HTTP означает протокол передачи гипертекста. Это протокол уровня приложения без связи с состоянием, предназначенный для связи между распределенными системами, и является основой современной сети. Как веб-разработчик, мы все должны хорошо понимать этот протокол.
Давайте рассмотрим этот мощный протокол через призму веб-разработчика. Мы рассмотрим тему в двух частях. В этой первой записи мы рассмотрим основы и наметим различные заголовки запросов и ответов. В следующей статье мы рассмотрим конкретные части HTTP, а именно: кэширование, обработку соединений и аутентификацию.
Хотя я упомяну некоторые детали, связанные с заголовками, лучше вместо этого проконсультироваться с RFC ( RFC 2616 ) для углубленного освещения. Я буду указывать на конкретные части RFC на протяжении всей статьи.
Ищете быстрое решение?
Если у вас возникли проблемы с ошибкой HTTP в WordPress, которую нужно исправить, вы можете заказать исправление ошибки Express HTTP в Envato Studio и исправить ее за один день всего за 50 долларов.

Основы HTTP
HTTP обеспечивает связь между различными хостами и клиентами и поддерживает различные конфигурации сети.
Чтобы сделать это возможным, он предполагает очень мало о конкретной системе и не сохраняет состояния между различными обменами сообщениями.
Это делает HTTP протоколом без сохранения состояния . Связь обычно происходит по TCP / IP, но может использоваться любой надежный транспорт. Порт по умолчанию для TCP / IP — 80 , но можно использовать и другие порты.
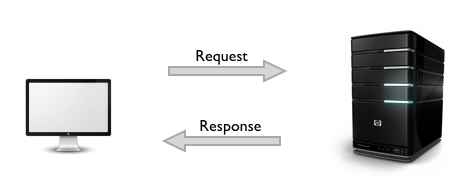
Пользовательские заголовки также могут быть созданы и отправлены клиентом.
Связь между хостом и клиентом происходит через пару запрос / ответ . Клиент инициирует сообщение HTTP-запроса, которое, в свою очередь, обслуживается ответным HTTP-сообщением. Мы рассмотрим эту фундаментальную пару сообщений в следующем разделе.
Текущая версия протокола HTTP / 1.1 , которая добавляет несколько дополнительных функций к предыдущей версии 1.0. Наиболее важными из них, на мой взгляд, являются постоянные соединения , частичное кодирование передачи и мелкозернистые заголовки кэширования . Мы кратко коснемся этих функций в этой статье; углубленное освещение будет предоставлено во второй части.
URL-адрес
В основе веб-коммуникаций лежит сообщение с запросом, которое отправляется через унифицированные указатели ресурсов (URL). Я уверен, что вы уже знакомы с URL, но для полноты картины я включу его сюда. URL-адреса имеют простую структуру, состоящую из следующих компонентов:
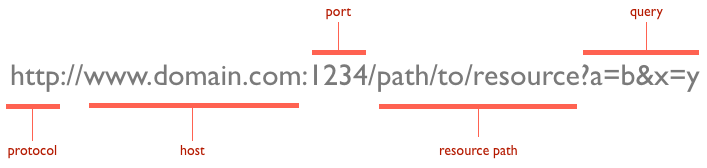
Протокол, как правило, http , но он также может быть https для безопасной связи. Порт по умолчанию — 80 , но он может быть установлен явно, как показано на рисунке выше. Путь к ресурсу — это локальный путь к ресурсу на сервере.
Глаголы
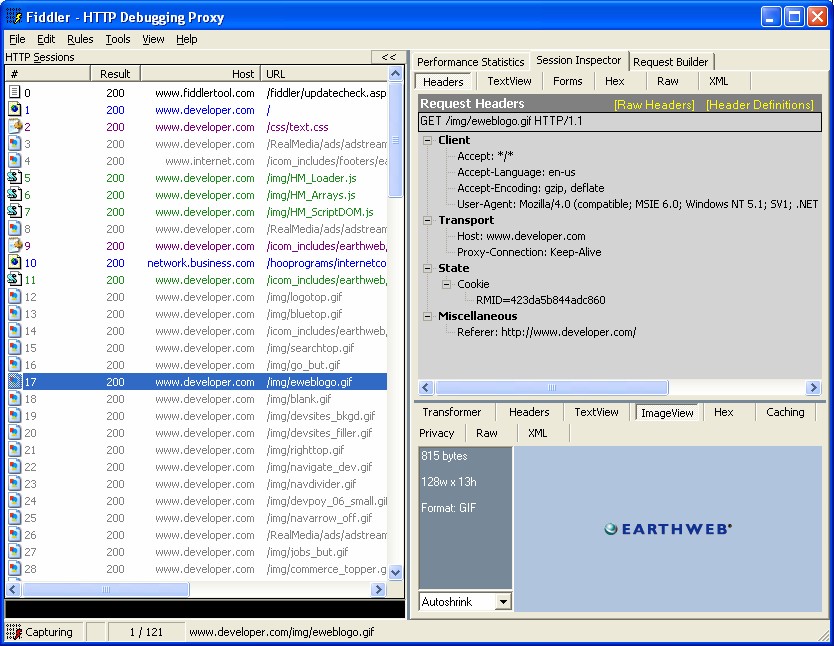
Существуют также прокси-серверы для отладки, такие как Fiddler для Windows и Charles Proxy для OSX.
URL-адреса показывают личность конкретного хоста, с которым мы хотим общаться, но действие, которое должно быть выполнено на хосте, указывается с помощью HTTP-глаголов. Конечно, есть несколько действий, которые клиент хотел бы, чтобы хост выполнял. HTTP формализован на нескольких, которые охватывают основы, которые универсально применимы для всех видов приложений.
Эти глаголы запроса:
- GET : получить существующий ресурс. URL содержит всю необходимую информацию, необходимую серверу для поиска и возврата ресурса.
- POST : создать новый ресурс. POST-запросы обычно несут полезную нагрузку, которая определяет данные для нового ресурса.
- PUT : обновить существующий ресурс. Полезная нагрузка может содержать обновленные данные для ресурса.
- УДАЛИТЬ : удалить существующий ресурс.
Вышеупомянутые четыре глагола являются самыми популярными, и большинство инструментов и сред явно предоставляют эти глаголы запроса. PUT и DELETE иногда считаются специализированными версиями глагола POST , и они могут быть упакованы как POST запросы с полезной нагрузкой, содержащей точное действие: создать , обновить или удалить .
HTTP использует некоторые менее используемые глаголы:
- HEAD : это похоже на GET, но без тела сообщения. Он используется для получения заголовков сервера для определенного ресурса, обычно для проверки изменения ресурса с помощью временных отметок.
- TRACE : используется для получения запросов от сервера в обратном направлении. Каждый промежуточный прокси-сервер или шлюз вводит свое IP или DNS-имя в поле заголовка
Via. Это может быть использовано в диагностических целях. - ОПЦИИ : используется для извлечения возможностей сервера. На стороне клиента его можно использовать для изменения запроса в зависимости от того, что может поддерживать сервер.
Коды состояния
С помощью URL и глаголов клиент может инициировать запросы к серверу. В ответ сервер отвечает кодами состояния и полезными данными сообщения. Код состояния важен и говорит клиенту, как интерпретировать ответ сервера. Спецификация HTTP определяет определенные диапазоны номеров для определенных типов ответов:
1xx: информационные сообщения
Все клиенты HTTP / 1.1 должны принимать заголовок
Transfer-Encoding.
Этот класс кодов был введен в HTTP / 1.1 и является чисто предварительным. Сервер может отправить сообщение Expect: 100-continue , сообщающее клиенту продолжить отправку оставшейся части запроса, или проигнорировать, если он уже отправил его. HTTP / 1.0 клиенты должны игнорировать этот заголовок.
2xx: успешно
Это говорит клиенту, что запрос был успешно обработан. Самый распространенный код — 200 ОК . Для запроса GET сервер отправляет ресурс в теле сообщения. Есть и другие, менее часто используемые коды:
- 202 Принят: запрос принят, но может не включать ресурс в ответ. Это полезно для асинхронной обработки на стороне сервера. Сервер может выбрать отправку информации для мониторинга.
- 204 Нет содержимого: в ответе нет тела сообщения.
- 205 Сбросить содержимое: указывает клиенту сбросить вид документа.
- 206 Частичное содержимое: указывает, что ответ содержит только частичное содержимое. Дополнительные заголовки указывают точный диапазон и информацию об истечении срока действия контента.
3xx: перенаправление
404 указывает, что ресурс недействителен и не существует на сервере.
Это требует от клиента дополнительных действий. Самым распространенным вариантом использования является переход на другой URL-адрес для получения ресурса.
- 301 Перемещено навсегда: ресурс теперь находится по новому URL.
- 303 См. Другое: ресурс временно расположен по новому URL. Заголовок ответа
Locationсодержит временный URL. - 304 Not Modified: сервер определил, что ресурс не изменился, и клиент должен использовать свою кэшированную копию. Это основывается на том факте, что клиент отправляет информацию
ETag(Enttity Tag), которая является хешем содержимого. Сервер сравнивает это с собственным вычисленнымETagдля проверки на наличие модификаций.
4xx: ошибка клиента
Эти коды используются, когда сервер считает, что клиент виноват, либо запрашивая неверный ресурс, либо делая неверный запрос. Самый популярный код в этом классе — 404 Not Found , с которым, я думаю, все будут отождествлять себя. 404 указывает, что ресурс недействителен и не существует на сервере. Другие коды в этом классе включают в себя:
- 400 Bad Request: запрос был искажен.
- 401 Несанкционированный: запрос требует аутентификации. Клиент может повторить запрос с заголовком
Authorization. Если клиент уже включил заголовокAuthorization, учетные данные были неправильными. - 403 Запрещено: сервер отказал в доступе к ресурсу.
- 405 Метод не разрешен: недопустимый глагол HTTP, используемый в строке запроса, или сервер не поддерживает этот глагол.
- 409 Конфликт: серверу не удалось выполнить запрос, потому что клиент пытается изменить ресурс, который новее, чем временная метка клиента. Конфликты возникают в основном для запросов PUT при совместном редактировании ресурса.
5xx: ошибка сервера
Этот класс кодов используется для указания сбоя сервера при обработке запроса. Наиболее часто используемый код ошибки — 500 Internal Server Error . Другие в этом классе:
- 501 Не реализовано : сервер еще не поддерживает запрошенную функциональность.
- 503 Сервис недоступен : это может произойти в случае сбоя внутренней системы на сервере или перегрузки сервера. Как правило, сервер даже не отвечает, и запрос истекает.
Форматы сообщений запроса и ответа
До сих пор мы видели, что URL, глаголы и коды состояния составляют основную часть пары HTTP-запросов / ответов.

Давайте теперь посмотрим на содержание этих сообщений. Спецификация HTTP гласит, что сообщение запроса или ответа имеет следующую общую структуру:
сообщение = <начальная строка> * (<Сообщение заголовка>) CRLF [<Тело сообщения>] <start-line> = Строка запроса | Status-Line <message-header> = Field-Name ':' Field-Value
Обязательно ставить новую строку между заголовками сообщений и телом. Сообщение может содержать один или несколько заголовков, которые широко классифицируются на:
- общие заголовки : это применимо как к сообщениям запроса, так и к ответам
- запрашивать конкретные заголовки .
- конкретные заголовки ответа .
- заголовки сущностей .
Тело сообщения может содержать полные данные объекта или оно может быть частичным, если используется кодирование по частям ( Transfer-Encoding: chunked ). Все клиенты HTTP / 1.1 должны принимать заголовок Transfer-Encoding .
Общие заголовки
Существует несколько заголовков (общих заголовков), которые совместно используются сообщениями запроса и ответа:
general-header = Cache-Control | соединение | Дата | Pragma | трейлер | Transfer-Encoding | Обновить | Через | Предупреждение
Мы уже видели некоторые из этих заголовков, в частности, Via и Transfer-Encoding . Мы рассмотрим Cache-Control и Connection во второй части.
Код состояния важен и говорит клиенту, как интерпретировать ответ сервера.
- Заголовок
Viaиспользуется в сообщении TRACE и обновляется всеми прерывистыми прокси и шлюзами. -
Pragmaсчитается настраиваемым заголовком и может использоваться для включения заголовков, связанных с реализацией. Наиболее часто используемая прагма-директива — этоPragma: no-cache, а на самом деле этоCache-Control: no-cacheв HTTP / 1.1. Это будет рассмотрено во второй части статьи. - Поле заголовка «
Dateиспользуется для отметки времени сообщения запроса / ответа. -
Upgradeиспользуется для переключения протоколов и обеспечения плавного перехода к более новому протоколу. -
Transfer-Encodingобычно используется для разбиения ответа на более мелкие части с помощью значенияTransfer-Encoding: chunked. Это новый заголовок в HTTP / 1.1 и позволяет потоковую передачу ответа клиенту вместо одной большой полезной нагрузки.
Заголовки сущностей
Сообщения запроса и ответа также могут включать в себя заголовки объекта для предоставления мета-информации о контенте (также называемого телом сообщения или объектом). Эти заголовки включают в себя:
заголовок объекта = Разрешить | Content-Encoding | Content-Language | Content-Length | Content-Location | Content-MD5 | Content-Range | Тип содержимого | Истекает | Последнее изменение
Все заголовки с префиксом Content предоставляют информацию о структуре, кодировке и размере тела сообщения. Некоторые из этих заголовков должны присутствовать, если объект является частью сообщения.
Заголовок Expires указывает метку времени истечения срока действия сущности. Интересно, что сущность «никогда не истекает» отправляется с отметкой времени в один год в будущее. Заголовок Last-Modified указывает метку времени последнего изменения для объекта.
Пользовательские заголовки также могут быть созданы и отправлены клиентом; по протоколу HTTP они будут рассматриваться как заголовки объектов.
Это действительно механизм расширения, и некоторые реализации клиент-сервер могут предпочесть обмениваться данными именно через эти заголовки расширения. Хотя HTTP поддерживает пользовательские заголовки, на самом деле он ищет заголовки запроса и ответа, которые мы рассмотрим далее.
Формат запроса
Сообщение запроса имеет ту же общую структуру, что и выше, за исключением строки запроса, которая выглядит следующим образом:
Строка запроса = метод SP URI SP HTTP-версия CRLF Метод = "ВАРИАНТЫ" | "ГОЛОВА" | "ПОЛУЧИТЬ" | "ПОЧТА" | "ПОЛОЖИЛ" | "УДАЛЯТЬ" | "TRACE"
SP — это разделитель пространства между токенами. HTTP-Version указывается как «HTTP / 1.1», а затем следует новая строка. Таким образом, типичное сообщение запроса может выглядеть так:
GET / статьи / http-основы HTTP / 1.1 Ведущий: www.articles.com Подключение: keep-alive Cache-Control: без кеша Прагма: без кеша Принять: текст / html, приложение / xhtml + xml, приложение / xml; q = 0,9, * / *; q = 0,8
Обратите внимание на строку запроса, за которой следует много заголовков запроса. Заголовок Host является обязательным для клиентов HTTP / 1.1. GET- запросы не имеют тела сообщения, но POST- запросы могут содержать данные сообщения в теле.
Заголовки запроса действуют как модификаторы сообщения запроса. Полный список известных заголовков запросов не слишком длинный и приведен ниже. Неизвестные заголовки обрабатываются как поля заголовка объекта.
заголовок запроса = Принять | Accept-Charset | Accept-Encoding | Accept-Language | авторизация | ожидать | Из | хозяин | If-Match | If-Modified-Since | If-None-Match | If-Range | Если-Unmodified-С | Max-Нападающие | Proxy-Authorization | Ассортимент | Referer | TE | User-Agent
Заголовки с префиксом Accept указывают на допустимые типы носителей, языки и наборы символов на клиенте. From , Host , Referer и User-Agent идентифицируют детали о клиенте, который инициировал запрос. Заголовки с префиксом If используются для того, чтобы сделать запрос более условным, и сервер возвращает ресурс, только если условие соответствует. В противном случае возвращается 304 Not Modified . Условие может быть основано на отметке времени или ETag (хэш сущности).
Формат ответа
Формат ответа аналогичен сообщению запроса, за исключением строки состояния и заголовков. Строка состояния имеет следующую структуру:
Строка состояния = HTTP-версия SP Статус-код SP Причина-фраза CRLF
- HTTP-версия отправляется как
HTTP/1.1 - Код состояния является одним из многих состояний, обсужденных ранее.
- Разум-фраза — это читаемая человеком версия кода состояния.
Типичная строка состояния для успешного ответа может выглядеть так:
HTTP / 1.1 200 ОК
Заголовки ответа также довольно ограничены, и полный набор приведен ниже:
response-header = Accept-Ranges | Возраст | ETag | Место расположения | Proxy-Authenticate | Retry-After | сервер | изменяться | WWW-Authenticate
-
Age— это время в секундах с момента создания сообщения на сервере. -
ETag— это хеш MD5 объекта, который используется для проверки изменений. -
Locationиспользуется при отправке перенаправления и содержит новый URL. -
Serverидентифицирует сервер, генерирующий сообщение.
До сих пор было много теории, поэтому я не буду винить вас за сонливость глаз. В следующих разделах мы познакомимся с инструментами, инфраструктурой и библиотеками.
Инструменты для просмотра HTTP-трафика
Существует множество инструментов для мониторинга HTTP-связи. Здесь мы перечислим некоторые из наиболее популярных инструментов.
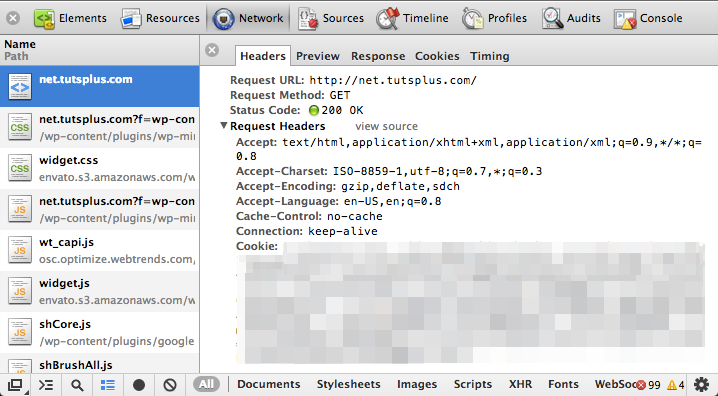
Несомненно, инспектор Chrome / Webkit является фаворитом среди веб-разработчиков:
Существуют также прокси-серверы для отладки, такие как Fiddler для Windows и Charles Proxy для OSX. Мой коллега Рей Банго написал отличную статью на эту тему.
Для командной строки у нас есть такие утилиты, как curl , tcpdump и tshark для мониторинга HTTP-трафика.
Использование HTTP в веб-фреймворках и библиотеках
Теперь, когда мы рассмотрели сообщения запроса / ответа, пришло время узнать, как библиотеки и фреймворки представляют его в форме API. В качестве примеров мы будем использовать ExpressJS для Node , Ruby on Rails и jQuery Ajax .
ExpressJS
Если вы создаете веб-серверы в NodeJS, велика вероятность, что вы рассматривали ExpressJS . ExpressJS изначально был вдохновлен веб-фреймворком Ruby, который называется Sinatra. Как и ожидалось, API также в равной степени под влиянием.
Поскольку мы имеем дело с серверной средой, при работе с сообщениями HTTP есть две основные задачи:
- Прочитать фрагменты URL и запросить заголовки.
- Напишите ответ заголовки и тело
Понимание HTTP имеет решающее значение для обеспечения чистого, простого и RESTful-интерфейса между двумя конечными точками.
ExpressJS предоставляет простой API для этого. Мы не будем раскрывать детали API. Вместо этого мы предоставим ссылки на подробную документацию по руководствам ExpressJS. Методы в API в большинстве случаев говорят сами за себя. Пример API, относящегося к запросу, приведен ниже:
- req.body : получить тело запроса.
- req.query : получить фрагмент запроса URL.
- req.originalUrl
- req.host : читает поле заголовка
Host. - req.accepts : читает допустимые MIME-типы на стороне клиента.
- req.get ИЛИ req.header : прочитать любое поле заголовка, переданное в качестве аргумента.
На пути к клиенту ExpressJS предоставляет следующий API ответа:
- res.status : установить явный код состояния.
- res.set : установить конкретный заголовок ответа.
- res.send : отправить HTML, JSON или октет-поток.
- res.sendFile : передать файл клиенту.
- res.render : визуализировать шаблон экспресс-просмотра.
- res.redirect : перенаправить на другой маршрут. Express автоматически добавляет код перенаправления по умолчанию 302.
Рубин на рельсах
Сообщения с запросами и ответами в основном одинаковы, за исключением первой строки и заголовков сообщений.
В Rails модули ActionController и ActionDispatch предоставляют API для обработки сообщений запроса и ответа.
ActionController предоставляет высокоуровневый API для чтения URL-адреса запроса, визуализации вывода и перенаправления на другую конечную точку. Конечная точка (он же маршрут) обрабатывается как метод действия. Большая часть необходимой контекстной информации внутри action-метода предоставляется через объекты request , response и params .
- params : предоставляет доступ к параметрам URL и данным POST.
- запрос : содержит информацию о клиенте, заголовки и URL.
- ответ : используется для установки заголовков и кодов состояния.
- render : визуализировать представления путем расширения шаблонов.
- redirect_to : перенаправить на другой action-метод или URL.
ActionDispatch обеспечивает детальный доступ к сообщениям запроса / ответа через ActionDispatch::Request и ActionDispatch::Response . Он предоставляет набор методов запроса для проверки типа запроса ( get?() , post?() , head?() , local?() ). Заголовки запросов могут быть напрямую доступны через метод request.headers() .
Что касается ответа, он предоставляет методы для установки cookies() , location=() и status=() . Если вы чувствуете себя авантюрным, вы также можете установить body=() и обойти систему рендеринга Rails.
JQuery Ajax
Поскольку jQuery — это, прежде всего, библиотека на стороне клиента, его Ajax API обеспечивает противоположность инфраструктуры на стороне сервера. Другими словами, он позволяет читать ответные сообщения и изменять сообщения запроса. jQuery предоставляет простой API через jQuery.ajax (настройки) :
beforeSend объект settings с beforeSend вызовом beforeSend , мы можем изменить заголовки запроса. Обратный вызов получает объект jqXHR (jQuery XMLHttpRequest), который предоставляет метод setRequestHeader() для установки заголовков.
$ .Ajax ({ URL: 'http://www.articles.com/latest', тип: 'GET', beforeSend: function (jqXHR) { jqXHR.setRequestHeader ('Accepts-Language', 'en-US, en'); } });
- Объект jqXHR также можно использовать для чтения заголовков ответов с помощью
jqXHR.getResponseHeader(). - Если вы хотите выполнить определенные действия для различных кодов состояния, вы можете использовать
statusCodeвызовstatusCode:
$ .Ajax ({ statusCode: { 404: функция () { оповещение («страница не найдена»); } } });
Резюме
Итак, подведем итог нашего краткого обзора протокола HTTP.
Мы рассмотрели структуру URL, глаголы и коды состояния: три столпа HTTP-коммуникации.
Сообщения с запросами и ответами в основном одинаковы, за исключением первой строки и заголовков сообщений. Наконец, мы рассмотрели, как можно изменять заголовки запросов и ответов в веб-платформах и библиотеках.
Понимание HTTP имеет решающее значение для обеспечения чистого, простого и RESTful-интерфейса между двумя конечными точками. В более широком масштабе это также помогает при проектировании вашей сетевой инфраструктуры и обеспечении отличного опыта для ваших конечных пользователей.
Во второй части мы рассмотрим обработку соединений, аутентификацию и кэширование! Увидимся тогда.