В 2012 году инженер Facebook Ник Шрок начал работу над небольшим прототипом, чтобы облегчить переход от старого, неподдерживаемого партнерского API, который послужил основой для текущей ленты новостей Facebook. В то время это называлось «SuperGraph». Перенесемся в будущее, и SuperGraph помог сформировать язык запросов с открытым исходным кодом GraphQL, который в последнее время стал популярным.
Facebook описывает GraphQL как «язык запросов для API и среду выполнения для выполнения этих запросов с вашими существующими данными». Проще говоря, GraphQL является альтернативой REST, которая неуклонно набирает популярность с момента ее выпуска. В то время как с REST разработчик обычно собирал данные из серии запросов конечных точек, GraphQL позволяет разработчику отправлять на сервер один запрос, который описывает точные требования к данным.
Хотите узнать React Native с нуля? Эта статья является выдержкой из нашей Премиум библиотеки. Получите полную коллекцию книг React Native, охватывающую основы, проекты, советы и инструменты и многое другое с SitePoint Premium. Присоединяйтесь сейчас всего за $ 9 / месяц .
Предпосылки
Для этого урока вам понадобятся базовые знания о React Native и некоторое знакомство с окружением Expo . Вам также понадобится клиент Expo, установленный на вашем мобильном устройстве, или совместимый симулятор, установленный на вашем компьютере. Инструкции о том, как это сделать, можно найти здесь .
Обзор проекта
В этом уроке мы собираемся продемонстрировать всю мощь GraphQL в настройках React Native, создав простое приложение для сравнения кофейных зерен. Чтобы вы могли сосредоточиться на всех замечательных возможностях GraphQL, я собрал базовый шаблон для приложения с помощью Expo.
Чтобы начать, вы можете клонировать этот репозиторий и перейти к ветви «Getting-Start», которая включает в себя все наши основные представления, чтобы начать добавлять наши данные GraphQL, а также все наши начальные зависимости, которые на этом этапе:
{ "expo": "^32.0.0", "react": "16.5.0", "react-native": "https://github.com/expo/react-native/archive/sdk-32.0.0.tar.gz", "react-navigation": "^3.6.1" } Чтобы клонировать эту ветку, вам нужно открыть терминал и запустить эту команду:
git clone https://github.com/jamiemaison/graphql-coffee-comparison.git
Чтобы затем перейти к ветке « getting-started , вы переходите во вновь клонированное cd graphql-coffee-comparison с помощью cd graphql-coffee-comparison и запускаете запуск git checkout getting-started .
Следующим этапом является установка наших зависимостей. Для этого убедитесь, что вы находитесь на Node v11.10.1 и запустите npm install в корневом каталоге проекта. Это добавит все перечисленные выше зависимости в вашу папку node_modules .
Чтобы начать добавлять GraphQL в наше приложение React Native, нам нужно установить еще несколько зависимостей, которые помогут нам выполнить несколько простых функций GraphQL. Как и в случае современной разработки JavaScript, вам не нужны все эти зависимости для выполнения запроса данных, но они, безусловно, помогают дать разработчику больше шансов структурировать некоторый чистый, легко читаемый код. npm install --save apollo-boost react-apollo graphql-tag graphql зависимости можно установить, запустив npm install --save apollo-boost react-apollo graphql-tag graphql .
Вот обзор этих зависимостей:
-
apollo-boost: способ нулевой конфигурации, чтобы начать работу с GraphQL в React / React Native -
react-apollo: это обеспечивает интеграцию между GraphQL и клиентом Apollo -
graphql-tag: шаблонный литеральный тег, который анализирует запросы GraphQL -
graphql: эталонная реализация JavaScript для GraphQL
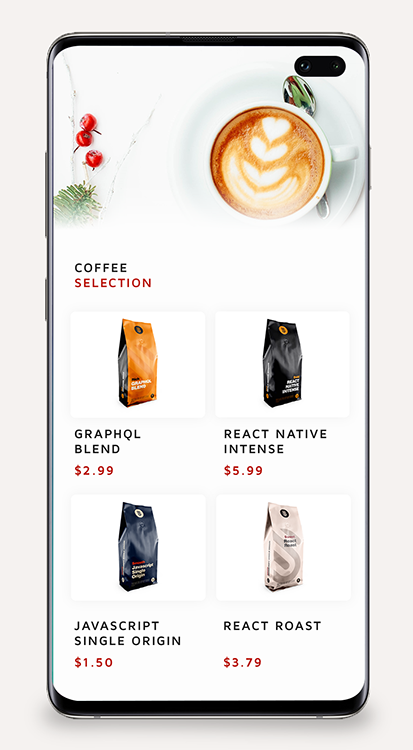
Как только все необходимые зависимости закончат установку, запустите npm start . Теперь вы должны увидеть знакомое окно Expo, и если вы запустите приложение (через симулятор или на устройстве), то вы должны увидеть экран, подобный следующему:
В общих чертах, это приложение имеет два экрана, которые управляются react-navigation , Home.js и CoffeePage.js . Главный экран содержит простой FlatList который отображает все кофейные зерна, предоставленные в его поле data . При нажатии пользователь переходит на CoffeePage для этого элемента, который отображает дополнительную информацию о продукте. Теперь наша задача — заполнить эти представления интересными данными из GraphQL.
Аполлон сервер игровая площадка
В любой успешной транзакции GraphQL есть два основных элемента: сервер, содержащий данные, и внешний запрос, выполняющий запрос. Для целей данного руководства мы не собираемся углубляться в удивительный мир серверного кода, поэтому я создал наш сервер, готовый к работе. Все, что вам нужно сделать, это перейти к yq42lj36m9.sse.codesandbox.io в вашем любимом браузере и оставить его включенным на протяжении всего процесса разработки. Для тех, кто заинтересован, сам сервер работает с использованием apollo-server и содержит достаточно кода для хранения необходимых нам данных и их обслуживания при получении соответствующего запроса. Для дальнейшего чтения вы можете зайти на apollographql.com, чтобы узнать больше об apollo-server .
GraphQL Query Basics
Прежде чем мы начнем писать реальный код, который будет запрашивать данные, которые нам нужны для нашего приложения для сравнения кофейных зерен, мы должны понять, как работают запросы GraphQL. Если вы уже знаете, как работают запросы, или просто хотите начать работу с кодированием, вы можете перейти к следующему разделу.
Примечание: эти запросы не будут работать с нашим сервером codeandbox , но вы можете создать свой собственный на codesandbox.io, если вы хотите проверить запросы.
На простейшем уровне мы можем использовать плоскую структуру для наших запросов, когда знаем форму запрашиваемых данных:
QUERY: RESPONSE: { { coffee { "coffee": { blend "blend": "rich" } } } }
Слева мы видим запрос GraphQL, запрашивающий поле blend у coffee . Это хорошо работает, когда мы точно знаем, какова наша структура данных, но что делать, когда вещи менее прозрачны? В этом примере blend возвращает нам строку, но запросы также могут использоваться для запроса объектов:
QUERY: RESPONSE: { { coffee { "coffee": { beans { "beans": [ blend { } blend: "rich" } }, } { blend: "smooth" } ] } }
Здесь вы можете видеть, что мы просто запрашиваем объект beans , а из этого объекта возвращается только blend полей. Каждый объект в массиве beans может очень хорошо содержать другие данные, кроме blend , но запросы GraphQL помогают нам запрашивать только те данные, которые нам нужны, исключая любую дополнительную информацию, которая не нужна нашему приложению.
Так что, когда нам нужно быть более конкретным, чем это? GraphQL предоставляет возможность для многих вещей, но кое-что, что допускает чрезвычайно мощные запросы данных, — это возможность передавать аргументы в вашем запросе. Возьмите следующий пример:
QUERY: RESPONSE: { { coffee(companyId: "2") { "coffee": { beans { "beans": [ blend { } blend: "rich" } }, } { blend: "smooth" } ] } }
Мы видим, что мы можем передать аргумент — в данном случае, companyId — который гарантирует, что мы возвращаем beans только от одной конкретной компании. С помощью REST вы можете передавать один набор аргументов через параметры запроса и сегменты URL, но с помощью GraphQL, запрашивающего каждое отдельное поле, он может получить свой собственный набор аргументов. Это позволяет GraphQL быть динамическим решением для нескольких выборок API за запрос.
Псевдонимы
До сих пор во всех наших запросах поля возвращаемого объекта совпадали с именем поля в самом запросе. Это замечательно при использовании простых аргументов, но что если вы хотите запросить одно и то же поле с разными аргументами в запросе данных? Вот где появляются псевдонимы. Псевдонимы позволяют вам изменить имя поля, чтобы вы могли переименовать любые возвращаемые данные и, следовательно, использовать разные аргументы в вашем запросе данных. Возьмите наш пример с кофейными зернами. Что если мы хотим вернуть данные из двух разных идентификаторов компании? Мы бы структурировали наш запрос следующим образом:
QUERY: RESPONSE: { { company1: coffee(companyId: "1") { "company1": { beans { "beans": [ blend { } "blend": "rich" } } company2: coffee(companyId: "2") { ] beans { }, blend "company2": { } "beans": [ } { } "blend": "fruity" } ] } }
Здесь мы запрашиваем данные для псевдонимов company1 и company2 , которые представляют собой просто разные запросы coffee накладываемые друг на друга. Псевдонимы могут быть мощным инструментом для изменения ваших требований в соответствии с вашими требованиями к данным.
переменные
До сих пор мы знали наш точный запрос и поэтому могли жестко закодировать его в нашем приложении, но большинству приложений эти поля должны быть динамическими. Например, пользователь может выбрать компанию кофейных зерен из списка для отображения. Мы не будем заранее знать, какую компанию по производству кофейных зерен выбирает пользователь, поэтому нам нужен способ выполнить эти требования. Это где переменные входят.
Документация GraphQL перечисляет три вещи, которые нам нужно сделать, чтобы использовать переменные:
- замените статическое значение в запросе на
$variableName - объявите
$variableNameкачестве одной из переменных, принятых запросом - передать
variableName: valueв отдельном словаре переменных, специфичных для транспорта (обычно JSON)
В практическом плане это означает, что наш запрос данных будет выглядеть примерно так:
query coffeeCompany(companyId: CompanyId) { coffee(companyId: companyId) { beans: { type } } }
Мы также companyId бы companyId как объект JSON:
{ "companyId": "1" }
Использование переменных в GraphQL — это мощный способ сделать все наши запросы динамическими, поскольку мы запрашиваем только те данные, которые нам нужны в данный момент.
Запрос кофе
Для целей нашего приложения нам понадобится запрос, который позволяет нам запрашивать данные, извлекающие только наши кофейные зерна, в то же время включая все соответствующие поля, которые нам понадобятся. Наши требования к данным не так сложны, поэтому они будут выглядеть примерно так:
{ coffee { beans { key name price blend color productImage } } }
Запрос наших данных
Теперь для фактического кода, который мы собираемся использовать для запроса наших данных. Откройте App.js , который является контейнером для всех наших представлений и будет хорошим местом для запроса данных при запуске приложения.
Мы хотим инициализировать наш клиент, что мы можем просто сделать, импортировав ApolloClient из apollo-boost и указав URL нашего сервера. Важно отметить, что вам нужно инициализировать сервер, что достигается простым запуском yq42lj36m9.sse.codesandbox.io в вашем браузере. Иногда вы можете обнаружить тайм-аут сервера. Если Expo возвращает предупреждение, напоминающее «ошибка сети», перезагрузите yq42lj36m9.sse.codesandbox.io в браузере, чтобы повторно инициализировать сервер.
После запуска сервера добавьте импорт и инициализацию в начало App.js , который должен выглядеть примерно так:
// ./App.js import ApolloClient from 'apollo-boost'; const client = new ApolloClient({ uri: 'https://yq42lj36m9.sse.codesandbox.io/' })
Далее мы хотим собрать запрос graphQL для последующего использования при запросе наших данных. К счастью, библиотека graphql-tag делает это простым. Опять же, нам нужно импортировать саму библиотеку в App.js :
// ./App.js import gql from 'graphql-tag';
Теперь мы можем структурировать запрос:
// ./App.js const QUERY = gql` { coffee { beans { key name price blend color productImage } } } `
Следующим шагом является изменение функции рендеринга для включения нашего запроса данных. Для этого мы используем библиотеку react-apollo чтобы сделать запрос, который позволяет нам обрабатывать ответ по своему усмотрению. Добавьте новый импорт в App.js :
// ./App.js import { ApolloProvider, Query } from 'react-apollo';
Затем измените функцию рендеринга, чтобы она теперь выглядела так:
// ./App.js render() { return ( <ApolloProvider client={client}> <Query query={QUERY} > {({ loading, error, data }) => { if (loading || error) return <View /> return <View style={{ flex: 1 }}> {this.state.isFontsLoaded ? <AppContainer /> : <View />} </View> }} </Query> </ApolloProvider> ); }
Здесь вы можете видеть, что мы используем запрос, который мы создали ранее, чтобы запросить необходимые данные. В данный момент мы просто визуализируем пустое представление во время загрузки, и если в запросе данных есть ошибка. На практике это будет заменено для соответствующих представлений загрузки и ошибок, но для этого примера мы оставим их пустыми. Как только данные возвращаются, мы рендерим наш AppContainer как обычно. Вы можете проверить, поступают ли данные, проверив, что data возвращаются успешно. Это можно проверить, добавив console.log(data) в ваш код, чтобы просмотреть вывод в вашем терминале. Вы должны получать объект с нашими полями coffee и beans если ваш сервер Apollo работает без проблем.
Хранение данных с помощью API контекста
Нам понадобится где-то хранить наши данные, которые будут доступны в любом из наших компонентов, независимо от того, как далеко они находятся в дереве. Если бы нам нужно было передать данные через несколько детей только для того, чтобы добраться до нашего компонента, это было бы не самой эффективной вещью. Учитывая, что наши потребности в хранении данных довольно просты для этого примера, было бы хорошо использовать React’s Context API, а не какой-нибудь более сложный инструмент управления состоянием, такой как Redux. Context API позволяет передавать глобальное состояние по нашему дереву компонентов без необходимости каждый раз пропускать его через реквизиты, и для нашего текущего примера этого достаточно.
Преимущества Redux поверх Context API можно в целом сузить до трех пунктов:
- Redux поставляется с отладчиком путешествий во времени
- он предоставляет разработчику API промежуточного программного обеспечения, предоставляя вам доступ к таким инструментам, как
redux-sagas - его привязки React предотвращают слишком много рендеров
Использование Context API не может быть проще. По сути, нам просто нужно создать компонент <Provider /> для хранения всех наших данных и доступа к ним путем создания компонента <Consumer /> когда он нам понадобится.
Создание провайдера
Давайте вернемся к App.js , где нам нужно всего лишь добавить пару строк, чтобы наш Provider заработал. Сначала мы начнем с создания нашего AppContext . Нам понадобится доступ к этому в любом файле, где мы хотим использовать сохраненные данные, поэтому нам нужно убедиться, что они экспортированы. Чтобы создать AppContext , добавьте следующую строку в App.js :
// ./App.js export const AppContext = React.createContext({ data: { coffee: { beans: [] } } });
Здесь мы создаем контекст и инициализируем его пустыми данными. Далее мы хотим заполнить AppProvider данными, которые мы получаем от сервера GraphQL.
Хранение данных cCoffee
Чтобы обновить нашего провайдера данными, нам просто нужно изменить пустое представление контейнера в нашей App.js рендеринга App.js для провайдера, добавив при этом наши данные GraphQL к его базе данных. Это выглядит так:
// ./App.js render() { return ( <ApolloProvider client={client}> <Query query={QUERY} > {({ loading, error, data }) => { if (loading || error) return <View /> return <AppContext.Provider value={data.coffee.beans} style={{ flex: 1 }}> {this.state.isFontsLoaded ? <AppContainer /> : <View />} </AppContext.Provider> }} </Query> </ApolloProvider> ); }
Здесь вы можете видеть, что мы напрямую data.coffee.beans данные bean ( data.coffee.beans ) в нашем провайдере. На данный момент у нас есть все необходимые данные, но мы по-прежнему передаем содержимое нашего заполнителя. Последняя часть этой головоломки состоит в том, чтобы изменить Home.js для отображения наших данных с использованием Consumer .
Создание потребителя приложения
Во-первых, нам нужно импортировать наш AppContext из более раннего, чтобы использовать Consumer . Для этого нам просто нужно импортировать его из App.js в Home.js :
// ./src/Home.js import { AppContext } from '../App';
Использование Consumer работает как любой другой компонент React. Для наших текущих целей мы добавим его в нашу функцию render и будем использовать данные для заполнения нашего FlatList . Наша функция рендеринга должна выглядеть примерно так:
// ./src/Home.js render() { return ( <AppContext.Consumer> { (context) => <View style={styles.container}> <Image style={styles.header} source={require('../assets/header.png')} /> <View style={{ marginLeft: 30, marginTop: 30 }}> <Text style={styles.title}>COFFEE</Text> <Text style={styles.subtitle}>SELECTION</Text> </View> <FlatList style={styles.list} data={context} renderItem={({ item }) => <TouchableOpacity style={styles.block} onPress={() => this.props.navigation.navigate('CoffeePage', { item: item })}> <Image style={styles.productImage} source={{ uri: item.productImage }} /> <Text style={styles.name}>{item.name}</Text> <Text style={styles.price}>{item.price}</Text> </TouchableOpacity>} numColumns={2} /> </View> } </AppContext.Consumer> ); }
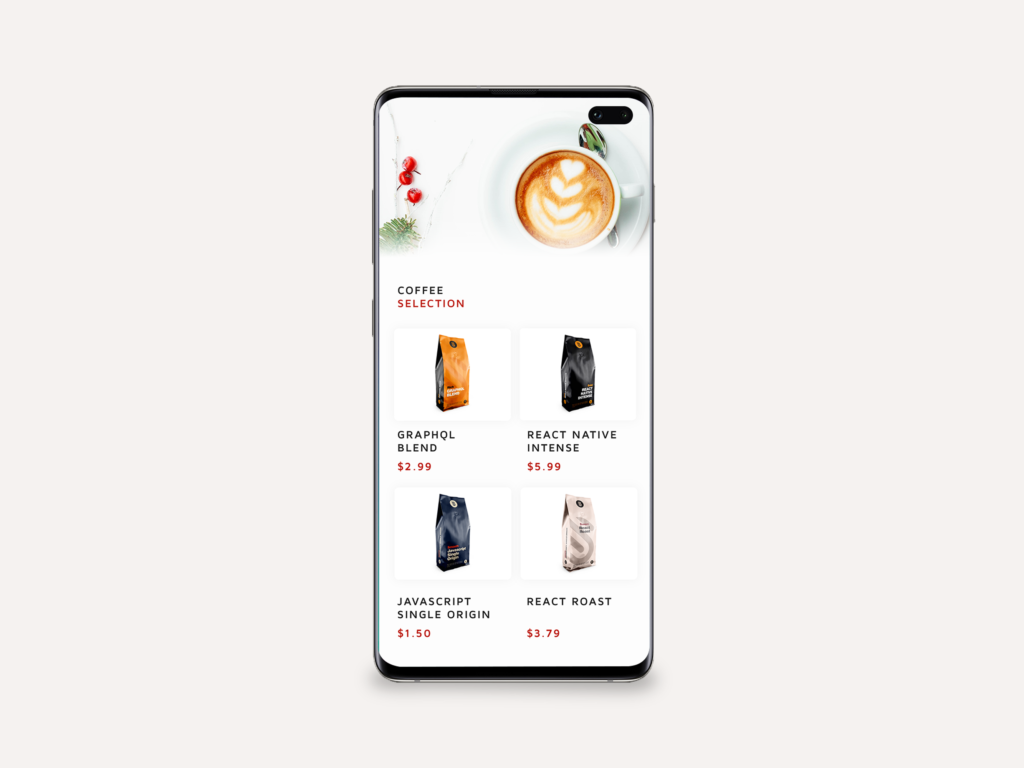
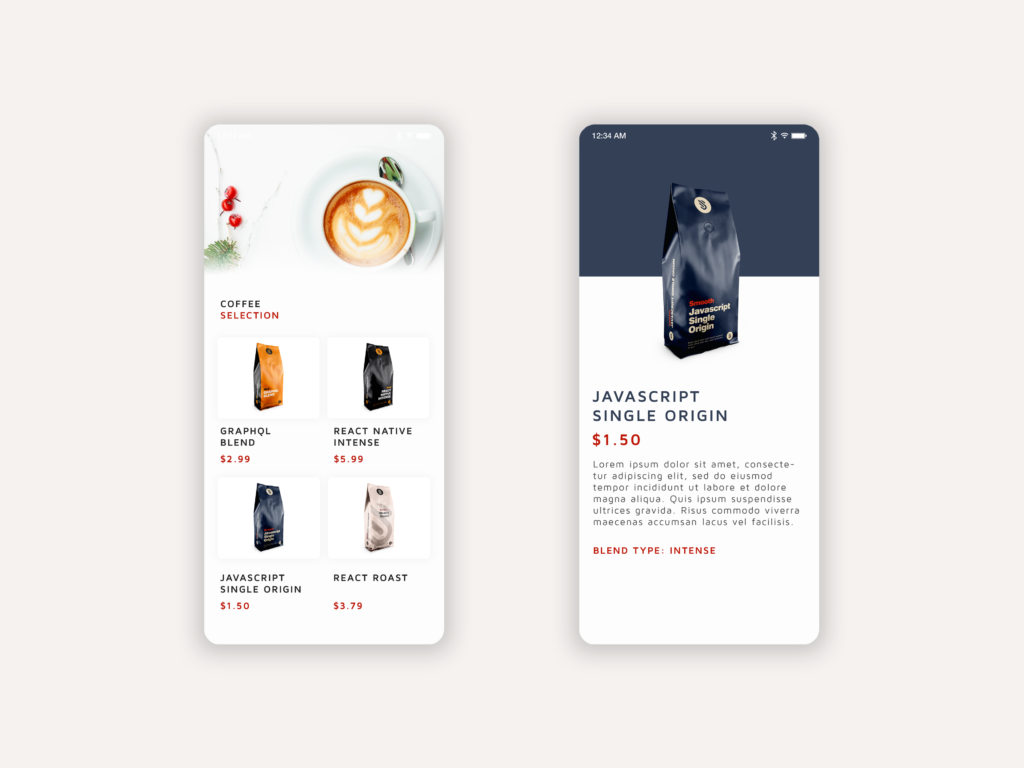
Если мы AppContext.Consumer по приведенному выше коду, вы увидите, что AppContext.Consumer предоставляет нам context , который содержит наши данные GraphQL. Мы используем этот context для заполнения компонента FlatList , передав его в реквизит data . Когда пользователь нажимает на один из элементов кофе, наши данные передаются через параметры навигации в наш CoffeePage.js , что позволяет получить к ним доступ в этом представлении. Если вы сейчас сохраните свои измененные файлы и запустите приложение на Expo, вы должны увидеть свой полностью заполненный FlatList .
Резюме
Поздравляем! Вы успешно использовали GraphQL для извлечения данных и рендеринга этих данных с помощью React Native. Мы узнали, насколько мощными могут быть запросы к GraphQL, и продемонстрировали преимущества по сравнению с такой системой, как REST. Я рекомендую вам использовать GraphQL в вашем следующем проекте и самим судить, насколько быстрее это может быть для извлечения данных, особенно в приложениях с большим количеством данных.
Если вы хотите изучить GraphQL более подробно, я рекомендую вам прочитать раздел « Запросы и мутации » документации GraphQL и, возможно, начать самостоятельно программировать сервер Apollo с использованием codesandbox.io .
Весь код этого проекта можно найти на GitHub , так что не стесняйтесь клонировать / раскладывать репозиторий и вносить свои собственные улучшения!