В предыдущем посте « Анализ профилей авторов SitePoint с помощью Diffbot» мы создали специальный API-интерфейс, который автоматически разбивает на страницы список работ автора и извлекает его имя, биографию и список сообщений с основными данными (URL, заголовок и отметка даты). В этом посте мы извлечем ссылки на авторские социальные сети.
Вступление
Если вы посмотрите на значки социальных сетей внутри био-рамки автора на странице его профиля, вы заметите, что они различаются. Не может быть ни одного, или может быть восемь, или что-нибудь между ними. Что еще хуже, ссылки не классифицируются семантически значимым образом — это просто ссылки с иконкой и атрибутом href.
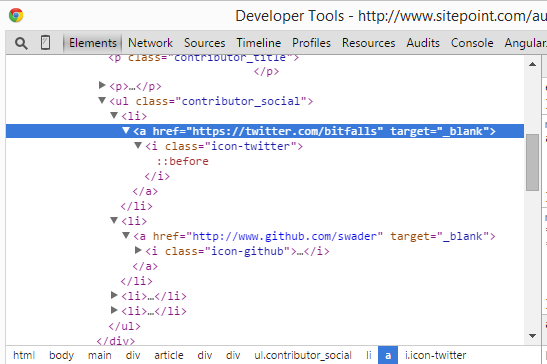
Это затрудняет превращение их в извлекаемый шаблон, и все же это именно то, что мы будем делать здесь, потому что, эй, кто не любит вызов?
Для настройки, пожалуйста, прочитайте и пройдите первую часть . Когда вы закончите, снова войдите в приборную панель разработчика.
Проблема повторных сборов
Логическим подходом было бы определить новую коллекцию, аналогичную сообщениям, но предназначенную для ссылок в социальных сетях. Затем просто наведите атрибут href на каждого, и мы настроены, верно? Нет.
Соблюдайте ниже:
Как видите, мы получаем все социальные ссылки. Но мы получаем их все X раз, где X — количество страниц в профиле автора. Это происходит потому, что Diffbot API объединяет HTML всех страниц в один большой, и наше правило сбора находит несколько наборов этих ссылок на иконки социальных сетей.
Интуиция может заставить вас использовать псевдоэлемент :first-child в родительском элементе коллекции на первой странице, но API не работает таким образом. HTML-содержимое отдельных страниц объединяется, да, но сначала на них выполняются правила. На самом деле, только результат объединяется. Вот почему нельзя использовать main:first-child для нацеливания только на первую страницу. Аналогично, в данный момент Diffbot API не имеет никаких :first-page псевдоэлементов :first-page , но их появление на более поздней стадии не исключено. Как же тогда мы это делаем?
Пользовательский домен Regex и API Dupes
Diffbot позволяет вам определять несколько пользовательских наборов правил для одной и той же конечной точки API, отличающихся регулярным выражением домена. Когда вызывается конечная точка API, выполняются все наборы правил, соответствующие URL, результаты объединяются, и вы получаете уникальный набор обратно, как если бы он был в одном API. Это то, что мы собираемся сделать тоже.
Новый Старый API
Начните с перехода к разделу «Создание правила» и выбора пользовательского API, чтобы вас попросили ввести имя. Введите то же имя, что и в первой части (в моем случае это AuthorFolio). Введите типичный URL-адрес теста ( http://sitepoint.com/author/bskvorc/ ) и запустите тест. Затем измените регулярное выражение домена на это:
( http ( s )?: //)?(.*\.)?sitepoint.com/author/[^/]+/
Это указывает API-интерфейсу нацеливаться только на первую страницу любого профиля автора — он полностью игнорирует нумерацию страниц.
Определить коллекцию
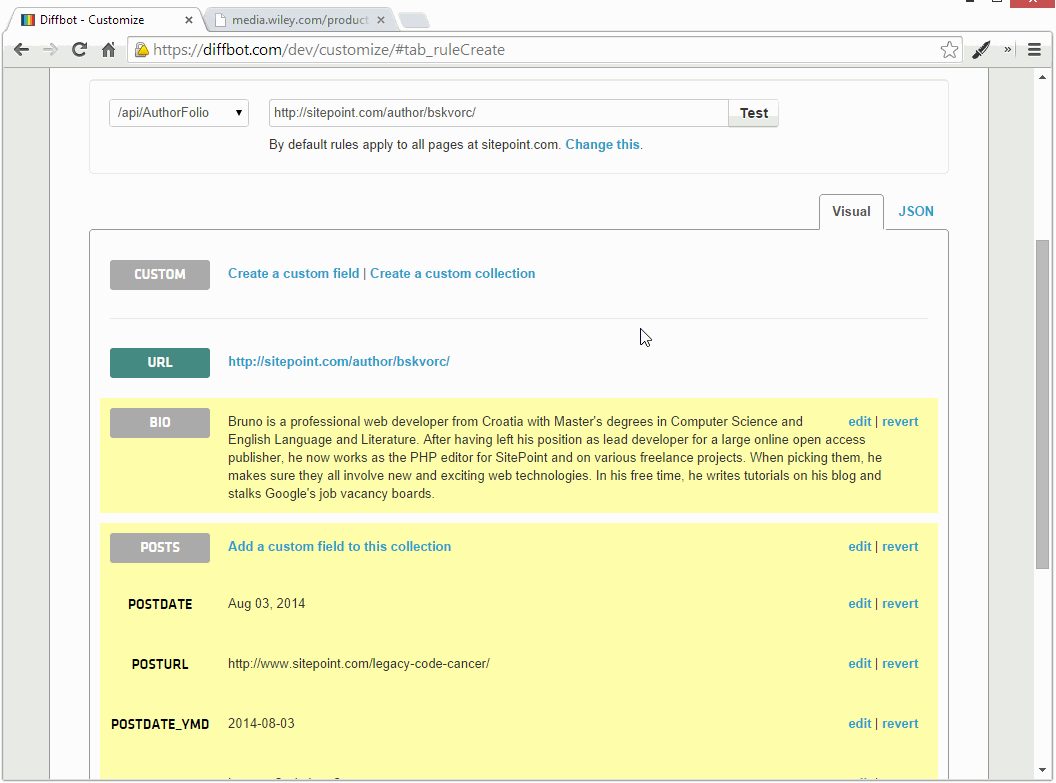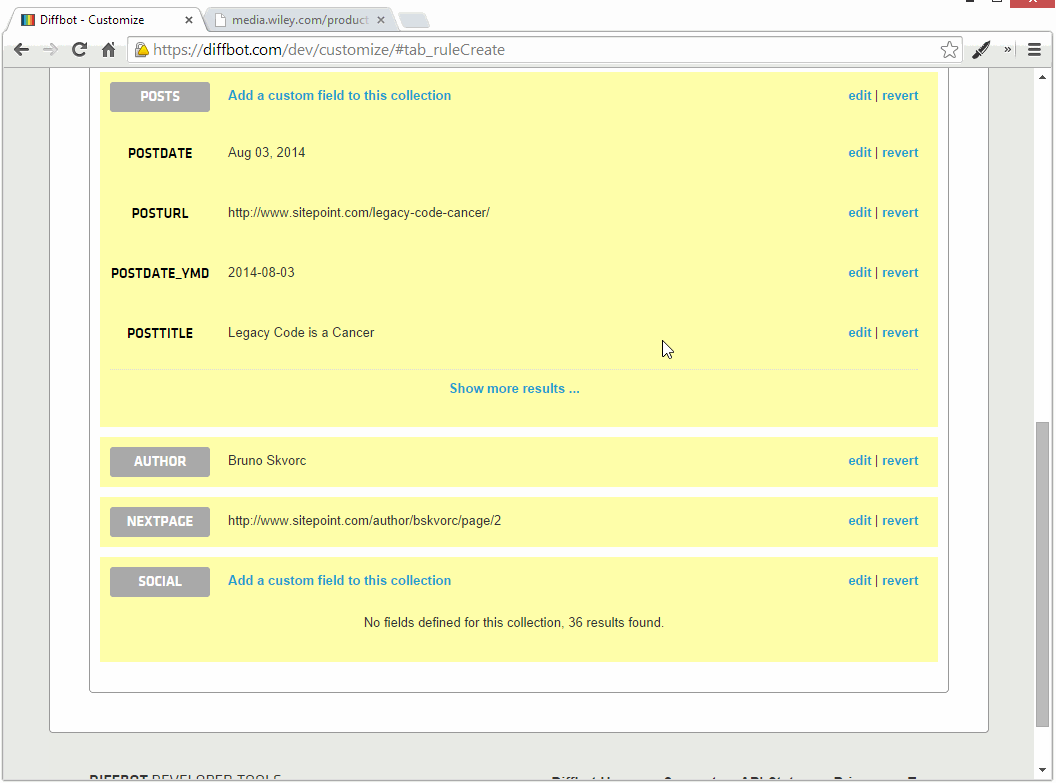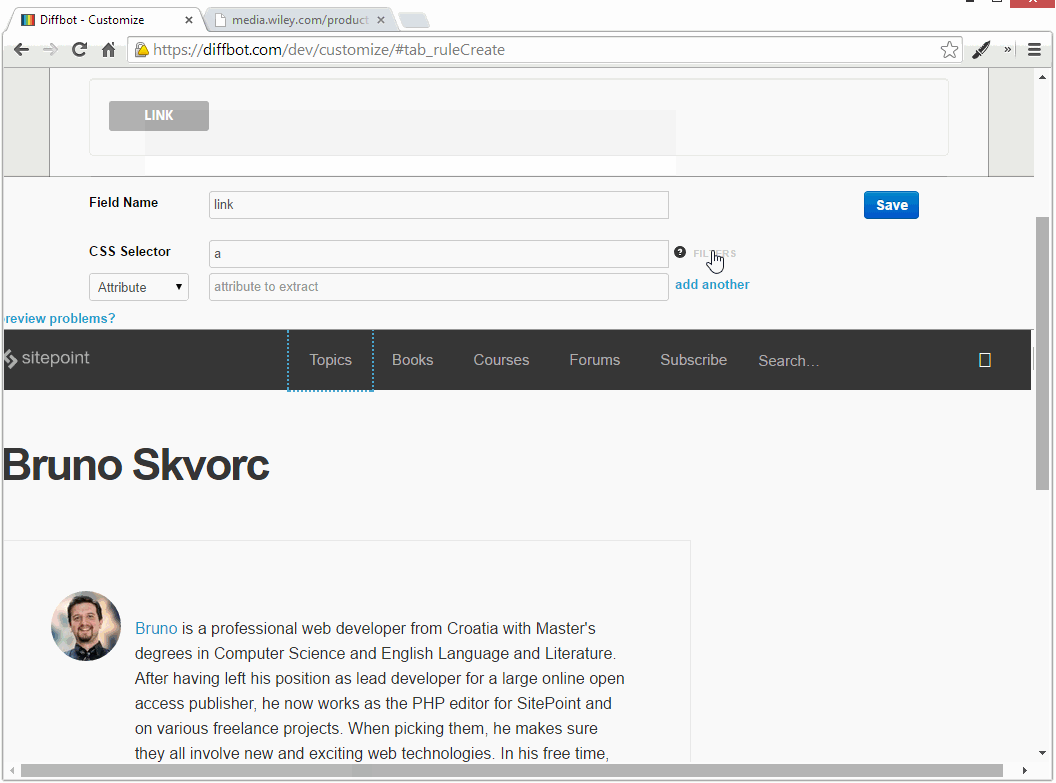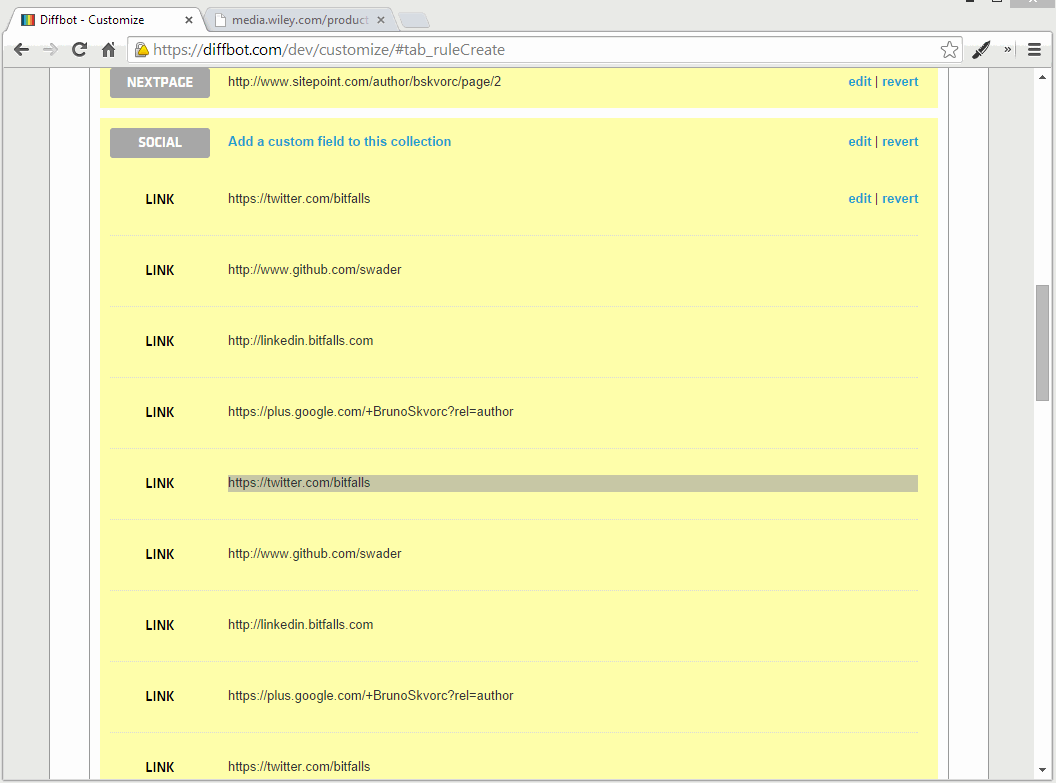
Затем определите новую коллекцию. Назовите его «социальным» и задайте ему специальное поле с селектором .contributor_social li . Назовите поле «link» и присвойте ему селектор «a» с атрибутом filter of href . Сохраните, дождитесь перезагрузки и обратите внимание, что теперь у вас есть четыре извлеченные ссылки:
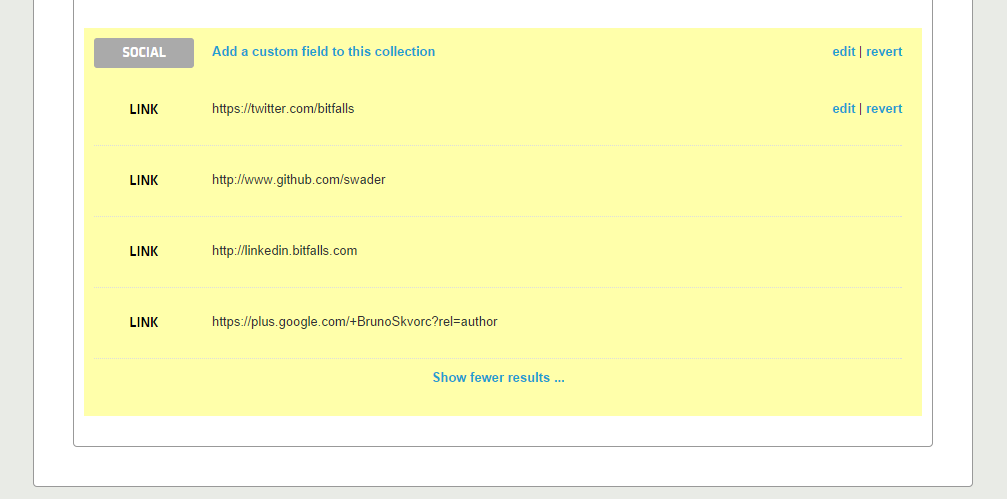
Имена социальных сетей
Но наличие только ссылок там отстой, не так ли? Было бы неплохо, если бы у нас тоже было имя в социальной сети. Однако дизайн SitePoint не классифицирует их семантически значимым образом, поэтому нет простого способа получить имя сети. Как мы можем решить это?
Regex переписать фильтры на помощь!
Пользовательские поля имеют три доступных фильтра:
- Атрибут: извлекает атрибут элемента HTML
- ignore: игнорирует определенные элементы HTML, основанные на селекторе css
- replace: заменяет содержимое вывода на указанное содержимое, если шаблон регулярного выражения соответствует
Мы будем использовать третий — узнайте больше о них здесь .
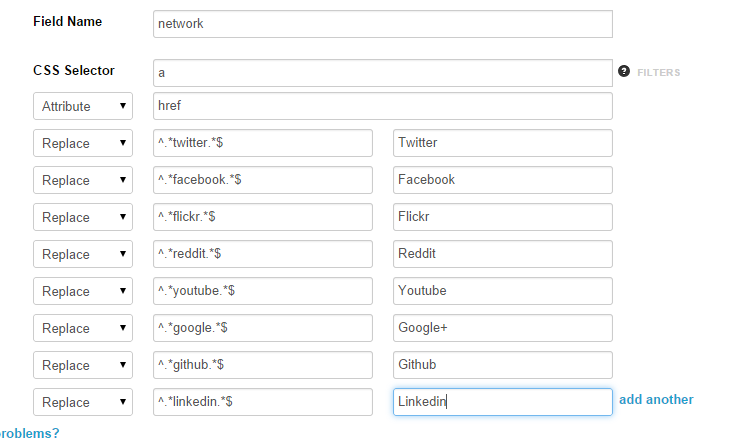
Добавьте новое поле в нашу «социальную» коллекцию. Дайте ему имя «сеть», селектор a и фильтр атрибутов href чтобы он извлекал ссылку так же, как поле «ссылка». Затем добавьте новый фильтр «Заменить».
К профилям авторов SitePoint могут быть прикреплены следующие социальные сети: Google+, Twitter, Facebook, Reddit, Youtube, Flickr, Github и Linkedin. К счастью, у каждого из них есть довольно простые URL-адреса с полными доменными именами, поэтому регулярное выражение имен — это просто. Правильное регулярное выражение: ^.*KEYWORD.*$ :
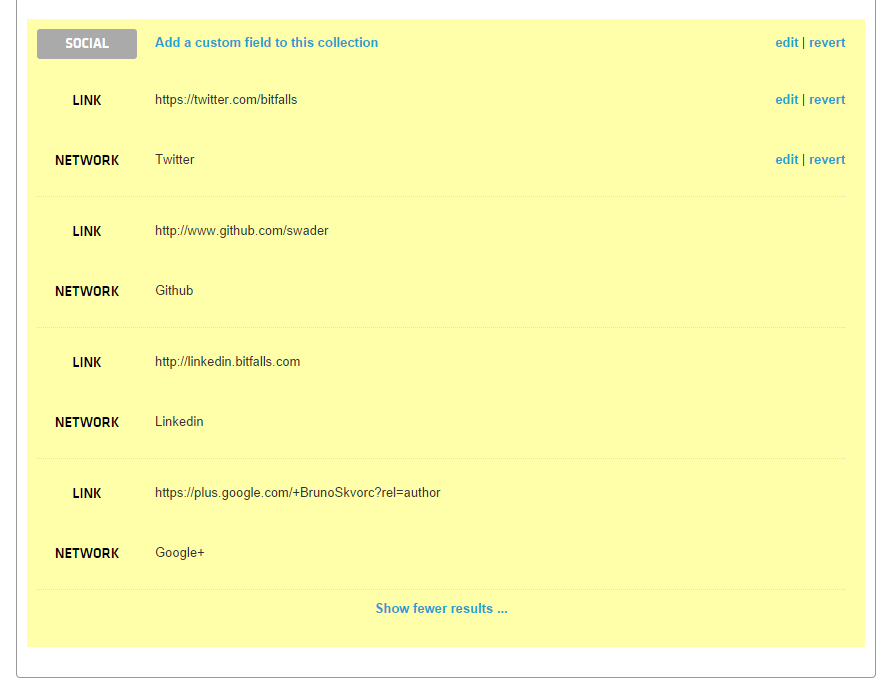
Сохраните, дождитесь перезагрузки и обратите внимание, что теперь у вас есть правильно сформированная коллекция социальных ссылок автора.
Объединяя API
Наконец, давайте сразу же получим все эти данные. Согласно тому, что мы сказали выше, выполнение вызова страницы автора с API AuthorFolio теперь должно дать нам один JSON-ответ, содержащий сумму всего, что мы до сих пор определили, включая поля из первого поста. Посмотрим, правда ли это. Посетите следующую ссылку в вашем браузере:
http : //diffbot.com/api/AuthorFolio?token=xxxxxxxxx&url=http://www.sitepoint.com/author/bskvorc/
Вот результат, который я получаю:

Как видите, мы успешно объединили два API и получили единый результат из всего, что хотели. Теперь мы можем по желанию использовать этот URL-адрес API из любого стороннего приложения и загружать портфолио автора, легко группируя по дате, обнаруживая изменения в биографии, регистрируя новые добавленные социальные сети и многое другое.
Вывод
В этой статье мы рассмотрели некоторые хитрые аспекты визуального сканирования с помощью Diffbot, такие как повторяющиеся коллекции и дублированные API-интерфейсы в регулярных выражениях пользовательских доменов. Мы создали конечную точку, которая позволяет нам извлекать ценную информацию из профиля автора, и мы узнали, как применять эти знания в любой подобной ситуации.
Вы ползали что-то интересное, используя эти методы? Вы столкнулись с какой-либо проблемой? Дайте нам знать в комментариях ниже!