обзор
HTML почти интуитивно понятен. CSS — это большое достижение, которое четко отделяет структуру страницы от ее внешнего вида. JavaScript добавляет некоторый pizazz. Это теория. Реальный мир немного другой.
В этом уроке вы узнаете, как на самом деле воспроизводится содержимое, которое вы видите в браузере, и как его очищать при необходимости. В частности, вы научитесь считать комментарии Disqus. Нашими инструментами будут Python и потрясающие пакеты, такие как запросы, BeautifulSoup и Selenium.
Когда следует использовать очистку веб-страниц?
Скрепление веб-страниц — это практика автоматического извлечения содержимого веб-страниц, предназначенного для взаимодействия с пользователями-пользователями, их анализа и извлечения некоторой информации (возможно, перехода по ссылкам на другие страницы). Иногда это необходимо, если нет другого способа извлечь необходимую информацию. В идеале приложение предоставляет специальный API для программного доступа к своим данным. Существует несколько причин, по которым очистка веб-страниц должна быть вашим последним средством:
- Он хрупок (веб-страницы, которые вы просматриваете, могут часто меняться).
- Это может быть запрещено (в некоторых веб-приложениях есть правила против удаления).
- Это может быть медленно и экспансивно (если вам нужно извлечь и пробраться через много шума).
Понимание реальных веб-страниц
Давайте разберемся, с чем мы столкнулись, посмотрев на вывод некоторого общего кода веб-приложения. В статье « Введение в Vagrant» внизу страницы есть несколько комментариев Disqus:
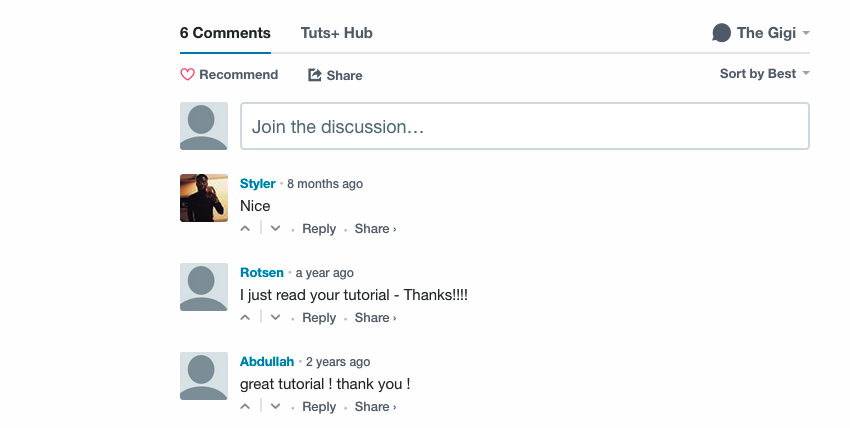
Чтобы очистить эти комментарии, нам нужно сначала найти их на странице.
Просмотр исходной страницы
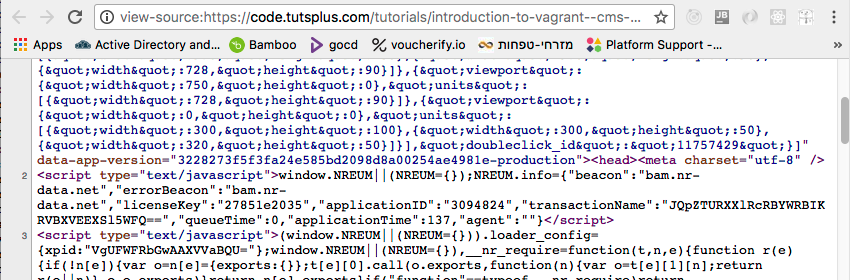
Каждый браузер с незапамятных времен (1990-х годов) поддерживает возможность просмотра HTML-кода текущей страницы. Вот фрагмент из источника представления « Введение в Vagrant», который начинается с огромного фрагмента минимизированного и увеличенного JavaScript, не связанного с самой статьей. Вот небольшая часть этого:
Вот немного фактического HTML со страницы:
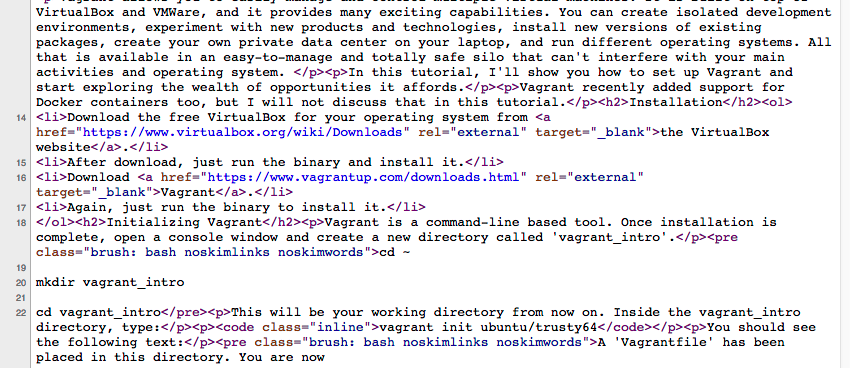
Это выглядит довольно грязно, но что удивительно, вы не найдете комментариев Disqus в источнике страницы.
Могучий встроенный каркас
Оказывается, что страница представляет собой гибридное приложение, а комментарии Disqus внедряются как элемент iframe (встроенный фрейм). Вы можете узнать это, щелкнув правой кнопкой мыши в области комментариев, и вы увидите, что там есть информация о фрейме и источник:
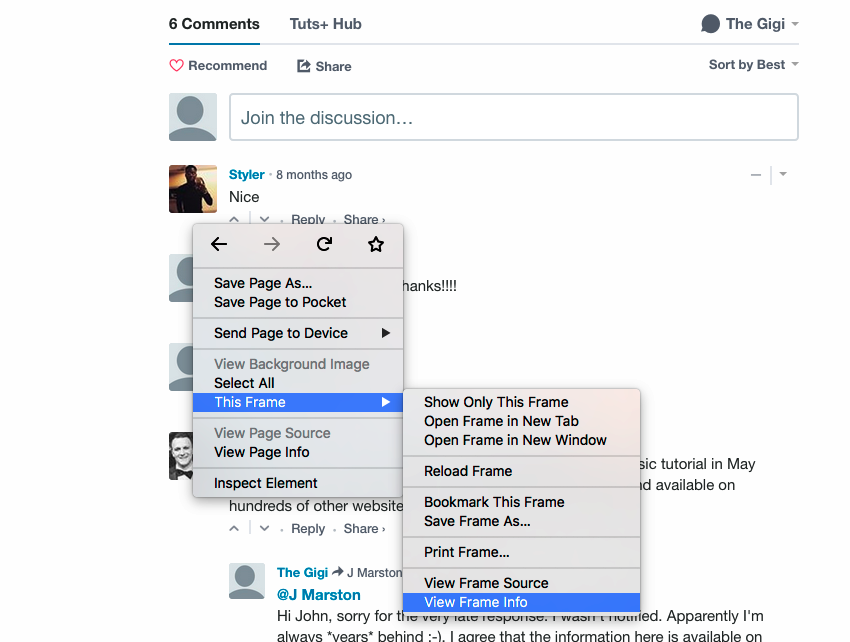
Это имеет смысл. Встраивание стороннего контента в качестве iframe является одной из основных причин использования iframe. Давайте найдем <iframe> в исходном коде главной страницы. Снова сорвали! В источнике главной страницы нет <iframe> .
Генерируемая JavaScript разметка
Причиной этого упущения является то, что на view page source отображается содержимое, полученное с сервера. Но конечный DOM (объектная модель документа), который отображается в браузере, может сильно отличаться. JavaScript включается и может манипулировать DOM по желанию. Iframe не может быть найден, потому что он не был там, когда страница была получена с сервера.
Статическая очистка против динамической очистки
Статическая очистка игнорирует JavaScript. Он получает веб-страницы с сервера без помощи браузера. Вы получаете именно то, что видите в «просмотре исходного кода страницы», а затем нарезаете и нарезаете его. Если контент, который вы ищете, доступен, вам не нужно идти дальше. Тем не менее, если содержимое является чем-то вроде iframe комментариев Disqus, вам нужно динамическое очищение.
Динамическая очистка использует реальный браузер (или браузер без головы) и позволяет JavaScript делать свое дело. Затем он запрашивает DOM для извлечения искомого контента. Иногда вам нужно автоматизировать браузер, симулируя пользователя для получения необходимого контента.
Статическая очистка с запросами и BeautifulSoup
Давайте посмотрим, как работает статическая очистка с использованием двух потрясающих пакетов Python: запросов на выборку веб-страниц и BeautifulSoup для анализа HTML-страниц.
Установка запросов и BeautifulSoup
Сначала установите pipenv , а затем: pipenv install requests beautifulsoup4
Это также создаст виртуальную среду для вас. Если вы используете код из gitlab, вы можете просто pipenv install .
Извлечение страниц
Извлечение страницы с запросами — это одна строка: r = requests.get(url)
Объект ответа имеет много атрибутов. Самые важные из них в ok и content . Если запрос не выполняется, r.ok будет False, а r.content будет содержать ошибку. Контент представляет собой поток байтов. Обычно лучше декодировать его в utf-8 при работе с текстом:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
>>> r = requests.get(‘http://www.c2.com/no-such-page’)
>>> r.ok
False
>>> print(r.content.decode(‘utf-8’))
<!DOCTYPE HTML PUBLIC «-//IETF//DTD HTML 2.0//EN»>
<html><head>
<title>404 Not Found</title>
</head><body>
<h1>Not Found</h1>
<p>The requested URL /ggg was not found on this server.</p>
<hr>
<address>
Apache/2.0.52 (CentOS) Server at www.c2.com Port 80
</address>
</body></html>
|
Если все в порядке, то r.content будет содержать запрошенную веб-страницу (так же, как и источник просмотра страницы).
Поиск элементов с BeautifulSoup
Функция get_page() ниже извлекает веб-страницу по URL, декодирует ее в UTF-8 и анализирует ее в объект BeautifulSoup, используя анализатор HTML.
|
1
2
3
4
|
def get_page(url):
r = requests.get(url)
content = r.content.decode(‘utf-8’)
return BeautifulSoup(content, ‘html.parser’)
|
Получив объект BeautifulSoup, мы можем начать извлекать информацию со страницы. BeautifulSoup предоставляет множество функций поиска для поиска элементов внутри страницы и углубления во вложенные элементы.
Страницы Tuts + автора содержат несколько учебных пособий. Вот моя страница автора . На каждой странице есть до 12 учебных пособий. Если у вас есть более 12 учебных пособий, вы можете перейти на следующую страницу. HTML-код каждой статьи заключен в <article> . Следующая функция находит все элементы статьи на странице, детализирует их ссылки и извлекает атрибут href, чтобы получить URL-адрес учебника:
|
1
2
3
4
|
def get_page_articles(page):
elements = page.findAll(‘article’)
articles = [eaattrs[‘href’] for e in elements]
return articles
|
Следующий код получает все статьи с моей страницы и печатает их (без общего префикса):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
page = get_page(‘https://tutsplus.com/authors/gigi-sayfan’)
articles = get_page_articles(page)
prefix = ‘https://code.tutsplus.com/tutorials’
for a in articles:
print(a[len(prefix):])
Output:
building-games-with-python-3-and-pygame-part-5—cms-30085
building-games-with-python-3-and-pygame-part-4—cms-30084
building-games-with-python-3-and-pygame-part-3—cms-30083
building-games-with-python-3-and-pygame-part-2—cms-30082
building-games-with-python-3-and-pygame-part-1—cms-30081
mastering-the-react-lifecycle-methods—cms-29849
testing-data-intensive-code-with-go-part-5—cms-29852
testing-data-intensive-code-with-go-part-4—cms-29851
testing-data-intensive-code-with-go-part-3—cms-29850
testing-data-intensive-code-with-go-part-2—cms-29848
testing-data-intensive-code-with-go-part-1—cms-29847
make-your-go-programs-lightning-fast-with-profiling—cms-29809
|
Динамическое выскабливание с селеном
Статическая очистка была достаточно хороша, чтобы получить список статей, но, как мы видели ранее, комментарии Disqus встроены в JavaScript как элемент iframe. Для сбора комментариев нам нужно будет автоматизировать браузер и интерактивно взаимодействовать с DOM. Одним из лучших инструментов для работы является Selenium .
Selenium в первую очередь ориентирован на автоматизированное тестирование веб-приложений, но он великолепен как универсальный инструмент для автоматизации браузера.
Установка Selenium
Введите эту команду для установки Selenium: pipenv install selenium
Выберите свой веб-драйвер
Selenium нужен веб-драйвер (браузер, который он автоматизирует). Для просмотра веб-страниц обычно не имеет значения, какой драйвер вы выберете. Я предпочитаю драйвер Chrome. Следуйте инструкциям в этом руководстве Selenium .
Chrome vs. PhantomJS
В некоторых случаях вы можете предпочесть использовать безголовый браузер, что означает, что пользовательский интерфейс не отображается. Теоретически, PhantomJS — это просто еще один веб-драйвер. Но на практике люди сообщали о проблемах несовместимости, когда Selenium правильно работает с Chrome или Firefox, а иногда и с PhantomJS. Я предпочитаю удалить эту переменную из уравнения и использовать реальный веб-драйвер браузера.
Подсчет комментариев Disqus
Давайте сделаем динамический анализ и используем Selenium для подсчета комментариев Disqus к учебникам Tuts +. Вот необходимый импорт.
|
1
2
3
4
5
|
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.expected_conditions import (
presence_of_element_located)
from selenium.webdriver.support.wait import WebDriverWait
|
Функция get_comment_count() принимает драйвер Selenium и URL. Он использует метод get() драйвера для получения URL. Это похоже на requests.get() , но разница в том, что объект драйвера управляет живым представлением DOM.
Затем он получает заголовок руководства и находит iframe Disqus, используя его родительский идентификатор disqus_thread а затем сам iframe:
|
1
2
3
4
5
6
7
|
def get_comment_count(driver, url):
driver.get(url)
class_name = ‘content-banner__title’
name = driver.find_element_by_class_name(class_name).text
e = driver.find_element_by_id(‘disqus_thread’)
disqus_iframe = e.find_element_by_tag_name(‘iframe’)
iframe_url = disqus_iframe.get_attribute(‘src’)
|
Следующим шагом является получение содержимого самого iframe. Обратите внимание, что мы ожидаем появления элемента comment-count потому что комментарии загружаются динамически и еще не обязательно доступны.
|
1
2
3
4
5
6
7
8
9
|
driver.get(iframe_url)
wait = WebDriverWait(driver, 5)
commentCountPresent = presence_of_element_located(
(By.CLASS_NAME, ‘comment-count’))
wait.until(commentCountPresent)
comment_count_span = driver.find_element_by_class_name(
‘comment-count’)
comment_count = int(comment_count_span.text.split()[0])
|
Последняя часть — вернуть последний комментарий, если он не был сделан мной. Идея состоит в том, чтобы обнаружить комментарии, на которые я еще не ответил.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
last_comment = {}
if comment_count > 0:
e = driver.find_elements_by_class_name(‘author’)[-1]
last_author = e.find_element_by_tag_name(‘a’)
last_author = e.get_attribute(‘data-username’)
if last_author != ‘the_gigi’:
e = driver.find_elements_by_class_name(‘post-meta’)
meta = e[-1].find_element_by_tag_name(‘a’)
last_comment = dict(
author=last_author,
title=meta.get_attribute(‘title’),
when=meta.text)
return name, comment_count, last_comment
|
Вывод
Соскреб в Интернете — полезная практика, когда необходимая информация доступна через веб-приложение, которое не предоставляет соответствующего API. Для извлечения данных из современных веб-приложений требуется некоторая нетривиальная работа, но зрелые и хорошо разработанные инструменты, такие как запросы, BeautifulSoup и Selenium, того стоят.
Кроме того, не стесняйтесь посмотреть, что у нас есть в наличии для продажи и для изучения на рынке Envato , и не стесняйтесь задавать любые вопросы и предоставлять ценные отзывы, используя канал ниже.