
Ниже приводится выдержка из нашей книги « HTML5 и CSS3 для реального мира», 2-е издание , написанной Алексисом Гольдштейном, Луи Лазарисом и Эстель Вейль. Копии продаются в магазинах по всему миру, или вы можете купить их в электронном виде здесь .
Микроданные — это еще одна технология, которая быстро завоевывает признание и поддержку, но, в отличие от WAI-ARIA, технически является частью HTML5. Несмотря на то, что разработка еще находится на ранней стадии разработки, стоит упомянуть здесь спецификацию микроданных, поскольку эта технология дает представление о том, что может стать будущим читабельности и семантики документов.
В спецификации микроданные определены как механизм, который «позволяет машиночитаемым данным быть легко внедряемыми в HTML-документы с помощью однозначной модели анализа».
С помощью микроданных авторы страниц могут добавлять специальные метки к элементам HTML, аннотируя их, чтобы их можно было читать на машинах или ботах. Это делается с помощью специального словаря. Например, вы можете захотеть, чтобы скрипт или другая сторонняя служба могли иметь доступ к вашим страницам и определенным образом взаимодействовать с определенными элементами на странице. С помощью микроданных вы можете расширить существующие семантические элементы (например, article и figure ), чтобы эти службы имели специализированный доступ к аннотированному контенту.
Это может показаться странным, поэтому давайте подумаем о реальном примере. Допустим, на вашем сайте есть обзоры фильмов. Вы можете иметь каждый отзыв в элементе article , с количеством звездочек или процентным баллом за ваш отзыв. Но когда появляется такая машина, как поисковый паук Google, у нее нет возможности узнать, какая часть вашего контента является реальным обзором — все, что она видит, это куча текста на странице.
Почему машина хочет знать, что вы думаете о фильме? Стоит учесть, что Google начал отображать более богатую информацию на своих страницах результатов поиска, чтобы предоставить поисковикам больше, чем просто текстовые соответствия для своих запросов. Это достигается путем считывания обзорной информации, закодированной на страницах этих сайтов с использованием микроданных или других подобных технологий. Пример информации о просмотре фильма показан ниже.
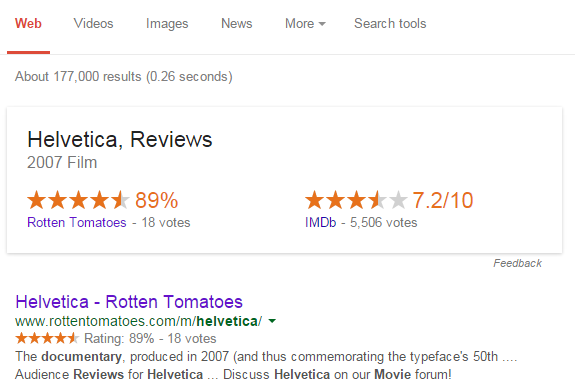
Используя микроданные, вы можете точно указать, какие части вашей страницы соответствуют рецензиям, людям, событиям и т. Д. — в едином словаре, который программные приложения могут понять и использовать.
Не достаточно ли семантики HTML5?
Спецификация HTML5 теперь включает в себя ряд новых элементов, обеспечивающих более выразительную разметку. Но было бы контрпродуктивно добавлять элементы в HTML, которые могли бы использовать только немногие люди. Это привело бы к раздуванию языка, что сделало бы его возможности неуправляемыми со всех точек зрения — будь то авторы спецификаций, поставщики браузеров или органы стандартизации.
Микроданные, с другой стороны, позволяют разработчикам использовать собственные словари (как существующие, так и свои) для конкретных ситуаций, которые невозможны с использованием семантических элементов HTML5. Таким образом, существующие элементы HTML и новые элементы, добавленные в HTML5, сохраняются как своего рода семантическая базовая линия, в то время как разработчики могут создавать специальные аннотации для удовлетворения своих собственных потребностей.
Синтаксис микроданных
Микроданные работают с существующим правильно сформированным содержимым HTML и добавляются в документ с помощью пар имя-значение (также называемых свойствами ). Микроданные запрещают вам создавать новые элементы; вместо этого он дает вам возможность добавлять настраиваемые атрибуты, которые расширяют семантику существующих элементов.
Вот простой пример:
<aside itemscope> <h1 itemprop="name">John Doe</h1> <p><img src="http://www.sitepoint.com/bio-photo.jpg" alt="John Doe" itemprop="photo"></p> <p><a href="http://www.sitepoint.com" itemprop="url">Author's website</a></p> </aside>
В приведенном выше примере у нас есть заурядная биография автора, помещенная в aside элемент. Первая странность, которую вы заметите, это логический атрибут itemscope . Это идентифицирует элемент aside как контейнер, который определяет область нашего словаря микроданных. Наличие атрибута itemscope определяет то, что в спецификации называется предметом . Каждый элемент характеризуется группой пар имя-значение.
Возможность определить объем наших словарей позволяет нам определять несколько словарей на одной странице. В этом примере все пары «имя-значение» внутри элемента aside являются частью одного словаря микроданных.
После атрибута itemscope следующим интересующим элементом является атрибут itemprop , который имеет значение "name" . На этом этапе, вероятно, будет хорошей идеей объяснить, как скрипт получит информацию из этих атрибутов, а также то, что мы подразумеваем под «парами имя-значение».
Понимание пары имя-значение
Имя — это свойство, определенное с помощью атрибута itemprop . В нашем примере первым именем свойства является имя с name . В этой области есть два дополнительных имени свойства: photo и url .
Значения для данного свойства определяются по-разному, в зависимости от элемента, на котором объявлено свойство. Для большинства элементов значение берется из его текстового содержимого; например, свойство name в нашем примере получит свое значение из текстового содержимого между открывающим и закрывающим тегами h1 . Другие элементы обрабатываются по-разному.
Свойство photo берет свое значение из атрибута src изображения, поэтому значение состоит из URL-адреса, указывающего на фотографию автора. Свойство url , хотя и определено для элемента с текстовым содержимым (а именно с фразой «сайт автора»), не использует это текстовое содержимое для определения его значения; вместо этого он получает свое значение из атрибута href .
Другие элементы, которые не используют связанный с ними текстовый контент для определения значений микроданных, включают meta , iframe , object , audio , link и time . Полный список элементов, которые получают свои значения не из текстового содержимого, см. В разделе « Значения» спецификации микроданных.
Пространства имен микроданных
То, что мы описали до сих пор, приемлемо для микроданных, которые не предназначены для повторного использования, но это немного непрактично. Реальная сила микроданных раскрывается, когда, как мы обсуждали, сторонние скрипты и авторы страниц могут получить доступ к нашим парам имя-значение и найти для них полезное применение.
Чтобы это произошло, каждый элемент должен определить тип с помощью атрибута itemtype . Помните, что элемент в контексте микроданных — это элемент, для itemscope установлен атрибут itemscope . Каждая пара элемент и имя-значение внутри этого элемента является частью этого элемента. Следовательно, значение атрибута itemtype определяет пространство имен для словаря этого элемента. Давайте добавим itemtype в наш пример:
<aside itemscope itemtype="http://schema.org/Person"> <h1 itemprop="name">John Doe</h1> <p><img src="http://www.sitepoint.com/bio-photo.jpg" alt="John Doe" itemprop="photo"></p> <p><a href="http://www.sitepoint.com" itemprop="url">Author's website</a></p> </aside>
В нашем материале мы используем URL-адрес «http://schema.org/Person», который принадлежит Schema.org, совместному проекту, поддерживаемому несколькими основными поисковыми системами. На этом веб-сайте размещены несколько словарей микроданных, в том числе организация, человек, обзор, событие и многое другое.
Дальнейшее чтение
Это краткое введение в Microdata едва раскрывает тему, но мы надеемся, что оно даст вам представление о том, что возможно при расширении семантики ваших документов с помощью этой технологии.
Это очень широкая тема, которая требует чтения и изучения вне этого источника. Имея это в виду, вот несколько ссылок, чтобы проверить, хотите ли вы углубиться в возможности, предлагаемые Microdata: