В этой последней главе мы рассмотрим аспекты безопасности HTTP, включая то, как идентифицировать пользователей, как работает аутентификация HTTP и почему в некоторых сценариях требуется HTTPS (безопасный HTTP). Попутно мы также немного узнаем о том, как управлять состоянием с помощью HTTP.
Сеть без гражданства (но с состоянием)
HTTP — это протокол без сохранения состояния, то есть каждая транзакция запрос-ответ не зависит от предыдущей или будущей транзакции. В протоколе HTTP нет ничего, что требовало бы от сервера хранить информацию о HTTP-запросе. Все, что нужно серверу — это генерировать ответ на каждый запрос. Каждый запрос будет содержать всю информацию, необходимую серверу для создания ответа.
Природа HTTP без сохранения состояния является одним из движущих факторов успеха сети. Многоуровневые сервисы, которые мы рассмотрели в предыдущей главе, такие сервисы, как кэширование, стали возможными (или, по крайней мере, более простыми), потому что каждое сообщение содержит всю информацию, необходимую для обработки сообщения. Прокси-серверы и веб-серверы могут проверять, преобразовывать и кэшировать сообщения. Без кеширования сеть не сможет масштабироваться для удовлетворения требований Интернета.
Тем не менее, большинство веб-приложений и сервисов, которые мы создаем поверх HTTP, имеют высокую степень состояния.
Банковское приложение будет хотеть, чтобы пользователь вошел в систему, прежде чем разрешить пользователю просматривать ресурсы, связанные с его учетной записью. Поскольку каждый запрос без сохранения состояния поступает для частного ресурса, приложение хочет убедиться, что пользователь уже прошел аутентификацию. Другой пример — когда пользователь хочет открыть учетную запись и заполняет формы в трехстраничном мастере. Приложение захочет убедиться, что первая страница мастера завершена, прежде чем разрешить пользователю отправить вторую страницу.
К счастью, существует множество вариантов сохранения состояния в веб-приложении. Один из подходов заключается во внедрении состояния в ресурсы, передаваемые клиенту, чтобы все состояния, требуемые приложением, возвращались при следующем запросе. Этот подход обычно требует некоторых скрытых полей ввода и лучше всего подходит для кратковременного состояния (например, состояния, необходимого для перемещения через трехстраничный мастер). Внедрение состояния в ресурс сохраняет все состояние внутри HTTP-сообщений, поэтому это очень масштабируемый подход, но он может усложнить программирование приложения.
Другой вариант — сохранить состояние на сервере (или за сервером). Эта опция необходима для состояния, которое должно быть долгое время. Допустим, пользователь отправляет форму для изменения своего адреса электронной почты. Адрес электронной почты всегда должен быть связан с пользователем, чтобы приложение могло взять новый адрес, проверить адрес и сохранить адрес в базе данных, файле или вызвать веб-службу, чтобы кто-то другой мог позаботиться о сохранении адреса. ,
Для серверного хранилища многие инфраструктуры веб-разработки, такие как ASP.NET, также предоставляют доступ к «пользовательскому сеансу». Сеанс может находиться в памяти или в базе данных, но разработчик может сохранять информацию в сеансе и извлекать информацию по каждому последующему запросу. Данные, хранящиеся в сеансе, ограничиваются отдельным пользователем (фактически, сеансом просмотра пользователя) и не используются несколькими пользователями.
Хранилище сессий имеет простую модель программирования и подходит только для кратковременного состояния, поскольку в конечном итоге сервер должен предположить, что пользователь покинул сайт или закрыл браузер, и сервер откажется от сеанса. Хранение сеанса, если оно хранится в памяти, может отрицательно повлиять на масштабируемость, поскольку последующие запросы должны отправляться на тот же сервер, где хранятся данные сеанса. Некоторые балансировщики нагрузки помогают поддерживать этот сценарий, реализуя «липкие сессии».
Вам может быть интересно, как сервер может отслеживать пользователя для реализации состояния сеанса. Если на сервер поступают два запроса, как сервер узнает, что это два запроса от одного пользователя или два разных пользователя делают один запрос?
В первые дни Интернета серверное программное обеспечение могло дифференцировать пользователей, просматривая IP-адрес сообщения с запросом. Однако в наши дни многие пользователи живут за устройствами, использующими трансляцию сетевых адресов, и по этой и другим причинам вы можете эффективно использовать несколько пользователей на одном IP-адресе. IP-адрес не является надежным методом дифференциации пользователей.
К счастью, есть более надежные методы.
Идентификация и файлы cookie
Сайты, которые хотят отслеживать пользователей, часто обращаются к файлам cookie . Файлы cookie определяются в RFC6265 ( http://tools.ietf.org/html/rfc6265 ), и этот RFC называется «Механизм управления состоянием HTTP». Когда пользователь впервые посещает веб-сайт, он может передать браузеру пользователя файл cookie с использованием заголовка HTTP. Затем браузер знает, что нужно отправлять cookie в заголовках каждого дополнительного запроса, который он отправляет на сайт. Предполагая, что веб-сайт поместил в cookie какой-то уникальный идентификатор, теперь сайт может отслеживать пользователя по мере того, как он или она делает запросы, и отличать одного пользователя от другого.
Прежде чем мы углубимся в детали того, как выглядят файлы cookie и как они ведут себя, стоит отметить пару ограничений. Во-первых, cookie-файлы могут идентифицировать пользователей в том смысле, что ваш cookie-файл отличается от моего cookie-файла, но cookie-файлы не аутентифицируют пользователей. Аутентифицированный пользователь обычно подтверждает свою личность, предоставляя такие учетные данные, как имя пользователя и пароль. Куки, о которых мы говорим до сих пор, просто дают нам некоторый уникальный идентификатор, чтобы отличать одного пользователя от другого, и отслеживать пользователя по мере поступления запросов на сайт.
Во-вторых, поскольку файлы cookie могут отслеживать действия пользователя, в некоторых кругах возникают проблемы с конфиденциальностью. Некоторые пользователи отключают файлы cookie в своих браузерах, то есть браузер отклоняет любые файлы cookie, отправленные сервером в ответ. Отключенные куки-файлы представляют собой проблему для сайтов, которые должны отслеживать пользователей, конечно, и альтернативы являются грязными. Например, один из подходов к «сеансам без файлов cookie» заключается в размещении идентификатора пользователя в URL. Сеансы без файлов cookie требуют, чтобы каждый URL, который сайт дает пользователю, содержал правильный идентификатор, и URL-адреса становились намного больше (именно поэтому этот метод часто называют методом «толстого URL»).
Настройка Cookies
Когда веб-сайт хочет дать пользователю cookie, он использует заголовок Set-Cookie в HTTP-ответе.
|
1
2
3
4
5
|
HTTP/1.1 200 OK
Content-Type: text/html;
Set-Cookie: fname=Scott$lname=Allen;
domain=.mywebsite.com;
…
|
В файле cookie показано три области информации. Три области разделены точками с запятой (;). Во-первых, есть одна или несколько пар имя-значение. Эти пары имя-значение ограничены знаком доллара ($) и очень похожи на то, как параметры запроса форматируются в URL. В примере файла cookie сервер хотел сохранить имя и фамилию пользователя в файле cookie. Вторая и третья области — это домен и путь соответственно. Позже мы вернемся к разговору о домене и пути.
Веб-сайт может помещать любую информацию, которая ему нравится, в файл cookie, хотя ограничение размера составляет 4 КБ. Однако многие веб-сайты вводят уникальный идентификатор пользователя, возможно, GUID. Сервер никогда не может доверять чему-либо, хранящемуся на клиенте, если он не защищен криптографически. Да, можно сохранить зашифрованные данные в файле cookie, но обычно проще хранить идентификатор.
|
1
2
3
|
HTTP/1.1 200 OK
Set-Cookie: GUID=00a48b7f6a4946a8adf593373e53347c;
domain=.msn.com;
|
Предполагая, что браузер настроен на прием куки, он будет отправлять куки на сервер при каждом последующем HTTP-запросе.
|
1
2
3
|
GET … HTTP/1.1
Cookie: GUID=00a48b7f6a4946a8adf593373e53347c;
…
|
Когда приходит идентификатор, серверное программное обеспечение может быстро найти любые связанные пользовательские данные из структуры данных в памяти, базы данных или распределенного кэша. Вы можете настроить большинство структур веб-приложений для управления файлами cookie и автоматического поиска состояния сеанса. Например, в ASP.NET объект Session предоставляет простой API для чтения и записи состояния сеанса пользователя. Как разработчики, нам никогда не нужно беспокоиться об отправке заголовка Set-Cookie или чтении входящих cookie-файлов, чтобы найти соответствующее состояние сеанса. За кулисами ASP.NET будет управлять cookie-файлами сеанса.
|
1
2
3
|
Session[«firstName»] = «Scott»;
…
var lastName = Session[«lastName»];
|
Опять же, стоит указать, что данные firstName и lastName хранящиеся в объекте сеанса, не попадают в cookie . Файл cookie содержит только идентификатор сеанса. Значения, связанные с идентификатором сеанса, являются безопасными на сервере. По умолчанию данные сеанса помещаются в структуру данных в памяти и остаются живыми в течение 20 минут. Когда в запросе поступает файл cookie сеанса, ASP.NET свяжет правильные данные сеанса с объектом Session после нахождения данных пользователя с использованием идентификатора, сохраненного в файле cookie. Если нет входящего куки с идентификатором сеанса, ASP.NET создаст его с заголовком Set-Cookie .
Одной из проблем безопасности идентификаторов сеансов является то, как они могут открыть возможность взлома сеанса другого пользователя. Например, если я использую такой инструмент, как Fiddler, для отслеживания HTTP-трафика, я могу увидеть заголовок Set-Cookie полученный с сервера с SessionID=12 внутри. Я мог бы догадаться, что какой-то другой пользователь уже имеет SessionID 11 и создать HTTP-запрос с этим идентификатором, просто чтобы посмотреть, смогу ли я украсть или просмотреть HTML-код, предназначенный для другого пользователя. Для решения этой проблемы большинство веб-приложений будут использовать большие случайные числа в качестве идентификаторов (ASP.NET использует 120 бит случайности). Идентификатор сеанса ASP.NET выглядит следующим образом, что затрудняет угадывание идентификатора сеанса другого человека.
|
1
2
|
Set-Cookie: ASP.NET_SessionId=en5yl2yopwkdamv2ur5c3z45;
path=/;
|
HttpOnly Cookies
Другая проблема безопасности, связанная с файлами cookie, заключается в том, насколько они уязвимы для атаки межсайтовых сценариев (XSS). При атаке XSS злоумышленник внедряет вредоносный код JavaScript в чужой веб-сайт. Если другой веб-сайт отправляет вредоносный сценарий своим пользователям, этот вредоносный сценарий может изменить или проверить и украсть информацию cookie (что может привести к перехвату сеанса или, что еще хуже).
Чтобы бороться с этой уязвимостью, Microsoft ввела флаг HttpOnly (замеченный в последнем примере Set-Cookie ). Флаг HttpOnly указывает агенту пользователя не разрешать коду сценария обращаться к cookie. Файл cookie существует только для «HTTP», то есть в заголовке каждого сообщения HTTP-запроса. Браузеры, которые реализуют HttpOnly , не позволяют JavaScript читать или записывать cookie на клиенте.
Типы печенья
Куки, которые мы видели до сих пор, являются сессионными . Сессионные куки существуют для одного пользовательского сеанса и уничтожаются, когда пользователь закрывает браузер. Постоянные куки могут пережить один сеанс просмотра, и пользовательский агент сохранит куки на диск. Вы можете выключить компьютер и вернуться через неделю, зайти на ваш любимый веб-сайт, и постоянный файл cookie все еще будет доступен для первого запроса.
Единственное различие между ними заключается в том, что постоянному файлу cookie требуется значение Expires .
|
1
|
Set-Cookie: name=value;
|
Сеансовый cookie-файл может явно добавить атрибут Discard к cookie-файлу, но без значения Expires пользовательский агент должен в любом случае удалить cookie-файл.
Пути к файлам cookie и домены
До сих пор мы говорили, что после того, как веб-сайт установит файл cookie, он будет перемещаться на веб-сайт с каждым последующим запросом (при условии, что срок действия файла cookie не истек). Однако не все файлы cookie отправляются на каждый сайт. Единственные файлы cookie, которые пользовательский агент должен отправлять на сайт, — это файлы cookie, предоставляемые пользовательскому агенту тем же сайтом. Для файлов cookie от amazon.com не имеет смысла отправлять HTTP-запрос на google.com. Такое поведение может только открыть дополнительные проблемы безопасности и конфиденциальности. Если вы установили файл cookie в ответ на запрос к www.server.com, полученный файл cookie будет передаваться только в запросах к www.server.com.
Веб-приложение также может изменить область действия cookie, чтобы ограничить использование cookie конкретным хостом или доменом и даже определенным путем к ресурсу. Веб-приложение управляет областью, используя атрибуты domain и path .
|
1
2
3
|
HTTP/1.1 200 OK
Set-Cookie: name=value;
…
|
Атрибут domain позволяет cookie охватывать субдомены. Другими словами, если вы установили файл cookie с сайта www.server.com, пользовательский агент доставит файл cookie только на сайт www.server.com. Домен в предыдущем примере также позволяет куки-файлам перемещаться по любому URL-адресу в домене server.com, включая images.server.com, help.server.com и просто простой server.com. Вы не можете использовать атрибут домена для охвата доменов, поэтому установка домена .microsoft.com в ответ на .server.com недопустима, и пользовательский агент должен отклонить файл cookie.
Атрибут path может ограничивать cookie-файлом определенным путем к ресурсу. В предыдущем примере файл cookie отправляется на сайт server.com только в том случае, если URL-адрес запроса указывает на /stuff , или на местоположение под /stuff , например /stuff/images . Параметры пути могут помочь организовать файлы cookie, когда несколько команд создают веб-приложения по разным путям.
Печенье Недостатки
Файлы cookie позволяют веб-сайтам хранить информацию в клиенте, и эта информация будет возвращаться на сайты в последующих запросах. Преимущества веб-разработки огромны, потому что куки позволяют нам отслеживать, какой запрос принадлежит какому пользователю. Но у файлов cookie есть некоторые проблемы, о которых мы уже говорили.
Как мы уже упоминали ранее, файлы cookie были уязвимы для атак XSS, а также получили плохую огласку, когда сайты (особенно рекламные сайты) используют сторонние файлы cookie для отслеживания пользователей в Интернете. Сторонние файлы cookie — это файлы cookie, которые устанавливаются из домена, отличного от домена в адресной строке браузера. Сторонние файлы cookie имеют такую возможность, поскольку многие веб-сайты при отправке ресурса страницы клиенту будут содержать ссылки на сценарии или изображения с других URL-адресов. Запросы, которые переходят на другие URL-адреса, позволяют другим сайтам устанавливать файлы cookie.
Например, домашняя страница на server.com может включать <script> с источником, установленным на bigadvertising.com. Это позволяет bigadvertising.com доставлять cookie-файлы, пока пользователь просматривает контент с server.com. Файл cookie может вернуться только на bigadvertising.com, но если bigadvertising.com использует достаточное количество веб-сайтов, Big Advertising может начать профилировать отдельных пользователей и посещаемые ими сайты. Большинство веб-браузеров позволяют отключать сторонние файлы cookie (но они включены по умолчанию).
Однако два главных недостатка файлов cookie — это то, как они мешают кешированию и как они передают данные при каждом запросе. Любой ответ с заголовком Set-Cookie не должен кэшироваться, по крайней мере, не заголовки, так как это может помешать идентификации пользователя и создать проблемы безопасности. Кроме того, имейте в виду, что все, что хранится в куки-файле, видно по мере его прохождения по сети (и в случае постоянного куки-файла, когда оно находится в файловой системе). Поскольку мы знаем, что существует множество устройств, которые могут прослушивать и интерпретировать HTTP-трафик, cookie никогда не должен хранить конфиденциальную информацию. Даже идентификаторы сеансов опасны, потому что если кто-то может перехватить идентификатор другого пользователя, он или она может украсть данные сеанса с сервера.
Даже со всеми этими недостатками, куки не исчезают. Иногда нам требуется состояние для перемещения по HTTP, и куки-файлы предоставляют эту возможность простым, в основном прозрачным способом. Другой возможностью, которая нам иногда нужна, является возможность аутентификации пользователя. Мы обсудим функции аутентификации дальше.
Аутентификация
Процесс аутентификации вынуждает пользователя подтвердить свою личность, введя имя пользователя и пароль, или электронное письмо и ПИН-код, или другой тип учетных данных.
На сетевом уровне аутентификация обычно следует формату запроса / ответа. Клиент запросит безопасный ресурс, а сервер запросит у клиента аутентификацию. Затем клиент должен отправить еще один запрос и включить учетные данные для проверки подлинности на сервере. Если учетные данные хороши, запрос будет выполнен успешно.
Расширяемость HTTP позволяет HTTP поддерживать различные протоколы аутентификации. В этом разделе мы кратко рассмотрим топ-5: базовый, дайджест, Windows, формы и OpenID. Из этих пяти только два являются «официальными» в спецификации HTTP — протоколы базовой и дайджест-аутентификации. Сначала мы рассмотрим эти два.
Базовая аутентификация
При базовой аутентификации клиент сначала запрашивает ресурс с обычным HTTP-сообщением.
|
1
2
|
GET http://localhost/html5/ HTTP/1.1
Host: localhost
|
Веб-серверы позволят вам настроить доступ к определенным файлам и каталогам. Вы можете разрешить доступ всем анонимным пользователям или ограничить доступ, чтобы только определенные пользователи или группы могли иметь доступ к файлу или каталогу. Что касается предыдущего запроса, давайте представим, что сервер настроен так, что только определенные пользователи могут просматривать ресурс /html5/ . В этом случае сервер выдаст запрос аутентификации.
|
1
2
|
HTTP/1.1 401 Unauthorized
WWW-Authenticate: Basic realm=»localhost»
|
Код состояния 401 сообщает клиенту, что запрос не авторизован. Заголовок WWW-Authenticate указывает клиенту собрать учетные данные пользователя и повторить попытку. Атрибут realm предоставляет агенту пользователя строку, которую он может использовать в качестве описания для защищенной области. Что будет дальше, зависит от пользовательского агента, но большинство браузеров могут отображать пользовательский интерфейс для ввода учетных данных.
Имея учетные данные, браузер может отправить другой запрос на сервер. Этот запрос будет включать заголовок Authorization .
|
1
2
|
GET http://localhost/html5/ HTTP/1.1
Authorization: Basic bm86aXdvdWxkbnRkb3RoYXQh
|
Значением заголовка авторизации является имя пользователя и пароль клиента в кодировке base 64. По умолчанию обычная проверка подлинности небезопасна , поскольку любой пользователь с декодером base 64, который может просмотреть сообщение, может украсть пароль пользователя. По этой причине базовая аутентификация редко используется без использования безопасного HTTP, о чем мы поговорим позже.
Сервер должен декодировать заголовок авторизации и проверять имя пользователя и пароль в операционной системе или любой другой системе управления учетными данными, установленной на сервере. Если учетные данные совпадают, сервер может сделать обычный ответ. Если учетные данные не совпадают, сервер должен снова ответить с состоянием 401 .
Дайджест-аутентификация
Дайджест-аутентификация является улучшением по сравнению с базовой аутентификацией, поскольку она не передает пароли пользователей с использованием кодировки base 64 (которая, по сути, передает пароль в виде простого текста). Вместо этого клиент должен отправить дайджест пароля. Клиент вычисляет дайджест с использованием алгоритма хеширования MD5 с одноразовым номером, который сервер предоставляет во время проверки подлинности (одноразовый номер — это криптографическое число, используемое для предотвращения атак воспроизведения).
Ответ на дайджест-запрос аналогичен ответу на базовый запрос аутентификации, но с дополнительными значениями, поступающими с сервера в заголовке WWW-Authenticate для использования в криптографических функциях.
|
1
2
3
4
5
|
HTTP/1.0 401 Unauthorized
WWW-Authenticate: Digest realm=»localhost»,
qop=»auth,auth-int»,
nonce=»dcd98b7102dd2f0e8b11d0f600bfb0c093″,
opaque=»5ccc069c403ebaf9f0171e9517f40e41″
|
Дайджест-аутентификация лучше, чем обычная аутентификация, когда безопасный HTTP недоступен, но все еще далек от совершенства. Дайджест-проверка подлинности по-прежнему уязвима для атак типа «человек посередине», в которых кто-то перехватывает сетевой трафик.
Проверка подлинности Windows
Интегрированная аутентификация Windows не является стандартным протоколом аутентификации, но она популярна среди продуктов и серверов Microsoft. Хотя проверка подлинности Windows поддерживается многими современными браузерами (не только Internet Explorer), она не очень хорошо работает через Интернет или там, где находятся прокси-серверы. Вы найдете это распространенным на внутренних и интранет-сайтах, где существует сервер Microsoft Active Directory.
Аутентификация Windows зависит от базовых протоколов аутентификации, поддерживаемых Windows, включая NTLM и Kerberos. Этапы запроса / ответа проверки подлинности Windows очень похожи на то, что мы уже видели, но сервер будет указывать NTLM или Negotiate в заголовке WWW-Authenticate ( Negotiate — это протокол, который позволяет клиенту выбирать Kerberos или HTML).
|
1
2
|
HTTP/1.1 401 Unauthorized
WWW-Authenticate: Negotiate
|
Аутентификация Windows имеет преимущество в том, что она безопасна даже без использования безопасного HTTP и является ненавязчивой для пользователей Internet Explorer. IE автоматически аутентифицирует пользователя при вызове со стороны сервера и делает это, используя учетные данные пользователя, которые он или она использовали для входа в операционную систему Windows.
Аутентификация на основе форм
Проверка подлинности с помощью форм является наиболее популярным подходом к проверке подлинности пользователя через Интернет. WWW-Authenticate подлинности на основе форм не является стандартным протоколом проверки подлинности и не использует заголовки WWW-Authenticate или Authorization . Однако многие платформы веб-приложений предоставляют некоторую готовую поддержку для аутентификации на основе форм.
При проверке подлинности на основе форм приложение ответит на запрос безопасного ресурса анонимным пользователем, перенаправив пользователя на страницу входа. Перенаправление — это временное перенаправление HTTP 302. Как правило, запрашиваемый пользователем URL-адрес может быть включен в строку запроса местоположения перенаправления, чтобы после завершения входа в систему приложение могло перенаправить пользователя на защищенный ресурс, который он или она пытались получить.
|
1
2
|
HTTP/1.1 302 Found
Location: /Login.aspx?ReturnUrl=/Admin.aspx
|
Страница входа для проверки подлинности на основе форм представляет собой HTML-форму с входными данными для ввода пользователем учетных данных. Когда пользователь нажимает кнопку «Отправить», значения формы отправляются в пункт назначения, где приложение должно принять учетные данные и проверить их по записи в базе данных или операционной системе.
|
1
2
3
4
5
6
|
<form method=»post»>
…
<input type=»text» name=»username» />
<input type=»password» name=»password» />
<input type=»submit» value=»Login» />
</form>
|
Обратите внимание, что аутентификация на основе форм будет передавать учетные данные пользователя в виде простого текста, поэтому, как и обычная аутентификация, аутентификация на основе форм не является безопасной, если вы не используете безопасный HTTP. В ответ на сообщение POST с учетными данными (при условии, что учетные данные являются хорошими), приложение, как правило, перенаправляет пользователя обратно к защищенному ресурсу, а также устанавливает файл cookie, указывающий, что пользователь теперь аутентифицирован.
|
1
2
3
|
HTTP/1.1 302 Found
Location: /admin.aspx
Set-Cookie: .ASPXAUTH=9694BAB… path=/;
|
Для ASP.NET билет аутентификации ( .ASPXAUTH файла cookie .ASPXAUTH ) шифруется и хэшируется для предотвращения взлома. Однако без безопасного HTTP cookie может быть перехвачен, поэтому перехват сеанса остается потенциальной проблемой. Тем не менее, проверка подлинности форм остается популярной, поскольку она позволяет приложениям полностью контролировать процесс входа в систему и проверку учетных данных.
OpenID
Хотя проверка подлинности на основе форм дает приложению полный контроль над проверкой подлинности пользователя, многим приложениям этот уровень контроля не нужен. В частности, приложения не хотят управлять и проверять имена пользователей и пароли (и пользователи не хотят иметь разные имена пользователей и пароли для каждого веб-сайта). OpenID — это открытый стандарт для децентрализованной аутентификации. С OpenID пользователь регистрируется у провайдера идентификации OpenID, а провайдер идентификации является единственным сайтом, который должен хранить и проверять учетные данные пользователя. Вокруг много поставщиков OpenID, в том числе Google, Yahoo и Verisign.
Когда приложение должно аутентифицировать пользователя, оно работает с пользователем и поставщиком удостоверений пользователя. В конечном счете, пользователь должен проверить свое имя пользователя и пароль у провайдера идентификации, но приложение узнает, прошла ли аутентификация успешно, благодаря наличию криптографических токенов и секретов. Google имеет обзор процесса на своей веб- странице «Федеративный вход для пользователей учетной записи Google» ( https://developers.google.com/accounts/docs/OpenID ).
Хотя OpenID предлагает много потенциальных преимуществ по сравнению с аутентификацией форм, он столкнулся с отсутствием принятия из-за сложности в реализации, отладке и поддержании танца входа в систему OpenID. Мы должны надеяться, что наборы инструментов и инфраструктуры продолжают развиваться, чтобы упростить подход OpenID к аутентификации.
Безопасный HTTP
Ранее мы упоминали, что текстовые HTTP-сообщения с самоописанием являются одной из сильных сторон Интернета. Любой может прочитать сообщение и понять, что внутри. Но есть много сообщений, которые мы отправляем через Интернет, которые мы не хотим, чтобы кто-то еще видел. Мы обсудили некоторые из этих сценариев в этой книге. Например, мы не хотим, чтобы кто-то другой в сети видел наши пароли, но мы также не хотим, чтобы они видели номера наших кредитных карт или номера банковских счетов. Безопасный HTTP решает эту проблему, зашифровывая сообщения до того, как сообщения начинают передаваться по сети.
Безопасный HTTP также известен как HTTPS (потому что он использует схему https в URL-адресе вместо обычной схемы http ). Порт по умолчанию для HTTP — это порт 80, а порт по умолчанию для HTTPS — это порт 443. Браузер будет подключаться к нужному порту в зависимости от схемы (если только он не использует явный порт, который присутствует в URL-адресе). HTTPS работает с использованием дополнительного уровня безопасности в стеке сетевых протоколов. Уровень безопасности существует между уровнями HTTP и TCP и включает использование протокола безопасности транспортного уровня (TLS) или предшественника TLS, известного как уровень защищенных сокетов (SSL).
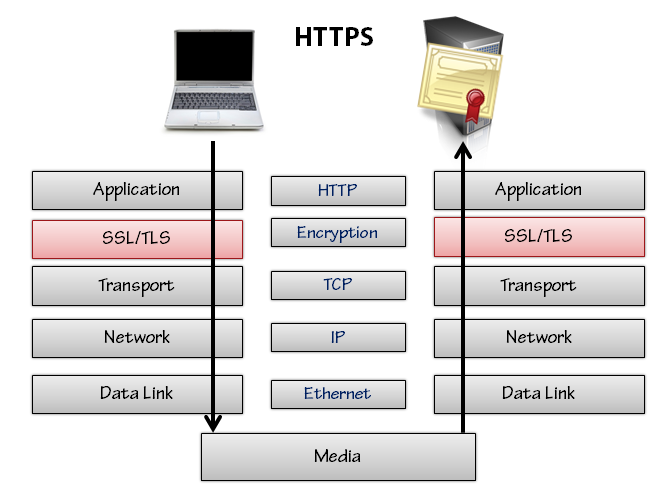
HTTPS требует, чтобы сервер имел криптографический сертификат. Сертификат отправляется клиенту во время настройки связи HTTPS. Сертификат включает имя хоста сервера, и пользовательский агент может использовать сертификат для проверки того, что он действительно общается с сервером, с которым он думает, что общается. Проверка возможна благодаря криптографии с открытым ключом и наличию центров сертификации, таких как Verisign, которые будут подписывать и ручаться за целостность сертификата. Администраторы должны приобрести и установить сертификаты в центрах сертификации.
Есть много криптографических деталей, которые мы могли бы охватить, но с точки зрения разработчика, наиболее важные вещи, которые нужно знать о HTTPS:
- Весь трафик по HTTPS зашифрован в запросе и ответе , включая заголовки HTTP и тело сообщения, а также все после имени хоста в URL. Это означает, что данные пути и строки запроса зашифрованы, а также все файлы cookie. HTTPS предотвращает перехват сеанса, потому что никакие перехватчики не могут проверить сообщение и украсть куки.
- Сервер аутентифицирован для клиента благодаря сертификату сервера. Если вы разговариваете с mybigbank.com через HTTPS, вы можете быть уверены, что ваши сообщения действительно отправляются на mybigbank.com, а не кому-то, кто подключил прокси-сервер к сети, чтобы перехватывать запросы и подделывать трафик ответов от mybigbank.com.
- HTTPS не аутентифицирует клиента. Приложения по-прежнему должны реализовывать проверку подлинности с помощью форм или один из других протоколов проверки подлинности, упомянутых ранее, если им необходимо знать личность пользователя. HTTPS делает проверку подлинности на основе форм и базовую проверку подлинности более безопасной, поскольку все данные зашифрованы. Существует возможность использования клиентских сертификатов с HTTPS, и клиентские сертификаты будут аутентифицировать клиента наиболее безопасным способом. Однако клиентские сертификаты, как правило, не используются в открытом Интернете, поскольку не многие пользователи приобретают и устанавливают персональные сертификаты. Корпорации могут требовать от клиентов сертификатов для доступа сотрудников к корпоративным серверам, но в этом случае корпорация может выступать в качестве центра сертификации и выпускать сертификаты сотрудников, которые они создают и управляют.
У HTTPS есть некоторые недостатки, и большинство из них связаны с производительностью. HTTPS требует значительных вычислительных ресурсов, и крупные сайты часто используют специализированное оборудование (ускорители SSL), чтобы снять нагрузку с криптографических вычислений с веб-серверов. HTTPS-трафик также невозможно кэшировать в публичном кеше, но пользовательские агенты могут хранить HTTPS-ответы в своем частном кеше. Наконец, HTTPS-соединения дороги в настройке и требуют дополнительного рукопожатия между клиентом и сервером для обмена криптографическими ключами и обеспечения того, чтобы все общались с надлежащим безопасным протоколом. Постоянные связи могут помочь амортизировать эту стоимость.
В конце концов, если вам нужна безопасная связь, вы охотно заплатите штрафы за производительность.
Где мы?
В этой статье мы рассмотрели файлы cookie, аутентификацию и безопасный HTTP. Если вы завершили весь этот сеанс, я надеюсь, что вы нашли ценную информацию, которая поможет вам при написании, обслуживании и отладке веб-приложений.