерно так:
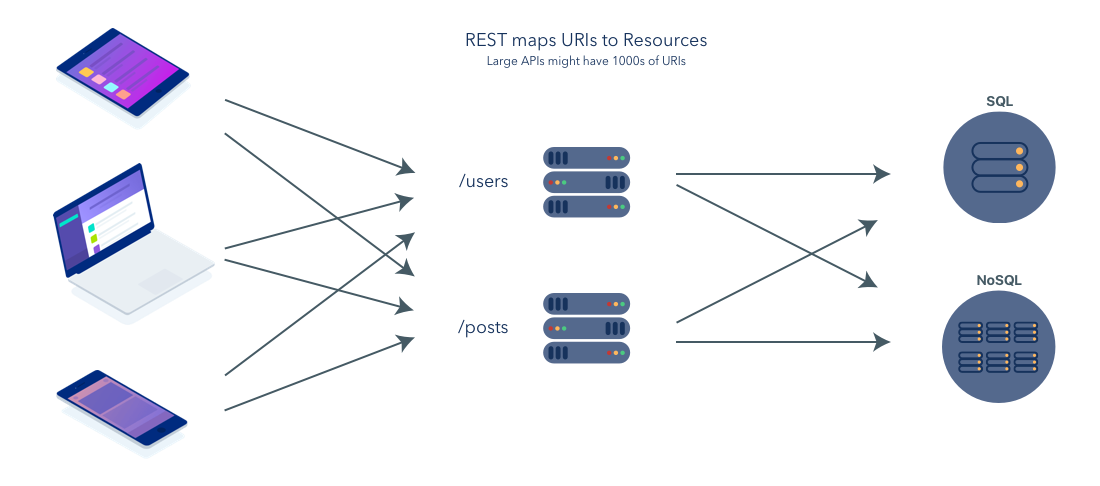
GraphQL: эволюция API
GraphQL — это язык запросов для API, который был разработан и открыт с помощью Facebook. Вы можете думать о GraphQL как об альтернативе REST для создания API. Принимая во внимание, что REST — это концептуальная модель, которую вы можете использовать для разработки и реализации своего API, GraphQL — это стандартизированный язык, система типов и спецификация, которая создает надежный контракт между клиентом и сервером. Наличие стандартного языка, с помощью которого все наши устройства взаимодействуют, упрощает процесс создания больших кроссплатформенных приложений.
С GraphQL наша диаграмма упрощает:
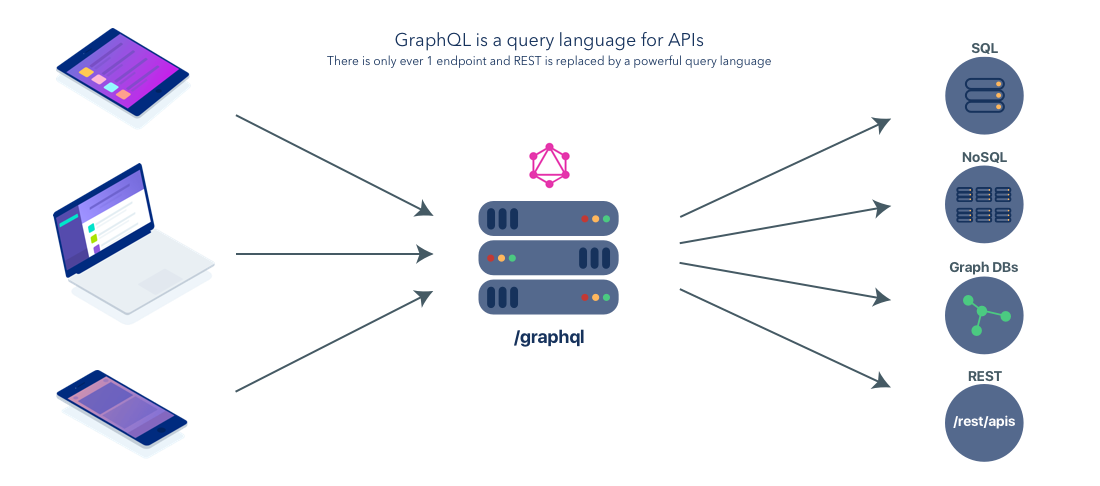
GraphQL против REST
На протяжении оставшейся части этого урока (без каламбура) я призываю вас следовать за кодом! Вы можете найти код этой статьи в сопроводительном репозитории GitHub .
Код включает три проекта:
- RESTful API
- GraphQL API и
- простая клиентская веб-страница, созданная с использованием jQuery и HTML.
Проекты преднамеренно просты и были разработаны, чтобы обеспечить как можно более простое сравнение между этими технологиями.
Если вы хотите продолжить, откройте три окна терминала и cd в GraphQL RESTful , GraphQL и Client в репозитории проекта. Из каждого из этих каталогов запустите сервер разработки через npm run dev . Как только у вас будут готовые серверы, продолжайте читать 🙂
Запрос с REST
Наш RESTful API содержит несколько конечных точек:
| Конечная точка | Описание |
|---|---|
| /кино | возвращает массив объектов, содержащих ссылки на наши фильмы (например, [{href: ‘http: // localhost / movie / 1’}] |
| / Фильм /: идентификатор | возвращает один фильм с id =: id |
| / кино /: ID / актеры | возвращает массив объектов, содержащих ссылки на актеров в фильме с id =: id |
| / актеры | возвращает массив объектов, содержащих ссылки на актеров |
| / Актер /: идентификатор | возвращает одного актера с id =: id |
| / актер /: / ID фильмы | возвращает массив объектов, содержащих ссылки на фильмы, в которых действовал актер с id =: id |
Примечание . Наша простая модель данных уже имеет 6 конечных точек, которые нам необходимо поддерживать и документировать.
Давайте представим, что мы являемся клиентскими разработчиками, которым нужно использовать наш API фильмов для создания простой веб-страницы с HTML и jQuery. Чтобы создать эту страницу, нам нужна информация о наших фильмах, а также об актерах, которые в них появляются. Наш API имеет все функциональные возможности, которые нам могут понадобиться, поэтому давайте продолжим и получим данные.
Если вы открываете новый терминал и запускаете
curl localhost:3000/movies
Вы должны получить ответ, который выглядит следующим образом:
[ { "href": "http://localhost:3000/movie/1" }, { "href": "http://localhost:3000/movie/2" }, { "href": "http://localhost:3000/movie/3" }, { "href": "http://localhost:3000/movie/4" }, { "href": "http://localhost:3000/movie/5" } ]
В режиме RESTful API вернул массив ссылок на реальные объекты фильма. Затем мы можем получить первый фильм, запустив curl http://localhost:3000/movie/1 а второй — curl http://localhost:3000/movie/2 и так далее, и так далее.
Если вы посмотрите на app.js вы увидите нашу функцию для извлечения всех данных, которые нам нужны для заполнения нашей страницы:
const API_URL = 'http://localhost:3000/movies'; function fetchDataV1() { // 1 call to get the movie links $.get(API_URL, movieLinks => { movieLinks.forEach(movieLink => { // For each movie link, grab the movie object $.get(movieLink.href, movie => { $('#movies').append(buildMovieElement(movie)) // One call (for each movie) to get the links to actors in this movie $.get(movie.actors, actorLinks => { actorLinks.forEach(actorLink => { // For each actor for each movie, grab the actor object $.get(actorLink.href, actor => { const selector = '#' + getMovieId(movie) + ' .actors'; const actorElement = buildActorElement(actor); $(selector).append(actorElement); }) }) }) }) }) }) }
Как вы могли заметить, это не идеально. Когда все сказано и сделано, мы сделали 1 + M + M + sum(Am) вызовов туда и обратно в наш API, где M — количество фильмов, а sum (Am) — сумма количества действующих кредитов в каждом из М фильмы. Для приложений с небольшими требованиями к данным это может быть хорошо, но никогда не будет работать в большой производственной системе.
Вывод? Наш простой подход RESTful не адекватен. Чтобы улучшить наш API, мы могли бы попросить кого-нибудь из бэкэнд-команды создать для нас специальную /moviesAndActors точку /moviesAndActors для поддержки этой страницы. Как только эта конечная точка готова, мы можем заменить наши сетевые вызовы 1 + M + M + sum(Am) одним запросом.
curl http://localhost:3000/moviesAndActors
Теперь это возвращает полезную нагрузку, которая должна выглядеть примерно так:
[ { "id": 1, "title": "The Shawshank Redemption", "release_year": 1993, "tags": [ "Crime", "Drama" ], "rating": 9.3, "actors": [ { "id": 1, "name": "Tim Robbins", "dob": "10/16/1958", "num_credits": 73, "image": "https://images-na.ssl-images-amazon.com/images/M/MV5BMTI1OTYxNzAxOF5BMl5BanBnXkFtZTYwNTE5ODI4._V1_.jpg", "href": "http://localhost:3000/actor/1", "movies": "http://localhost:3000/actor/1/movies" }, { "id": 2, "name": "Morgan Freeman", "dob": "06/01/1937", "num_credits": 120, "image": "https://images-na.ssl-images-amazon.com/images/M/MV5BMTc0MDMyMzI2OF5BMl5BanBnXkFtZTcwMzM2OTk1MQ@@._V1_UX214_CR0,0,214,317_AL_.jpg", "href": "http://localhost:3000/actor/2", "movies": "http://localhost:3000/actor/2/movies" } ], "image": "https://images-na.ssl-images-amazon.com/images/M/MV5BODU4MjU4NjIwNl5BMl5BanBnXkFtZTgwMDU2MjEyMDE@._V1_UX182_CR0,0,182,268_AL_.jpg", "href": "http://localhost:3000/movie/1" }, ... ]
Большой! В одном запросе мы смогли получить все данные, необходимые для заполнения страницы. Оглядываясь назад на app.js в нашем каталоге Client мы видим улучшение в действии:
const MOVIES_AND_ACTORS_URL = 'http://localhost:3000/moviesAndActors'; function fetchDataV2() { $.get(MOVIES_AND_ACTORS_URL, movies => renderRoot(movies)); } function renderRoot(movies) { movies.forEach(movie => { $('#movies').append(buildMovieElement(movie)); movie.actors && movie.actors.forEach(actor => { const selector = '#' + getMovieId(movie) + ' .actors'; const actorElement = buildActorElement(actor); $(selector).append(actorElement); }) }); }
Наше новое приложение будет намного быстрее, чем на последней итерации, но оно все еще не идеально. Если вы откроете http://localhost:4000 и посмотрите на нашу простую веб-страницу, вы должны увидеть что-то вроде этого:
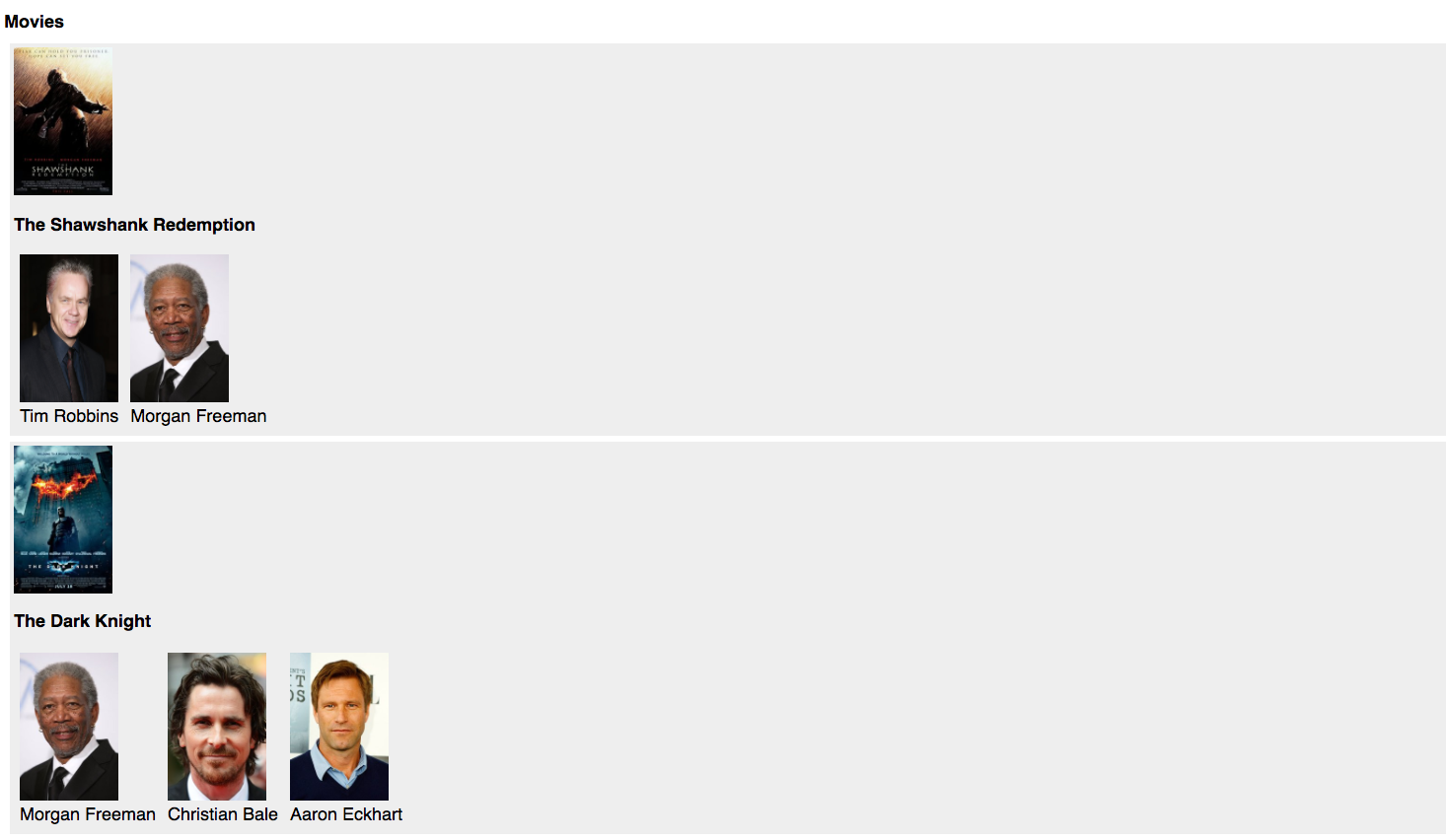
Если вы присмотритесь, вы заметите, что наша страница использует заголовок и изображение фильма, а также имя и изображение актера (т.е. мы используем только 2 из 8 полей в объекте фильма и 2 из 7 полей в объекте актера) , Это означает, что мы тратим примерно три четверти информации, которую мы запрашиваем по сети! Такое избыточное использование полосы пропускания может оказать реальное влияние на производительность и стоимость вашей инфраструктуры!
Опытный серверный разработчик может посмеяться над этим и быстро реализовать специальный параметр запроса с именем fields, который принимает массив имен полей, который будет динамически определять, какие поля должны быть возвращены в конкретном запросе.
Например, вместо curl http://localhost:3000/moviesAndActors у нас может быть curl http://localhost:3000/moviesAndActors?fields=title,image . У нас может даже быть другой специальный параметр запроса actor_fields который указывает, какие поля в моделях actor_fields должны быть включены. EG curl http://localhost:3000/moviesAndActors?fields=title,image&actor_fields=name,image .
Теперь это было бы почти оптимальной реализацией для нашего простого приложения, но оно порождает дурную привычку, когда мы создаем пользовательские конечные точки для определенных страниц в наших клиентских приложениях. Проблема становится более очевидной, когда вы начинаете создавать приложение для iOS, которое отображает информацию, отличную от вашей веб-страницы, и приложение для Android, которое отображает информацию, отличную от приложения для iOS.
Не было бы неплохо, если бы мы могли создать общий API, который явно представляет сущности в нашей модели данных, а также отношения между этими сущностями, но не страдает от проблемы производительности 1 + M + M + sum(Am) ? Хорошие новости! Мы можем!
Запросы с GraphQL
С GraphQL мы можем перейти непосредственно к оптимальному запросу и получить всю необходимую нам информацию, и ничего более с помощью простого, интуитивно понятного запроса:
query MoviesAndActors { movies { title image actors { image name } } }
Шутки в сторону! Чтобы попробовать сами, откройте GraphiQL (отличную среду IDE GraphQL на основе браузера) по адресу http: // localhost: 5000 и выполните приведенный выше запрос.
Теперь давайте погрузимся немного глубже.
Мышление в GraphQL
GraphQL использует принципиально иной подход к API, чем REST. Вместо того чтобы полагаться на HTTP-конструкции, такие как глаголы и URI, он накладывает интуитивно понятный язык запросов и мощную систему типов поверх наших данных. Система типов предоставляет строго типизированный контракт между клиентом и сервером, а язык запросов предоставляет механизм, который разработчик клиента может использовать для оперативного извлечения любых данных, которые могут ему понадобиться для любой данной страницы.
GraphQL побуждает вас думать о ваших данных как о виртуальном графе информации. Объекты, которые содержат информацию, называются типами, и эти типы могут относиться друг к другу через поля. Запросы начинаются с корня и пересекают этот виртуальный граф, собирая необходимую им информацию по пути.
Этот «виртуальный граф» более явно выражен в виде схемы . Схема — это набор типов, интерфейсов, перечислений и объединений, которые составляют модель данных вашего API. GraphQL даже включает удобный язык схемы, который мы можем использовать для определения нашего API. Например, это схема для нашего API фильма:
schema { query: Query } type Query { movies: [Movie] actors: [Actor] movie(id: Int!): Movie actor(id: Int!): Actor searchMovies(term: String): [Movie] searchActors(term: String): [Actor] } type Movie { id: Int title: String image: String release_year: Int tags: [String] rating: Float actors: [Actor] } type Actor { id: Int name: String image: String dob: String num_credits: Int movies: [Movie] }
Система типов открывает двери для множества удивительных вещей, включая лучшие инструменты, лучшую документацию и более эффективные приложения. Нам есть о чем поговорить, но сейчас давайте пропустим и выделим еще несколько сценариев, демонстрирующих различия между REST и GraphQL.
GraphQL vs Rest: управление версиями
Простой поиск в Google приведет к множеству мнений о том, как лучше всего разработать (или развить) REST API. Мы не собираемся спускаться по этой кроличьей норе, но я хочу подчеркнуть, что это нетривиальная проблема. Одна из причин того, что управление версиями так сложно, состоит в том, что зачастую очень трудно узнать, какая информация используется и какими приложениями или устройствами.
Добавление информации обычно легко как с REST, так и с GraphQL. Добавьте поле, и оно будет передаваться вашим клиентам REST и будет безопасно игнорироваться в GraphQL, пока вы не измените свои запросы. Однако удаление и редактирование информации — это отдельная история.
В REST трудно определить на полевом уровне, какая информация используется. Мы можем знать, что используется конечная точка /movies , но мы не знаем, использует ли клиент заголовок, изображение или и то, и другое. Возможным решением является добавление fields параметров запроса, которые указывают, какие поля возвращать, но эти параметры почти всегда являются необязательными. По этой причине вы часто будете наблюдать эволюцию на уровне конечной точки, где мы представляем новую конечную точку /v2/movies . Это работает, но также увеличивает площадь нашего API, а также увеличивает нагрузку на разработчика, чтобы поддерживать актуальность и полную документацию.
Управление версиями в GraphQL очень отличается. Каждый запрос GraphQL должен точно указывать, какие поля запрашиваются в любом данном запросе. Тот факт, что это обязательно, означает, что мы точно знаем, какая информация запрашивается, и позволяет нам задавать вопрос о том, как часто и кем. GraphQL также включает в себя примитивы, которые позволяют нам украшать схему устаревшими полями и сообщениями, почему они являются устаревшими.
Вот как выглядит версия в GraphQL:

GraphQL против REST: кеширование
Кэширование в REST является простым и эффективным. На самом деле, кэширование является одним из шести направляющих ограничений REST и включается в дизайн RESTful. Если ответ от конечной точки /movies/1 указывает, что ответ может быть кэширован, любые будущие запросы к /movies/1 могут быть просто заменены элементом в кэше. Просто.
Кеширование в GraphQL решается немного иначе. Кэширование API-интерфейса GraphQL часто требует введения какого-то уникального идентификатора для каждого объекта в API. Когда каждый объект имеет уникальный идентификатор, клиенты могут создавать нормализованные кэши, которые используют этот идентификатор для надежного кэширования, обновления и устаревания объектов. Когда клиент выдает нижестоящие запросы, которые ссылаются на этот объект, вместо него может использоваться кэшированная версия объекта. Если вы хотите узнать больше о том, как работает кеширование в GraphQL, вот хорошая статья, которая более подробно освещает эту тему .
GraphQL vs REST: опыт разработчика
Опыт разработчиков является чрезвычайно важным аспектом разработки приложений и является причиной, по которой мы, инженеры, уделяем так много времени созданию хороших инструментов. Сравнение здесь несколько субъективно, но я думаю, что все же важно упомянуть.
REST проверен и верен и имеет богатую экосистему инструментов, помогающих разработчикам документировать, тестировать и проверять API-интерфейсы RESTful. С учетом вышесказанного разработчики платят огромную цену за масштабирование API REST. Количество конечных точек быстро становится огромным, несоответствия становятся более очевидными, а управление версиями остается трудным.
GraphQL действительно превосходен в отделе опыта разработчиков. Система типов открыла двери для удивительных инструментов, таких как GraphiQL IDE, и документация встроена в саму схему. В GraphQL также есть только одна конечная точка, и вместо того, чтобы полагаться на документацию, чтобы выяснить, какие данные доступны, у вас есть типобезопасный язык и автозаполнение, которые вы можете использовать, чтобы быстро освоиться с API. GraphQL также был разработан для блестящей работы с современными интерфейсными средами и инструментами, такими как React и Redux. Если вы думаете о создании приложения с помощью React, я настоятельно рекомендую вам воспользоваться клиентом Relay или Apollo .
Вывод
GraphQL предлагает несколько более самоуверенный, но чрезвычайно мощный набор инструментов для создания эффективных приложений, управляемых данными. REST не исчезнет в ближайшее время, но есть много чего желать, особенно когда речь идет о создании клиентских приложений.
Если вы заинтересованы в получении дополнительной информации, посмотрите BackQL-скрипт Scaphold.io как сервис . Через несколько минут у вас будет готовый к работе API GraphQL, развернутый в AWS и готовый для настройки и расширения с вашей собственной бизнес-логикой.
Я надеюсь, вам понравился этот пост, и если у вас есть какие-либо мысли или комментарии, я хотел бы услышать от вас. Спасибо за прочтение!