Операции с базами данных часто являются основным узким местом для большинства веб-приложений сегодня. Эти проблемы с производительностью должны беспокоить не только администраторов баз данных (администраторов баз данных). Мы, программисты, должны выполнять свою часть работы, правильно структурируя таблицы, создавая оптимизированные запросы и улучшая код. В этой статье я перечислю некоторые методы оптимизации MySQL для программистов.
Прежде чем мы начнем, имейте в виду, что вы можете найти множество полезных сценариев и утилит MySQL на Envato Market.

1. Оптимизируйте свои запросы для кеша запросов
На большинстве серверов MySQL включено кэширование запросов. Это один из наиболее эффективных методов повышения производительности, который незаметно обрабатывается ядром базы данных. Когда один и тот же запрос выполняется несколько раз, результат выбирается из кеша, что довольно быстро.
Основная проблема в том, что это так просто и скрыто от программиста, что большинство из нас склонны игнорировать это. Некоторые вещи, которые мы делаем, могут фактически препятствовать выполнению своей задачи кешем запросов.
|
1
2
3
4
5
6
|
// query cache does NOT work
$r = mysql_query(«SELECT username FROM user WHERE signup_date >= CURDATE()»);
// query cache works!
$today = date(«Ymd»);
$r = mysql_query(«SELECT username FROM user WHERE signup_date >= ‘$today'»);
|
Причиной того, что кеш запросов не работает в первой строке, является использование функции CURDATE (). Это относится ко всем недетерминированным функциям, таким как NOW () и RAND () и т. Д. Поскольку возвращаемый результат функции может измениться, MySQL решает отключить кеширование запросов для этого запроса. Все, что нам нужно было сделать, это добавить дополнительную строку PHP перед запросом, чтобы этого не произошло.
2. ОБЪЯСНИТЕ ВЫБЕРИТЕ запросы
Использование ключевого слова EXPLAIN может дать вам представление о том, что делает MySQL для выполнения вашего запроса. Это может помочь вам определить узкие места и другие проблемы с вашим запросом или структурами таблиц.
Результаты запроса EXPLAIN покажут, какие индексы используются, как сканируется и сортируется таблица и т. Д.
Возьмите запрос SELECT (желательно сложный, с объединениями) и добавьте перед ним ключевое слово EXPLAIN. Вы можете просто использовать phpmyadmin для этого. Он покажет вам результаты в хорошей таблице. Например, допустим, я забыл добавить индекс к столбцу, для которого я выполняю соединения:
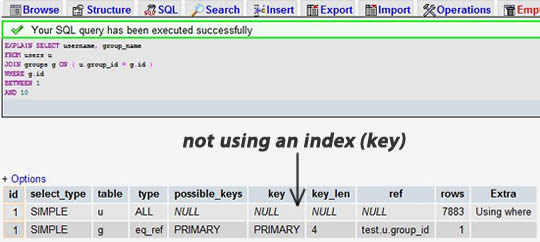
После добавления индекса в поле group_id:
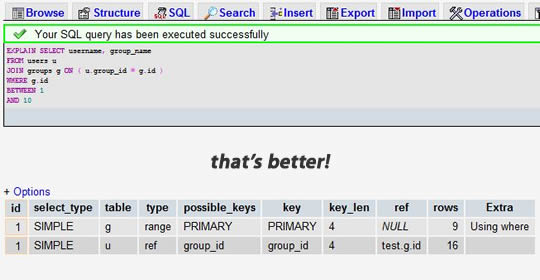
Теперь вместо сканирования 7883 строк он будет сканировать только 9 и 16 строк из 2 таблиц. Хорошее практическое правило — умножить все числа в столбце «строки», и производительность вашего запроса будет несколько пропорциональна полученному числу.
3. ПРЕДЕЛ 1 при получении уникальной строки
Иногда, когда вы запрашиваете ваши таблицы, вы уже знаете, что ищете только одну строку. Возможно, вы выбираете уникальную запись или просто проверяете наличие любого количества записей, удовлетворяющих вашему предложению WHERE.
В таких случаях добавление LIMIT 1 к вашему запросу может повысить производительность. Таким образом, ядро базы данных прекратит сканирование записей после того, как найдет только 1, вместо того, чтобы проходить через всю таблицу или индекс.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
// do I have any users from Alabama?
// what NOT to do:
$r = mysql_query(«SELECT * FROM user WHERE state = ‘Alabama'»);
if (mysql_num_rows($r) > 0) {
// …
}
// much better:
$r = mysql_query(«SELECT 1 FROM user WHERE state = ‘Alabama’ LIMIT 1»);
if (mysql_num_rows($r) > 0) {
// …
}
|
4. Индексируйте поля поиска
Индексы предназначены не только для первичных ключей или уникальных ключей. Если в вашей таблице есть столбцы, по которым вы будете искать, вы почти всегда должны их индексировать.
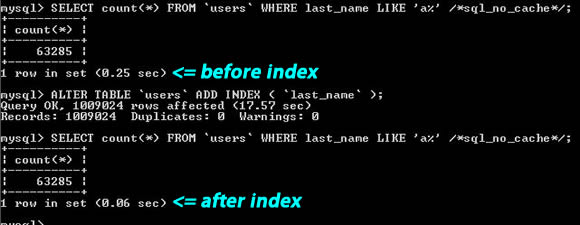
Как вы можете видеть, это правило также применимо к частичному поиску строк, например «last_name LIKE ‘a%'». При поиске с начала строки MySQL может использовать индекс для этого столбца.
Вы также должны понимать, какие виды поиска не могут использовать обычные индексы. Например, при поиске слова (например, «WHERE post_content LIKE ‘% apple%'») вы не увидите выгоды от нормального индекса. Вам будет лучше использовать полнотекстовый поиск mysql или создать собственное решение для индексирования.
5. Индексируйте и используйте одинаковые типы столбцов для объединений.
Если ваше приложение содержит много запросов JOIN, вам необходимо убедиться, что столбцы, к которым вы присоединяетесь, проиндексированы в обеих таблицах. Это влияет на то, как MySQL внутренне оптимизирует операцию соединения.
Кроме того, столбцы, которые объединяются, должны быть одного типа. Например, если вы присоедините столбец DECIMAL к столбцу INT из другой таблицы, MySQL не сможет использовать хотя бы один из индексов. Даже кодировки символов должны быть одинакового типа для столбцов строкового типа.
|
1
2
3
4
5
6
7
8
|
// looking for companies in my state
$r = mysql_query(«SELECT company_name FROM users
LEFT JOIN companies ON (users.state = companies.state)
WHERE users.id = $user_id»);
// both state columns should be indexed
// and they both should be the same type and character encoding
// or MySQL might do full table scans
|
6. НЕ ЗАКАЗЫВАЙТЕ ПО RAND ()
Поначалу это один из тех трюков, которые звучат круто, и многие новички попадают в эту ловушку. Вы можете не понимать, какое ужасное узкое место вы можете создать, когда начнете использовать это в своих запросах.
Если вам действительно нужны случайные строки из ваших результатов, есть гораздо лучшие способы сделать это. Конечно, это требует дополнительного кода, но вы предотвратите узкое место, которое экспоненциально ухудшается по мере роста ваших данных. Проблема в том, что MySQL должен будет выполнить операцию RAND () (которая потребляет вычислительную мощность) для каждой строки в таблице, прежде чем отсортировать ее и получить только 1 строку.
|
01
02
03
04
05
06
07
08
09
10
11
|
// what NOT to do:
$r = mysql_query(«SELECT username FROM user ORDER BY RAND() LIMIT 1»);
// much better:
$r = mysql_query(«SELECT count(*) FROM user»);
$d = mysql_fetch_row($r);
$rand = mt_rand(0,$d[0] — 1);
$r = mysql_query(«SELECT username FROM user LIMIT $rand, 1»);
|
Таким образом, вы выбираете случайное число меньше количества результатов и используете его в качестве смещения в предложении LIMIT.
7. Избегайте SELECT *
Чем больше данных будет прочитано из таблиц, тем медленнее будет выполняться запрос. Это увеличивает время, необходимое для операций с диском. Также, когда сервер базы данных отделен от веб-сервера, вы будете иметь более длительные задержки в сети из-за данных, которые должны быть переданы между серверами.
Это хорошая привычка всегда указывать, какие столбцы вам нужны, когда вы делаете свой SELECT.
|
01
02
03
04
05
06
07
08
09
10
11
|
// not preferred
$r = mysql_query(«SELECT * FROM user WHERE user_id = 1»);
$d = mysql_fetch_assoc($r);
echo «Welcome {$d[‘username’]}»;
// better:
$r = mysql_query(«SELECT username FROM user WHERE user_id = 1»);
$d = mysql_fetch_assoc($r);
echo «Welcome {$d[‘username’]}»;
// the differences are more significant with bigger result sets
|
8. Почти всегда есть поле id
В каждой таблице есть столбец id, который является ПЕРВИЧНЫМ КЛЮЧОМ, AUTO_INCREMENT и одним из видов INT. Также желательно UNSIGNED, так как значение не может быть отрицательным.
Даже если у вас есть таблица пользователей с уникальным полем имени пользователя, не делайте это своим основным ключом. Поля VARCHAR в качестве первичных ключей работают медленнее. И вы будете иметь лучшую структуру в своем коде, обращаясь ко всем пользователям с их внутренним идентификатором.
Также есть скрытые операции, выполняемые самим движком MySQL, который использует поле первичного ключа для внутреннего использования. Что становится еще важнее, тем сложнее настройка базы данных. (кластеры, разбиение и т.д …).
Одним из возможных исключений из правила являются «таблицы ассоциаций», используемые для типа «многие ко многим» между двумя таблицами. Например, таблица «posts_tags», которая содержит 2 столбца: post_id, tag_id, которая используется для отношений между двумя таблицами с именем «post» и «tags». Эти таблицы могут иметь первичный ключ, который содержит оба поля идентификатора.
9. Используйте ENUM поверх VARCHAR
Колонки типа ENUM очень быстрые и компактные. Внутри они хранятся как TINYINT, но могут содержать и отображать строковые значения. Это делает их идеальным кандидатом для определенных областей.
Если у вас есть поле, которое будет содержать только несколько различных типов значений, используйте ENUM вместо VARCHAR. Например, это может быть столбец с именем «status», который может содержать только такие значения, как «active», «inactive», «pending», «expired» и т. Д.
Есть даже способ получить «предложение» от самого MySQL о том, как реструктурировать вашу таблицу. Если у вас есть поле VARCHAR, оно может предложить вам вместо этого изменить тип столбца на ENUM. Это делается с помощью вызова PROCEDURE ANALYZE (). Что приводит нас к:
10. Получить предложения с ПРОЦЕДУРОЙ АНАЛИЗА ()
PROCEDURE ANALYZE () позволит MySQL проанализировать структуры столбцов и фактические данные в вашей таблице, чтобы предложить вам определенные предложения. Это полезно, только если в ваших таблицах есть фактические данные, потому что это играет большую роль в принятии решений.
Например, если вы создали поле INT для своего первичного ключа, однако не имеете слишком много строк, он может предложить вместо этого использовать MEDIUMINT. Или, если вы используете поле VARCHAR, вы можете получить предложение преобразовать его в ENUM, если уникальных значений мало.
Это также можно запустить, щелкнув ссылку «Предложить структуру таблицы» в phpmyadmin в одном из представлений таблицы.
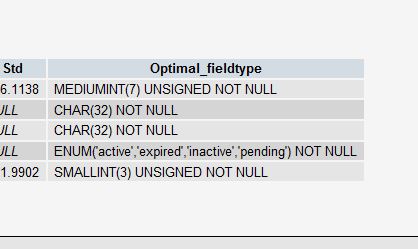
Имейте в виду, что это только предложения. И если ваш стол будет расти больше, они могут даже не быть правильными предложениями для подражания. Решение в конечном итоге за вами.
11. Используйте NOT NULL, если можете
Если у вас нет очень конкретной причины использовать значение NULL, вы должны всегда устанавливать столбцы как NOT NULL.
Прежде всего, спросите себя, есть ли разница между наличием пустого строкового значения и значения NULL (для полей INT: 0 против NULL). Если нет причин иметь оба, вам не нужно поле NULL. (Знаете ли вы, что Oracle считает NULL и пустую строку одинаковыми?)
NULL столбцы требуют дополнительного пространства, и они могут добавить сложность в ваши операторы сравнения. Просто избегайте их, когда можете. Однако я понимаю, что у некоторых людей могут быть очень конкретные причины иметь значения NULL, что не всегда плохо.
Из документов MySQL:
«Столбцы NULL требуют дополнительного пространства в строке, чтобы записать, имеют ли их значения NULL. Для таблиц MyISAM каждый столбец NULL занимает один дополнительный бит, округленный до ближайшего байта».
12. Подготовленные заявления
Использование готовых операторов дает множество преимуществ как по производительности, так и по соображениям безопасности.
Подготовленные операторы фильтруют переменные, которые вы связываете с ними по умолчанию, что отлично подходит для защиты вашего приложения от атак SQL-инъекций. Конечно, вы также можете фильтровать переменные вручную, но эти методы более склонны к человеческим ошибкам и забывчивости программистом. Это не проблема при использовании какой-либо платформы или ORM.
Поскольку мы сосредоточены на производительности, я должен также упомянуть преимущества в этой области. Эти преимущества более значимы, когда один и тот же запрос используется в вашем приложении несколько раз. Вы можете назначить разные значения одному и тому же подготовленному оператору, но MySQL будет анализировать его только один раз.
Также последние версии MySQL передают подготовленные операторы в собственном двоичном виде, которые более эффективны и могут также помочь уменьшить задержки в сети.
Было время, когда многие программисты старались избегать заранее подготовленных утверждений по одной важной причине. Они не кэшировались кэшем запросов MySQL. Но начиная с версии 5.1, кеширование запросов также поддерживается.
Чтобы использовать подготовленные операторы в PHP, вы проверяете расширение mysqli или используете уровень абстракции базы данных, такой как PDO .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
// create a prepared statement
if ($stmt = $mysqli->prepare(«SELECT username FROM user WHERE state=?»)) {
// bind parameters
$stmt->bind_param(«s», $state);
// execute
$stmt->execute();
// bind result variables
$stmt->bind_result($username);
// fetch value
$stmt->fetch();
printf(«%s is from %s\n», $username, $state);
$stmt->close();
}
|
13. Небуферизованные запросы
Обычно, когда вы выполняете запрос из скрипта, он будет ждать завершения этого запроса, прежде чем продолжить. Вы можете изменить это, используя небуферизованные запросы.
В документации PHP есть отличное объяснение функции mysql_unbuffered_query () :
«mysql_unbuffered_query () отправляет запрос SQL-запроса в MySQL без автоматической выборки и буферизации строк результатов, как это делает mysql_query (). Это экономит значительный объем памяти с запросами SQL, которые производят большие наборы результатов, и вы можете начать работу с набором результатов сразу после извлечения первой строки, так как вам не нужно ждать, пока завершится полный SQL-запрос. «
Однако это имеет определенные ограничения. Вы должны либо прочитать все строки, либо вызвать mysql_free_result (), прежде чем сможете выполнить другой запрос. Также вы не можете использовать mysql_num_rows () или mysql_data_seek () в наборе результатов.
14. Храните IP-адреса как неподписанные INT
Многие программисты создают поле VARCHAR (15), не понимая, что они могут хранить IP-адреса в виде целочисленных значений. С INT вы уменьшаете до 4 байтов пространства и вместо этого получаете поле фиксированного размера.
Вы должны убедиться, что ваш столбец имеет тип UNSIGNED INT, поскольку IP-адреса используют весь диапазон 32-разрядного целого числа без знака.
В своих запросах вы можете использовать INET_ATON () для преобразования и IP в целое число, а INET_NTOA () для обратного . В PHP также есть похожие функции, называемые ip2long () и long2ip () .
|
1
|
$r = «UPDATE users SET ip = INET_ATON(‘{$_SERVER[‘REMOTE_ADDR’]}’) WHERE user_id = $user_id»;
|
15. Таблицы фиксированной длины (статические) быстрее
Когда каждый столбец в таблице имеет «фиксированную длину», эта таблица также считается «статической» или «фиксированной длины» . Примеры типов столбцов НЕ фиксированной длины: VARCHAR, TEXT, BLOB. Если вы включите хотя бы один из этих типов столбцов, таблица перестает быть фиксированной длины и должна обрабатываться движком MySQL по-разному.
Таблицы фиксированной длины могут повысить производительность, потому что движок MySQL быстрее просматривает записи. Когда он хочет прочитать определенную строку в таблице, он может быстро рассчитать ее положение. Если размер строки не фиксирован, каждый раз, когда ему нужно выполнить поиск, он должен обратиться к индексу первичного ключа.
Их также легче кэшировать и легче восстанавливать после сбоя. Но они также могут занять больше места. Например, если вы преобразуете поле VARCHAR (20) в поле CHAR (20), оно всегда будет занимать 20 байт пространства независимо от того, в чем оно находится.
Используя методы «Вертикальное разбиение», вы можете разделить столбцы переменной длины на отдельную таблицу. Что приводит нас к:
16. Вертикальное разделение
Вертикальное разбиение — это процесс разделения структуры таблицы по вертикали в целях оптимизации.
Пример 1. Возможно, у вас есть таблица пользователей, содержащая домашние адреса, которые не часто читаются. Вы можете разделить таблицу и сохранить информацию об адресе в отдельной таблице. Таким образом, ваша таблица основных пользователей будет уменьшаться в размере. Как вы знаете, меньшие таблицы работают быстрее.
Пример 2 : у вас есть поле «last_login» в вашей таблице. Он обновляется каждый раз, когда пользователь входит на сайт. Но каждое обновление таблицы приводит к сбросу кэша запросов для этой таблицы. Вы можете поместить это поле в другую таблицу, чтобы свести к минимуму обновления таблицы пользователей.
Но вам также нужно убедиться, что вам не нужно постоянно объединять эти 2 таблицы после разбиения, иначе вы можете столкнуться с падением производительности.
17. Разделить большие запросы DELETE или INSERT
Если вам нужно выполнить большой запрос DELETE или INSERT на активном веб-сайте, вы должны быть осторожны, чтобы не нарушить интернет-трафик. Когда такой большой запрос выполняется, он может заблокировать ваши таблицы и остановить ваше веб-приложение.
Apache запускает много параллельных процессов / потоков. Поэтому он работает наиболее эффективно, когда выполнение скриптов завершается как можно скорее, поэтому серверы не испытывают слишком много открытых соединений и процессов одновременно, которые потребляют ресурсы, особенно память.
Если вы в конечном итоге заблокируете свои таблицы на длительный период времени (например, 30 секунд или более) на веб-сайте с высоким трафиком, вы вызовете сбой процесса и запроса, который может занять много времени для очистки или даже сбоя вашей сети. сервер.
Если у вас есть какой-то сценарий обслуживания, который должен удалять большое количество строк, просто используйте предложение LIMIT, чтобы сделать это небольшими партиями, чтобы избежать этой перегрузки.
|
1
2
3
4
5
6
7
8
9
|
while (1) {
mysql_query(«DELETE FROM logs WHERE log_date <= ‘2009-10-01’ LIMIT 10000»);
if (mysql_affected_rows() == 0) {
// done deleting
break;
}
// you can even pause a bit
usleep(50000);
}
|
18. Меньшие столбцы быстрее
С ядрами баз данных диск, пожалуй, является наиболее существенным узким местом. Сокращение объема и компактность обычно помогают с точки зрения производительности уменьшить объем передачи данных на диск.
Документы MySQL содержат список требований к хранилищу для всех типов данных.
Если ожидается, что в таблице будет очень мало строк, нет причин делать первичный ключ INT, а не MEDIUMINT, SMALLINT или даже в некоторых случаях TINYINT. Если вам не нужен компонент времени, используйте DATE вместо DATETIME.
Просто убедитесь, что вы оставляете достаточно места для роста, иначе вы можете оказаться как Slashdot .
19. Выберите правильный механизм хранения
Два основных механизма хранения в MySQL — это MyISAM и InnoDB. У каждого есть свои плюсы и минусы.
MyISAM хорош для приложений с интенсивным чтением, но он не очень хорошо масштабируется при большом количестве записей. Даже если вы обновляете одно поле одной строки, вся таблица блокируется, и никакой другой процесс не может даже прочитать из нее, пока этот запрос не будет завершен. MyISAM очень быстро вычисляет типы запросов SELECT COUNT (*).
InnoDB имеет тенденцию быть более сложным механизмом хранения и может быть медленнее, чем MyISAM для большинства небольших приложений. Но он поддерживает блокировку на основе строк, которая лучше масштабируется. Он также поддерживает некоторые более сложные функции, такие как транзакции.
20. Используйте объектный реляционный маппер
Используя ORM (Object Relational Mapper), вы можете получить определенные преимущества в производительности. Все, что может сделать ORM, может быть закодировано вручную. Но это может означать слишком много дополнительной работы и требовать высокого уровня знаний.
ORM отлично подходят для «Lazy Loading». Это означает, что они могут получать значения только по мере необходимости. Но вы должны быть осторожны с ними, иначе вы можете создать множество мини-запросов, которые могут снизить производительность.
ORM также может группировать ваши запросы в транзакции, которые работают намного быстрее, чем отправка отдельных запросов в базу данных.
В настоящее время мой любимый ORM для PHP — Doctrine . Я написал статью о том, как установить Doctrine с CodeIgniter .
21. Будьте осторожны с постоянными связями
Постоянные соединения предназначены для уменьшения накладных расходов при воссоздании соединений с MySQL. Когда постоянное соединение создано, оно останется открытым даже после завершения работы скрипта. Поскольку Apache повторно использует свои дочерние процессы, в следующий раз, когда процесс будет запущен для нового сценария, он будет использовать то же соединение MySQL.
Это звучит великолепно в теории. Но по моему личному опыту (и многим другим) эта функция оказалась не стоящей проблемой. У вас могут быть серьезные проблемы с ограничениями соединения, проблемами с памятью и так далее.
Apache работает очень параллельно и создает много дочерних процессов. Это основная причина того, что постоянные соединения не очень хорошо работают в этой среде. Прежде чем рассмотреть возможность использования функции mysql_pconnect (), проконсультируйтесь с системным администратором.
- Подпишитесь на нас в Твиттере или подпишитесь на ленту Nettuts + RSS для получения лучших учебных материалов по веб-разработке.