Эта статья была первоначально опубликована на MongoDB . Спасибо за поддержку партнеров, которые делают возможным использование SitePoint.
Понимание взаимосвязей между различными внутренними кешами и производительностью диска, а также того, как эти взаимосвязи влияют на производительность базы данных и приложений, может оказаться сложной задачей. Мы использовали тест YCSB, варьируя рабочий набор (количество документов, использованных для теста) и производительность диска, чтобы лучше показать, как они связаны. При рассмотрении результатов мы рассмотрим некоторые внутренние компоненты MongoDB, чтобы улучшить понимание общих шаблонов использования базы данных.
Ключевые вынос
- Знание базовой производительности диска важно для понимания общей производительности базы данных.
- Высокое ожидание и использование диска указывают на узкое место на диске.
- WiredTiger IO является случайным.
- Запрос, нацеленный на один набор реплик, является однопоточным и последовательным.
- Производительность диска и размер рабочего набора тесно связаны.
Резюме
Основным фактором, влияющим на общую производительность системы, является то, как рабочий набор соотносится как с размером кэша подсистемы хранения (память, выделенная для хранения данных), так и с производительностью диска (что обеспечивает физический предел скорости доступа к данным).
Используя YCSB , мы исследуем взаимодействие между производительностью диска и размером кэша, демонстрируя, как эти два фактора могут влиять на производительность. В то время как YCSB использовался для этого тестирования, синтетические тесты не являются репрезентативными для рабочих нагрузок. Показатели задержки и пропускной способности, полученные этими методами, не соответствуют производительности. Для этих тестов мы использовали MongoDB 3.4.10, YCSB 0.14 и драйвер MongoDB 3.6.0. YCSB был сконфигурирован с 16 потоками и «равномерной» рабочей нагрузкой только для чтения.
Мы показываем, что размещение вашего рабочего набора внутри памяти обеспечивает оптимальную производительность приложения и, как и в случае любой базы данных, превышение этого лимита отрицательно влияет на задержку и общую пропускную способность.
Понимание метрик диска
Существует четыре важных показателя при рассмотрении производительности диска:
- Пропускная способность диска или количество запросов, умноженное на размер запроса. Обычно это измеряется в мегабайтах в секунду. Производительность произвольного чтения и записи в диапазоне 4 КБ является наиболее представительной из стандартных рабочих нагрузок базы данных. Обратите внимание, что многие облачные провайдеры ограничивают пропускную способность диска или пропускную способность.
- Дисковая задержка. В Linux это представляется как
awaitДля твердотельных накопителей задержки обычно не превышают 3 мс. Жесткие диски обычно выше 7 мс. Высокие задержки указывают на то, что диски не справляются с заданной рабочей нагрузкой. - Дисковые IOPS (Операции ввода / вывода в секунду).
iostattpsДанный облачный провайдер может гарантировать определенное количество операций ввода-вывода в секунду для данного диска. Если вы достигнете этого порога, любые дальнейшие обращения будут поставлены в очередь, что приведет к узкому месту на диске. Устройство NVMe, подключенное к высокопроизводительному PCIe, может предложить 1 500 000 операций ввода-вывода в секунду, в то время как типичный жесткий диск может поддерживать только 150 операций ввода-вывода в секунду. - Использование диска. Об этом сообщает
utiliostatLinux имеет несколькоqueuesИспользование указывает, какой процент этих очередей занят в данный момент времени. Хотя это число может сбивать с толку, оно является хорошим показателем общего состояния диска.
Тестирование производительности диска
Хотя облачные провайдеры могут предоставить порог IOPS для данного тома и диска, а производители дисков публикуют ожидаемые показатели производительности, фактические результаты в вашей системе могут отличаться. Если наблюдаемая производительность диска находится под вопросом, выполнение IO-теста может быть очень полезным.
Обычно мы проводим тестирование с помощью fio , гибкого тестера ввода-вывода. Мы выполнили тесты на 10 ГБ данных, ioengine от psync, и с чтениями в диапазоне от 4 до 32 КБ. Хотя настройки fio по умолчанию не отражают рабочую нагрузку WiredTiger, мы обнаружили, что эта конфигурация является хорошим приближением к использованию диска WiredTiger.
Все тесты были повторены в трех дисковых сценариях:
Сценарий 1
Настройки диска по умолчанию, предоставляемые томом AWS c5 io1 100 ГБ. 5000 IOPS
- 1144 операций ввода-вывода в секунду / 5025 физических операций чтения в секунду / загрузка 99,85%
Сценарий 2
Ограничение диска до 600 IOPS и задержка 7 мс. Это должно отражать производительность типичного RAID10 SAN с жесткими дисками
- 134 IOPS / 150 физических чтений в секунду / 95,72% утилит
Сценарий 3
Дальнейшее ограничение диска до 150 IOPS с задержкой 7 мс. Это должно моделировать товарный вращающийся жесткий диск.
- 34 IOPS / 150 физических чтений в секунду / 98,2% использования
Как обслуживается запрос с диска?
Механизм хранения WiredTiger выполняет свое собственное кэширование. По умолчанию размер кэша WiredTiger составляет 50% от системной памяти минус 1 ГБ, чтобы обеспечить достаточное пространство для других системных процессов, кэша файловой системы и внутренних операций MongoDB, которые потребляют дополнительную память, такую как создание индексов, выполнение в сортировке памяти, дедупликация результатов. , оценка текста, обработка соединений и агрегации. Чтобы предотвратить снижение производительности из полностью заполненного кеша, WiredTiger автоматически начинает извлекать данные из кеша, когда загрузка превышает 80%. Для наших тестов это означает, что эффективный размер кэша составляет (7634–1024 МБ) * .5 * .8 или 2644 МБ.
Все запросы обслуживаются из кеша WiredTiger. Это означает, что запрос приведет к тому, что индексы и документы будут считаны с диска через кеш файловой системы в кеш WiredTiger перед возвратом результатов. Если запрошенные данные уже находятся в кэше, этот шаг пропускается.
WiredTiger хранит документы с алгоритмом сжатия snappy по умолчанию. Любые данные, считанные из кэша файловой системы, сначала распаковываются, а затем сохраняются в кэше WiredTiger. Индексы используют префиксное сжатие по умолчанию и сжимаются как на диске, так и внутри кэша WiredTiger.
Кэш файловой системы — это структура операционной системы, предназначенная для хранения часто используемых файлов в памяти для ускорения доступа. Linux очень агрессивен в кэшировании файлов и будет пытаться использовать всю свободную память с кешем файловой системы. Если требуется дополнительная память, кэш файловой системы высвобождается, чтобы выделить больше памяти для приложений.
Вот анимированная графика, показывающая доступ к диску для коллекции YCSB, полученной в результате 100 операций чтения YCSB. Каждая операция — это отдельная находка для предоставления _id для одного документа.
Верхний левый угол представляет первый байт в файле коллекции WiredTiger. Расположение диска увеличивается с правой стороны и оборачивается. Каждая строка представляет сегмент размером 3,5 МБ в файле коллекции WiredTiger. Доступы упорядочены по времени и представлены кадром анимации. Доступы представлены в красных и зеленых полях, чтобы выделить текущий доступ к диску.

3,5 МБ против 4 КБ
Здесь мы видим файл данных для нашей коллекции, считанный в память. Поскольку данные хранятся в деревьях B +, нам может потребоваться найти местоположение на диске нашего документа (меньший доступ), посетив одно или несколько мест на диске, прежде чем наш документ будет найден и прочитан (более широкий доступ).
Это демонстрирует типичные шаблоны доступа к запросу MongoDB — документы вряд ли будут находиться близко друг к другу на диске. Это также показывает, что весьма маловероятно, что документы, даже если они вставлены друг за другом, будут располагаться на последовательных дисках.
Механизм хранения WiredTiger предназначен для «полного чтения»: он выдаст чтение для всех данных, которые ему нужны одновременно. Это приводит к нашей рекомендации ограничить опережающее чтение диска для развертываний WiredTiger до нуля, так как при последующем доступе вряд ли будут использованы дополнительные данные, полученные при опережающем чтении.
Рабочий набор помещается в кэш
Для нашего первого набора тестов мы установили количество записей равным 2 миллионам, в результате чего общий размер данных и индексов составил 2,43 ГБ, или 92% кеша.
Здесь мы видим сильную производительность сценария 1 76,113 запросов в секунду. Проверяя статистику кеша файловой системы, мы наблюдаем частоту обращений к кешу WiredTiger, равную 100%, без обращений и нулевых байтов, считываемых в кеш файловой системы, что означает, что во время этого теста не требуется дополнительный ввод-вывод.
Неудивительно, что в сценариях 2 и 3 изменение производительности диска (добавление 7 мс задержки и ограничение числа iops до 600 или 150) сказалось на пропускной способности минимально (69 579,5 и 70 252 операций в секунду соответственно).
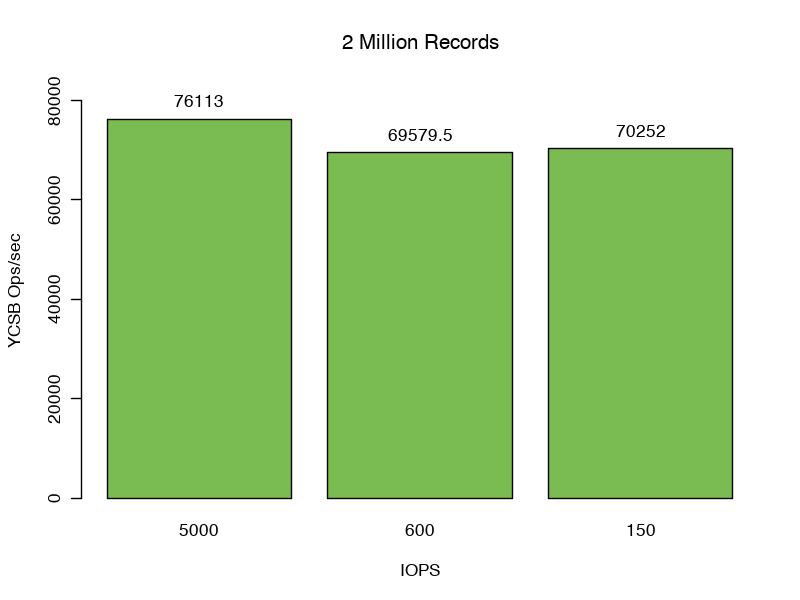
Наши задержки отклика 99% для всех трех тестов составляют от 0,40 до 0,44 мс.
Рабочий набор больше, чем WiredTiger Cache, но все еще помещается в кэш файловой системы
Современные операционные системы кэшируют часто используемые файлы для повышения производительности чтения. Поскольку файл уже находится в памяти, доступ к кэшированным файлам не приводит к физическому чтению. cachedfree
Когда мы увеличиваем количество записей с 2 миллионов до 3 миллионов, мы увеличиваем общий объем данных и индексов до 3,66 ГБ, что на 38% больше, чем можно обслуживать исключительно из кэша WiredTiger.
Метрики очевидны, мы читаем в среднем 548 Мбит / с в кеш WiredTiger, но мы можем наблюдать частоту обращений 99,9% при проверке метрик кеша файловой системы.
В этом тесте мы начинаем видеть снижение производительности, выполняя только 66 720 операций в секунду по сравнению с нашей базовой линией, что представляет собой снижение на 8% по сравнению с нашим предыдущим тестом, обслуживаемым исключительно из кэша WiredTiger.
Как и ожидалось, снижение производительности диска в этом случае не оказывает существенного влияния на нашу общую пропускную способность (64 484 и 64 229 операций соответственно). В случаях, когда документы являются более сжимаемыми, или процессор является ограничивающим фактором, чтение штрафа из кэша файловой системы будет более выраженным.

Мы отмечаем 54% увеличение наблюдаемой задержки p99 до .53 — .55ms.
Рабочий набор чуть больше, чем WiredTiger и кэш файловой системы
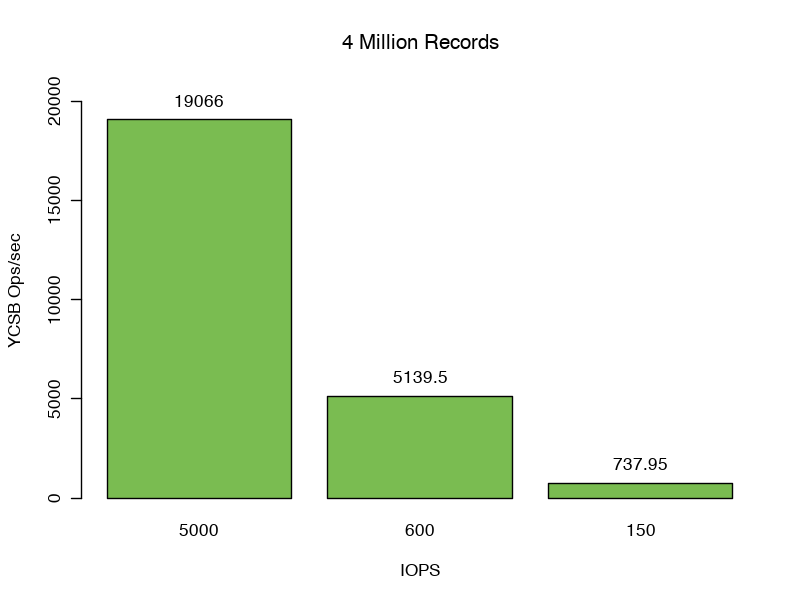
Мы установили, что кэши WiredTiger и файловой системы работают вместе, чтобы предоставлять данные для обслуживания наших запросов. Однако когда мы увеличиваем количество записей с 3 до 4 миллионов, мы больше не можем использовать эти кэши исключительно для обслуживания запросов. Наш объем данных увеличивается до 4,8 ГБ или на 82% больше, чем наш кэш WiredTiger.
Здесь мы читаем в кеш WiredTiger со скоростью 257,4 Мбит / с. Наша частота обращений к кешу файловой системы снижается до 93-96%, что означает, что 4-7% наших операций чтения приводят к физическим чтениям с диска.
Изменение доступных операций ввода-вывода в секунду и задержки диска оказывает огромное влияние на производительность этого теста.
Задержки отклика 99-го процентиля еще больше возрастают. Сценарий 1: 19 мс, сценарий 2: 171 мс и сценарий 3: 770 мс — увеличение в 43x, 389x и 1751x по сравнению со случаем в кэше.
Мы видим снижение производительности на 75%, когда MongoDB обеспечивает полные 5000 iops по сравнению с нашим более ранним тестом, который полностью помещается в кэш. Сценарии 2 и Сценарий 3 достигли 5139,5 и 737,95 операций в секунду соответственно, дополнительно демонстрируя узкое место ввода-вывода.
Рабочий набор гораздо больше, чем WiredTiger и кэш файловой системы
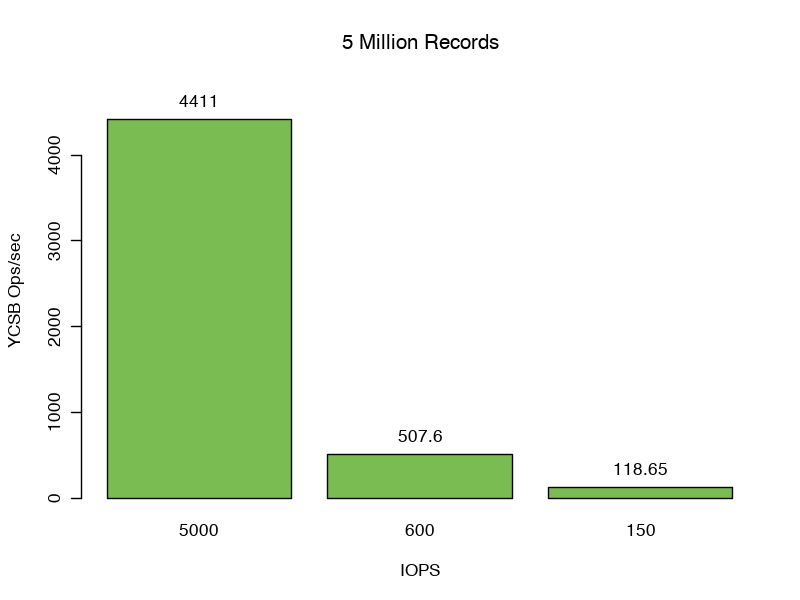
Перемещая до 5 миллионов записей, мы увеличиваем размер данных и индексов до 6,09 ГБ, что больше, чем объединенные кэши WiredTiger и файловой системы. Мы видим падение пропускной способности ниже нашего IOPS. В этом случае мы все еще обслуживаем 81% операций чтения WiredTiger из кэша файловой системы, но переполнения операций чтения с диска насыщают наш ввод-вывод. Мы видим 71, 8.3 и 1.9 Мбит / с, прочитанные в кеш файловой системы для этого теста.
Задержки отклика 99-го процентиля еще больше возрастают. Сценарий 1: 22 мс, сценарий 2: 199 мс и Senario 3: 810 мс, увеличившись в 52x, 454x и 1841x по сравнению с задержками ответа в кэше. Здесь, изменение IOPS диска значительно влияет на нашу пропускную способность.
Резюме
В этой серии тестов мы демонстрируем два основных момента.
- Если рабочий набор помещается в кэш, производительность диска не сильно влияет на производительность приложения.
- Когда рабочий набор превышает доступную память, производительность диска быстро становится ограничивающим фактором для пропускной способности.
Понимание того, как MongoDB использует как память, так и диски, является важной частью как определения размеров развертывания, так и понимания производительности. Внутренняя работа механизма хранения WiredTiger пытается максимально полно использовать оборудование, но память и диск являются двумя критически важными элементами инфраструктуры, способствующими общим характеристикам производительности вашей рабочей нагрузки.