
Одним из наиболее важных понятий в DOM является обход дерева. С тех пор, как информатика стала собственной областью исследования, десятилетия исследований были потрачены на структуры данных и алгоритмы. Одна из наиболее часто используемых структур — это дерево. Деревья повсюду. Очень элементарной, но полезной и часто используемой версией является двоичное дерево. Турнир может быть представлен в виде двоичного дерева. Однако дерево DOM не является двоичным. Вместо этого это K-арное дерево. Каждый узел может иметь от нуля до N childNodes , называемых childNodes .
Дерево DOM содержит широкий спектр возможных типов узлов. Среди многих могут быть Text , Element , Comment и другие специальные, такие как ProcessingInstruction или DocumentType . У большинства из них по определению не будет childNodes . Они являются конечными точками и несут только один кусок информации. Например, узел Comment несет только указанную строку комментария. Text узел доступен только для хранения строки содержимого.
Узел Element содержит другие узлы. Мы можем рекурсивно спускаться от элементов к элементам, чтобы пройти через все доступные узлы в системе.
Наглядный пример
Примером, который также относится к предыдущей статье, касающейся элемента <template> является заполнение структуры поддерева DOM. Поддерево является частью дерева, которое начинается с указанного элемента. Мы называем указанный элемент корневым поддеревом. Если мы возьмем элемент <html> дерева в качестве корня поддерева, поддерево будет почти идентично реальному дереву, которое начинается в document , то есть на один уровень ниже documentElement .
Заполнение структуры поддерева требует от нас перебора всех дочерних элементов корня поддерева. На каждом узле нам нужно проверить точный тип узла и затем продолжить соответствующим образом. Например, каждый элемент должен снова рассматриваться как корень поддерева. Текстовые узлы, с другой стороны, должны оцениваться более тщательно. Возможно, мы также хотим проверить узлы комментариев на наличие специальных директив. Кроме того, атрибуты элементов должны быть рассмотрены также.
Для этого сценария мы используем метод applyModel для заполнения шаблонных строк значениями из модели. Метод выглядит следующим образом и, конечно, может быть дополнительно оптимизирован. Тем не менее, для наших целей этого, безусловно, достаточно.
« `функция javascript applyModel (модель, данные) {var rx = new RegExp (‘\ {\ s (. +?) \ s \}’, ‘g’); var group = rx.exec (данные);
while (группа) { var name = group [1]; var value = ''; eval ('with (model) {value =' + name + ';}'); data = data.replace (группа [0], значение); group = rx.exec (данные); } вернуть данные; } `` `
Давайте посмотрим реализацию для описанного сценария, которая использует метод applyModel в различных случаях. Это берет экземпляр элемента template и объект с именем model чтобы вернуть новый DocumentFragment . Новый фрагмент использует данные из модели, чтобы изменить все значения с {X} на результат вычисления выражения X с использованием предоставленного объекта.
« `javascript function iterateClassic (template, model) {var фрагмент = шаблон.content.clone (true); var allNodes = findAllNodes (фрагмент);
allNodes.forEach (changeNode); возвратный фрагмент; } `` `
В предыдущем коде используется функция findAllNodes , которая принимает узел и сохраняет все его дочерние findAllNodes в массиве. Затем функция вызывается рекурсивно для каждого дочернего элемента. В конце все результаты объединяются в один массив всего поддерева, т.е. мы преобразуем древовидную структуру в одномерный массив.
Следующий фрагмент кода показывает пример реализации описанного алгоритма.
« `javascript function findAllNodes (childNodes) {var node = [];
if (childNodes && childNodes.length> 0) { for (var i = 0, length = childNodes.length; i <длина; i ++) { nodes.push (ChildNodes [I]); node = node.concat (findAllNodes (childNodes [i] .childNodes)); } } возвратные узлы; } `` `
Функция для изменения каждого узла в массиве показана ниже. Функция выполняет некоторые манипуляции в зависимости от типа узла. Мы заботимся только об атрибутах и текстовых узлах.
javascript function changeNode (node) { switch (node.nodeType) { case Node.TEXT_NODE: node.text.data = applyModel(model, node.text.data); break; case Node.ELEMENT_NODE: Array.prototype.forEach.call(node.attributes, function (attribute) { attribute.value = applyModel(model, attribute.value); }); break; } }
Хотя код легко понять, он не очень красив. У нас довольно много проблем с производительностью, тем более что у нас много, к сожалению, необходимых операций DOM. Это можно сделать более эффективно с помощью одного из помощников дерева DOM. Обратите внимание, что метод findAllNodes возвращает массив со всеми узлами, а не только со всеми экземплярами Element в поддереве. Если мы заинтересованы в последнем, мы можем просто использовать querySelectorAll('*') , который выполняет итерацию для нас.
Перебор узлов
Решение, которое приходит немедленно, — это использование NodeIterator . NodeIterator выполняет итерации по узлам. Это почти идеально соответствует нашим критериям. Мы можем создать новый NodeIterator , используя метод createNodeIterator объекта document . Есть три важных параметра:
- Корневой узел поддерева для итерации.
- Фильтры, какие узлы выбирать / перебирать.
- Объект с
acceptNodeдля пользовательской фильтрации.
В то время как первый аргумент является простым узлом DOM, два других используют специальные константы. Например, если должны быть показаны все узлы, мы должны передать -1 в качестве фильтра. В качестве альтернативы мы можем использовать NodeFilter.SHOW_ALL . Мы могли бы объединить несколько фильтров несколькими способами. Например, комбинация отображения всех комментариев и всех элементов может быть выражена с помощью NodeFilter.SHOW_COMMENT | NodeFilter.SHOW_ELEMENT NodeFilter.SHOW_COMMENT | NodeFilter.SHOW_ELEMENT .
Третий аргумент — это объект, который может выглядеть так же примитивно, как и следующий фрагмент кода. Хотя объект, обертывающий функцию, кажется избыточным, он был указан таким образом. Некоторые браузеры, например Mozilla Firefox, дают нам возможность сводить объект к одной функции.
javascript var acceptAllNodes = { acceptNode: function (node) { return NodeFilter.FILTER_ACCEPT; } };
Здесь мы принимаем любой переданный узел. Кроме того, у нас есть возможность отклонить узел (и его дочерние FILTER_REJECT ) с опцией FILTER_REJECT . Если мы просто хотим пропустить узел, но все еще заинтересованы в его дочерних FILTER_SKIP , если они есть, мы можем использовать константу FILTER_SKIP .
Реализация нашего предыдущего примера с использованием NodeIterator довольно проста. Мы создаем новый итератор, используя метод конструктора в document . Затем мы используем метод nextNode для перебора всех узлов.
Давайте посмотрим на преобразованный пример.
« `javascript function iterateNodeIterator (template, model) {var currentNode; vargment = template.content.clone (true); var iterator = document.createNodeIterator (фрагмент, NodeFilter.SHOW_ELEMENT | NodeFilter.SHOW_TEXT, acceptAllNodes, false);
while ((currentNode = iterator.nextNode ())) changeNode (сиггепЬЫойя); возвратный фрагмент; } `` `
Поиск DOM полностью скрыт от нас. Это большое преимущество. Мы запрашиваем только те узлы, которые нам нужны, а остальное выполняется наиболее эффективным способом в движке браузера. Однако, с другой стороны, мы все еще должны предоставить код для итерации атрибутов.
Даже если атрибуты покрыты константой SHOW_ATTRIBUTE , они не связаны с узлами элемента как дочерние. Вместо этого они живут в коллекции NamedNodeMap , которая не будет включена в поиск NodeIterator . Мы можем перебирать только атрибуты, если начинаем итерацию с атрибута, ограничивая себя только атрибутами.
Предыдущий пример также может вызвать изменение в предоставленном фильтре. Это, однако, не очень хорошая практика, поскольку мы можем использовать итератор и для других целей. Поэтому итератор должен просто представить решение только для чтения, которое не изменяет дерево.
Отключение дерева также не очень хорошо поддерживается NodeIterator . Итератор можно представить как курсор в документе, помещенный между двумя (последним и следующим) узлом. Поэтому NodeIterator не указывает ни на какой узел.
Прогулка по дереву
Мы хотим перебрать узлы в поддереве. Другой вариант, который может прийти нам в голову, — это использовать TreeWalker . Здесь мы идем по дереву, как уже подсказывает название. Мы указываем корневой узел и элементы для рассмотрения в нашем маршруте, а затем обрабатываем. Интересно то, что TreeWalker имеет много общего с NodeIterator . Мало того, что мы уже видим много общих свойств, он также использует тот же NodeFilter для установки ограничений.
В большинстве TreeWalker на самом деле лучший выбор, чем NodeIterator . API NodeIterator для того, что он поставляет. TreeWalker содержит еще больше методов и настроек, но, по крайней мере, использует их.
Основное различие между TreeWalker и NodeIterator заключается в том, что первый представляет древовидное представление узлов в поддереве, а не итеративное представление списка. В то время как NodeIterator позволяет нам двигаться вперед или назад, TreeWalker дает нам возможность перейти к родительскому узлу, одному из его дочерних TreeWalker или TreeWalker .
« `javascript function iterateTreeWalker (шаблон, модель) {var фрагмент = template.content.clone (true); var walker = document.createTreeWalker (фрагмент, NodeFilter.SHOW_ELEMENT | NodeFilter.SHOW_TEXT, acceptAllNodes, false);
while (walker.nextNode ()) changeNode (treeWalker.currentNode); возвратный фрагмент; } `` `
В отличие от NodeIterator , TreeWalker указывает непосредственно на определенный узел в дереве. Если узел, на который указывает указатель, перемещается, TreeWalker будет следовать за ним. Что еще более важно, если узел, на который указывает указатель, удален из дерева, то мы фактически окажемся вне дерева документа. Если мы последуем совету NodeIterator и не NodeIterator дерево во время обхода, мы получим тот же путь.
TreeWalker также, по-видимому, почти идентичен NodeIterator для наших целей. Есть причины, по которым последний не мог привлечь много внимания. Тем не менее, TreeWalker не очень известен. Возможно, область его использования слишком ограничена, что не дает нам возможности снова обойти атрибуты — особенно с третьим вариантом, который мы имеем для итерации дерева DOM.
Выбор диапазона
Наконец, есть третья конструкция, которая может быть интересна при определенных обстоятельствах. Если мы хотим выбрать диапазон в одномерном массиве, то мы можем легко реализовать это, просто используя два индекса: i для начальной (левой) границы и f для конечной (правой) границы, которую мы имеем, [i, f] ,
Если мы заменим массив связанным списком, тогда два индекса также можно будет заменить двумя конкретными узлами [n_i, n_f] . Преимущество в этом выборе заключается в неявном механизме обновления. Если мы вставляем узлы между ними, нам не нужно обновлять границы нашего диапазона. Также, если левая граница удаляется из связанного списка, мы получаем диапазон, расширенный влево, такой как [0, n_f] .
Теперь у нас нет одномерной задачи, но есть древовидная структура. Выбор диапазона K-арного дерева не так тривиален. Мы могли бы придумать наш собственный алгоритм, но у дерева DOM есть некоторые особые проблемы. Например, у нас есть текстовые узлы, которые также могут быть предметом диапазона. В нашем дереве DOM диапазон состоит из четырех свойств. У нас есть начальный узел, конечный узел и смещение для обоих.
Есть также помощники, такие как методы selectNode или selectNodeContents , которые выполняют правильные вызовы setStart и setEnd . Например, selectNodeContents(node) эквивалентен фрагменту кода:
javascript range.setStart(node, 0); range.setEnd(node, node.childNodes.length);
Диапазоны выходят за рамки чисто программного выбора. Они также используются для фактического визуального выбора в браузере. Метод getSelection() контекста window дает объект Selection , который можно легко преобразовать в Range путем вызова getRangeAt(0) . Если ничего не выбрано, предыдущий оператор не выполняется.
Давайте рассмотрим простой пример для выбора, который приводит к следующему изображению.
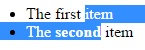
Здесь мы начинаем в текстовом узле первого элемента списка и заканчиваем в конце текстового узла сильного элемента. Следующее изображение иллюстрирует закрытый диапазон с точки зрения исходного кода.
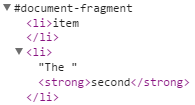
Отображение дерева DOM для предоставленного экземпляра Range также интересно. Мы видим, что такой диапазон способен охватить целый ряд узлов независимо от их предка или родного брата.
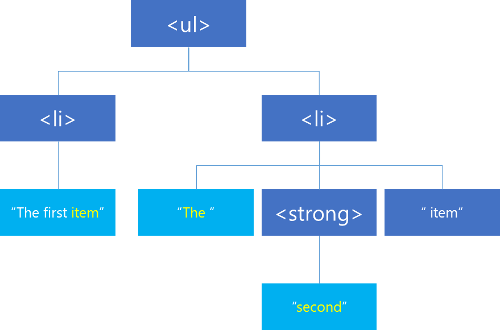
Извлечение выбранных узлов дает нам DocumentFragment , который начинается с нового элемента списка и заканчивается после сильного элемента.

Извлечение на самом деле является мутирующим действием DOM, то есть оно изменит существующее дерево Теперь у нас остались следующие два пункта, как мы и ожидали.
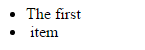
Поскольку текст может включать элементы и все, что в них содержится, диапазон также должен охватывать эти случаи. На первый взгляд Range имеет странную конструкцию, так как ему всегда нужно заботиться как минимум о двух случаях: текстовом и нетекстовом (в основном, элементах). Однако, как мы видели, есть веская причина различать эти два случая, иначе мы не смогли бы выделить фрагменты текста.
У объекта Range отсутствуют возможности итерации, которые мы испытывали ранее. Вместо этого мы улучшили возможности сериализации и экспорта. Поэтому изменение нашего прежнего примера поначалу обременительно. Тем не менее, введя несколько новых методов, мы можем объединить гибкость Range с расширенной итерацией.
« `javascript Range.prototype.current = function () {if (this.started) возвращает this.startContainer.childNodes [this.startOffset]; };
Range.prototype.next = function (types) {var s = this.startContainer; var o = this.startOffset; var n = this.current ();
if (n) { if (n.childNodes.length) { s = n; о = 0; } else if (o + 1 <s.childNodes.length) { о + = 1; } еще { делать { n = s.parentNode; if (s == this.endContainer) вернуть ложь; o = Array.prototype.indexOf.call (n.childNodes, s) + 1; s = n; } while (o === s.childNodes.length); } this.setStart (s, o); n = this.current (); } иначе если (! this.started) { this.started = true; n = this.current (); } if (n && types && Array.isArray (types) && types.indexOf (n.nodeType) <0) вернуть this.next (); возврат !! n; }; `` `
Эти два метода позволяют использовать Range же, как и итераторы ранее. Прямо сейчас мы можем идти только в одном направлении; тем не менее, мы могли бы легко реализовать методы, чтобы пропустить потомков, перейти непосредственно к родителю или выполнить любое другое движение.
« `javascript function iterateRange (template, model) {var фрагмент = шаблон.content.clone (true); var range = document.createRange (); range.selectNodeContents (фрагмент);
while (range.nextNode ([Node.TEXT_NODE, Node.ELEMENT_NODE])) changeNode (range.current ()); range.detach (); возвратный фрагмент; } `` `
Несмотря на то, что Range является сборщиком мусора, как и любой другой объект JavaScript, все же рекомендуется освобождать его с помощью функции detach . Одна из причин заключается в том, что все экземпляры Range фактически хранятся в document , где они обновляются в случае мутаций DOM.
Определение наших собственных методов итераторов для Range полезно. Смещения автоматически обновляются, и у нас есть вспомогательные возможности, такие как клонирование текущего выделения в виде DocumentFragment , извлечение или удаление выбранных узлов. Также мы можем разработать API для наших собственных нужд.
Вывод
Итерация по дереву DOM — интересная тема для всех, кто задумывается о манипулировании DOM и эффективном поиске узлов. Для большинства случаев использования уже существует соответствующий API. Мы хотим простую итерацию? Мы хотим выбрать диапазон? Мы хотим гулять по дереву? У каждого метода есть свои преимущества и недостатки. Если мы знаем, чего хотим, мы можем сделать правильный выбор.
К сожалению, древовидные структуры не так просты, как одномерные массивы. Их можно сопоставить с одномерными массивами, но сопоставление следует тому же алгоритму, что и итерация по его структуре. Если мы используем одну из предоставленных структур, у нас есть доступ к методам, которые уже следуют этим алгоритмам. Поэтому мы получаем удобный способ выполнить итерацию по узлам в K-арном дереве. Мы также экономим некоторую производительность, выполняя меньше операций DOM.