Поведенческая разработка является отличным процессом для разработки программного обеспечения. С тестированием, которое часто откладывается до последней минуты (или полностью игнорируется), внедрение процесса в ваш ежедневный рабочий процесс может оказаться чрезвычайно полезным для качества вашего кода. Структура и дизайн тестов в сочетании с синтаксисом Gherkin делают тесты легко читаемыми даже для членов команды с нетехническим опытом.
Весь код должен быть тщательно протестирован, а это означает, что в идеале дефекты никогда не должны достигать производства Если они это сделают, то тщательный набор тестов, ориентированный на поведение вашего приложения в целом, гарантирует, что их легко как обнаружить, так и исправить. Именно скорость, ясность, фокус и качество в вашем коде — вот почему вы должны принять этот процесс … сейчас.
Что такое развитие на основе поведения?
Поведенческая разработка (которую мы теперь будем называть «BDD») следует из идей и принципов, представленных в разработке через тестирование. Ключевые моменты написания тестов перед кодом действительно применимы и к BDD. Идея состоит в том, чтобы не только тестировать ваш код на детальном уровне с помощью модульных тестов, но и тестировать приложение полностью, используя приемочные тесты. Мы представим этот стиль тестирования с использованием инфраструктуры тестирования салата .
Разработка на основе поведения (BDD) является подмножеством разработки на основе тестирования (TDD).
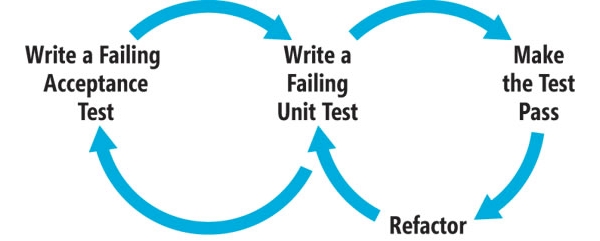
Процесс может быть просто определен как:
- Написать не пройденный приемочный тест
- Написать неудачный юнит-тест
- Сделайте прохождение модульного теста
- Refactor
- Пройти приемочный тест
Промойте и повторите для каждой функции, как это необходимо.
BDD в Agile Development
BDD действительно вступает в свои права, когда используется с гибкой разработкой.
Совет: обратитесь к Принципам гибкой разработки для получения дополнительной информации о методах гибкой разработки.
С появлением новых функций и требований каждые 1, 2 или 4 недели, в зависимости от вашей команды, вам необходимо быстро протестировать и написать код для этих требований. Приемочное и модульное тестирование в Python позволяет достичь этих целей.
Приемочные тесты, как известно, используют «функциональный» файл английского (или, возможно, альтернативного) языкового формата, описывающий то, что охватывает тест, и сами отдельные тесты. Это может привлечь всех в вашей команде — не только разработчиков, но и менеджеров и бизнес-аналитиков, которые иначе не сыграли бы никакой роли в процессе тестирования. Это может помочь укрепить уверенность всей команды в том, чего они стремятся достичь.
Файлы функций позволяют описывать тесты на языке, который / может быть доступен для всех уровней бизнеса, и гарантируют, что предоставляемые функции сформулированы и протестированы в соответствии с требованиями и ожиданиями бизнеса. Одно только модульное тестирование не может гарантировать, что доставляемое приложение на самом деле обеспечивает всю необходимую функциональность. Таким образом, приемочное тестирование добавляет еще один уровень доверия к вашему коду, чтобы убедиться, что эти отдельные «единицы» совмещены для обеспечения полного требуемого пакета. Преимущество приемочного тестирования заключается в том, что его можно применять к любому проекту, над которым вы работаете, как в большом, так и в малом масштабе.
Огурец Синтаксис
Приемочные тесты обычно используют синтаксис Gherkin, представленный фреймворком Cucumber , написанным для Ruby. Синтаксис довольно прост для понимания, и в пакете Lettuce Python используются следующие восемь ключевых слов для определения ваших функций и тестов:
- Данный
- когда
- потом
- И
- Особенность:
- Фон:
- Сценарий:
- План сценария:
Ниже вы можете просмотреть эти ключевые слова в действии и узнать, как их можно использовать для структурирования ваших приемочных тестов.
Установка
Установка пакета Lettuce проста, следуя обычному шаблону pip install который знаком большинству разработчиков Python.
Выполните следующие шаги, чтобы начать использовать Lettuce :
-
$ pip install lettuce -
$ lettuce /path/to/example.featureдля запуска ваших тестов. Вы можете запустить только один файл объектов или, если вы передадите каталог файлов объектов, вы можете запустить все из них.
Вам также следует установить nosetests (если он еще не установлен), так как вы будете использовать некоторые из утверждений, которые предоставляет nosetests чтобы облегчить написание и использование ваших тестов.
-
$ pip install nose
Файлы функций
Файлы компонентов написаны на простом английском языке и указывают область приложения, охватываемую тестами. Они также предоставляют некоторые задачи настройки для тестов. Это означает, что вы не только пишете свои тесты, но фактически заставляете себя писать хорошую документацию для всех аспектов вашего приложения. Таким образом, вы можете четко определить, что делает каждый фрагмент кода и что он обрабатывает. Этот документальный аспект тестов может быть велик по мере роста размера вашего приложения, и вы хотите посмотреть, как работает определенный аспект приложения, или вы хотите напомнить себе, например, как взаимодействовать с частью API.
Давайте создадим файл Feature, который будет тестировать приложение, написанное для моей статьи « Разработка через тестирование на Python» для Tuts +. Приложение представляет собой простой калькулятор, написанный на Python, но оно покажет нам основы написания приемочных тестов. Вы должны структурировать свое приложение с помощью app и папки с tests . В папке tests добавьте папку с features . Поместите следующий код в файл с именем calculator.py в папке app .
|
1
2
3
4
5
6
7
8
|
class Calculator(object):
def add(self, x, y):
number_types = (int, long, float, complex)
if isinstance(x, number_types) and isinstance(y, number_types):
return x + y
else:
raise ValueError
|
Теперь добавьте следующий код в файл с именем calculator.feature в папке tests/features .
|
01
02
03
04
05
06
07
08
09
10
11
|
Feature: As a writer for NetTuts
I wish to demonstrate
How easy writing Acceptance Tests
In Python really is.
Background:
Given I am using the calculator
Scenario: Calculate 2 plus 2 on our calculator
Given I input «2» add «2»
Then I should see «4»
|
Из этого простого примера вы можете увидеть, насколько просто описать свои тесты и поделиться ими с различными людьми, участвующими в вашей команде.
В файле возможностей есть три ключевых области примечания:
- Функциональный блок: Здесь вы пишете документацию для этой группы тестов. Здесь код не выполняется, но он позволяет читателю точно понять, что тестирует эта функция.
- Фоновый блок: выполняется перед каждым сценарием в файле Feature. Это похоже на метод
SetUp()и позволяет вам выполнить необходимый код установки, например, убедиться, что вы находитесь на какой-то странице или имеете определенные условия. - Блок сценария: здесь вы определяете тест. Первая строка снова служит документацией, а затем вы переходите в свой сценарий для выполнения теста. Должно быть довольно легко увидеть, как можно написать любой тест в этом стиле.
Файл шагов
Исходя из файла Feature, у нас должен быть файл шагов внизу. Вот где происходит «волшебство». Очевидно, что сам файл Feature ничего не сделает; это требует шагов, чтобы фактически отобразить каждую строку для выполнения кода Python внизу. Это достигается за счет использования регулярных выражений.
«Регулярные выражения? Слишком сложный, чтобы беспокоиться при тестировании» часто может быть ответом на RegEx в этих тестах. Однако в мире BDD они используются для захвата всей строки или использования очень простых RegEx для выбора переменных из строки. Поэтому вы не должны откладывать их использование здесь.
Регулярные выражения? Слишком сложно, чтобы беспокоиться в тестировании? Не в салате. Просто и легко!
Если мы рассмотрим пример. Вы увидите, как легко файл «Шаги» следует из компонента.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
from lettuce import *
from nose.tools import assert_equals
from app.calculator import Calculator
@step(u’I am using the calculator’)
def select_calc(step):
print (‘Attempting to use calculator…’)
world.calc = Calculator()
@step(u’I input «([^»]*)» add «([^»]*)»‘)
def given_i_input_group1_add_group1(step, x, y):
world.result = world.calc.add(int(x), int(y))
@step(u’I should see «([^»]+)»‘)
def result(step, expected_result):
actual_result = world.result
assert_equals(int(expected_result), actual_result)
|
Первое, на что стоит обратить внимание, это стандартный импорт в верхней части файла. Поэтому нам нужен доступ к нашему классу Calculator и, конечно же, к инструментам, предоставляемым Lettuce. Вы также импортируете некоторые удобные методы из пакета для nosetest , такие как assert_equals чтобы упростить утверждения в шагах. Затем вы можете начать определять шаги для каждой строки в файле Feature. Мы можем видеть, что, как объяснялось ранее, регулярные выражения в основном просто собирают всю строку, за исключением тех случаев, когда мы хотим получить доступ к переменной внутри строки.
Если мы используем @step(u'I input "([^"]*)" add "([^"]*)"') качестве нашего примера, вы можете увидеть, что строка сначала выбирается с помощью @step декоратор. Затем вы используете символ 'u' в начале, чтобы указать строку в кодировке Unicode, для которой салат будет выполнять регулярные выражения. После этого это просто сама строка и очень простое регулярное выражение для соответствия чему-либо в кавычках — числа, которые нужно добавить в этом случае.
Затем вы должны увидеть, что метод Python следует непосредственно после этого, с переменными, передаваемыми в метод с любым именем, которое вы пожелаете. Здесь я назвал их x и y чтобы указать два числа, которые будут переданы в метод add калькулятора.
Еще один заметный момент здесь — использование переменной world . Это контейнер с глобальной областью действия, который позволяет использовать переменные на разных этапах сценария. Если бы мы этого не сделали, все переменные были бы локальны для их метода, но здесь мы создаем экземпляр Calculator() один раз, а затем обращаемся к нему на каждом шаге. Вы также используете ту же технику для сохранения результата метода add в одном шаге, а затем утверждаете результат в другом шаге.
Выполнение функций
Имея файл функции и шаги, вы можете выполнить тесты и посмотреть, пройдут ли они. Как упоминалось ранее, выполнение тестов является простым, и Lettuce предоставляет встроенный тестовый прогон, доступный вам из командной строки после установки. Попробуйте выполнить lettuce test/features/calculator.feature в предпочитаемом вами приложении командной строки.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
$ lettuce tests/features/calculator.feature
Feature: As a writer for NetTuts # tests/features/calculator.feature:1
I wish to demonstrate # tests/features/calculator.feature:2
How easy writing Acceptance Tests # tests/features/calculator.feature:3
In Python really is.
Background:
Given I am using the calculator # tests/features/steps.py:6
Given I am using the calculator # tests/features/steps.py:6
Scenario: Calculate 2 plus 2 on our calculator # tests/features/calculator.feature:9
Given I input «2» add «2» # tests/features/steps.py:11
Then I should see «4» # tests/features/steps.py:16
1 feature (1 passed)
1 scenario (1 passed)
2 steps (2 passed)
|
Вывод салата действительно хорош, так как он показывает вам каждую строку файла объекта, который был выполнен, и подсвечивается зеленым цветом, чтобы показать, что он успешно прошел эту строку. Он также показывает, какой файл функций он выполняет, и номер строки, которая пригодится, когда вы соберете большой набор тестов с многочисленными функциями и вам потребуется найти ошибочную строку функции, например, когда тест не пройден. Наконец, последняя часть вывода предоставляет вам статистику о количестве выполненных функций, сценариев и шагов, а также о количестве пройденных. В нашем примере все тесты были хорошими, но давайте посмотрим, как Lettuce показывает ошибки тестирования и как их можно отлаживать и исправлять.
Внесите изменения в код calculator.py , чтобы тест не прошел, например, изменив метод add, чтобы фактически вычесть два переданных числа.
|
1
2
3
4
5
6
7
8
|
class Calculator(object):
def add(self, x, y):
number_types = (int, long, float, complex)
if isinstance(x, number_types) and isinstance(y, number_types):
return x — y
else:
raise ValueError
|
Теперь, когда вы запустите файл возможностей с помощью Lettuce, вы увидите, как он четко указывает, что пошло не так в тесте, и какая часть кода не выполнена.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
$ lettuce tests/features/calculator.feature
Feature: As a writer for NetTuts # tests/features/calculator.feature:1
I wish to demonstrate # tests/features/calculator.feature:2
How easy writing Acceptance Tests # tests/features/calculator.feature:3
In Python really is.
Background:
Given I am using the calculator # tests/features/steps.py:6
Given I am using the calculator # tests/features/steps.py:6
Scenario: Calculate 2 plus 2 on our calculator # tests/features/calculator.feature:9
Given I input «2» add «2» # tests/features/steps.py:11
Then I should see «4» # tests/features/steps.py:16
Traceback (most recent call last):
File «/Users/user/.virtualenvs/bdd-in-python/lib/python2.7/site-packages/lettuce/core.py», line 144, in __call__
ret = self.function(self.step, *args, **kw)
File «/Users/user/Documents/Articles — NetTuts/BDD_in_Python/tests/features/steps.py», line 18, in result
assert_equals(int(expected_result), actual_result)
File «/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/unittest/case.py», line 515, in assertEqual
assertion_func(first, second, msg=msg)
File «/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/unittest/case.py», line 508, in _baseAssertEqual
raise self.failureException(msg)
AssertionError: 4 != 0
1 feature (0 passed)
1 scenario (0 passed)
2 steps (1 failed, 1 passed)
List of failed scenarios:
Scenario: Calculate 2 plus 2 on our calculator # tests/features/calculator.feature:9
|
Очевидно, что ожидаемое значение 4 теперь не соответствует фактическому возвращаемому значению 0 . Салат ясно показал вам эту проблему, и вы можете отладить свой код, чтобы выяснить, что пошло не так, применить исправление и снова пройти тест.
Альтернативные инструменты

В Python есть множество альтернативных вариантов для проведения этой формы тестирования. У нас есть примеры, такие как Behave, Lettuce, а также Cucumber, которые, как уже упоминалось, определили эту структуру. Другие инструменты по сути являются клонами / портами Cucumber. Cucumber можно использовать с кодом Python, используя интерпретатор Ruby-Python, но это выходит за рамки данного руководства.
- Поведение : почти точный порт Огурца в Питон. Имеет хороший уровень документации и постоянно обновляется разработчиками. Они также предлагают сравнение с другими инструментами , которые стоит прочитать.
- Freshen : еще один прямой порт Cucumber, содержащий учебники и примеры на их веб-сайте, а также простые инструменты установки, такие как «pip».
Ключевым моментом всех этих инструментов является то, что все они более или менее одинаковы. Как только вы овладеете одним, вы быстро поймете другие, если решите переключиться. Быстрый обзор документации должен быть достаточным для большинства разработчиков, владеющих Python.
преимущества
Вы можете уверенно погрузиться в рефакторинг.
Существуют значительные преимущества использования тщательного набора тестов. Один из главных — это рефакторинг кода. Имея надежный набор тестов, вы можете уверенно погрузиться в рефакторинг, зная, что вы не нарушили прежнее поведение в своем приложении.
Это приобретает все большее значение по мере развития вашего приложения и увеличения его размеров. Когда у вас появляется все больше и больше унаследованного кода, становится очень трудно возвращаться и вносить изменения с уверенностью и знать, что вы определенно не нарушили существующее поведение. Если у вас есть полный набор приемочных тестов, написанных для каждой разрабатываемой функции, вы знаете, что вы не нарушили эту существующую функциональность до тех пор, пока, когда вы вносите изменения, вы запускаете полную сборку своих тестов, прежде чем запускать эти изменения. Вы проверяете, что ваш код не « регрессировал » из-за ваших изменений и перезапусков.
Еще одним большим преимуществом внедрения приемочного тестирования в ваш ежедневный рабочий процесс является возможность провести разъяснительную сессию перед началом разработки функции.
Например, у вас могут быть разработчики, которые будут кодировать решение функции, тестировщики (обеспечение качества / контроль качества), которые тестируют код после завершения, и бизнес-технический аналитик, которые сядут и прояснят требования к функции, а затем задокументируйте это как файлы функций, к которым разработчики будут работать.
По сути, у вас может быть набор файлов с ошибками, которые разработчики могут запускать и проходить один за другим, чтобы они знали, что с этой функцией все сделано, когда все пройдут. Это дает разработчикам тот фокус, который им нужен для точного соответствия требованиям, а не для расширения кода с функциями и возможностями, которые не обязательно требуются (также известными как «золотое покрытие»). Затем тестировщики могут просмотреть файлы функций, чтобы убедиться, что все покрыто должным образом. Процесс может быть предпринят для следующей функции.
Последние мысли
Работая в команде, используя описанные выше процессы и инструменты, я лично ощутил огромные преимущества такой работы. BDD обеспечивает вашу команду ясностью, целеустремленностью и уверенностью в предоставлении отличного кода, сводя при этом к минимуму возможные ошибки.
Берегись!
Если эта статья разожгла ваш аппетит в мире тестирования на Python, почему бы не проверить мою книгу « Тестирование Python », выпущенную недавно на Amazon и других хороших ритейлерах. Посетите эту страницу, чтобы приобрести свою копию книги сегодня и поддержать одного из своих участников Tuts +.