В этом руководстве показано, как использовать API-интерфейс Python для подключения к учетной записи Twitter с помощью библиотеки Twitter. В частности, этот API позволяет пользователю извлекать большие объемы данных, относящихся к конкретной учетной записи Twitter, а также напрямую контролировать сообщения Twitter с платформы Python (например, публиковать несколько твитов одновременно).

Даже если вы не обычный пользователь Python, использование одной из библиотек Python в Twitter весьма полезно, когда дело доходит до аналитики. Например, в то время как веб-разработчики могут быть более склонны использовать язык, такой как PHP, для подключения к API, Python предлагает большую гибкость в анализе тенденций и статистики с данными. Таким образом, исследователи данных и другие аналитики считают, что Python лучше подходит для этой цели.
В этом руководстве мы начнем с некоторых основных шагов по подключению Python к API Twitter, а затем рассмотрим, как передавать нужные данные. Обратите внимание, что хотя библиотека Twitter (и другие библиотеки Python, такие как Tweepy и Twython ) могут выполнять множество различных задач с данными, я сосредоточусь на некоторых более простых (и полезных) запросах в этой статье. В частности, я пойду через, как:
- подключите Python к API Twitter, используя соответствующие учетные данные
- скачать твиты, связанные с конкретным аккаунтом
- скачать список всех подписчиков и подписчиков для аккаунта
- опубликовать несколько твитов одновременно
- настроить поиск экземпляров определенного термина в Twitter.
1. Подключите Python к API Twitter
Это руководство использует iPython в качестве интерфейса Python для подключения к Twitter. Чтобы подключиться к API, нам необходимо получить Ключ потребителя, Секрет потребителя и Секрет токена доступа .
Чтобы получить их, вам необходимо войти в свою учетную запись на apps.twitter.com . Там вам будет предложено создать приложение:
Создав приложение, вы найдете соответствующие ключи и токены в разделе Ключи и токены доступа .
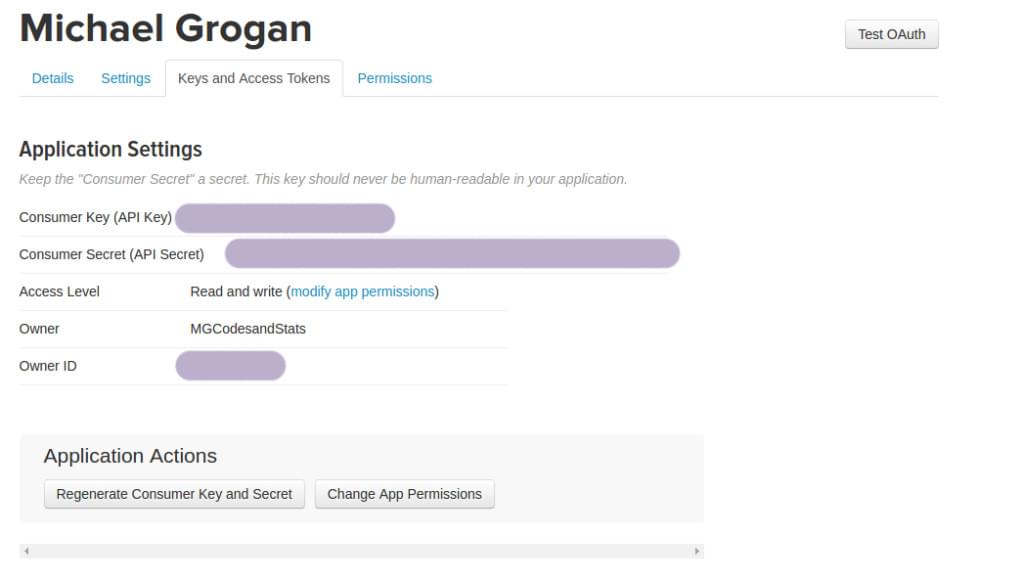
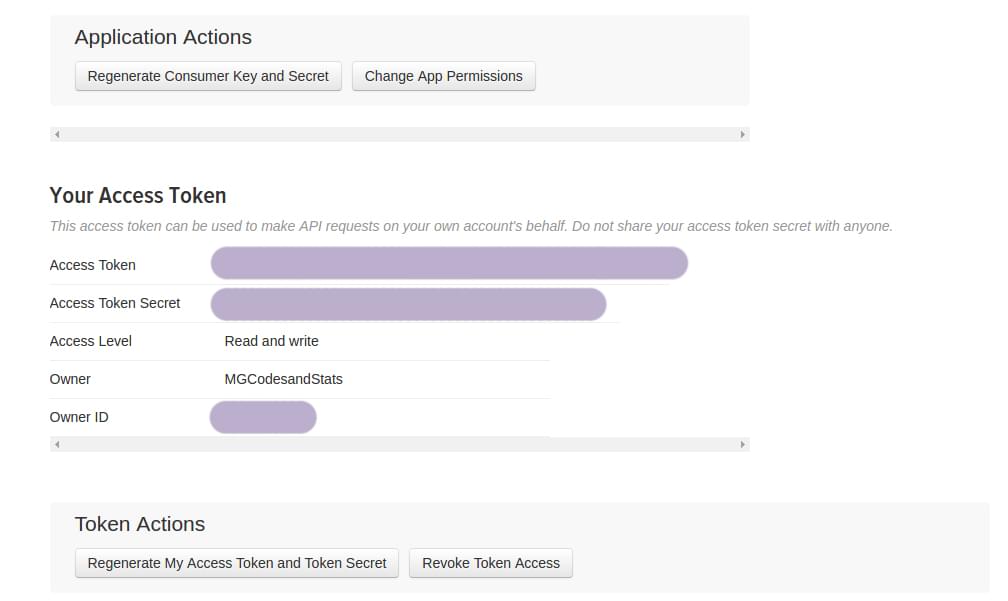
Сначала мы устанавливаем библиотеку python-twitter в наш терминал следующим образом:
pip install python twitter После этого мы импортируем библиотеку Twitter и вводим учетные данные следующим образом:
import twitter api = twitter.Api(consumer_key='your_consumer_key', consumer_secret='your_consumer_secret', access_token_key='your_access_token_key', access_token_secret='your_access_token_secret')
print(api.VerifyCredentials())
Как только введены правильные учетные данные, соединение с API завершено, и теперь мы можем контролировать нашу учетную запись Twitter через платформу Python!
2. Скачать пользовательскую временную шкалу
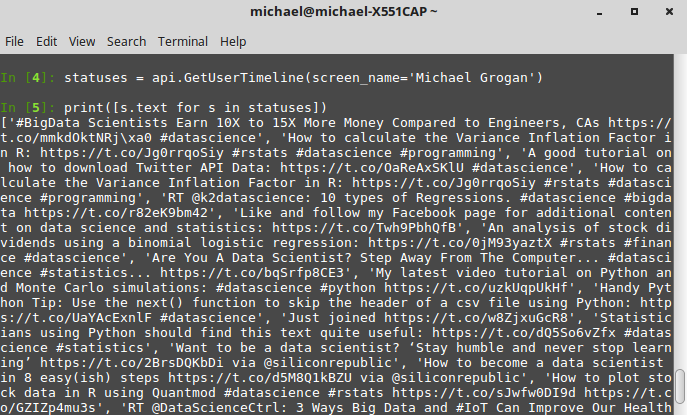
Теперь, когда мы подключили Python к API Twitter, мы можем приступить к удаленному использованию различных функций Twitter. Например, если мы хотим загрузить пользовательскую временную шкалу твитов, мы делаем это с помощью api.GetUserTimeline как api.GetUserTimeline ниже (и указываем имя экрана для соответствующей учетной записи), а затем с помощью функции print() для отображения результатов:
statuses = api.GetUserTimeline(screen_name=) print([s.text for s in statuses])
После того, как мы ввели выше, мы видим соответствующую временную шкалу, отображаемую в интерфейсе Python:
3. Скачать подписку и подписку
Библиотека Twitter также позволяет нам загружать список учетных записей, за которыми следует конкретный пользователь, а также учетные записи, которые являются подписчиками этого конкретного пользователя. Чтобы сделать это, мы используем api.GetFriends() для первого и api.GetFollowers() для второго:
users = api.GetFriends() print([u.name for u in users])
followers = api.GetFollowers() print([f.name for f in followers])

Обратите внимание, что мы также можем установить верхнюю границу для количества пользователей, которых мы хотим получить. Например, если мы хотим получить 100 подписчиков для любого конкретного аккаунта, мы можем сделать это, добавив переменную total_count в функцию следующим образом:
followers = api.GetFollowers(total_count=100) print([f.name for f in followers])
4. Опубликовать несколько твитов
Одна из замечательных особенностей использования Twitter API — возможность публиковать несколько твитов одновременно. В качестве примера, мы можем опубликовать два следующих твита одновременно, используя команду api.PostUpdate (опять же, используя функцию print() для подтверждения). Как только мы перейдем к соответствующему аккаунту Twitter, мы увидим, что оба твита были опубликованы:
status = api.PostUpdate('How to calculate the Variance Inflation Factor in R: http://www.michaeljgrogan.com/ordinary-least-squares-an-analysis-of-stock-returns/ #rstats #datascience #programming') print(status.text)

status = api.PostUpdate('#BigData Scientists Earn 10X to 15X More Money Compared to Engineers, CAs http://bit.ly/1NoAgto #datascience') print(status.text)

5. Поиск твитов
Функция GetSearch() включенная в библиотеку Twitter, является особенно мощным инструментом. Эта функция позволяет нам искать определенный термин в Twitter. Обратите внимание, что это относится ко всем пользователям, которые ввели определенный термин, а не просто к учетной записи, для которой мы предоставили учетные данные в Python.
В качестве примера давайте проведем поиск по термину «большие данные» в Python. Параметры, которые мы устанавливаем, — это те твиты с 21 ноября 2016 года, которые содержат термин, и мы решили ограничить количество твитов, передаваемых в 10:
api.GetSearch(term='bigdata', since=2016-11-21, count=10)

Обратите внимание, что мы можем настроить GetSearch() различными способами, в зависимости от того, как мы хотим извлечь данные. Например, хотя для потоковой передачи потребуется значительно больше времени, если не указана дата, мы также можем выбрать сбор твитов до 21 ноября 2016 года, которые содержат термин «большие данные», следующим образом:
api.GetSearch(term='bigdata', until=2016-11-21, count=10)
Следует помнить, что эта функция загружает данные за 7 дней до даты, указанной в переменной while.
Кроме того, мы не ограничиваемся просто поиском по терминам с GetSearch . Например, предположим, что мы хотим искать твиты по геолокации — в частности, твиты, отправленные с 18 ноября в радиусе 1 мили от Таймс-сквер, Нью-Йорк (обратите внимание, что расстояние может быть отформатировано в милях или километрах, используя ми или км соответственно):
api.GetSearch(geocode="40.758896,-73.985130,1mi", since=2016-11-18)
GetSearch() функцию GetSearch() , мы увидим, что Python возвращает следующие твиты (и, конечно, какое лучшее место, чтобы найти Дональда Трампа!):

Как эти данные могут быть использованы?
Одна из особых причин, по которой Python очень привлекателен для потоковой передачи данных в социальных сетях, — как упоминалось ранее, — возможность проводить углубленный анализ данных на собираемой нами информации.
Например, мы уже видели, как искать твиты по местоположению, используя GetSearch . Поскольку машинное обучение становится все более популярным среди ученых, занимающихся анализом тенденций в социальных сетях, одним из методов, который стал довольно популярным в этой области, является сетевой анализ. Это метод, при котором рассредоточенные данные (или узлы) могут фактически быть показаны для формирования тесных сетей — обычно с определенными узлами, оказавшимися в фокусе. В качестве примера, предположим, что мы должны были проанализировать 1000 самых популярных твитов в десяти разных местах по всему миру.
В случайный день мы можем обнаружить, что хэштеги в твитах в Лондоне значительно отличаются от хештегов в Нью-Йорке, хотя мы, вероятно, все еще видим некоторую согласованность между различными твитами в сети. Тем не менее, во время крупного мирового события, такого как ночь выборов в США или Brexit, когда Twitter обсуждает эту конкретную тему, обнаруживается, что сети, как правило, гораздо более сплочены, и, как следствие, появляется больше возможностей для анализа настроений в рамках таких сценарий — например, когда становится очевидным, кто выиграет президентство или что Великобритания голосует за выход из ЕС. Как правило, по мере поступления дополнительной информации в режиме реального времени кластер сетей будет виден по-разному, в зависимости от популярных твитов.
Это только одно из преимуществ Python. Хотя одно дело — использовать API для подключения к Twitter (что можно сделать на многих языках программирования), другое — возможность использовать аналитику для осмысленной сортировки этих данных. Методы машинного обучения могут быть использованы через Python как для анализа потоковых данных из социальных сетей, так и для значимых прогнозов на основе этих данных.
Вывод
Документация модуля содержит очень подробное описание различных функций, которые могут использоваться в Python для загрузки, фильтрации и манипулирования данными. В конечном счете, хотя мы также рассмотрели способы прямой публикации в Twitter с помощью API, описанные выше методы особенно полезны, когда речь идет о анализе тенденций, таких как популярность хэштегов, частота поисковых запросов по местоположению и так далее. В связи с этим, взаимодействие с Twitter через Python особенно полезно для тех, кто хочет внедрить методы анализа данных в собранную информацию.
Конечно, взаимодействие API с Twitter может осуществляться на разных языках, в зависимости от вашей конечной цели. Если целью является веб-разработка или дизайн, то лучшим выбором будет PHP или Ruby. Однако, если ваша цель состоит в том, чтобы использовать данные, полученные из Twitter, для проведения содержательного анализа, то Python находится в своей собственной лиге. В этом контексте я настоятельно рекомендую Python, когда дело доходит до серьезного перебора чисел в Твиттере.