Добро пожаловать в эту серию по созданию веб-скребка. В этом уроке я расскажу о том, как собрать данные со своего сайта подкастов. Я подробно расскажу, как я извлек данные, как вспомогательные и служебные методы выполняют свою работу и как все кусочки головоломки объединяются.
темы
- Соскоб мой подкаст
- подглядывать
- скребок
- Вспомогательные методы
- Написание сообщений
Соскоб мой подкаст
Давайте применим то, что мы узнали на практике. По разным причинам, редизайн для моего подкаста Между | Экраны были давно пора. Были проблемы, которые заставляли меня кричать, когда я просыпался утром. Поэтому я решил создать совершенно новый статический сайт, созданный с помощью Middleman и размещенный на GitHub Pages.
Я потратил много времени на новый дизайн после того, как настроил блог Middleman под свои нужды. Осталось только импортировать контент из моего приложения Sinatra, поддерживаемого базой данных, поэтому мне нужно было очистить существующий контент и перенести его на мой новый статический сайт.
Делать это вручную в стиле чмо не было на столе, даже вопрос, потому что я мог положиться на своих друзей Нокогири и Механизатора, которые сделают эту работу за меня. Впереди у вас достаточно небольшая работа по очистке, которая не слишком сложна, но предлагает несколько интересных поворотов, которые должны быть полезны для веб-пользователей.
Ниже приведены два скриншота из моего подкаста.
Скриншот старого подкаста
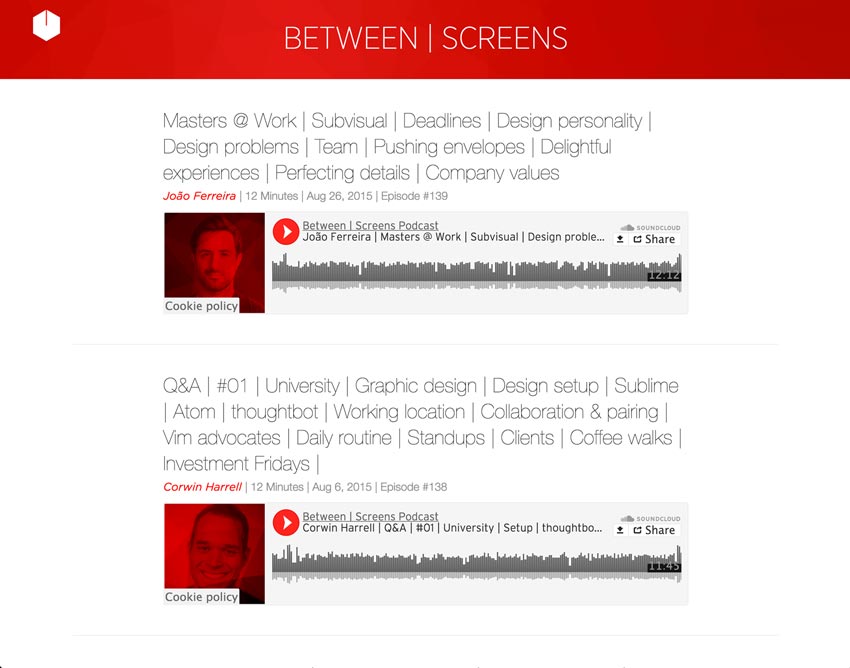
Скриншот нового подкаста
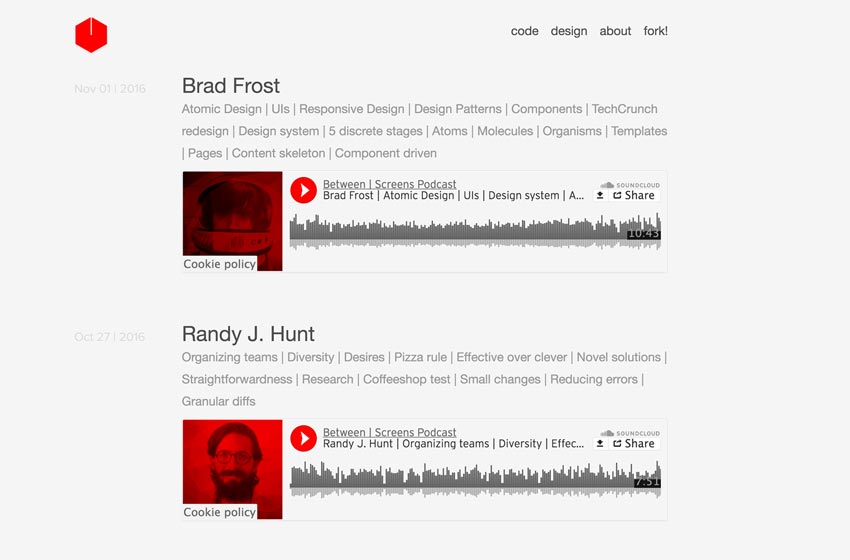
Давайте разберемся, чего мы хотим достичь. Мы хотим извлечь следующие данные из 139 эпизодов, разбросанных по 21 страничным индексным сайтам:
- название
- интервьюируемый
- подзаголовок со списком тем
- номер трека SoundCloud для каждого эпизода
- Дата
- номер эпизода
- текст из шоу заметок
- ссылки из заметок шоу
Мы перебираем пагинацию и позволяем Mechanize щелкать по каждой ссылке для эпизода. На следующей странице с подробной информацией мы найдем всю необходимую информацию сверху. Используя эти извлеченные данные, мы хотим заполнить текст и «тело» файлов уценки для каждого эпизода.
Ниже вы можете увидеть предварительный просмотр того, как мы будем составлять новые файлы уценки с содержанием, которое мы извлекли. Я думаю, что это даст вам хорошее представление о масштабах, которые нас ожидают. Это представляет собой последний шаг в нашем маленьком сценарии. Не волнуйтесь, мы рассмотрим это более подробно.
def compose_markdown
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
def compose_markdown(options={})
<<-HEREDOC
—
title: #{options[:interviewee]}
interviewee: #{options[:interviewee]}
topic_list: #{options[:title]}
tags: #{options[:tags]}
soundcloud_id: #{options[:sc_id]}
date: #{options[:date]}
episode_number: #{options[:episode_number]}
—
#{options[:text]}
HEREDOC
end
|
Я также хотел добавить несколько трюков, которые старый сайт не мог воспроизвести. Для меня было крайне важно иметь настраиваемую комплексную систему тегов. Я хотел, чтобы у слушателей был инструмент глубокого открытия. Поэтому мне нужны были теги для каждого собеседника, а также разделить подзаголовок на теги. Так как я создал 139 эпизодов только в первом сезоне, мне пришлось подготовить сайт к тому времени, когда объем контента становится сложнее прочесывать. Глубокая система меток с разумно расположенными рекомендациями — вот путь. Это позволило мне сохранить сайт легким и быстрым.
Давайте посмотрим на полный код для очистки содержимого моего сайта. Посмотрите вокруг и попытайтесь понять общую картину происходящего. Поскольку я ожидаю, что вы будете на стороне новичка, я избегал слишком много абстрагироваться и допустил ошибку в сторону ясности. Я сделал несколько рефакторингов, которые были нацелены на то, чтобы помочь ясности кода, но я также оставил немного мяса на косточке, чтобы вы могли поиграть, когда закончите с этой статьей. В конце концов, качественное обучение происходит, когда вы выходите за рамки чтения и играете с собственным кодом.
По пути я настоятельно рекомендую вам начать думать о том, как вы можете улучшить код перед собой. Это будет ваша последняя задача в конце этой статьи. Небольшая подсказка от меня: разбивка больших методов на более мелкие всегда является хорошей отправной точкой. Как только вы поймете, как работает код, вы должны весело провести время, оттачивая этот рефакторинг.
Я уже начал с того, что выделил кучу методов в маленьких целенаправленных помощников. Вы легко сможете применить то, что узнали из моих предыдущих статей о запахах кода и их рефакторинге . Если это все еще идет вам прямо сейчас, не волнуйтесь — мы все были там. Просто продолжайте в том же духе, и в какой-то момент все станет быстрее щелкать
Полный код
|
001
002
003
004
005
006
007
008
009
010
011
012
013
014
015
016
017
018
019
020
021
022
023
024
025
026
027
028
029
030
031
032
033
034
035
036
037
038
039
040
041
042
043
044
045
046
047
048
049
050
051
052
053
054
055
056
057
058
059
060
061
062
063
064
065
066
067
068
069
070
071
072
073
074
075
076
077
078
079
080
081
082
083
084
085
086
087
088
089
090
091
092
093
094
095
096
097
098
099
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
|
require ‘Mechanize’
require ‘Pry’
require ‘date’
# Helper Methods
# (Extraction Methods)
def extract_interviewee(detail_page)
interviewee_selector = ‘.episode_sub_title span’
detail_page.search(interviewee_selector).text.strip
end
def extract_title(detail_page)
title_selector = «.episode_title»
detail_page.search(title_selector).text.gsub(/[?#]/, »)
end
def extract_soundcloud_id(detail_page)
sc = detail_page.iframes_with(href: /soundcloud.com/).to_s
sc.scan(/\d{3,}/).first
end
def extract_shownotes_text(detail_page)
shownote_selector = «#shownote_container > p»
detail_page.search(shownote_selector)
end
def extract_subtitle(detail_page)
subheader_selector = «.episode_sub_title»
detail_page.search(subheader_selector).text
end
def extract_episode_number(episode_subtitle)
number = /[#]\d*/.match(episode_subtitle)
clean_episode_number(number)
end
# (Utility Methods)
def clean_date(episode_subtitle)
string_date = /[^|]*([,])(…..)/.match(episode_subtitle).to_s
Date.parse(string_date)
end
def build_tags(title, interviewee)
extracted_tags = strip_pipes(title)
«#{interviewee}»+ «, #{extracted_tags}»
end
def strip_pipes(text)
tags = text.tr(‘|’, ‘,’)
tags = tags.gsub(/[@?#&]/, »)
tags.gsub(/[w\/]{2}/, ‘with’)
end
def clean_episode_number(number)
number.to_s.tr(‘#’, »)
end
def dasherize(text)
text.lstrip.rstrip.tr(‘ ‘, ‘-‘)
end
def extract_data(detail_page)
interviewee = extract_interviewee(detail_page)
title = extract_title(detail_page)
sc_id = extract_soundcloud_id(detail_page)
text = extract_shownotes_text(detail_page)
episode_subtitle = extract_subtitle(detail_page)
episode_number = extract_episode_number(episode_subtitle)
date = clean_date(episode_subtitle)
tags = build_tags(title, interviewee)
options = {
interviewee: interviewee,
title: title,
sc_id: sc_id,
text: text,
tags: tags,
date: date,
episode_number: episode_number
}
end
def compose_markdown(options={})
<<-HEREDOC
—
title: #{options[:interviewee]}
interviewee: #{options[:interviewee]}
topic_list: #{options[:title]}
tags: #{options[:tags]}
soundcloud_id: #{options[:sc_id]}
date: #{options[:date]}
episode_number: #{options[:episode_number]}
—
#{options[:text]}
HEREDOC
end
def write_page(link)
detail_page = link.click
extracted_data = extract_data(detail_page)
markdown_text = compose_markdown(extracted_data)
date = extracted_data[:date]
interviewee = extracted_data[:interviewee]
episode_number = extracted_data[:episode_number]
File.open(«#{date}-#{dasherize(interviewee)}-#{episode_number}.html.erb.md», ‘w’) { |file|
end
def scrape
link_range = 1
agent ||= Mechanize.new
until link_range == 21
page = agent.get(«https://between-screens.herokuapp.com/?page=#{link_range}»)
link_range += 1
page.links[2..8].map do |link|
write_page(link)
end
end
end
scrape
|
Почему мы не require "Nokogiri" ? Mechanize предоставляет нам все наши потребности в очистке. Как мы уже говорили в предыдущей статье, Mechanize строится поверх Nokogiri и позволяет нам также извлекать контент. Однако важно было рассмотреть этот драгоценный камень в первой статье, поскольку нам нужно было основываться на нем.
подглядывать
Обо всем по порядку. Прежде чем мы перейдем к нашему коду, я подумал, что необходимо показать вам, как вы можете эффективно проверять, работает ли ваш код, как и ожидалось, на каждом этапе пути. Как вы наверняка заметили, я добавил еще один инструмент в микс. Среди прочего, Pry действительно удобен для отладки.
Если вы разместите Pry.start(binding) где-нибудь в вашем коде, вы можете проверить свое приложение именно в этот момент. Вы можете заглянуть в объекты в определенных точках в приложении. Это действительно полезно, чтобы подать заявку шаг за шагом, не споткнувшись о свои ноги. Например, давайте разместим его сразу после нашей функции write_page и проверим, является ли link ожидаемой.
подглядывать
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
…
def scrape
link_range = 1
agent ||= Mechanize.new
until link_range == 21
page = agent.get(«https://between-screens.herokuapp.com/?page=#{link_range}»)
link_range += 1
page.links[2..8].map do |link|
write_page(link)
Pry.start(binding)
end
end
end
…
|
Если вы запустите скрипт, мы получим что-то вроде этого.
Выход
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
»$ ruby noko_scraper.rb
321: def scrape
322: link_range = 1
323: agent ||= Mechanize.new
324:
326: until link_range == 21
327: page = agent.get(«https://between-screens.herokuapp.com/?page=#{link_range}»)
328: link_range += 1
329:
330: page.links[2..8].map do |link|
331: write_page(link)
=> 332: Pry.start(binding)
333: end
334: end
335: end
[1] pry(main)>
|
Когда мы затем запрашиваем объект link , мы можем проверить, находим ли мы правильный путь, прежде чем перейти к другим деталям реализации.
Терминал
|
1
2
3
4
|
[2] pry(main)> link
=> #<Mechanize::Page::Link
«Masters @ Work | Subvisual | Deadlines | Design personality | Design problems | Team | Pushing envelopes | Delightful experiences | Perfecting details | Company values»
«/episodes/139»>
|
Похоже, что нам нужно. Отлично, мы можем двигаться дальше. Выполнение этого шага по всему приложению является важной практикой, чтобы вы не потеряли себя и не поняли, как оно работает. Я не буду здесь подробно рассказывать о Прай, так как мне понадобится хотя бы еще одна полная статья. Я могу только рекомендовать использовать его как альтернативу стандартной оболочке IRB. Вернемся к нашей основной задаче.
скребок
Теперь, когда у вас была возможность ознакомиться с кусочками головоломки на месте, я рекомендую пройтись по ним один за другим и уточнить некоторые интересные моменты здесь и там. Давайте начнем с центральных частей.
podcast_scraper.rb
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
…
def write_page(link)
detail_page = link.click
extracted_data = extract_data(detail_page)
markdown_text = compose_markdown(extracted_data)
date = extracted_data[:date]
interviewee = extracted_data[:interviewee]
episode_number = extracted_data[:episode_number]
file_name = «#{date}-#{dasherize(interviewee)}-#{episode_number}.html.erb.md»
File.open(file_name, ‘w’) { |file|
end
def scrape
link_range = 1
agent ||= Mechanize.new
until link_range == 21
page = agent.get(«https://between-screens.herokuapp.com/?page=#{link_range}»)
link_range += 1
page.links[2..8].map do |link|
write_page(link)
end
end
end
…
|
Что происходит в методе scrape ? Прежде всего, я зацикливаюсь на каждой странице индекса в старом подкасте. Я использую старый URL-адрес из приложения Heroku, так как новый сайт уже находится на сайте Между экранами . У меня было 20 страниц эпизодов, которые мне нужно было зациклить.
Я ограничил цикл с помощью переменной link_range , которую я обновлял с каждым циклом. Пройти через нумерацию страниц было так же просто, как использовать эту переменную в URL каждой страницы. Просто и эффективно.
Def Scrape
|
1
|
page = agent.get(«https://between-screens.herokuapp.com/?page=#{link_range}»)
|
Затем, всякий раз, когда я получаю новую страницу с еще восемью эпизодами для очистки, я использую page.links чтобы определить ссылки, по которым мы хотим щелкнуть, и перейти на страницу page.links для каждого эпизода. Я решил использовать ряд ссылок ( links[2..8] ), поскольку они были согласованы на каждой странице. Это был также самый простой способ нацеливать нужные мне ссылки с каждой страницы индекса. Нет необходимости возиться с селекторами CSS здесь.
Затем мы write_page эту ссылку для страницы write_page метод write_page . Здесь большая часть работы выполнена. Мы берем эту ссылку, щелкаем по ней и следуем по ней на страницу сведений, где мы можем начать извлекать ее данные. На этой странице мы находим всю информацию, которая мне нужна для составления моих новых эпизодов уценки для нового сайта.
def write_page
|
1
|
extracted_data = extract_data(detail_page)
|
def extract_data
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
def extract_data(detail_page)
interviewee = extract_interviewee(detail_page)
title = extract_title(detail_page)
sc_id = extract_soundcloud_id(detail_page)
text = extract_shownotes_text(detail_page)
episode_subtitle = extract_subtitle(detail_page)
episode_number = extract_episode_number(episode_subtitle)
date = clean_date(episode_subtitle)
tags = build_tags(title, interviewee)
options = {
interviewee: interviewee,
title: title,
sc_id: sc_id,
text: text,
tags: tags,
date: date,
episode_number: episode_number
}
end
|
Как вы можете видеть выше, мы берем эту detail_page и применяем к ней несколько методов извлечения. Мы извлекаем interviewee , title , sc_id , text , episode_title и episode_number . Я провел рефакторинг нескольких целенаправленных вспомогательных методов, которые отвечают за эти обязанности по извлечению. Давайте кратко рассмотрим их:
Вспомогательные методы
Методы извлечения
Я извлек этих помощников, потому что это позволило мне использовать меньшие методы в целом. Заключение в капсулу их поведения было также важно. Код читается лучше. Большинство из них используют detail_page в качестве аргумента и извлекают некоторые конкретные данные, которые нам нужны для наших сообщений Middleman.
|
1
2
3
4
|
def extract_interviewee(detail_page)
interviewee_selector = ‘.episode_sub_title span’
detail_page.search(interviewee_selector).text.strip
end
|
Мы ищем на странице определенный селектор и получаем текст без лишних пробелов.
|
1
2
3
4
|
def extract_title(detail_page)
title_selector = «.episode_title»
detail_page.search(title_selector).text.gsub(/[?#]/, »)
end
|
Мы берем название и удаляем ? и # поскольку они не очень хорошо подходят к основному вопросу в постах наших эпизодов. Подробнее о сути дела ниже.
|
1
2
3
4
|
def extract_soundcloud_id(detail_page)
sc = detail_page.iframes_with(href: /soundcloud.com/).to_s
sc.scan(/\d{3,}/).first
end
|
Здесь нам нужно было потрудиться, чтобы извлечь идентификатор SoundCloud для наших треков. Для начала нам понадобится встроить iframes с помощью href на soundcloud.com и сделать его строкой для сканирования …
|
1
|
«[#<Mechanize::Page::Frame\n nil\n \»https://w.soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/221003494&auto_play=false&hide_related=false&show_comments=false&show_user=true&show_reposts=false&visual=true\»>\n]»
|
Затем сопоставьте регулярное выражение для его цифр идентификатора дорожки — наш "221003494" .
|
1
2
3
4
|
def extract_shownotes_text(detail_page)
shownote_selector = «#shownote_container > p»
detail_page.search(shownote_selector)
end
|
Извлечение заметок к шоу снова довольно просто. Нам нужно только посмотреть абзацы заметок к шоу на странице с подробностями. Здесь нет сюрпризов.
|
1
2
3
4
|
def extract_subtitle(detail_page)
subheader_selector = «.episode_sub_title»
detail_page.search(subheader_selector).text
end
|
То же самое касается субтитров, за исключением того, что это просто подготовка к чистому извлечению номера эпизода из него.
|
1
2
3
4
|
def extract_episode_number(episode_subtitle)
number = /[#]\d*/.match(episode_subtitle)
clean_episode_number(number)
end
|
Здесь нам нужен еще один раунд регулярного выражения. Давайте посмотрим до и после того, как мы применили регулярное выражение.
episode_subtitle
|
1
|
» João Ferreira | 12 Minutes | Aug 26, 2015 | Episode #139 «
|
число
|
1
|
«#139»
|
Еще один шаг, пока у нас не будет чистого номера.
|
1
2
3
|
def clean_episode_number(number)
number.to_s.tr(‘#’, »)
end
|
Мы берем это число с хешем # и удаляем его. Вуаля, у нас также есть наш первый эпизод № 139 . Я предлагаю, чтобы мы рассмотрели и другие полезные методы, прежде чем свести все это вместе.
Полезные методы
После всего этого бизнеса по добыче у нас есть кое-что сделать. Мы уже можем начать готовить данные для составления уценки. Например, я episode_subtitle немного, чтобы получить episode_subtitle дату и создаю tags с build_tags метода build_tags .
def clean_date
|
1
2
3
4
|
def clean_date(episode_subtitle)
string_date = /[^|]*([,])(…..)/.match(episode_subtitle).to_s
Date.parse(string_date)
end
|
Мы запускаем другое регулярное выражение, которое выглядит для таких дат: " Aug 26, 2015" . Как видите, это пока не очень полезно. Из string_date мы получаем из субтитров, нам нужно создать реальный объект Date . В противном случае было бы бесполезно создавать посты посредников.
string_date
|
1
|
» Aug 26, 2015″
|
Поэтому мы берем эту строку и делаем Date.parse . Результат выглядит многообещающе.
Дата
|
1
|
2015-08-26
|
def build_tags
|
1
2
3
4
|
def build_tags(title, interviewee)
extracted_tags = strip_pipes(title)
«#{interviewee}»+ «, #{extracted_tags}»
end
|
Это берет title и interviewee мы создали в методе extract_data и удаляет все символы канала и спам. Мы заменяем символы канала запятой, @ ? , # и & с пустой строкой, и, наконец, позаботьтесь о сокращениях для with .
def strip_pipes
|
1
2
3
4
5
|
def strip_pipes(text)
tags = text.tr(‘|’, ‘,’)
tags = tags.gsub(/[@?#&]/, »)
tags.gsub(/[w\/]{2}/, ‘with’)
end
|
В конце мы также включаем имя собеседника в список тегов и разделяем каждый тег запятой.
Перед
|
1
|
«Masters @ Work | Subvisual | Deadlines | Design personality | Design problems | Team | Pushing envelopes | Delightful experiences | Perfecting details | Company values»
|
После
|
1
|
«João Ferreira, Masters Work , Subvisual , Deadlines , Design personality , Design problems , Team , Pushing envelopes , Delightful experiences , Perfecting details , Company values»
|
Каждый из этих тегов станет ссылкой на коллекцию сообщений по этой теме. Все это произошло внутри метода extract_data . Давайте еще раз посмотрим, где мы находимся:
def extract_data
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
def extract_data(detail_page)
interviewee = extract_interviewee(detail_page)
title = extract_title(detail_page)
sc_id = extract_soundcloud_id(detail_page)
text = extract_shownotes_text(detail_page)
episode_subtitle = extract_subtitle(detail_page)
episode_number = extract_episode_number(episode_subtitle)
date = clean_date(episode_subtitle)
tags = build_tags(title, interviewee)
options = {
interviewee: interviewee,
title: title,
sc_id: sc_id,
text: text,
tags: tags,
date: date,
episode_number: episode_number
}
end
|
Все, что здесь осталось сделать, это вернуть хэш опций с данными, которые мы извлекли. Мы можем compose_markdown этот хэш в метод compose_markdown , который compose_markdown наши данные для записи в виде файла, который мне нужен для моего нового сайта.
Написание сообщений
def compose_markdown
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
def compose_markdown(options={})
<<-HEREDOC
—
title: #{options[:interviewee]}
interviewee: #{options[:interviewee]}
topic_list: #{options[:title]}
tags: #{options[:tags]}
soundcloud_id: #{options[:sc_id]}
date: #{options[:date]}
episode_number: #{options[:episode_number]}
—
#{options[:text]}
HEREDOC
end
|
Для публикации эпизодов подкастов на моем сайте Middleman я решил изменить систему ведения блогов. Вместо того, чтобы создавать «чистые» посты в блоге, я создаю заметки для моих эпизодов, которые отображают эпизоды, размещенные в SoundCloud через фреймы. На индексных сайтах я отображаю только этот iframe плюс заголовок и прочее.
Формат, который мне нужен для работы, состоит из чего-то, что называется передним вопросом. Это в основном хранилище ключей / значений для моих статических сайтов. Он заменяет мои потребности в базе данных с моего старого сайта Синатры.
Такие данные, как имя собеседника, дата, идентификатор дорожки SoundCloud, номер эпизода и т. Д., Находятся между тремя тире ( --- ) поверх файлов наших эпизодов. Ниже приводится содержание каждого эпизода — такие как вопросы, ссылки, спонсорские материалы и т. Д.
Front Matter
|
1
2
3
4
5
6
7
8
|
—
key: value
key: value
key: value
key: value
—
Episode content goes here.
|
В методе compose_markdown я использую HEREDOC для компоновки этого файла с его HEREDOC для каждого эпизода, который мы HEREDOC . Из хеша опций, который мы передаем этому методу, мы извлекаем все данные, которые мы собрали во вспомогательном методе extract_data .
def compose_markdown
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
…
<<-HEREDOC
—
title: #{options[:interviewee]}
interviewee: #{options[:interviewee]}
topic_list: #{options[:title]}
tags: #{options[:tags]}
soundcloud_id: #{options[:sc_id]}
date: #{options[:date]}
episode_number: #{options[:episode_number]}
—
#{options[:text]}
HEREDOC
…
|
Это план для нового эпизода подкаста прямо здесь. Вот для чего мы пришли. Возможно, вы задаетесь вопросом об этом конкретном синтаксисе: #{options[:interviewee]} . Я как обычно интерполирую со строками, но так как я уже внутри <<-HEREDOC , я могу оставить двойные кавычки выключенными.
Просто чтобы сориентироваться, мы все еще находимся в цикле, внутри функции write_page для каждой write_page ссылки на страницу с подробностями показа примечаний к единственному эпизоду. Что происходит дальше, готовится записать этот план в файловую систему. Другими словами, мы создаем фактический эпизод, предоставляя имя файла и составленный markdown_text .
Для этого последнего шага нам просто нужно подготовить следующие ингредиенты: дату, имя интервьюируемого и номер эпизода. Плюс конечно compose_markdown , который мы только что получили из compose_markdown .
def write_page
|
01
02
03
04
05
06
07
08
09
10
|
…
markdown_text = compose_markdown(extracted_data)
date = extracted_data[:date]
interviewee = extracted_data[:interviewee]
episode_number = extracted_data[:episode_number]
file_name = «#{date}-#{dasherize(interviewee)}-#{episode_number}.html.erb.md»
…
|
Тогда нам нужно только взять file_name и markdown_text и записать файл.
def write_page
|
1
2
3
4
5
|
…
File.open(file_name, ‘w’) { |file|
…
|
Давайте разберемся и с этим. Для каждого поста мне нужен определенный формат: что-то вроде 2016-10-25-Avdi-Grimm-120 . Я хочу выписать файлы, которые начинаются с даты и включают имя собеседника и номер серии.
Чтобы соответствовать формату, dasherize для новых постов, мне нужно было взять имя собеседника и dasherize его через мой вспомогательный метод, чтобы dasherize его имя от Avdi Grimm до Avdi-Grimm . Ничего волшебного, но стоит посмотреть
Def Dasherize
|
1
2
3
|
def dasherize(text)
text.lstrip.rstrip.tr(‘ ‘, ‘-‘)
end
|
Он удаляет пробелы из текста, который мы удалили для имени собеседника, и заменяет пробел между Авди и Гриммом. Остальная часть имени файла разбита в самой строке: "date-interviewee-name-episodenumber" .
def write_page
|
1
2
3
4
5
|
…
«#{date}-#{dasherize(interviewee)}-#{episode_number}.html.erb.md»
…
|
Поскольку извлеченный контент поступает прямо с HTML-сайта, я не могу просто использовать .md или .markdown в качестве расширения имени файла. Я решил пойти с .html.erb.md . Для будущих эпизодов, которые я сочиняю без очистки, я могу .html.erb часть .html.erb и .html.erb нужен только .md .
После этого шага цикл в функции scrape завершается, и у нас должен быть один эпизод, который выглядит следующим образом:
2014-12-01-Avdi-Grimm-1.html.erb.md
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
—
title: Avdi Grimm
interviewee: Avdi Grimm
topic_list: What is Rake |
tags: Avdi Grimm, What is Rake , Origins , Jim Weirich , Common use cases , Advantages of Rake
soundcloud_id: 179619755
date: 2014-12-01
episode_number: 1
—
Questions:
— What is Rake?
— What can you tell us about the origins of Rake?
— What can you tell us about Jim Weihrich?
— What are the most common use cases for Rake?
— What are the most notable advantages of Rake?
Links:
In»>http://www.youtube.com/watch?v=2ZHJSrF52bc»>In memory of the great Jim Weirich
Rake»>https://github.com/jimweirich/rake»>Rake on GitHub
Jim»>https://github.com/jimweirich»>Jim Weirich on GitHub
Basic»>http://www.youtube.com/watch?v=AFPWDzHWjEY»>Basic Rake talk by Jim Weirich
Power»>http://www.youtube.com/watch?v=KaEqZtulOus»>Power Rake talk by Jim Weirich
Learn»>http://devblog.avdi.org/2014/04/30/learn-advanced-rake-in-7-episodes/»>Learn advanced Rake in 7 episodes — from Avdi Grimm ( free )
Avdi»>http://about.avdi.org/»>Avdi Grimm
Avdi Grimm’s screencasts: Ruby»>http://www.rubytapas.com/»>Ruby Tapas
Ruby»>http://devchat.tv/ruby-rogues/»>Ruby Rogues podcast with Avdi Grimm
Great ebook: Rake»>http://www.amazon.com/Rake-Management-Essentials-Andrey-Koleshko/dp/1783280778″>Rake Task Management Essentials fromhttps://twitter.com/ka8725″> Andrey Koleshko
|
Конечно, этот скребок будет начинаться в последнем эпизоде и дойдет до первого цикла. В демонстрационных целях эпизод 01 так же хорош, как и любой другой. Вы можете увидеть в начале с данными, которые мы извлекли.
Все это ранее было заблокировано в базе данных моего приложения Sinatra — номер эпизода, дата, имя собеседника и так далее. Теперь мы готовы стать частью моего нового статичного сайта Middleman. Все, что ниже двух тройных черточек ( --- ) — это текст заметок к шоу: в основном вопросы и ссылки.
Последние мысли
И мы сделали. Мой новый подкаст уже запущен и работает. Я очень рад, что нашел время, чтобы изменить дизайн с нуля. Публиковать новые эпизоды сейчас намного круче. Обнаружение нового контента должно быть более плавным и для пользователей.
Как я упоминал ранее, сейчас самое время пойти в редактор кода, чтобы повеселиться. Возьми этот код и поборись с ним немного. Попробуйте найти способы сделать это проще. Есть несколько возможностей для рефакторинга кода.
В целом, я надеюсь, что этот небольшой пример дал вам хорошее представление о том, что вы можете сделать с помощью новых веб-страниц. Конечно, вы можете решать гораздо более сложные задачи — я уверен, что с этими навыками можно создать множество возможностей для малого бизнеса.
Но, как всегда, делайте это по одному шагу за раз, и не расстраивайтесь, если что-то не сработает. Это не только нормально для большинства людей, но и следовало ожидать. Это часть путешествия. Счастливого соскоба!