Масштабирование от 4K до 40 миллионов в Dropbox
Некоторое время я отвечал за масштабирование Dropbox , примерно от 4000 до 40 000 000 пользователей. Большую часть этого времени у нас работало от одного до трех человек. Вот некоторые предложения по масштабированию, особенно в условиях ограниченных ресурсов, быстро растущей среды, которая не всегда может позволить себе делать вещи «правильным образом», то есть в любом реальном инженерном проекте!
Бег с дополнительной нагрузкой
Одна из техник, которую мы неоднократно использовали, создавала искусственную дополнительную нагрузку на живой сайт. Например, мы сделали бы намного больше операций чтения из memcached, чем необходимо. Затем, когда memcached сломался, мы могли быстро отключить повторяющиеся запросы и успеть найти решение. Почему бы просто не планировать заранее? Потому что большую часть времени это был очень резкий сбой, который мы не могли обнаружить с помощью мониторинга. Обратите внимание, что не просто совершать дополнительные операции чтения, потому что более вероятно, что высокая нагрузка записи вызовет проблемы, но записи трудно смоделировать (риск подвергнуть опасности данные, не получая реалистичное количество конфликтов блокировки). По моему опыту, одни только дополнительные чтения на самом деле достаточно хороши, чтобы выиграть время.
Метрики для приложений
Еще одна вещь, которая становилась все более полезной при масштабировании, заключалась в том, что тысячи пользовательских статистических данных агрегировались на тысячах серверов. Большинство готовых решений по мониторингу не предназначены для обработки такого рода нагрузки, и нам нужен был однострочный способ добавления статистики, чтобы нам не приходилось думать о том, стоит ли это чего-то или суетиться с конфигурационными файлами, чтобы просто добавить статистику (снижение трения тестирования и мониторинга является большим приоритетом). Мы решили реализовать решение в комбинации memcached, cron и ganglia . Каждый раз, когда происходило что-то, что мы хотели представить, мы сохраняли это в буфере локальной памяти потока. Каждую секунду мы помещаем эту статистику в корзину с временным ключом (timestamp mod что-то) в memcached, а на центральной машине каждую минуту корзины в memcached очищаются, агрегируются и отправляются в ганглии. Очень масштабируемый, и это позволило нам отслеживать тысячи статистических данных практически в реальном времени. Даже статистика, столь же детализированная, как «среднее время чтения ключа memcached», которое происходило десятки раз за запрос, выполнялась нормально. Конечно, когда у вас есть тысячи характеристик, становится трудно просто «смотреть на графики», чтобы найти аномалии. Вот один сводный график, который мы нашли наиболее полезным: 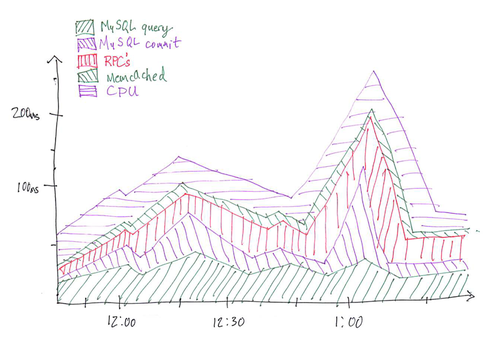
Верхняя строка представляет среднее время ответа на сайте (у нас был один из этих графиков для веб-трафика и один для трафика клиента). Каждый сегмент представляет собой раздел работы. Итак, вы можете видеть, что примерно в 1:00 время отклика увеличилось, что было вызвано чем-то в фазе фиксации MySQL. На нашем реальном графике было больше сегментов, поэтому представьте, сколько экранной недвижимости это экономит, когда вы пытаетесь разобраться. «CPU» — это мошенничество, на самом деле это просто среднее время отклика минус все остальное, что мы учтем. Если есть способ сделать это, было бы здорово иметь на графике метки, указывающие на события, которые вы можете аннотировать, такие как нажатие кода или сбой AWS.
Бедная мужская аналитика с башом
Если вы не часто используете оболочку, это может показаться, насколько быстрее выполняются определенные задачи. Допустим, вы пытаетесь что-то отладить на своем веб-сервере, и вы хотите знать, возможно, в последнее время произошел всплеск активности, и все, что у вас есть, это журналы. Графики для этого веб-сервера были бы хорошими, но если они выполняются с интервалами в 1 или 5 минут, как в большинстве систем, они могут быть недостаточно детализированными (или, возможно, вы просто хотите посмотреть на запрос определенного типа или что-то в этом роде).
8 апр. 2012 14:33:59 POST ... 8 апреля 2012 14:34:00 ПОЛУЧИТЬ ... 8 апр. 2012 14:34:01 POST ...
Вы можете использовать свою оболочку следующим образом:
cut -d '' -f1-4 log.txt | xargs -L1 -I_ дата +% s -d_ | uniq -c | (повторить «plot» - «используя 2: 1 с линиями»; cat) | Gnuplot
Boom!
Очень быстро у вас есть хороший график того, что происходит, и вы можете легко настроить его (выбрать только один URL-адрес, изменить гистограмму и т. Д.). Почти все инструменты командной строки принимают разделенные строкой двумерные массивы с разделителями пробелом в качестве входных данных с неявным числовым преобразованием по мере необходимости, поэтому обычно не требуется выполнять обратные кадры для передачи программ вместе. Они также не генерируют исключения для неверных данных, что, на мой взгляд, хорошо, когда вы просто пытаетесь что-то сделать быстро и не заботитесь о нескольких пропущенных точках данных. Если вы не знакомы с инструментами командной строки, вот короткий список, с которым я бы порекомендовал ознакомиться: sed, awk, grep, cut, head, tail, sort, uniq, tr, date, xargs
Журнал спама действительно полезен
Журнал спама не так уж и плох. Раньше у нас было так много случайных операторов печати, разбросанных по коду, которые попадали в журналы нашего веб-сервера, но я не могу сосчитать, сколько раз это оказалось непреднамеренно полезным. Это почти способ случайного отслеживания вашего кода. Так, например, при отладке особенно неприятного состояния гонки я заметил, что определенный «## ваш специальный комментарий ##» не печатался там, где он должен был быть, и это давало понять, где происходит проблема.
Если что-то может потерпеть неудачу, убедитесь, что оно делает
Если у вас есть что-то, что, как вы знаете, может в любой момент дать сбой, и вы думаете, что отработка отказа будет изящной, вам следует проверять это время от времени. Случайно отключите этот сервер от сети и убедитесь, что отработка отказа работает, потому что может произойти пара вещей:
- Начиная с последнего аварийного переключения, увеличенная нагрузка означает, что процесс аварийного переключения теперь вызывает каскад.
- В промежутке между последним аварийным переключением и сейчас произошли несколько миллиардов нажатий кода, изменения схемы базы данных, внутренние переименования DNS и т. Д., Поэтому любой из тех сценариев, которые с тех пор не запускались, может зависеть от старых предположений.
Эти вещи лучше понять в мирное время, поэтому лучше, чтобы это происходило намеренно. Может быть, звучать глупо, чтобы проводить пожарные учения на живой площадке, но условий тестирования недостаточно, и это действительно хорошая страховка.
Запускай нечастые вещи чаще вообще
Вышеуказанные пункты также относятся к вещам, которые просто не часто запускаются в вашей кодовой базе. Если вы можете позволить себе проталкивать код по нечастым путям кода чаще, это избавит вас от головной боли. Например, если у вас есть cron, который запускается каждый месяц, возможно, запускайте его как пробную версию каждый день или неделю, чтобы убедиться, что, по крайней мере, предположения согласованы, поэтому вам не нужно отлаживать его после месячных коммитов. То же самое касается сценариев, которые запускаются только вручную.
Постарайтесь сохранить вещи однородными
Когда-то давно у нас было два шарда для пользовательских данных, и как только они начали заполняться, я добавил третий шард для добавления новых пользователей. Черт, это была головная боль! Итак, у нас было два осколка, растущих почти в одном и том же темпе, и новый, который рос гораздо быстрее, а это значит, что мы должны были разыгрывать в разное время. Гораздо лучше (но, очевидно, хитрее) просто разделить каждый осколок на два и сохранить их все одинаковыми. Однородность хороша и для аппаратного обеспечения, поскольку планирование емкости становится более простой проблемой.
Ведение журнала простоя
Каждый раз, когда сайт выходит из строя или ухудшается (даже короткими сообщениями), запишите время начала и окончания отключения, а затем пометьте его любыми применимыми причинами (плохой анализ кода, недостаточный мониторинг, переполнение журнала). Затем, когда вы посмотрите на список, вы можете объективно ответить на вопрос «что я могу сделать, чтобы минимизировать наибольшее количество простоев прямо сейчас?», Выяснив, как покрыть наибольшее количество минут. Решения могут охватывать несколько проблем, и каждая проблема может быть решена многими способами, поэтому она помогает записать как можно больше. Например, надлежащий мониторинг может предупредить вас о надвигающейся проблеме переполнения диска, или вы можете ограничить количество материала, записываемого на диск.
универсальное глобальное время
Храните все в UTC внутри! Время работы сервера, содержимое базы данных и т. Д. Это избавит от множества головных болей, а не только от перехода на летнее время. Некоторое программное обеспечение просто даже не обрабатывает время без UTC, так что не делайте этого! Мы держали часы на стене, установленные на UTC. Если вы хотите отобразить время для пользователя, сделайте преобразование часового пояса в последнюю секунду.
Технологии, которые мы использовали
Для тех, кому интересно, что мы выбрали и почему, мы использовали программное обеспечение:
- Python практически для всего; не более пары тысяч строк
- MySQL
- Paster / Pylons / Cheetah (веб-фреймворк — минимальное использование помимо шаблонов и обработки ввода формы)
- S3 / EC2 для хранения и обслуживания файловых блоков
- memcached перед базой данных и для обработки межсерверной координации
- ganglia для построения графиков, с drraw для пользовательских графиков, таких как график стеков, упомянутый выше
- nginx для внешнего сервера
- haproxy для балансировки нагрузки на серверы приложений после nginx (лучшая конфигурируемость, чем модули балансировки nginx)
- нагиос для внутренних проверок здоровья
- Pingdom для внешнего мониторинга сервиса и пейджинга
- GeoIP для сопоставления IP-адресов с местоположениями
Довольно стандартный. Причина, по которой мы выбрали каждую из этих вещей, была одинаковой — надежность. Даже в memcached, который является концептуально самой простой из этих технологий и используется многими другими компаниями, были ДЕЙСТВИТЕЛЬНО неприятные ошибки, связанные с повреждением памяти, с которыми нам приходилось сталкиваться, поэтому мне не терпится подумать об использовании чего-то более нового и более сложного. Мое единственное предложение по выбору технологии — это выбрать легкие вещи, которые, как известно, работают и которые часто используются за пределами вашей компании, или быть готовыми стать «основным спонсором» проекта.
Моделируйте / анализируйте вещи, прежде чем пытаться их
В отличие от продукта, о котором сложнее рассуждать, бэкэнд-инжиниринг достаточно объективен (оптимизировать время загрузки страницы, время безотказной работы и т. Д.), И поэтому мы можем использовать это в своих интересах. Если вы думаете, что что-то даст результат, вы можете подумать о том, чтобы имитировать эффекты более простым способом, прежде чем приступить к его реализации. Как играть с перемещением сервера базы данных в место с большей задержкой, добавьте задержку в несколько мс в свой низкоуровневый клей базы данных и посмотрите, что произойдет.
Компромисс безопасность-удобство
Безопасность действительно важна для Dropbox, потому что это личные файлы людей. Но все сервисы различны, и многие решения по безопасности могут доставить кому-то неудобства, будь то программист или пользователь. Наличие внутренних межсетевых экранов между серверами, которым не нужно общаться друг с другом — опять же хорошая идея. Но если ваша служба на самом деле не нуждается в этом, не обязательно делать это, или делать это там, где это важно. Возможно, это противоречиво… но безопасность — это то, что людям нравится делать на словах и философствовать, но на самом деле я думаю, что многие службы (даже банки!) Имеют серьезные проблемы с безопасностью. Так что разберитесь, действительно ли это важно для вас (стоит ли взламывать? Вас действительно волнует, взломали ли это? Стоит ли это затрат на разработку или продукт?), Прежде чем идти и блокировать все.