Шаблон проектирования репозитория, определенный Эриком Эвенсом в его книге «Управление управляемым доменом» , является одним из самых полезных и наиболее широко применимых шаблонов проектирования, когда-либо изобретенных. Любое приложение должно работать с постоянством и с каким-то списком элементов. Это могут быть пользователи, продукты, сети, диски или что-то еще, о чем ваше приложение. Например, если у вас есть блог, вы должны иметь дело со списками постов в блоге и списками комментариев. Проблема, которая объединяет все эти логики управления списками, заключается в том, как соединить бизнес-логику, фабрики и постоянство.
Шаблон фабричного дизайна
Как мы упоминали во вступительном параграфе, репозиторий соединит фабрики со шлюзами (постоянство). Это также шаблоны проектирования, и если вы с ними не знакомы, этот параграф проливает свет на эту тему.
Фабрика — это простой шаблон проектирования, который определяет удобный способ создания объектов. Это класс или набор классов, отвечающих за создание объектов, в которых нуждается наша бизнес-логика. У фабрики традиционно есть метод, называемый " и он будет знать, как взять всю информацию, необходимую для построения объекта, а также построить объект самостоятельно и вернуть готовый к использованию объект в бизнес-логику. make() "
Вот еще немного о Factory Pattern в более старом учебнике Nettuts +: Руководство для начинающих по разработке шаблонов . Если вы предпочитаете более глубокий взгляд на Factory Pattern, ознакомьтесь с первым шаблоном дизайна в курсе Agile Design Patterns, который у нас есть на Tuts +.
Шаблон Ворот
Также известный как «шлюз табличных данных» — это простой шаблон, который обеспечивает связь между бизнес-логикой и самой базой данных. Его основная обязанность — выполнять запросы к базе данных и предоставлять извлеченные данные в структуре данных, типичной для языка программирования (например, массив в PHP). Затем эти данные обычно фильтруются и модифицируются в коде PHP, чтобы мы могли получить информацию и переменные, необходимые для создания наших объектов. Эта информация должна быть передана на фабрики.
Шаблон проектирования шлюза достаточно подробно объяснен и проиллюстрирован в учебном руководстве по Nettuts + об эволюции на уровне персистентности . Кроме того, в том же курсе Agile Design Patterns второй урок шаблона проектирования посвящен этой теме.
Проблемы, которые нам нужно решить
Дублирование при обработке данных
На первый взгляд это может быть неочевидно, но подключение шлюзов к фабрикам может привести к значительному дублированию. Любое программное обеспечение значительных размеров должно создавать одни и те же объекты из разных мест. В каждом месте вам нужно будет использовать шлюз для извлечения набора необработанных данных, фильтрации и обработки этих данных, чтобы быть готовыми к отправке на фабрики. Из всех этих мест вы будете называть одни и те же фабрики с одинаковыми структурами данных, но, очевидно, с разными данными. Ваши объекты будут созданы и предоставлены вам Фабриками. Это неизбежно приведет к значительному дублированию во времени. И дублирование будет распространено на удаленные классы или модули, и его будет трудно заметить и исправить.
Дублирование с помощью переопределения логики поиска данных
Другая проблема, с которой мы сталкиваемся, заключается в том, как выразить запросы, которые нам нужно выполнить с помощью шлюзов. Каждый раз, когда нам нужна информация от Шлюза, мы должны думать о том, что именно нам нужно? Нужны ли нам все данные по одному предмету? Нужна ли нам какая-то конкретная информация? Мы хотим извлечь определенную группу из базы данных и выполнить сортировку или уточненную фильтрацию на нашем языке программирования? Все эти вопросы необходимо решать каждый раз, когда мы получаем информацию со слоя постоянства через наш шлюз. Каждый раз, когда мы делаем это, нам нужно будет найти решение. Со временем, по мере роста нашего приложения, мы столкнемся с одними и теми же дилеммами в разных местах нашего приложения. По неосторожности мы придумаем несколько разные решения одних и тех же проблем. Это не только требует дополнительного времени и усилий, но также приводит к тонкому, в основном очень трудно распознаваемому, дублированию. Это самый опасный тип дублирования.
Дублирование с помощью переопределения логики постоянства данных
В предыдущих двух параграфах мы говорили только о поиске данных. Но Шлюз является двунаправленным. Наша бизнес-логика является двунаправленной. Мы должны как-то сохранять наши объекты. Это снова приводит к большому повторению, если мы хотим реализовать эту логику по мере необходимости в различных модулях и классах нашего приложения.
Основные понятия
Репозиторий для поиска данных
Репозиторий может функционировать двумя способами: извлечение данных и сохранение данных.
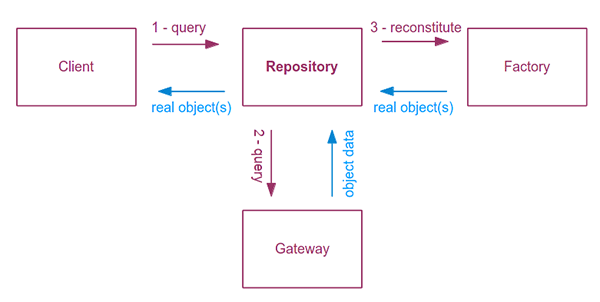
При использовании для извлечения объектов из постоянного хранилища будет вызываться репозиторий с пользовательским запросом. Этот запрос может быть конкретным методом по имени или более распространенным методом с параметрами. Хранилище отвечает за предоставление и реализацию этих методов запросов. Когда вызывается такой метод, репозиторий связывается со шлюзом, чтобы получить необработанные данные из персистентности. Шлюз будет предоставлять необработанные данные объекта (например, массив со значениями). Затем репозиторий получит эти данные, проведет необходимые преобразования и вызовет соответствующие методы Factory. Заводы предоставят объекты, построенные с данными, предоставленными хранилищем. Репозиторий будет собирать эти объекты и возвращать их как набор объектов (например, массив объектов или объект коллекции, как определено в уроке «Составной шаблон» в курсе « Шаблоны гибкой разработки» ).
Репозиторий для сохранения данных
Второй способ работы репозитория заключается в предоставлении логики, необходимой для извлечения информации из объекта и ее сохранения. Это может быть так же просто, как сериализация объекта и отправка сериализованных данных в шлюз для его сохранения, или так же сложно, как создание массивов информации со всеми полями и состоянием объекта.
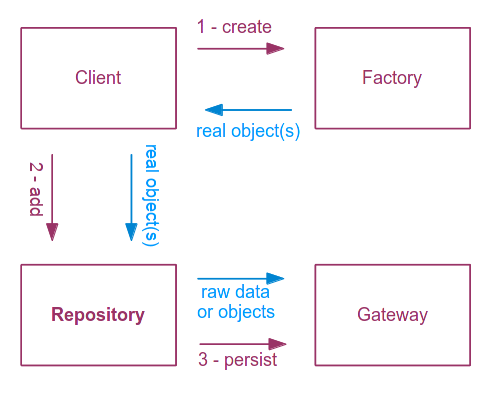
Когда используется для сохранения информации, клиентским классом является тот, который напрямую общается с Фабрикой. Представьте себе сценарий, когда новый комментарий публикуется в блоге. Объект Comment создается нашей бизнес-логикой (класс Client) и затем отправляется в репозиторий для сохранения. Хранилище сохранит объекты, используя шлюз, и при желании кеширует их в локальном списке памяти. Данные необходимо преобразовать, потому что только в редких случаях реальные объекты могут быть напрямую сохранены в персистентной системе.
Соединение точек
Изображение ниже представляет собой представление более высокого уровня о том, как интегрировать репозиторий между фабриками, шлюзом и клиентом.
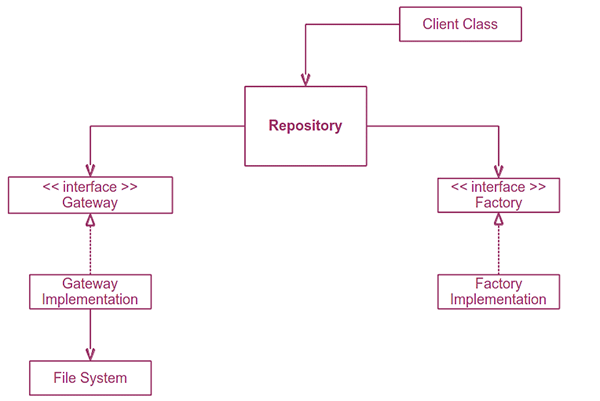
В центре схемы находится наш репозиторий. Слева находится интерфейс для шлюза, реализация и само постоянство. Справа находится Интерфейс для Фабрик и Фабрика. Наконец, сверху находится класс клиента.
Как видно из направления стрелок, зависимости инвертированы. Репозиторий зависит только от абстрактных интерфейсов для Фабрик и Шлюзов. Шлюз зависит от его интерфейса и постоянства, которое он предлагает. Фабрика зависит только от своего интерфейса. Клиент зависит от хранилища, что приемлемо, поскольку хранилище имеет тенденцию быть менее конкретным, чем клиент.
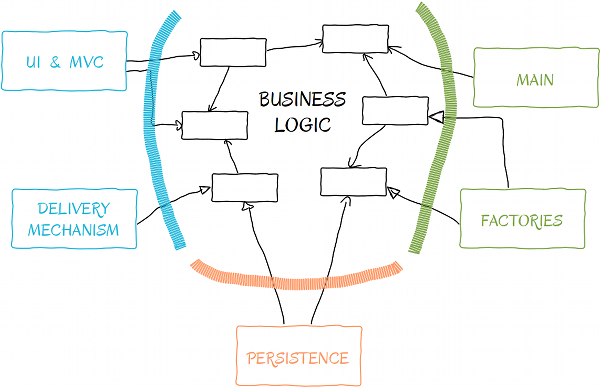
Говоря в перспективе, приведенный выше параграф учитывает нашу архитектуру высокого уровня и направление зависимостей, которых мы хотим достичь.
Управление комментариями к сообщениям в блоге с помощью репозитория
Теперь, когда мы увидели теорию, пришло время для практического примера. Представьте, что у нас есть блог, где у нас есть объекты Post и Comment. Комментарии принадлежат постам, и мы должны найти способ сохранить их и получить их.
Комментарий
Мы начнем с теста, который заставит нас задуматься о том, что должен содержать наш объект Comment.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
class RepositoryTest extends PHPUnit_Framework_TestCase {
function testACommentHasAllItsComposingParts() {
$postId = 1;
$commentAuthor = «Joe»;
$commentAuthorEmail = «joe@gmail.com»;
$commentSubject = «Joe Has an Opinion about the Repository Pattern»;
$commentBody = «I think it is a good idea to use the Repository Pattern to persist and retrieve objects.»;
$comment = new Comment($postId, $commentAuthor, $commentAuthorEmail, $commentSubject, $commentBody);
}
}
|
На первый взгляд, Комментарий будет просто объектом данных. Он может не иметь никакой функциональности, но это зависит от контекста нашего приложения. Для этого примера просто предположим, что это простой объект данных. Построен с набором переменных.
|
1
2
3
|
class Comment {
}
|
Просто создав пустой класс и требуя его в тесте, он проходит успешно.
|
1
2
3
4
5
6
7
|
require_once ‘../Comment.php’;
class RepositoryTest extends PHPUnit_Framework_TestCase {
[ … ]
}
|
Но это далеко не идеально. Наш тест еще ничего не тестирует. Давайте заставим себя написать все получатели в классе Comment.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
function testACommentsHasAllItsComposingParts() {
$postId = 1;
$commentAuthor = «Joe»;
$commentAuthorEmail = «joe@gmail.com»;
$commentSubject = «Joe Has an Opinion about the Repository Pattern»;
$commentBody = «I think it is a good idea to use the Repository Pattern to persist and retrieve objects.»;
$comment = new Comment($postId, $commentAuthor, $commentAuthorEmail, $commentSubject, $commentBody);
$this->assertEquals($postId, $comment->getPostId());
$this->assertEquals($commentAuthor, $comment->getAuthor());
$this->assertEquals($commentAuthorEmail, $comment->getAuthorEmail());
$this->assertEquals($commentSubject, $comment->getSubject());
$this->assertEquals($commentBody, $comment->getBody());
}
|
Чтобы проконтролировать продолжительность урока, я написал все утверждения сразу, и мы их сразу внедрим. В реальной жизни принимайте их по одному.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
class Comment {
private $postId;
private $author;
private $authorEmail;
private $subject;
private $body;
function __construct($postId, $author, $authorEmail, $subject, $body) {
$this->postId = $postId;
$this->author = $author;
$this->authorEmail = $authorEmail;
$this->subject = $subject;
$this->body = $body;
}
public function getPostId() {
return $this->postId;
}
public function getAuthor() {
return $this->author;
}
public function getAuthorEmail() {
return $this->authorEmail;
}
public function getSubject() {
return $this->subject;
}
public function getBody() {
return $this->body;
}
}
|
За исключением списка приватных переменных, остальная часть кода была сгенерирована моей IDE, NetBeans, поэтому тестирование автоматически сгенерированного кода иногда может быть немного трудоемким. Если вы не пишете эти строки самостоятельно, не стесняйтесь делать их напрямую и не беспокойтесь о тестах для сеттеров и конструкторов. Тем не менее, тест помог нам лучше раскрыть наши идеи и лучше документировать, что будет содержать наш класс Comment.
Мы также можем рассматривать эти методы тестирования и тестовые классы как наши «клиентские» классы из схем.
Наши врата в постоянство
Чтобы сделать этот пример максимально простым, мы будем реализовывать только InMemoryPersistence, чтобы не усложнять наше существование файловыми системами или базами данных.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
require_once ‘../InMemoryPersistence.php’;
class InMemoryPersistenceTest extends PHPUnit_Framework_TestCase {
function testItCanPerisistAndRetrieveASingleDataArray() {
$data = array(‘data’);
$persistence = new InMemoryPersistence();
$persistence->persist($data);
$this->assertEquals($data, $persistence->retrieve(0));
}
}
|
Как обычно, мы начнем с самого простого теста, который может быть неудачным, а также заставит нас написать некоторый код. Этот тест создает новый объект InMemoryPersistence и пытается сохранить и извлечь массив с именем data .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
require_once __DIR__ .
class InMemoryPersistence implements Persistence {
private $data = array();
function persist($data) {
$this->data = $data;
}
function retrieve($id) {
return $this->data;
}
}
|
Простейший код для его передачи — просто сохранить входящие $data в закрытой переменной и вернуть ее в методе retrieve . Код, как он есть сейчас, не заботится о переданной переменной $id . Это самая простая вещь, которая могла бы пройти тест. Мы также взяли на себя смелость представить и реализовать интерфейс под названием Persistence .
|
1
2
3
4
5
6
|
interface Persistence {
function persist($data);
function retrieve($ids);
}
|
Этот интерфейс определяет два метода, которые должен реализовывать любой шлюз. Persist и retrieve . Как вы, наверное, уже догадались, наш шлюз — это наш класс InMemoryPersistence а наше физическое постоянство — это частная переменная, InMemoryPersistence наши данные в памяти. Но вернемся к реализации этого в памяти.
|
01
02
03
04
05
06
07
08
09
10
11
|
function testItCanPerisistSeveralElementsAndRetrieveAnyOfThem() {
$data1 = array(‘data1’);
$data2 = array(‘data2’);
$persistence = new InMemoryPersistence();
$persistence->persist($data1);
$persistence->persist($data2);
$this->assertEquals($data1, $persistence->retrieve(0));
$this->assertEquals($data2, $persistence->retrieve(1));
}
|
Мы добавили еще один тест. В этом мы сохраняем два разных массива данных. Мы ожидаем, что сможем получить каждый из них в отдельности.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
require_once __DIR__ .
class InMemoryPersistence implements Persistence {
private $data = array();
function persist($data) {
$this->data[] = $data;
}
function retrieve($id) {
return $this->data[$id];
}
}
|
Тест заставил нас немного изменить наш код. Теперь нам нужно добавить данные в наш массив, а не просто заменить его на тот, который был отправлен в persists() . Нам также нужно рассмотреть параметр $id и вернуть элемент по этому индексу.
Этого достаточно для нашего InMemoryPersistence . При необходимости мы можем изменить его позже.
Наш Завод
У нас есть клиент (наши тесты), персистентность со шлюзом и объекты Comment для сохранения. Следующая недостающая вещь — наша Фабрика.
Мы начали наше кодирование с файла RepositoryTest . Этот тест, однако, фактически создал объект Comment . Теперь нам нужно создать тесты, чтобы проверить, сможет ли наша Фабрика создавать объекты Comment . Кажется, что мы допустили ошибку, и наш тест, скорее, является тестом для нашей будущей фабрики, чем для нашего репозитория. Мы можем переместить его в другой тестовый файл, CommentFactoryTest .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
require_once ‘../Comment.php’;
class CommentFactoryTest extends PHPUnit_Framework_TestCase {
function testACommentsHasAllItsComposingParts() {
$postId = 1;
$commentAuthor = «Joe»;
$commentAuthorEmail = «joe@gmail.com»;
$commentSubject = «Joe Has an Opinion about the Repository Pattern»;
$commentBody = «I think it is a good idea to use the Repository Pattern to persist and retrieve objects.»;
$comment = new Comment($postId, $commentAuthor, $commentAuthorEmail, $commentSubject, $commentBody);
$this->assertEquals($postId, $comment->getPostId());
$this->assertEquals($commentAuthor, $comment->getAuthor());
$this->assertEquals($commentAuthorEmail, $comment->getAuthorEmail());
$this->assertEquals($commentSubject, $comment->getSubject());
$this->assertEquals($commentBody, $comment->getBody());
}
}
|
Теперь этот тест, очевидно, проходит. И хотя это правильный тест, мы должны рассмотреть возможность его изменения. Мы хотим создать объект Factory , передать массив и попросить его создать Comment для нас.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
|
require_once ‘../CommentFactory.php’;
class CommentFactoryTest extends PHPUnit_Framework_TestCase {
function testACommentsHasAllItsComposingParts() {
$postId = 1;
$commentAuthor = «Joe»;
$commentAuthorEmail = «joe@gmail.com»;
$commentSubject = «Joe Has an Opinion about the Repository Pattern»;
$commentBody = «I think it is a good idea to use the Repository Pattern to persist and retrieve objects.»;
$commentData = array($postId, $commentAuthor, $commentAuthorEmail, $commentSubject, $commentBody);
$comment = (new CommentFactory())->make($commentData);
$this->assertEquals($postId, $comment->getPostId());
$this->assertEquals($commentAuthor, $comment->getAuthor());
$this->assertEquals($commentAuthorEmail, $comment->getAuthorEmail());
$this->assertEquals($commentSubject, $comment->getSubject());
$this->assertEquals($commentBody, $comment->getBody());
}
}
|
Мы никогда не должны называть наши классы на основе шаблона проектирования, который они реализуют, но Factory и Repository представляют собой нечто большее, чем просто шаблон проектирования. Я лично не имею ничего против включения этих двух слов в названия наших классов. Тем не менее, я все еще настоятельно рекомендую и соблюдаю концепцию не называть наши классы после шаблонов проектирования, которые мы используем для остальных шаблонов.
Этот тест немного отличается от предыдущего, но не проходит. Он пытается создать объект CommentFactory . Этот класс еще не существует. Мы также пытаемся вызвать метод make() с массивом, содержащим всю информацию комментария в виде массива. Этот метод определен в интерфейсе Factory .
|
1
2
3
|
interface Factory {
function make($data);
}
|
Это очень распространенный интерфейс Factory . Он определил единственный обязательный метод для фабрики, метод, который фактически создает объекты, которые мы хотим.
|
01
02
03
04
05
06
07
08
09
10
|
require_once __DIR__ .
require_once __DIR__ .
class CommentFactory implements Factory {
function make($components) {
return new Comment($components[0], $components[1], $components[2], $components[3], $components[4]);
}
}
|
А CommentFactory реализует интерфейс Factory , приняв параметр $components в методе make() , создает и возвращает новый объект Comment с информацией оттуда.
Мы сохраним нашу лояльность и логику создания объекта как можно проще. В этом руководстве мы можем безопасно игнорировать любую обработку ошибок, проверку и создание исключений. Мы остановимся здесь на реализации сохранения и создания объекта.
Использование репозитория для сохранения комментариев
Как мы видели выше, мы можем использовать репозиторий двумя способами. Для извлечения информации из постоянства, а также для сохранения информации на постоянном уровне. Используя TDD, в большинстве случаев проще начать с сохраняющей (сохраняющейся) части логики, а затем использовать эту существующую реализацию для проверки поиска данных.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
require_once ‘../../../vendor/autoload.php’;
require_once ‘../CommentRepository.php’;
require_once ‘../CommentFactory.php’;
class RepositoryTest extends PHPUnit_Framework_TestCase {
protected function tearDown() {
\Mockery::close();
}
function testItCallsThePersistenceWhenAddingAComment() {
$persistanceGateway = \Mockery::mock(‘Persistence’);
$commentRepository = new CommentRepository($persistanceGateway);
$commentData = array(1, ‘x’, ‘x’, ‘x’, ‘x’);
$comment = (new CommentFactory())->make($commentData);
$persistanceGateway->shouldReceive(‘persist’)->once()->with($commentData);
$commentRepository->add($comment);
}
}
|
Мы используем Mockery, чтобы высмеивать наше постоянство и вводить этот смоделированный объект в репозиторий. Затем мы вызываем add() в хранилище. Этот метод имеет параметр типа Comment . Мы ожидаем, что постоянство будет вызываться с массивом данных, похожим на $commentData .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
require_once __DIR__ .
class CommentRepository {
private $persistence;
function __construct(Persistence $persistence = null) {
$this->persistence = $persistence ?
}
function add(Comment $comment) {
$this->persistence->persist(array(
$comment->getPostId(),
$comment->getAuthor(),
$comment->getAuthorEmail(),
$comment->getSubject(),
$comment->getBody()
));
}
}
|
Как видите, метод add() довольно умен. Он инкапсулирует знания о том, как преобразовать объект PHP в простой массив, используемый постоянством. Помните, что наш постоянный шлюз обычно является общим объектом для всех наших данных. Он может сохранять и сохранит все данные нашего приложения, поэтому отправка на него объектов сделает его слишком большим: как преобразование, так и эффективное сохранение.
Когда у вас есть класс InMemoryPersistence как у нас, он очень быстрый. Мы можем использовать его как альтернативу издевательству над шлюзом.
|
01
02
03
04
05
06
07
08
09
10
11
12
|
function testAPersistedCommentCanBeRetrievedFromTheGateway() {
$persistanceGateway = new InMemoryPersistence();
$commentRepository = new CommentRepository($persistanceGateway);
$commentData = array(1, ‘x’, ‘x’, ‘x’, ‘x’);
$comment = (new CommentFactory())->make($commentData);
$commentRepository->add($comment);
$this->assertEquals($commentData, $persistanceGateway->retrieve(0));
}
|
Конечно, если у вас нет реализации вашей настойчивости в памяти, насмешка — единственный разумный путь. В противном случае ваш тест будет слишком медленным, чтобы быть практичным.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
function testItCanAddMultipleCommentsAtOnce() {
$persistanceGateway = \Mockery::mock(‘Persistence’);
$commentRepository = new CommentRepository($persistanceGateway);
$commentData1 = array(1, ‘x’, ‘x’, ‘x’, ‘x’);
$comment1 = (new CommentFactory())->make($commentData1);
$commentData2 = array(2, ‘y’, ‘y’, ‘y’, ‘y’);
$comment2 = (new CommentFactory())->make($commentData2);
$persistanceGateway->shouldReceive(‘persist’)->once()->with($commentData1);
$persistanceGateway->shouldReceive(‘persist’)->once()->with($commentData2);
$commentRepository->add(array($comment1, $comment2));
}
|
Наш следующий логический шаг — реализовать способ добавления нескольких комментариев одновременно. Вашему проекту может не потребоваться эта функциональность, и это не то, что требуется по шаблону. Фактически, шаблон репозитория говорит только о том, что он предоставит пользовательский запрос и язык персистенции для нашей бизнес-логики. Поэтому, если наша логика кустарности чувствует необходимость добавления нескольких комментариев одновременно, репозиторий — это место, где должна находиться логика.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
function add($commentData) {
if (is_array($commentData))
foreach ($commentData as $comment)
$this->persistence->persist(array(
$comment->getPostId(),
$comment->getAuthor(),
$comment->getAuthorEmail(),
$comment->getSubject(),
$comment->getBody()
));
else
$this->persistence->persist(array(
$commentData->getPostId(),
$commentData->getAuthor(),
$commentData->getAuthorEmail(),
$commentData->getSubject(),
$commentData->getBody()
));
}
|
И самый простой способ пройти тест — просто проверить, является ли получаемый нами параметр массивом или нет. Если это массив, мы будем циклически проходить через каждый элемент и вызывать постоянство с массивом, который мы генерируем из одного единственного объекта Comment . И хотя этот код синтаксически корректен и проходит тестирование, он вносит небольшое дублирование, от которого мы можем довольно легко избавиться.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
function add($commentData) {
if (is_array($commentData))
foreach ($commentData as $comment)
$this->addOne($comment);
else
$this->addOne($commentData);
}
private function addOne(Comment $comment) {
$this->persistence->persist(array(
$comment->getPostId(),
$comment->getAuthor(),
$comment->getAuthorEmail(),
$comment->getSubject(),
$comment->getBody()
));
}
|
Когда все тесты зеленые, для рефакторинга всегда есть время, прежде чем мы продолжим следующий неудачный тест. И мы сделали это с помощью метода add() . Мы извлекли добавление одного комментария в приватный метод и вызвали его из двух разных мест в нашем публичном методе add() . Это не только уменьшило дублирование, но и открыло возможность сделать метод addOne() общедоступным и позволить бизнес-логике решать, хочет ли он добавлять один или несколько комментариев одновременно. Это привело бы к другой реализации нашего репозитория с использованием addOne() и другого addMany() . Это была бы совершенно законная реализация шаблона репозитория.
Получение комментариев с нашего репозитория
Репозиторий предоставляет пользовательский язык запросов для бизнес-логики. Таким образом, имена и функциональные возможности методов запросов репозитория в значительной степени соответствуют требованиям бизнес-логики. Вы создаете свой репозиторий по мере того, как вы строите свою бизнес-логику, так как вам нужен другой специальный метод запроса. Однако есть по крайней мере один или два метода, которые вы найдете практически в любом репозитории.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
function testItCanFindAllComments() {
$repository = new CommentRepository();
$commentData1 = array(1, ‘x’, ‘x’, ‘x’, ‘x’);
$comment1 = (new CommentFactory())->make($commentData1);
$commentData2 = array(2, ‘y’, ‘y’, ‘y’, ‘y’);
$comment2 = (new CommentFactory())->make($commentData2);
$repository->add($comment1);
$repository->add($comment2);
$this->assertEquals(array($comment1, $comment2), $repository->findAll());
}
|
Первый такой метод называется findAll() . Это должно вернуть все объекты, за которые отвечает хранилище, в нашем случае — Comments . Тест прост, мы добавляем комментарий, затем еще один, и, наконец, мы хотим вызвать findAll() и получить список, содержащий оба комментария. Однако это невозможно сделать с помощью нашего InMemoryPersistence как на данный момент. Требуется небольшое обновление.
|
1
2
3
|
function retrieveAll() {
return $this->data;
}
|
Вот и все. Мы добавили метод retrieveAll() который просто возвращает весь массив $data из класса. Просто и эффективно. Пришло время реализовать findAll() в CommentRepository .
|
1
2
3
4
5
6
7
|
function findAll() {
$allCommentsData = $this->persistence->retrieveAll();
$comments = array();
foreach ($allCommentsData as $commentData)
$comments[] = $this->commentFactory->make($commentData);
return $comments;
}
|
findAll() вызовет метод retrieveAll() в нашем постоянстве. Этот метод предоставляет необработанный массив данных. findAll() будет циклически проходить через каждый элемент и использовать данные по мере необходимости для передачи на фабрику. Фабрика предоставит один Comment за раз. Массив с этими комментариями будет построен и возвращен в конце findAll() . Просто и эффективно.
Другой распространенный метод, который вы найдете в репозиториях, — это поиск определенного объекта или группы объектов на основе их характерного ключа. Например, все наши комментарии связаны с постом в $postId внутренней переменной $postId . Я могу себе представить, что в бизнес-логике нашего блога мы почти всегда хотели бы найти все комментарии, относящиеся к посту блога, когда этот пост отображается. Поэтому метод с именем findByPostId($id) звучит для меня разумно.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
function testItCanFindCommentsByBlogPostId() {
$repository = new CommentRepository();
$commentData1 = array(1, ‘x’, ‘x’, ‘x’, ‘x’);
$comment1 = (new CommentFactory())->make($commentData1);
$commentData2 = array(1, ‘y’, ‘y’, ‘y’, ‘y’);
$comment2 = (new CommentFactory())->make($commentData2);
$commentData3 = array(3, ‘y’, ‘y’, ‘y’, ‘y’);
$comment3 = (new CommentFactory())->make($commentData3);
$repository->add(array($comment1, $comment2));
$repository->add($comment3);
$this->assertEquals(array($comment1, $comment2), $repository->findByPostId(1));
}
|
Мы просто создаем три простых комментария. Первые два имеют одинаковый $postId = 1 , третий имеет $postID = 3 . Мы добавляем их все в репозиторий, а затем ожидаем массив с первыми двумя, когда мы выполняем findByPostId() для $postId = 1 .
|
1
2
3
4
5
|
function findByPostId($postId) {
return array_filter($this->findAll(), function ($comment) use ($postId){
return $comment->getPostId() == $postId;
});
}
|
Реализация не может быть проще. Мы находим все комментарии, используя наш уже реализованный findAll() и фильтруем массив. У нас нет возможности попросить упорство выполнить фильтрацию для нас, поэтому мы сделаем это здесь. Код будет запрашивать каждый объект Comment и сравнивать его $postId с тем, который мы отправили в качестве параметра. Отлично. Тест проходит. Но я чувствую, что мы что-то упустили.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
function testItCanFindCommentsByBlogPostId() {
$repository = new CommentRepository();
$commentData1 = array(1, ‘x’, ‘x’, ‘x’, ‘x’);
$comment1 = (new CommentFactory())->make($commentData1);
$commentData2 = array(1, ‘y’, ‘y’, ‘y’, ‘y’);
$comment2 = (new CommentFactory())->make($commentData2);
$commentData3 = array(3, ‘y’, ‘y’, ‘y’, ‘y’);
$comment3 = (new CommentFactory())->make($commentData3);
$repository->add(array($comment1, $comment2));
$repository->add($comment3);
$this->assertEquals(array($comment1, $comment2), $repository->findByPostId(1));
$this->assertEquals(array($comment3), $repository->findByPostId(3));
}
|
Добавление второго утверждения для получения третьего комментария с помощью findByPostID() показывает нашу ошибку. Всякий раз, когда вы можете легко проверить дополнительные пути или случаи, как в нашем случае с простым дополнительным утверждением, вы должны это сделать. Эти простые дополнительные утверждения или методы тестирования могут выявить скрытые проблемы. Как и в нашем случае, array_filter() не переиндексирует полученный массив. И хотя у нас есть массив с правильными элементами, индексы испортились.
|
1
2
3
4
5
6
7
8
9
|
1) RepositoryTest::testItCanFindCommentsByBlogPostId
Failed asserting that two arrays are equal.
— Expected
+++ Actual
@@ @@
Array (
— 0 => Comment Object (…)
+ 2 => Comment Object (…)
)
|
Теперь вы можете считать это недостатком PHPUnit или недостатком вашей бизнес-логики. Я склонен быть строгим с индексами массивов, потому что я несколько раз обжигал им руки. Поэтому мы должны считать ошибку проблемой нашей логики в CommentRepository .
|
1
2
3
4
5
6
7
|
function findByPostId($postId) {
return array_values(
array_filter($this->findAll(), function ($comment) use ($postId) {
return $comment->getPostId() == $postId;
})
);
}
|
Ага. Так просто. Мы просто запускаем результат через array_values() перед его возвратом. Это будет красиво переиндексировать наш массив. Миссия выполнена.
Последние мысли
И эта миссия выполнена и для нашего хранилища. У нас есть класс, который может использоваться любым другим классом бизнес-логики, который предлагает простой способ сохранения и извлечения объектов. Он также отделяет бизнес-логику от фабрик и шлюзов хранения данных. Это уменьшило дублирование логики и значительно упрощает операции сохранения и поиска для наших комментариев.
Помните, что этот шаблон проектирования можно использовать для всех типов списков, и как только вы начнете его использовать, вы увидите его полезность. По сути, всякий раз, когда вам приходится работать с несколькими объектами одного типа, вы должны рассмотреть возможность создания репозитория для них. Репозитории являются специализированными по типу объекта и не являются общими. Таким образом, для приложения блога у вас могут быть отдельные репозитории для сообщений в блоге, для комментариев, для пользователей, для пользовательских конфигураций, для тем, для проектов, для чего-либо, что вы можете иметь несколько экземпляров.
И прежде чем завершить это, репозиторий может иметь свой собственный список объектов и может выполнять локальное кэширование объектов. Если объект не может быть найден в локальном списке, мы извлекаем его из постоянства, в противном случае мы обслуживаем его из нашего списка. При использовании с кэшированием репозиторий может быть успешно объединен с шаблоном проектирования Singleton.
Как обычно, спасибо за ваше время, и я искренне надеюсь, что научил вас чему-то новому сегодня.