Цикл разработки, основанный на тестировании, упрощает процесс написания кода, делает его более простым и быстрым в долгосрочной перспективе. Но просто написание тестов само по себе недостаточно, зная, какие типы тестов нужно писать и как структурировать код для соответствия этому шаблону, это все, что нужно. В этой статье мы рассмотрим создание небольшого приложения в Node.js по шаблону TDD.
Помимо простых «юнит-тестов», с которыми мы все знакомы; У нас также может быть запущен асинхронный код Node.js, который добавляет дополнительное измерение, в котором мы не всегда знаем порядок, в котором выполняются функции, или мы можем пытаться что-то проверить в обратном вызове или проверить, как работает асинхронная функция. работает.
В этой статье мы будем создавать приложение Node, которое может искать файлы, соответствующие заданному запросу. Я знаю, что уже есть что-то для этого ( ack ), но ради демонстрации TDD я думаю, что это может быть хорошо округленный проект.
Первым шагом, очевидно, является написание некоторых тестов, но даже до этого нам нужно выбрать среду тестирования. Вы можете использовать vanilla Node, так как есть встроенная библиотека assert , но это не так много, как с точки зрения тестового бегуна, и это в значительной степени самое необходимое.
Другой вариант, и, вероятно, мой любимый для общего пользования, это жасмин . Он довольно самодостаточен, у вас нет других зависимостей, которые можно добавить в ваши скрипты, а синтаксис очень чистый и легко читаемый. Единственная причина, по которой я не собираюсь использовать это сегодня, заключается в том, что я думаю, что Джек Франклин отлично справился с этой задачей в своей недавней серии Tuts + , и было бы хорошо узнать ваши варианты, чтобы вы могли выбрать лучший инструмент для вашей ситуации.
Что мы будем строить
В этой статье мы будем использовать гибкий тестер Mocha вместе с библиотекой утверждений Chai .
В отличие от Jasmine, который больше похож на целый набор тестов в одном пакете, Mocha заботится только об общей структуре, но не имеет ничего общего с реальными утверждениями. Это позволяет вам поддерживать единообразный внешний вид при выполнении тестов, а также позволяет запускать любую библиотеку утверждений, которая лучше всего подходит для вашей ситуации.
Например, если вы собираетесь использовать ванильную библиотеку assert, вы можете связать ее с Mocha, чтобы добавить некоторую структуру в ваши тесты.
Чай — довольно популярный вариант, а также все о вариантах и модульности. Даже без каких-либо плагинов, просто используя API по умолчанию, у вас есть три различных синтаксиса, которые вы можете использовать в зависимости от того, хотите ли вы использовать более классический стиль TDD или более подробный синтаксис BDD.
Теперь, когда мы знаем, что будем использовать, давайте приступим к установке.
Настройка
Для начала давайте установим Mocha глобально, запустив:
|
1
|
npm install -g mocha
|
Когда это завершится, создайте новую папку для нашего проекта и запустите в ней следующее:
|
1
|
npm install chai
|
Это установит локальную копию Chai для нашего проекта. Затем создайте папку с именем test в каталоге нашего проекта, так как это местоположение по умолчанию, которое Mocha будет искать для тестов.
Вот и все, что нужно для настройки, следующий шаг — поговорить о том, как структурировать приложения, следуя процессу разработки, управляемому тестами.
Структурирование вашего приложения
При следовании подходу TDD важно знать, что нужно проводить тесты, а что нет. Практическое правило — не писать тесты для других людей, уже протестировавших код. Под этим я подразумеваю следующее: допустим, ваш код открывает файл, вам не нужно тестировать отдельную функцию fs , она является частью языка и предположительно уже хорошо протестирована. То же самое происходит при использовании сторонних библиотек, вы не должны структурировать функции, которые в первую очередь вызывают эти типы функций. Вы действительно не пишете тесты для них, и из-за этого у вас есть пробелы в цикле TDD.
Теперь, конечно, с каждым стилем программирования есть много разных мнений, и люди будут иметь разные взгляды на то, как использовать TDD. Но подход, который я использую, заключается в том, что вы создаете отдельные компоненты для использования в своем приложении, каждый из которых решает уникальную функциональную проблему. Эти компоненты построены с использованием TDD, что гарантирует их правильную работу, и вы не нарушите их API. Затем вы пишете свой основной сценарий, который, по сути, представляет собой весь связующий код и не нуждается в проверке / не может быть проверен в определенных ситуациях.
Это также означает, что большинство ваших компонентов могут быть повторно использованы в будущем, поскольку они не имеют непосредственного отношения к основному сценарию.
Следуя тому, что я только что сказал, обычной практикой является создание папки с именем « lib », в которую вы помещаете все отдельные компоненты. Таким образом, до этого момента у вас должны быть установлены Mocha и Chai, а затем каталог проекта с двумя папками: « lib » и « test ».
Начало работы с TDD
На всякий случай, если вы новичок в TDD, я подумал, что было бы неплохо быстро рассказать о процессе. Основное правило заключается в том, что вы не можете писать какой-либо код, если тестировщик не скажет вам об этом.
По сути, вы пишете, что должен делать ваш код, прежде чем делать это на самом деле. Во время кодирования у вас есть действительно сфокусированная цель, и вы никогда не ставите под угрозу свою идею, отстраняясь или думая слишком далеко вперед. Кроме того, поскольку весь ваш код будет связан с тестом, вы можете быть уверены, что никогда не сломаете свое приложение в будущем.
На самом деле тест — это просто объявление того, что функция должна делать при запуске, затем вы запускаете тестовый прогон, который, очевидно, завершится ошибкой (поскольку вы еще не написали код), а затем вы пишете минимальное количество кода, необходимого для прохождения неудачного теста. Важно никогда не пропускать этот шаг, потому что иногда тест будет проходить еще до того, как вы добавите какой-либо код, из-за другого кода, который есть в том же классе или функции. Когда это происходит, вы либо написали больше кода, чем предполагалось, для другого теста, или это просто плохой тест (обычно недостаточно конкретный).
Опять же, согласно нашему правилу, приведенному выше, если тест пройден сразу, вы не сможете написать код, потому что он не сказал вам об этом. Постоянно создавая тесты, а затем реализуя функции, вы создаете надежные модули, на которые можно положиться.
Когда вы закончите реализацию и тестирование своего компонента, вы можете вернуться и выполнить рефакторинг кода, чтобы оптимизировать его и очистить, но убедившись, что рефакторинг не провалит ни один из ваших тестов и, что более важно, t добавить любые функции, которые не были протестированы.
Каждая тестирующая библиотека будет иметь свой собственный синтаксис, но они обычно следуют одному и тому же шаблону: делают утверждения и затем проверяют, прошли ли они. Поскольку мы используем Mocha и Chai, давайте рассмотрим оба их синтаксиса, начиная с Chai.
Мокко и чай
Я буду использовать синтаксис BDD «Expect», потому что, как я уже говорил, Chai поставляется с несколькими опциями из коробки. Этот синтаксис работает так: вы начинаете с вызова ожидающей функции, передаваете объект, для которого хотите сделать утверждение, а затем цепляете его с помощью специального теста. Пример того, что я имею в виду, может быть следующим:
|
1
|
expect(4+5).equal(9);
|
Это основной синтаксис, мы говорим, ожидать, что сложение 4 и 5 будет равно 9 . Теперь это не очень хороший тест, потому что 4 и 5 будут добавлены Node.js до того, как функция будет вызвана, поэтому мы в основном проверяем мои математические навыки, но я надеюсь, что вы поняли основную идею. Еще одна вещь, которую вы должны заметить, это то, что этот синтаксис не очень читабелен, с точки зрения потока нормального английского предложения. Зная это, Чай добавил следующие цепочечные геттеры, которые ничего не делают, но вы можете добавить их, чтобы сделать их более подробными и удобочитаемыми. Цепные геттеры следующие:
- в
- быть
- было
- является
- тот
- и
- иметь
- с
- в
- из
- одна и та же
Используя вышеизложенное, мы можем переписать наш предыдущий тест примерно так:
|
1
|
expect(4+5).to.equal(9);
|
Мне очень нравится ощущение всей библиотеки, которое вы можете проверить в их API . Простые вещи, такие как отрицание операции, так же легко, как написать. .not перед тестом:
|
1
|
expect(4+5).to.not.equal(10);
|
Поэтому, даже если вы никогда ранее не использовали библиотеку, не составит труда выяснить, что пытается сделать тест.
Последнее, что я хотел бы рассмотреть, прежде чем мы приступим к нашему первому тесту, — это то, как мы структурируем наш код в Mocha.
кофе мокко
Mocha — это организатор тестов, поэтому он не особо заботится о реальных тестах, его интересует структура тестов, потому что именно так он знает, что дает сбой, и как расположить результаты. Вы создаете несколько блоков describe которые описывают различные компоненты вашей библиотеки, а затем добавляете блоки для определения конкретного теста.
В качестве быстрого примера, скажем, у нас был класс JSON, и у этого класса была функция для анализа JSON, и мы хотели убедиться, что функция синтаксического анализа может обнаружить плохо отформатированную строку JSON, мы могли бы структурировать это так:
|
1
2
3
4
5
6
7
|
describe(«JSON», function() {
describe(«.parse()», function() {
it(«should detect malformed JSON strings», function(){
//Test Goes Here
});
});
});
|
Это не сложно, и это около 80% личных предпочтений, но если вы сохраните этот формат, результаты теста должны быть в очень удобочитаемом формате.
Теперь мы готовы написать нашу первую библиотеку, давайте начнем с простого синхронного модуля, чтобы лучше познакомиться с системой. Наше приложение должно будет иметь возможность принимать параметры командной строки для установки таких параметров, как количество уровней папок, в которых наше приложение должно искать, и сам запрос.
Чтобы позаботиться обо всем этом, мы создадим модуль, который принимает строку команды и анализирует все включенные параметры вместе с их значениями.
Модуль Tag
Это отличный пример модуля, который вы можете использовать во всех своих приложениях командной строки, так как эта проблема часто возникает. Это будет упрощенная версия реального пакета, который у меня есть на npm, называется ClTags . Поэтому для начала создайте файл с именем tags.js внутри папки lib, а затем другой файл с именем tagsSpec.js внутри папки тестирования.
Нам нужно включить функцию ожидания Chai, так как это будет синтаксис утверждения, который мы будем использовать, и нам нужно извлечь файл фактических тегов, чтобы мы могли его протестировать. В целом с некоторой начальной настройкой это должно выглядеть примерно так:
|
1
2
3
4
5
6
|
var expect = require(«chai»).expect;
var tags = require(«../lib/tags.js»);
describe(«Tags», function(){
});
|
Если вы сейчас запустите команду ‘mocha’ из корня нашего проекта, все должно пройти, как и ожидалось. Теперь давайте подумаем о том, что будет делать наш модуль; мы хотим передать ему массив аргументов команды, который использовался для запуска приложения, а затем мы хотим, чтобы он создал объект со всеми тегами, и было бы неплохо, если бы мы также могли передать ему объект настроек по умолчанию, так что если ничего не будет переопределено, некоторые настройки уже будут сохранены.
При работе с тегами многие приложения также предоставляют опции быстрого доступа, которые представляют собой всего один символ, поэтому, скажем, мы хотели установить глубину нашего поиска, мы могли бы позволить пользователю указать что-то вроде --depth=2 или что-то вроде -d=2 что должно иметь тот же эффект.
Итак, давайте начнем с длинно сформированных тегов (например, ‘—depth = 2’). Для начала давайте напишем первый тест:
|
01
02
03
04
05
06
07
08
09
10
11
|
describe(«Tags», function(){
describe(«#parse()», function(){
it(«should parse long formed tags», function(){
var args = [«—depth=4», «—hello=world»];
var results = tags.parse(args);
expect(results).to.have.a.property(«depth», 4);
expect(results).to.have.a.property(«hello», «world»);
});
});
});
|
Мы добавили один метод в наш набор тестов, который называется parse и добавили тест для длинных тегов. В этом тесте я создал пример команды и добавил два утверждения для двух свойств, которые он должен получить.
Запустив Mocha сейчас, вы должны получить одну ошибку, а именно, что у tags нет функции parse . Чтобы исправить эту ошибку, давайте добавим функцию parse в модуль тегов. Довольно типичный способ создания модуля узла выглядит так:
|
1
2
3
4
5
|
exports = module.exports = {};
exports.parse = function() {
}
|
В ошибке говорилось, что нам нужен метод parse поэтому мы создали его, мы не добавили никакого другого кода, потому что он еще не сказал нам. Придерживаясь минимума, вы уверены, что не будете писать больше, чем предполагалось, и в итоге получите непроверенный код.
Теперь давайте снова запустим Mocha, на этот раз у нас должна появиться ошибка, сообщающая нам, что он не может прочитать свойство с именем depth из неопределенной переменной. Это потому, что в настоящее время наша функция parse ничего не возвращает, поэтому давайте добавим некоторый код, чтобы он возвращал объект:
|
1
2
3
4
5
|
exports.parse = function() {
var options = {}
return options;
}
|
Мы медленно продвигаемся вперед, если вы снова запустите Mocha, их не должно быть никаких исключений, просто чистое сообщение об ошибке, говорящее, что у нашего пустого объекта нет свойства, называемого depth .
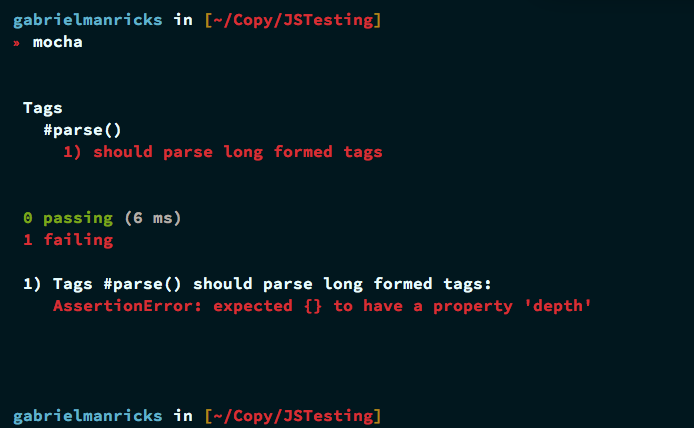
Теперь мы можем войти в некоторый реальный код. Чтобы наша функция проанализировала тег и добавила его к нашему объекту, нам нужно циклически перебрать массив аргументов и удалить двойные тире в начале ключа.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
exports.parse = function(args) {
var options = {}
for (var i in args) { //Cycle through args
var arg = args[i];
//Check if Long formed tag
if (arg.substr(0, 2) === «—«) {
arg = arg.substr(2);
//Check for equals sign
if (arg.indexOf(«=») !== -1) {
arg = arg.split(«=»);
var key = arg.shift();
options[key] = arg.join(«=»);
}
}
}
return options;
}
|
Этот код циклически перебирает список аргументов, проверяет, имеем ли мы дело с длинным сформированным тегом, а затем разделяет его по первому символу равенства, чтобы создать пару ключ и значение для объекта параметров.
Теперь это почти решает нашу проблему, но если мы снова запустим Mocha, вы увидите, что теперь у нас есть ключ для глубины, но он установлен на строку вместо числа. С числами немного легче работать позже в нашем приложении, поэтому следующий фрагмент кода, который нам нужно добавить, — это конвертировать значения в числа, когда это возможно. Это может быть достигнуто с помощью некоторого RegEx и функции parseInt следующим образом:
|
01
02
03
04
05
06
07
08
09
10
|
if (arg.indexOf(«=») !== -1) {
arg = arg.split(«=»);
var key = arg.shift();
var value = arg.join(«=»);
if (/^[0-9]+$/.test(value)) {
value = parseInt(value, 10);
}
options[key] = value;
}
|
Запустив Mocha сейчас, вы должны пройти один тест. Возможно, преобразование чисел должно проводиться в своем собственном тесте или, по крайней мере, упоминаться в декларации тестов, чтобы вы по ошибке не удалили утверждение о преобразовании чисел; поэтому просто добавьте «добавить и преобразовать числа» в объявление it для этого теста или разделите его на новый блок it . Это действительно зависит от того, считаете ли вы это «очевидным поведением по умолчанию» или отдельной функцией.
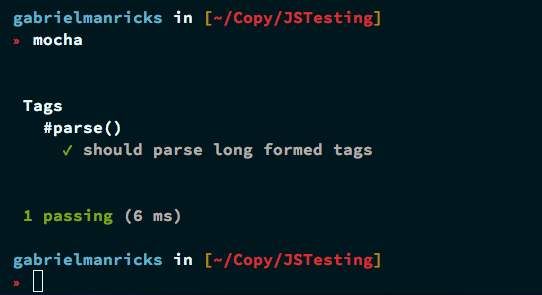
Теперь, как я пытался подчеркнуть во всей этой статье, когда вы видите прохождение спецификации, пришло время написать больше тестов. Следующим, что я хотел добавить, был массив по умолчанию, поэтому внутри файла tagsSpec давайте добавим следующий блок it сразу после предыдущего:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
it(«should parse long formed tags and convert numbers», function(){
var args = [«—depth=4», «—hello=world»];
var results = tags.parse(args);
expect(results).to.have.a.property(«depth», 4);
expect(results).to.have.a.property(«hello», «world»);
});
it(«should fallback to defaults», function(){
var args = [«—depth=4», «—hello=world»];
var defaults = { depth: 2, foo: «bar» };
var results = tags.parse(args, defaults);
var expected = {
depth: 4,
foo: «bar»,
hello: «world»
};
expect(results).to.deep.equal(expected);
});
|
Здесь мы используем новый тест, глубокое равенство, которое подходит для сопоставления двух объектов на одинаковые значения. В качестве альтернативы, вы можете использовать тест eql который является ярлыком, но я думаю, что это более понятно. Этот тест передает два аргумента в виде командной строки и передает два значения по умолчанию с одним перекрытием, просто чтобы мы могли получить хороший разброс тестовых случаев.
Запустив Mocha сейчас, вы должны получить что-то вроде diff, содержащее различия между тем, что ожидается, и тем, что оно действительно получило.
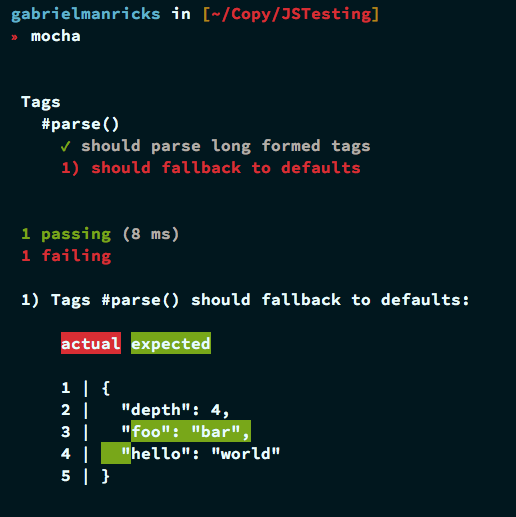
Давайте теперь вернемся к модулю tags.js и добавим эту функциональность. Это довольно простое исправление, мы просто должны принять второй параметр, и когда он установлен в объект, мы можем заменить стандартный пустой объект в начало с этим объектом:
|
1
2
3
4
5
|
exports.parse = function(args, defaults) {
var options = {};
if (typeof defaults === «object» && !(defaults instanceof Array)) {
options = defaults
}
|
Это вернет нас к зеленому состоянию. Следующее, что я хочу добавить, это возможность просто указать тег без значения и позволить ему работать как логическое значение. Например, если мы просто установим --searchContents или что-то в этом роде, он просто добавит это в наш массив опций со значением true .
Тест для этого будет выглядеть примерно так:
|
1
2
3
4
5
6
|
it(«should accept tags without values as a bool», function(){
var args = [«—searchContents»];
var results = tags.parse(args);
expect(results).to.have.a.property(«searchContents», true);
});
|
Выполнение этого даст нам следующую ошибку, как и раньше:
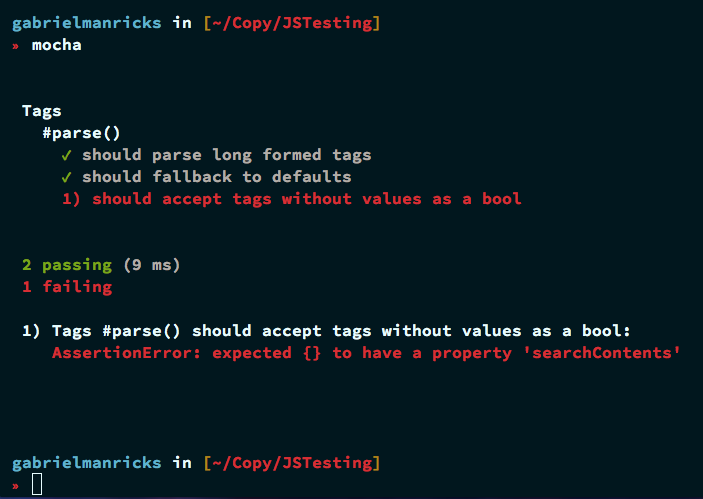
Внутри цикла for , когда мы получили совпадение для длинного тега, мы проверили, содержит ли он знак равенства; мы можем быстро написать код для этого теста, добавив к нему оператор else и просто установив для него значение true :
|
01
02
03
04
05
06
07
08
09
10
11
12
|
if (arg.indexOf(«=») !== -1) {
arg = arg.split(«=»);
var key = arg.shift();
var value = arg.join(«=»);
if (/^[0-9]+$/.test(value)) {
value = parseInt(value, 10);
}
options[key] = value;
} else {
options[arg] = true;
}
|
Следующее, что я хочу добавить, — это замена ярлыков с короткими руками. Это будет третий параметр функции parse и в основном будет объектом с буквами и соответствующими заменами. Вот спецификация для этого дополнения:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
it(«should accept short formed tags», function(){
var args = [«-sd=4», «-h»];
var replacements = {
s: «searchContents»,
d: «depth»,
h: «hello»
};
var results = tags.parse(args, {}, replacements);
var expected = {
searchContents: true,
depth: 4,
hello: true
};
expect(results).to.deep.equal(expected);
});
|
Проблема с сокращенными тегами состоит в том, что они могут быть объединены в ряд. Под этим я подразумеваю отличие от длинно сформированных тегов, каждый из которых является отдельным, с короткими ручками — поскольку каждый из них представляет собой просто букву длиной — вы можете вызвать три разных -vgh набрав -vgh . Это делает анализ немного более сложным, потому что нам все еще нужно разрешить оператору equals добавить значение к последнему упомянутому тегу, в то же время вам все равно нужно зарегистрировать другие теги. Но не волнуйтесь, это ничто, что не может быть решено с достаточным количеством сования и переключения.
Вот полное исправление с самого начала функции parse :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
exports.parse = function(args, defaults, replacements) {
var options = {};
if (typeof defaults === «object» && !(defaults instanceof Array)) {
options = defaults
}
if (typeof replacements === «object» && !(defaults instanceof Array)) {
for (var i in args) {
var arg = args[i];
if (arg.charAt(0) === «-» && arg.charAt(1) != «-«) {
arg = arg.substr(1);
if (arg.indexOf(«=») !== -1) {
arg = arg.split(«=»);
var keys = arg.shift();
var value = arg.join(«=»);
arg = keys.split(«»);
var key = arg.pop();
if (replacements.hasOwnProperty(key)) {
key = replacements[key];
}
args.push(«—» + key + «=» + value);
} else {
arg = arg.split(«»);
}
arg.forEach(function(key){
if (replacements.hasOwnProperty(key)) {
key = replacements[key];
}
args.push(«—» + key);
});
}
}
}
|
Это много кода (для сравнения), но все, что мы на самом деле делаем, это разделяем аргумент знаком равенства, а затем разбиваем этот ключ на отдельные буквы. Так, например, если мы -gj=asd мы -gj=asd asd в переменную с именем value , а затем gj раздел gj на отдельные символы. Последний символ (в нашем примере j ) станет ключом для значения ( asd ), тогда как любые другие буквы перед ним будут просто добавлены как обычные логические теги. Я не хотел просто обрабатывать эти теги сейчас, на случай, если мы изменим реализацию позже. Поэтому мы просто конвертируем эти короткие ярлыки в длинную версию и затем позволяем нашему сценарию обрабатывать это позже.
Повторный запуск Mocha вернет нас к нашим выдающимся зеленым результатам четырех прохождений теста для этого модуля.
Теперь есть еще несколько вещей, которые мы можем добавить в этот модуль тегов, чтобы сделать его ближе к пакету npm, например, возможность хранить текстовые аргументы для таких вещей, как команды, или возможность собирать весь текст в конце, для свойство запроса. Но эта статья уже становится длинной, и я хотел бы перейти к реализации функции поиска.
Модуль поиска
Мы только что пошли за созданием модуля шаг за шагом, следуя подходу TDD, и я надеюсь, что у вас есть идея и чувство, как писать так. Но ради продолжения этой статьи, для остальной части статьи я ускорю процесс тестирования, сгруппировав вещи и просто показывая вам окончательные версии тестов. Это скорее руководство к различным ситуациям, которые могут возникнуть, и к тому, как написать для них тесты.
Поэтому просто создайте файл с именем search.js внутри папки lib и файл searchSpec.js внутри тестовой папки.
Затем откройте файл спецификации и давайте настроим наш первый тест, который может быть для функции, чтобы получить список файлов на основе параметра depth , это также отличный пример для тестов, которые требуют немного внешней настройки для их работы. При работе с внешними объектно-подобными данными или в наших файлах дел вы захотите иметь предопределенную настройку, которая, как вы знаете, будет работать с вашими тестами, но вы также не хотите добавлять поддельную информацию в вашу систему.
В принципе, есть два варианта решения этой проблемы: вы можете либо смоделировать данные, как я упоминал выше, если вы имеете дело с собственными командами языков для загрузки данных, вам не обязательно проверять их. В таких случаях вы можете просто предоставить «извлеченные» данные и продолжить тестирование, что-то вроде того, что мы сделали с командной строкой в библиотеке тегов. Но в этом случае мы тестируем рекурсивную функциональность, которую мы добавляем в возможности чтения файлов языков, в зависимости от заданной глубины. В подобных случаях вам нужно написать тест, и поэтому нам нужно создать несколько демонстрационных файлов для проверки чтения файла. Альтернатива может заключаться в том, чтобы fs функции fs чтобы они просто запускались, но ничего не делали, и тогда мы можем подсчитать, сколько раз наша поддельная функция выполнялась или что-то в этом роде (посмотрите на шпионов ), но для нашего примера я просто собираюсь создать несколько файлы.
Mocha предоставляет функции, которые могут выполняться как до, так и после ваших тестов, поэтому вы можете выполнять такие виды внешней настройки и очистки вокруг ваших тестов.
В нашем примере мы создадим пару тестовых файлов и папок на двух разных глубинах, чтобы мы могли проверить эту функциональность:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
var expect = require(«chai»).expect;
var search = require(«../lib/search.js»);
var fs = require(«fs»);
describe(«Search», function(){
describe(«#scan()», function(){
before(function() {
if (!fs.existsSync(«.test_files»)) {
fs.mkdirSync(«.test_files»);
fs.writeFileSync(«.test_files/a», «»);
fs.writeFileSync(«.test_files/b», «»);
fs.mkdirSync(«.test_files/dir»);
fs.writeFileSync(«.test_files/dir/c», «»);
fs.mkdirSync(«.test_files/dir2»);
fs.writeFileSync(«.test_files/dir2/d», «»);
}
});
after(function() {
fs.unlinkSync(«.test_files/dir/c»);
fs.rmdirSync(«.test_files/dir»);
fs.unlinkSync(«.test_files/dir2/d»);
fs.rmdirSync(«.test_files/dir2»);
fs.unlinkSync(«.test_files/a»);
fs.unlinkSync(«.test_files/b»);
fs.rmdirSync(«.test_files»);
});
});
});
|
Они будут вызываться на основе блока describe они находятся, и вы даже можете запускать код до и после каждого блока, используя вместо этого beforeEach или afterEach . Сами функции просто используют стандартные команды узла для создания и удаления файлов соответственно. Далее нам нужно написать реальный тест. Это должно идти прямо рядом с функцией after , все еще внутри блока description:
|
01
02
03
04
05
06
07
08
09
10
11
|
it(«should retrieve the files from a directory», function(done) {
search.scan(«.test_files», 0, function(err, flist){
expect(flist).to.deep.equal([
«.test_files/a»,
«.test_files/b»,
«.test_files/dir/c»,
«.test_files/dir2/d»
]);
done();
});
});
|
Это наш первый пример тестирования асинхронной функции, но, как вы можете видеть, она так же проста, как и раньше; все, что нам нужно сделать, это использовать функцию done Mocha предоставляет в объявлениях it чтобы сообщить ей, когда мы закончим этот тест.
Mocha автоматически обнаружит, указали ли вы переменную done в обратном вызове, и будет ожидать ее вызова, что позволит вам действительно легко протестировать асинхронный код. Кроме того, стоит отметить, что этот шаблон доступен во всем Mocha, вы можете, например, использовать его в функциях before или after если вам нужно что-то установить асинхронно.
Далее я хотел бы написать тест, который проверяет, работает ли параметр глубины, если он установлен:
|
1
2
3
4
5
6
7
8
9
|
it(«should stop at a specified depth», function(done) {
search.scan(«.test_files», 1, function(err, flist) {
expect(flist).to.deep.equal([
«.test_files/a»,
«.test_files/b»,
]);
done();
});
});
|
Здесь нет ничего другого, просто еще один простой тест. Запустив это в Mocha, вы получите ошибку, что поиск не имеет никаких методов, в основном потому, что мы ничего не написали в нем. Итак, давайте добавим схему с функцией:
|
1
2
3
4
5
6
7
|
var fs = require(«fs»);
exports = module.exports = {};
exports.scan = function(dir, depth, done) {
}
|
Если вы снова запустите Mocha, он приостановит ожидание возврата этой асинхронной функции, но, поскольку мы вообще не вызывали функцию обратного вызова, тест просто остановится. По умолчанию время ожидания истекает примерно через две секунды, но вы можете отрегулировать его, используя this.timeout(milliseconds) внутри описания или блока, чтобы соответственно настроить их время ожидания.
Предполагается, что эта функция сканирования берет путь и глубину и возвращает список всех найденных файлов. Это на самом деле довольно сложно, когда вы начинаете думать о том, как мы, по сути, возвращаем две разные функции вместе в одну функцию. Нам нужно пройтись по разным папкам, а затем эти папки сами должны отсканировать и принять решение пойти дальше.
Делать это синхронно — это хорошо, потому что вы можете проходить через него один за другим, медленно проходя один уровень или путь за раз. При работе с асинхронной версией это становится немного сложнее, потому что вы не можете просто сделать цикл foreach или что-то еще, потому что он не будет делать паузу между папками, все они будут по существу работать одновременно, возвращая разные значения, и они будет перезаписывать друг друга.
Поэтому, чтобы это работало, вам нужно создать своего рода стек, в котором вы можете асинхронно обрабатывать по одному (или все сразу, если вместо этого используете очередь), а затем поддерживать некоторый порядок таким образом. Это очень специфический алгоритм, поэтому я оставляю фрагмент кода Кристофера Джеффри, который вы можете найти в Stack Overflow . Это не относится только к загрузке файлов, но я использовал это в ряде приложений, в основном во всех, где вам нужно обрабатывать массив объектов по одному, используя асинхронные функции.
Нам нужно немного его изменить, потому что нам хотелось бы иметь параметр глубины; как работает параметр глубины, вы устанавливаете, сколько уровней папок вы хотите проверять, или ноль повторяется бесконечно.
Вот завершенная функция, использующая фрагмент:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
exports.scan = function(dir, depth, done) {
depth—;
var results = [];
fs.readdir(dir, function(err, list) {
if (err) return done(err);
var i = 0;
(function next() {
var file = list[i++];
if (!file) return done(null, results);
file = dir + ‘/’ + file;
fs.stat(file, function(err, stat) {
if (stat && stat.isDirectory()) {
if (depth !== 0) {
var ndepth = (depth > 1) ?
exports.scan(file, ndepth, function(err, res) {
results = results.concat(res);
next();
});
} else {
next();
}
} else {
results.push(file);
next();
}
});
})();
});
};
|
Мокко теперь должен пройти оба теста. Последняя функция, которую нам нужно реализовать, это та, которая будет принимать массив путей и ключевое слово поиска и возвращать все совпадения. Вот тест для этого:
|
01
02
03
04
05
06
07
08
09
10
|
describe(«#match()», function(){
it(«should find and return matches based on a query», function(){
var files = [«hello.txt», «world.js», «another.js»];
var results = search.match(«.js», files);
expect(results).to.deep.equal([«world.js», «another.js»]);
results = search.match(«hello», files);
expect(results).to.deep.equal([«hello.txt»]);
});
});
|
И последнее, но не менее важное: давайте добавим функцию в search.js :
|
1
2
3
4
5
6
7
8
9
|
exports.match = function(query, files){
var matches = [];
files.forEach(function(name) {
if (name.indexOf(query) !== -1) {
matches.push(name);
}
});
return matches;
}
|
Просто чтобы убедиться, что запустите Mocha снова, вам нужно пройти всего семь тестов.
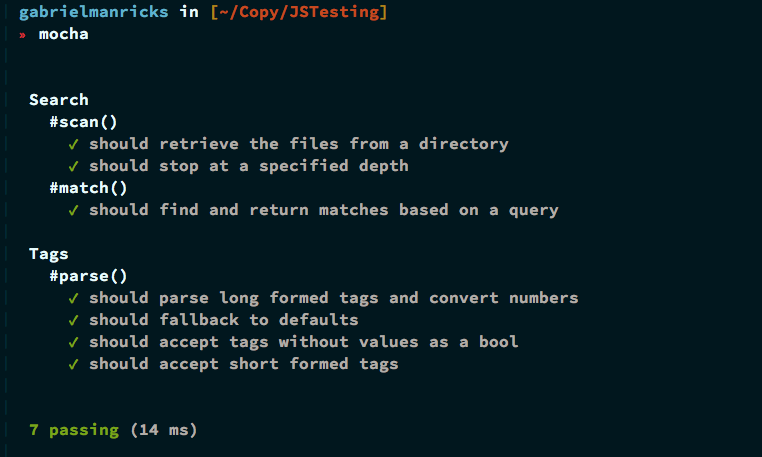
Собираем все вместе
Последний шаг — действительно написать связующий код, который объединяет все наши модули; поэтому в корне нашего проекта добавьте файл с именем app.js или что-то в этом роде и добавьте следующее:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
# !/usr/bin/env node
var tags = require(«./lib/tags.js»);
var search = require(«./lib/search.js»);
var defaults = {
path: «.»,
query: «»,
depth: 2
}
var replacements = {
p: «path»,
q: «query»,
d: «depth»,
h: «help»
}
tags = tags.parse(process.argv, defaults, replacements);
if (tags.help) {
console.log(«Usage: ./app.js -q=query [-d=depth] [-p=path]»);
} else {
search.scan(tags.path, tags.depth, function(err, files) {
search.match(tags.query, files).forEach(function(file){
console.log(file);
});
});
}
|
На самом деле никакой логики здесь не происходит, мы просто соединяем разные модули, чтобы получить желаемые результаты. Я обычно не тестирую этот код, так как это просто клейкий код, который уже был протестирован.
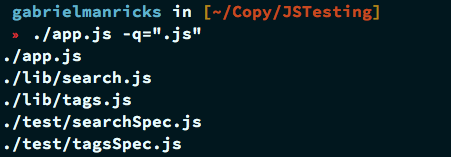
Теперь вы можете сделать ваш скрипт исполняемым ( chmod +x app.js в системе Unix) и затем запустить его так:
|
1
|
./app.js -q=».js»
|
При желании можно настроить некоторые другие заполнители, которые мы настраиваем.
Вывод
В этой статье мы создали целое приложение для поиска файлов, хотя и простое, но я думаю, что оно демонстрирует процесс в целом довольно хорошо.
Несколько личных советов в будущем; если вы собираетесь использовать много TDD, настройте свою среду. Большая часть времени, которое люди связывают с TDD, связана с тем, что им приходится постоянно переключать окна, открывать и закрывать разные файлы, а затем запускать тесты и повторять это 80 десятков раз в день. В таком случае это прерывает ваш рабочий процесс, снижая производительность. Но если у вас есть настройки редактора, например, если у вас есть тесты и код рядом или ваша IDE поддерживает переход назад и вперед, это сэкономит массу времени. Вы также можете настроить автоматический запуск тестов, вызвав его с тегом -w чтобы просмотреть файлы на предмет изменений и автоматически запустить все тесты. Подобные вещи делают процесс более плавным и помогают, а не беспокоят.
Надеюсь, вам понравилась эта статья, если у вас есть какие-либо вопросы, вы можете оставить их ниже, свяжитесь со мной в Twitter @gabrielmanricks или на канале Nettuts + IRC (#nettuts on freenode).
Также ознакомьтесь с подборкой полезных скриптов Node.js на Envato Market.