Оказывается, вы можете многое сделать с Raspberry Pi и IBM Bluemix. В первой статье этой серии мы рассмотрели, как подключить Raspberry Pi к IBM Bluemix, IBM Watson и Node-RED . Если вы еще не настроили Raspberry Pi с Bluemix и Node-RED, сначала пройдите первую часть, а затем возвращайтесь! Я лично использовал Raspberry Pi 3 для этого, однако я предполагаю, что Raspberry Pi 2 может работать так же хорошо.
В этой статье мы собираемся изучить, как внести текст в речь в наш поток Node-RED из предыдущего примера.

Работа сайта SitePoint / PatCat, права на логотип: IBM и Raspberry Pi Foundation
Соединение текста с речью в IBM Bluemix
Чтобы получить доступ к службам преобразования текста в речь IBM Watson, нам нужно добавить службу «Text to Speech» в Bluemix. Давайте перейдем на страницу «Службы Bluemix» и найдем услугу «Текст в речь» (будьте осторожны, не выбирайте «Речь в текст»… это другое!).
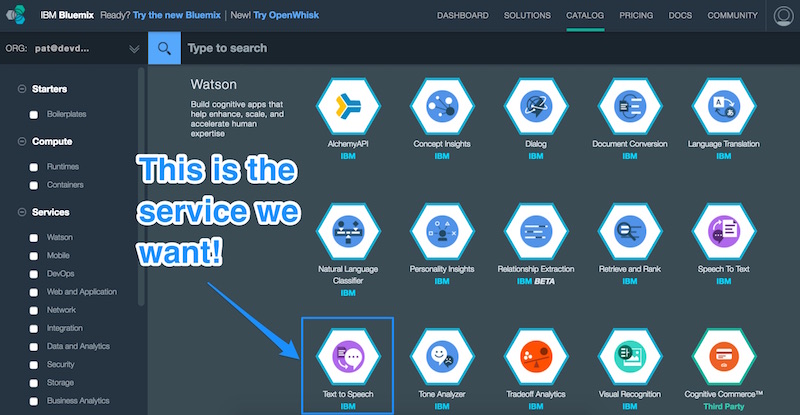
Это должно привести нас на страницу Bluemix сервиса Text to Speech .
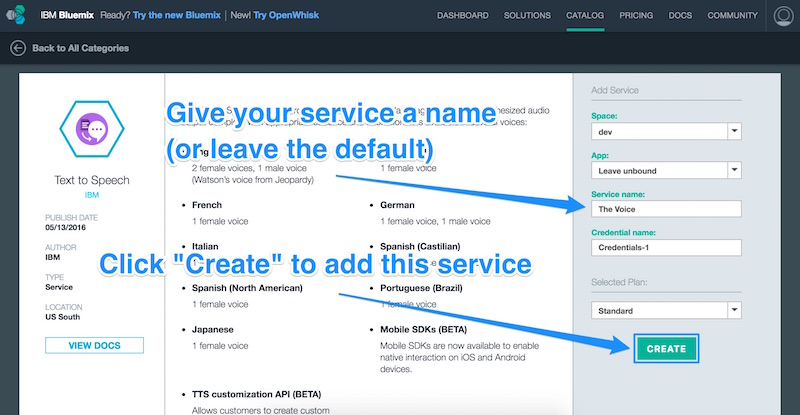
На этой странице мы увидим различные варианты добавления этого сервиса в наш арсенал IBM Bluemix. Мы уверены, что наше пространство, которое мы используем для нашего Raspberry Pi, выбрано (я назвал мой «Dev» в предыдущей статье) и оставляем приложение свободным. Мы можем дать службе имя (я назвал мой «Голос») и присвоить учетным данным имя (я оставил его как есть). Единственный доступный мне план был «Стандартный», поэтому я оставил его как есть. Как только мы довольны нашими настройками, мы нажимаем «Создать».
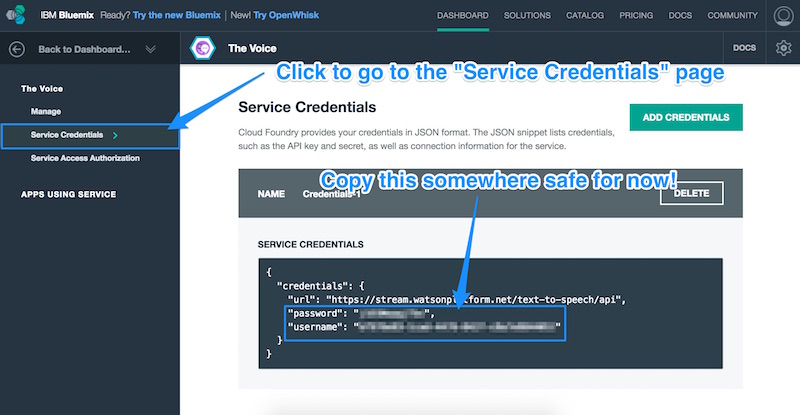
Как только сервис будет создан в нашем пространстве, мы перейдем на страницу этого сервиса. Мы щелкаем пункт меню «Учетные данные службы» слева, чтобы получить доступ к имени пользователя и паролю, которые нам понадобятся для предоставления Node-RED, чтобы получить доступ к нашей новой службе преобразования текста в речь IBM Watson. Скопируйте имя пользователя и пароль с этой страницы:
Добавление новых сервисов IBM Watson в Node-RED
Чтобы получить доступ к службе IBM Watson Text to Speech в Node-RED, нам потребуется установить несколько новых узлов. Для этого мы подключаем SSH к нашему Pi (или открываем терминал непосредственно из нашего Pi) и вводим:
cd ~/.node-redЭто приводит нас к папке приложения Node-RED. Отсюда мы устанавливаем новую коллекцию узлов Node-RED, которая называется node-red-node-watson . Это включает в себя доступ ко всему спектру услуг IBM Watson, включая текст в речь, который нам нужен. Чтобы установить его, мы запускаем следующую команду на нашем Pi из папки Node-RED:
sudo npm install node-red-node-watson
Установка библиотеки ALSA Dev
Функциональность IBM Watson Text to Speech преобразует текст нашего приложения Node-RED в голосовые аудиофайлы, но нам также нужен способ заставить Pi воспроизводить эти файлы — иначе эти слова никогда не будут услышаны! Чтобы это работало на вашем Pi, вам может потребоваться выполнить следующую команду для установки библиотеки dev ALSA:
sudo apt-get install libasound2-dev
Перезапуск Node-RED
Чтобы новые изменения узла Node-RED вступили в силу, нам нужно перезапустить Node-RED. Для этого мы запускаем следующие две команды:
node-red-stop
node-red-start
Наш новый Node-RED Flow
Теперь у нас есть все части, чтобы можно было выполнять преобразование текста в речь и воспроизводить его — теперь пришло время поместить их в Node-RED и запустить его.
Когда мы открываем Node-RED после установки пакета node-red-node-watson и перезапуска, мы увидим несколько новых узлов в разделе «IBM_Watson» с левой стороны:
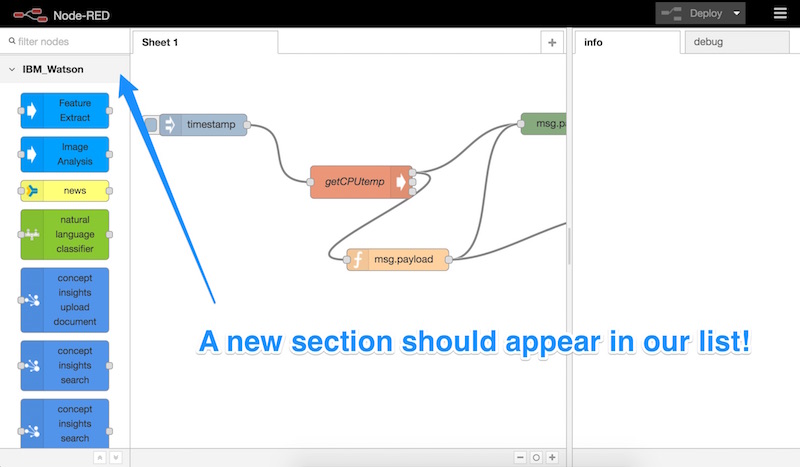
Давайте прокрутим вниз, найдем узел «text to speech» и перетащим его на наш Node-RED лист:
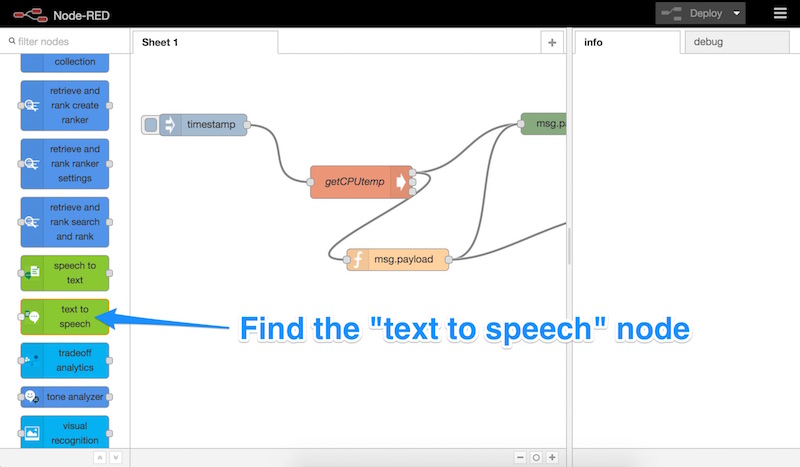
Как только он появится на нашем листе, мы дважды щелкнем по нему, чтобы открыть его настройки:
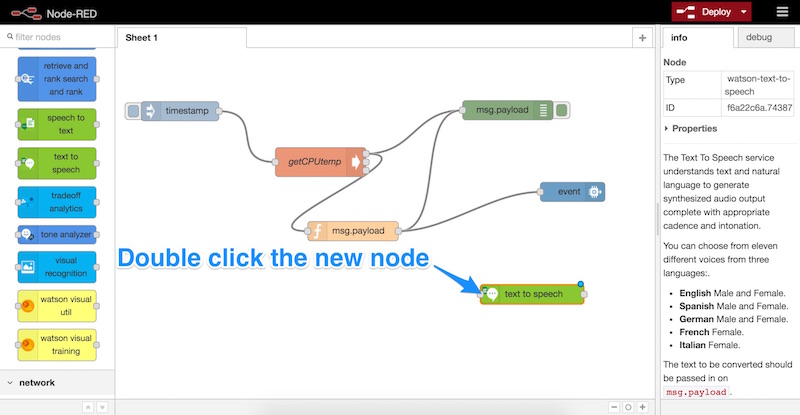
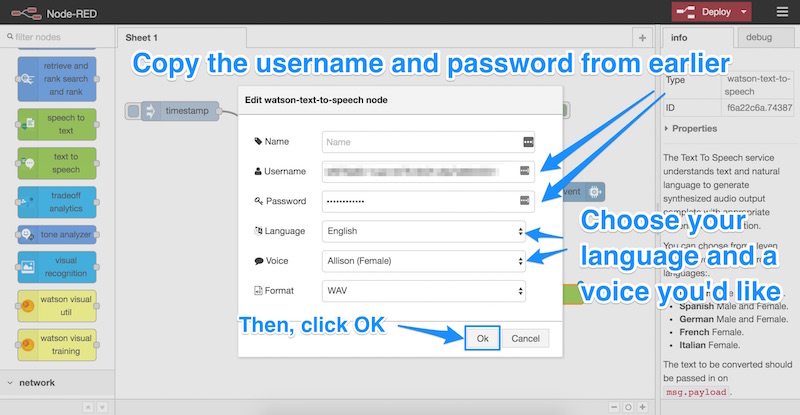
Это раздел, в который мы добавляем наши учетные данные, которые мы скопировали ранее из IBM Bluemix (имя пользователя и пароль). Мы вставляем их сюда и выбираем язык и голос для голоса нашего Пи. Мы оставляем формат файла как «WAV», затем нажимаем «ОК»:
Наш текст в речь готов работать свое волшебство. Теперь нам нужен способ сказать, что сказать. Давайте расскажем, какова температура нашего Pi, как мы ранее отправляли в систему IBM Bluemix в прошлой статье.
Для начала мы перетащим новый функциональный узел на наш лист:
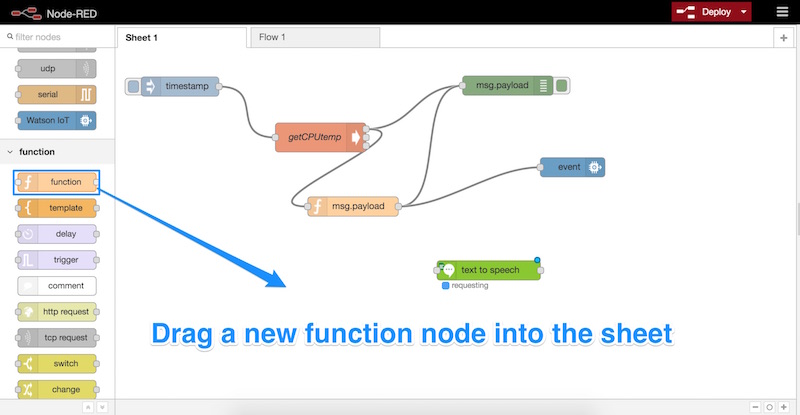
Дважды щелкните этот новый узел и введите следующий код для его функции:
msg.payload = "My current CPU temperature is " +
msg.payload.replace("temp=","").replace("'C\n","") +
" degrees celsius";
return msg;
Эта функция работает для форматирования нашего сообщения так же, как мы использовали в предыдущей статье, однако вместо того, чтобы форматировать его в строку JSON, мы форматируем его в удобочитаемое предложение. В предложении будет сказано: «Моя текущая температура процессора составляет X градусов Цельсия». Мы сохраняем это предложение в переменной msg.payload Мы также можем присвоить узлу функции метку, которую я назвал «Температурный текст»:
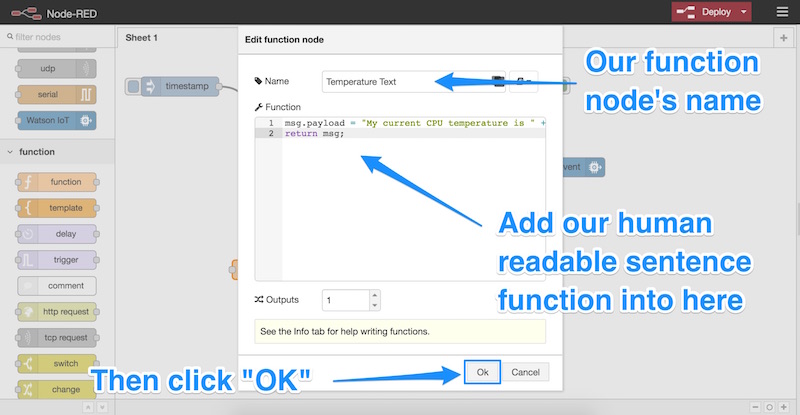
Мы связываем вывод нашего узла getCPUTemp со входом для нового функционального узла:
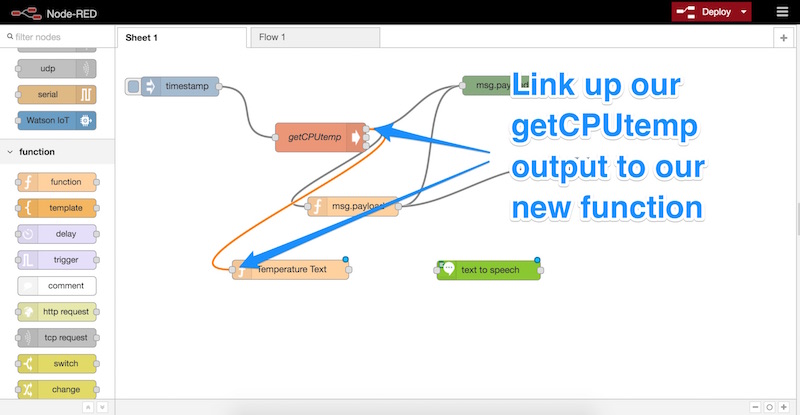
Далее следует связать вывод нашего функционального узла со входом нашего узла Text to Speech:
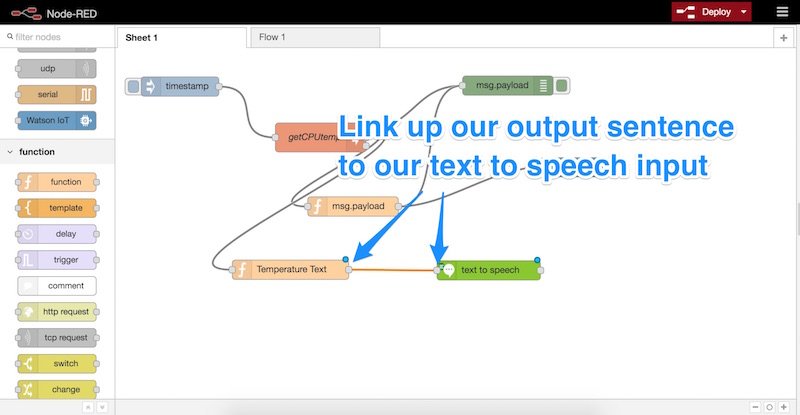
Затем мы добавляем еще один функциональный узел на наш лист. Внутри этого узла мы настроили простую функцию, которая установит для переменной msg.speechmsg.payload
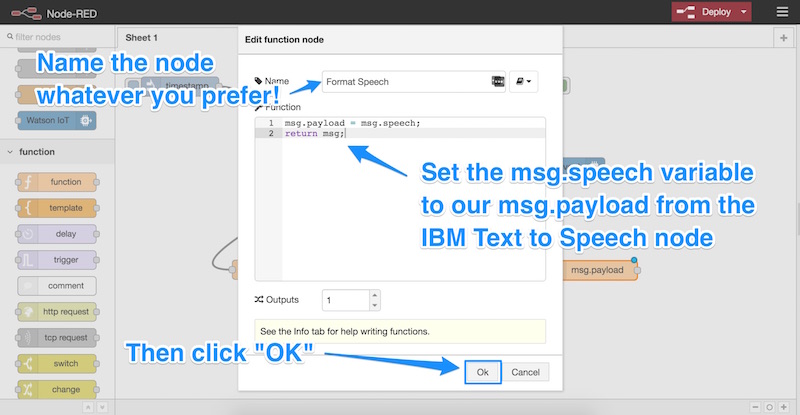
msg.payload = msg.speech;
return msg;
Не стесняйтесь называть этот узел как хотите, я назвал его «Форматировать речь». Затем нажмите «ОК»:
Хранение и получение нашего звукового файла
Теперь у нас есть звуковой буфер, который сгенерирован и готов к хранению где-то, чтобы мы могли его воспроизвести. Чтобы сохранить его в файле, мы используем узел «file», который находится под заголовком «storage». Перетащите тот без вывода на свой лист:
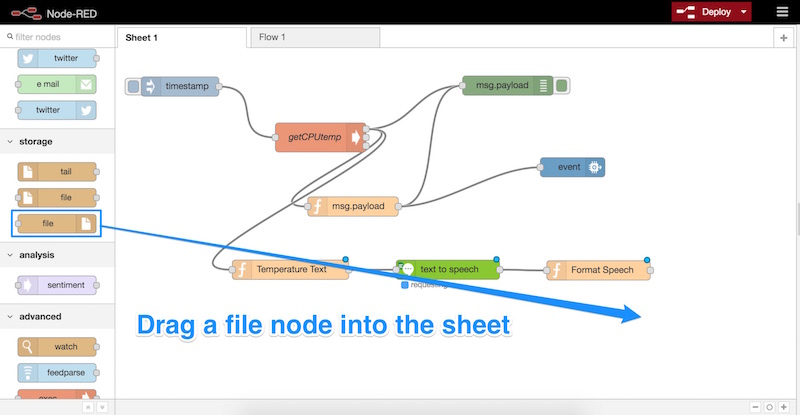
Мы дважды щелкаем по этому новому узлу и вводим следующие настройки:
- Мы устанавливаем имя файла в
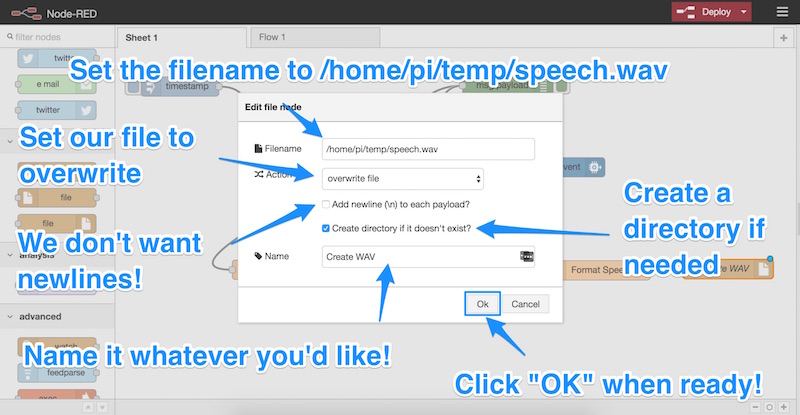
/home/pi/temp/speech.wavpi — это имя пользователя, на котором в данный момент работает Node-RED). - Действие должно быть «перезаписать файл».
- Мы гарантируем, что «Добавить новую строку (\ n) для каждой полезной нагрузки?» Не отмечен.
- Необходимо проверить «Создать каталог, если он не существует», чтобы при необходимости Node-RED мог создать каталог для файла.
- Мы называем наш узел — назовите его как хотите! Я назвал мой «Создать WAV».
- Нажмите «ОК»!
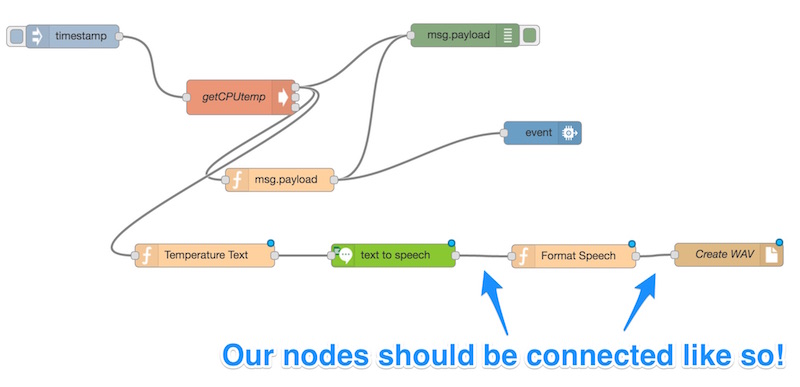
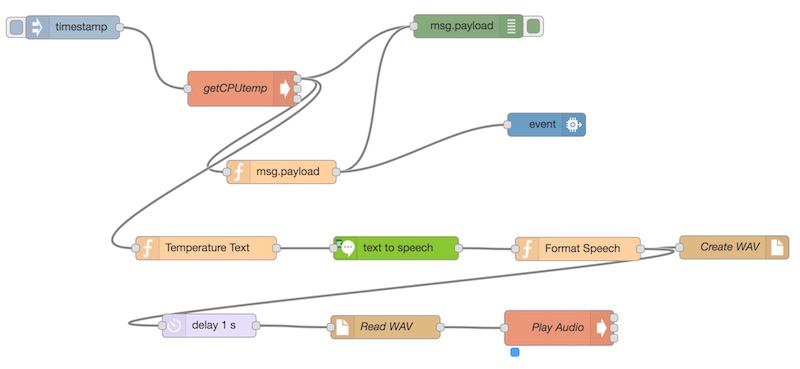
Это создало простой поток, который будет генерировать для нас WAV-файл каждый раз, когда IBM Watson переводит какой-то текст для нас. Убедитесь, что вы подключили каждый из узлов следующим образом:
Воспроизведение звука
Прежде чем пытаться запустить это приложение, нам нужно настроить частоту его запуска. Чтобы сделать это, мы дважды щелкаем наш узел «timestamp»:
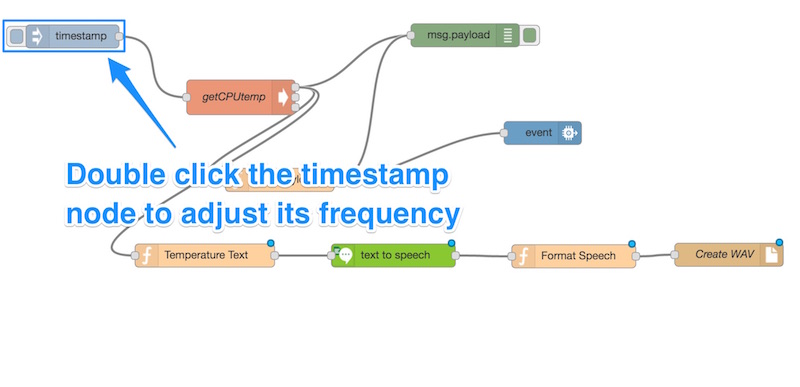
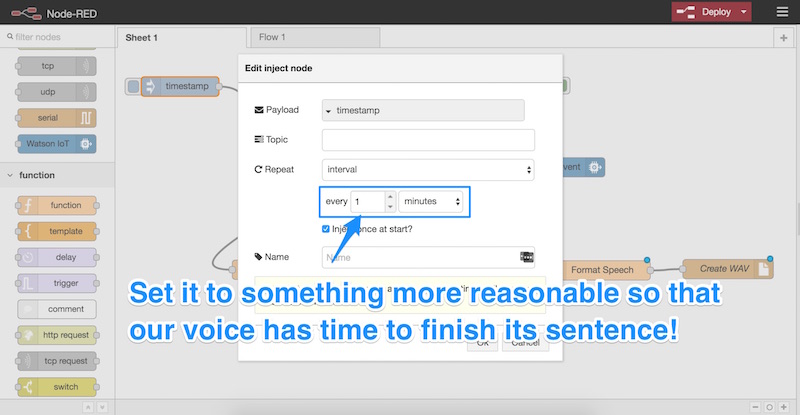
Давайте установим частоту на что-то более разумное — помните, что голосу IBM Watson нужно время, чтобы на самом деле каждый раз высказывать свое мнение! Кроме того, обратите внимание, что IBM будет взимать плату за услугу, если она превышает миллион символов в месяц, поэтому вы не хотите злоупотреблять этим — особенно если вы запрашиваете его так часто, что голос никогда не услышат! Один минутный интервал работал хорошо для меня:
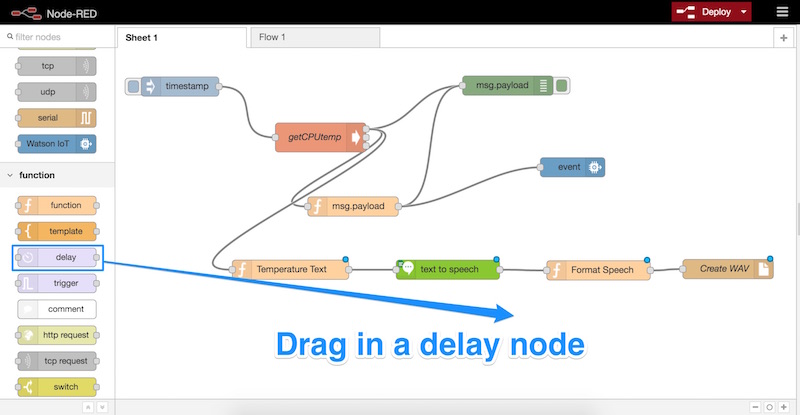
Теперь мы перетаскиваем узел «задержки». Это немного подождет, пока IBM Watson успеет выполнить текст в речь, прежде чем мы попробуем воспроизвести его. Существуют способы запуска узлов в Node-RED при обновлении звукового файла, но я иногда обнаруживаю, что они немного глючат — кажется, что простая задержка работает лучше всего.
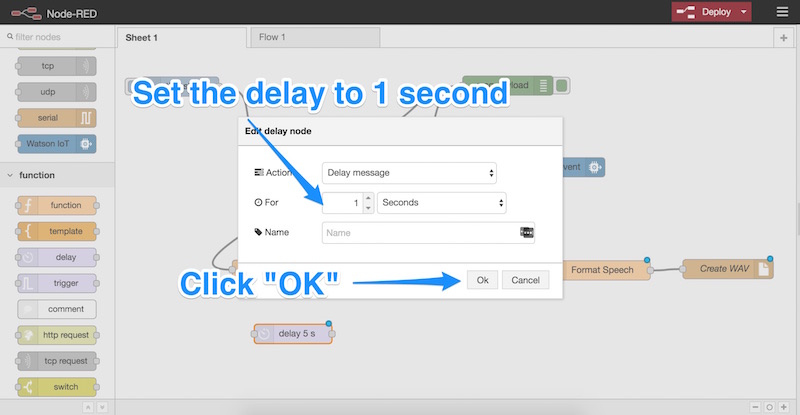
Дважды щелкните узел, чтобы открыть его настройки, измените задержку на 1 секунду и нажмите «ОК»:
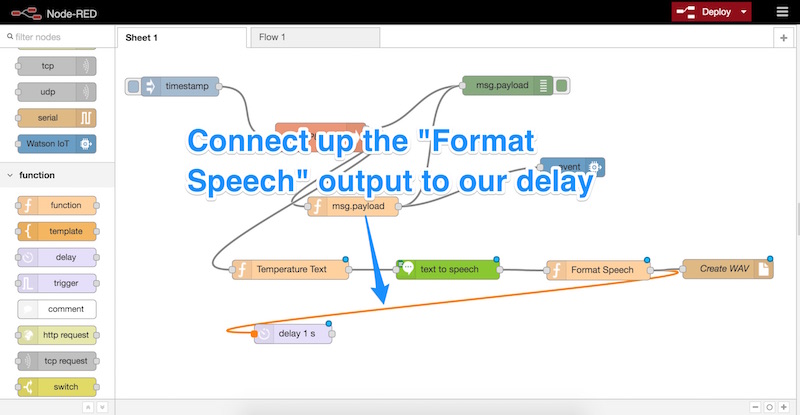
Мы подключаем вывод «Format Speech» (или как вы назвали функцию) к нашей задержке следующим образом:
Затем мы перетаскиваем новый узел — узел чтения файла. Он будет выше узла «файл», который мы перетащили ранее, но у него есть и вход, и выход:
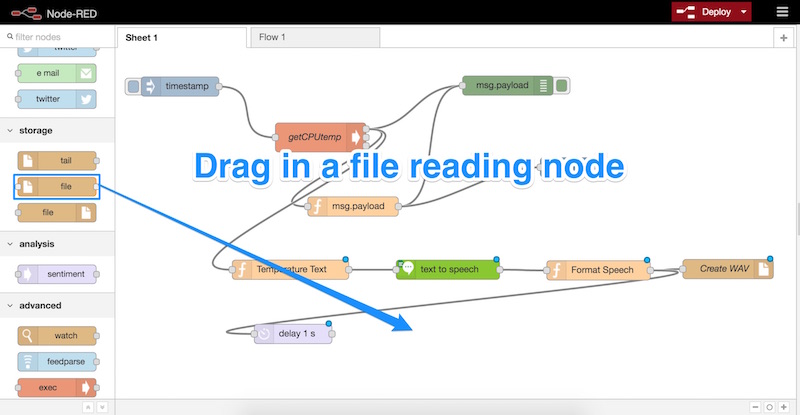
Дважды щелкните этот новый узел и введите следующие параметры:
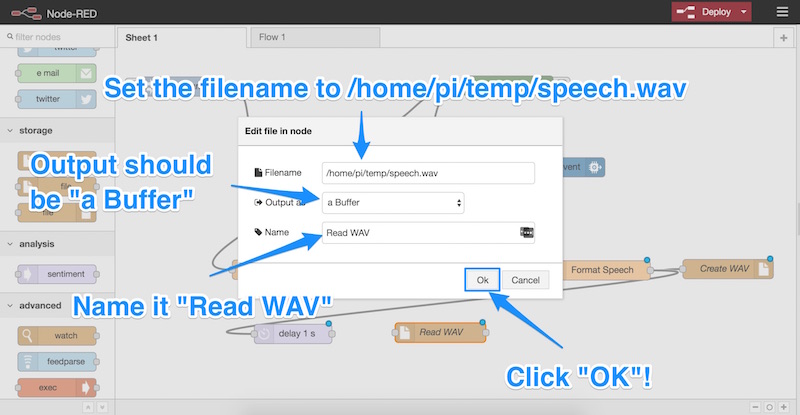
- Мы устанавливаем имя файла
/home/pi/temp/speech.wav - Мы гарантируем, что на выходе будет «буфер».
- Мы даем ему имя «Читать WAV» (это может быть как угодно, как вы бы это называли).
- Нажмите ОК!
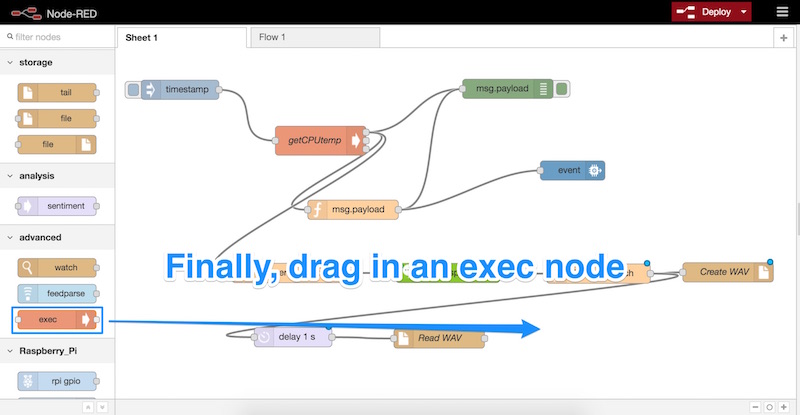
Мы подключаем наш узел задержки к узлу «Read WAV», а затем перетаскиваем наш последний узел — узел «exec». Этот раздел находится в разделе «Дополнительно» и может запускать команды Unix. Вот как мы будем проигрывать наше аудио на Пи.
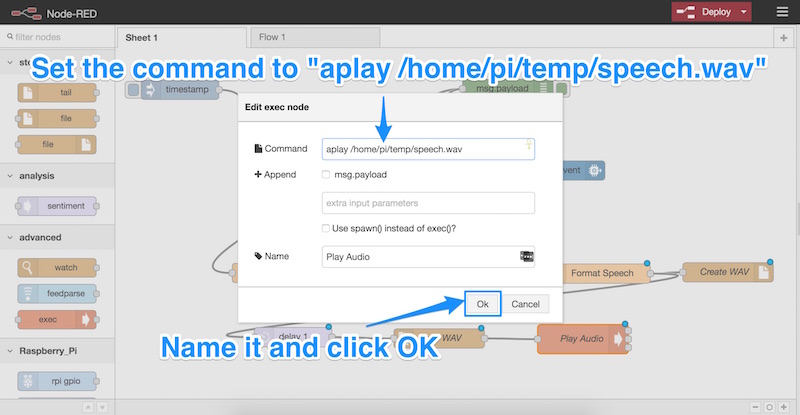
Мы дважды щелкаем по этому новому узлу, чтобы изменить его настройки. Мы устанавливаем команду для:
aplay /home/pi/temp/speech.wav
Это играет звуковой файл на нашем Pi! Нам не нужны переключатели или что-то еще, мы просто называем узел (я назвал мой «Play Audio») и нажимаем OK:
В бою
С этим у нас есть все части на месте, чтобы это работало:
Одна из настроек, которую вам, возможно, придется изменить на вашем Pi, — это то, где он настроен для вывода звука. Я использовал следующую команду для направления звука на разъем 3,5 мм:
amixer cset numid=3 1
Вы можете узнать больше об изменении настроек звука вашего Raspberry Pi на странице настроек аудио Raspberry Pi .
Когда звук настроен правильно и все на месте, нажмите кнопку «Развернуть» в правом верхнем углу интерфейса Node-RED. Если все идет по плану, он должен успешно работать, и ваш Raspberry Pi должен начать говорить с вами!
Ниже я разместил видео в Твиттере, где мой Raspberry Pi говорил со мной через чашку Starbucks:
(Как я это сделал, спросите вы? Я использовал волшебное устройство, которое называется Boombox Portable Vibration Speaker !)
Вывод
Возможности преобразования текста в речь IBM Watson предоставляют разработчикам, работающим с IBM Bluemix и Raspberry Pi, совершенно новый набор возможностей! Вы можете подключить речь практически ко всему, включая другие сервисы IBM Watson. Мы продолжим исследовать больше возможностей в следующей статье этой серии, спасибо тем, кто в настоящее время подписался!
Если бы вы попробовали комбинацию Raspberry Pi и IBM Bluemix, я бы хотел услышать, что вы с ней делаете! Дайте мне знать в комментариях ниже или свяжитесь со мной в Твиттере по адресу @thatpatrickguy .