Регулярные выражения являются собственным языком. Когда вы изучаете новый язык программирования, это маленький суб-язык, который не имеет смысла на первый взгляд. Часто вам приходится читать другой учебник, статью или книгу, чтобы понять описанный «простой» шаблон. Сегодня мы рассмотрим восемь регулярных выражений, которые вы должны знать для своего следующего проекта кодирования.
Прежде чем мы начнем, вы можете попробовать некоторые из приложений регулярных выражений на Envato Market, такие как:
RegEx Extractor
Вы можете извлекать электронные письма, прокси, IP-адреса, номера телефонов, адреса, HTML-теги, URL-адреса, ссылки, даты и т. Д. Просто вставьте одно или несколько регулярных выражений и исходные URL-адреса и запустите процесс.
Извлечь, очистить, разобрать, собрать.
Примеры использования
- Извлечение писем из старой адресной книги CSV.
- Извлечение источников изображений из файлов HTML.
- Извлекать прокси из интернет-сайтов.
- Извлечь результаты URL из Google.
Тестер регулярных выражений PHP
- Быстрый тестер регулярных выражений
- AJAX на основе
- JQuery и т. д. не требуются.
- База данных не требуется
- Реклама готова
MyRegExp
Этот элемент является PHP RegEx Builder, который помогает вам создавать регулярные выражения в расширяемом синтаксисе PHP. Вы можете:
- Создание регулярных выражений с простым синтаксисом PHP
- Проверяйте строки с помощью встроенного RegEx
- Постройте RegEx и получите их
- Применить preg_match к RegEx
- Заменить строку с помощью встроенного RegEx
Все это в синтаксисе PHP. Нет больше сломанных голов, пытающихся сделать простой или сложный RegEx!
Справочная информация о регулярных выражениях
Вот что Википедия говорит о них:
В вычислениях регулярные выражения обеспечивают сжатые и гибкие средства для идентификации строк текста, представляющих интерес, таких как конкретные символы, слова или шаблоны символов. Регулярные выражения (сокращенно regex или regexp с регулярными выражениями множественного числа, regexps или regexen) пишутся на формальном языке, который может интерпретироваться процессором регулярных выражений, программой, которая либо служит генератором синтаксического анализатора, либо анализирует текст и идентифицирует части. которые соответствуют предоставленной спецификации.
Теперь, это на самом деле не говорит мне много о реальных моделях. Регулярные выражения, о которых я расскажу сегодня, содержат такие символы, как \ w, \ s, \ 1 и многие другие, которые представляют нечто совершенно отличное от того, на что они похожи.
Если вы хотите немного узнать о регулярных выражениях, прежде чем продолжить чтение этой статьи, я бы посоветовал посмотреть серию скринкастов « Регулярные выражения для чайников ».
Восемь регулярных выражений, которые мы рассмотрим сегодня, позволят вам сопоставить (n): имя пользователя, пароль, адрес электронной почты, шестнадцатеричное значение (например, #fff или # 000), слаг , URL, IP-адрес и тег HTML. По мере того как список сокращается, регулярные выражения становятся все более запутанными. Картины для каждого регулярного выражения в начале легко понять, но последние четыре легче понять, прочитав объяснение.
Главное, что следует помнить о регулярных выражениях, это то, что они почти читаются вперед и назад одновременно. Это предложение будет иметь больше смысла, когда мы будем говорить о сопоставлении тегов HTML.
Примечание . Разделители, используемые в регулярных выражениях, — это косая черта, «/». Каждый шаблон начинается и заканчивается разделителем. Если в регулярном выражении появляется косая черта, мы должны экранировать ее обратной косой чертой: «\ /».
1. Соответствие имени пользователя

Шаблон:
|
1
|
/^[a-z0-9_-]{3,16}$/
|
Описание:
Мы начинаем с того, что говорим парсеру найти начало строки (^), за которой следуют любая строчная буква (az), число (0-9), подчеркивание или дефис. Далее {3,16} проверяет, что это не менее 3 из этих символов, но не более 16. Наконец, мы хотим получить конец строки ($).
Строка, которая соответствует:
мой-us3r_n4m3
Строка, которая не соответствует:
th1s1s-wayt00_l0ngt0beausername (слишком длинный)
2. Подбор пароля

Шаблон:
|
1
|
/^[a-z0-9_-]{6,18}$/
|
Описание:
Совпадение пароля очень похоже на сопоставление имени пользователя. Единственное отличие состоит в том, что вместо от 3 до 16 букв, цифр, подчеркиваний или дефисов нам нужно от 6 до 18 из них ({6,18}).
Строка, которая соответствует:
myp4ssw0rd
Строка, которая не соответствует:
mypa $$ w0rd (содержит знак доллара)
3. Соответствие шестнадцатеричного значения

Шаблон:
|
1
|
/^#?([a-f0-9]{6}|[a-f0-9]{3})$/
|
Описание:
Мы начинаем с того, что говорим парсеру найти начало строки (^). Далее, знак числа является необязательным, поскольку за ним следует знак вопроса. Знак вопроса говорит парсеру, что предыдущий символ — в данном случае знак числа — необязателен, но должен быть «жадным» и захватывать его, если он там есть. Затем, внутри первой группы (первая группа скобок), мы можем иметь две разные ситуации. Первая — любая строчная буква между a и f или число шесть раз. Вертикальная черта говорит нам, что у нас также может быть три строчные буквы между a и f или числами. Наконец, мы хотим конец строки ($).
Причина, по которой я поставил шестизначный символ, заключается в том, что синтаксический анализатор захватывает шестнадцатеричное значение, например #ffffff. Если бы я перевернул его так, чтобы три символа были первыми, синтаксический анализатор выбрал бы только #fff, а не три других символа f.
Строка, которая соответствует:
# a3c113
Строка, которая не соответствует:
# 4d82h4 (содержит букву h)
4. Подходящий слизень

Шаблон:
|
1
|
/^[a-z0-9-]+$/
|
Описание:
Вы будете использовать это регулярное выражение, если вам когда-нибудь придется работать с mod_rewrite и красивыми URL. Мы начинаем с того, что говорим парсеру найти начало строки (^), за которой следуют одна или несколько (знак плюс) букв, цифр или дефисов. Наконец, мы хотим конец строки ($).
Строка, которая соответствует:
мой титульный-здесь
Строка, которая не соответствует:
my_title_here (содержит подчеркивание)
5. Соответствие электронной почте
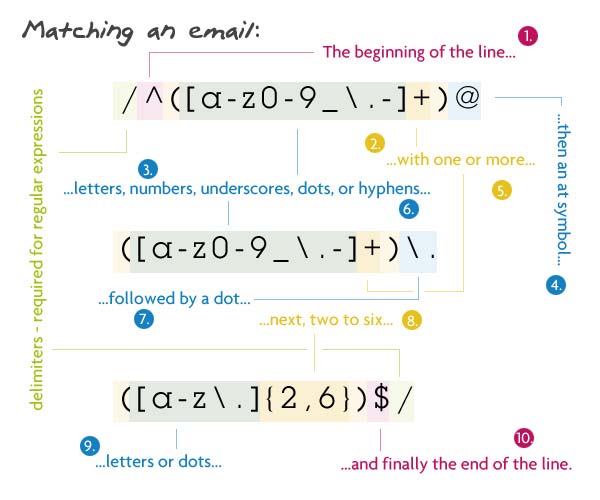
Шаблон:
|
1
|
/^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([az\.]{2,6})$/
|
Описание:
Мы начинаем с того, что говорим парсеру найти начало строки (^). Внутри первой группы мы сопоставляем одну или несколько строчных букв, цифр, подчеркиваний, точек или дефисов. Я избежал точки, потому что не экранированная точка означает любой символ. Сразу после этого должен быть знак «at». Далее следует имя домена, которое должно быть: одна или несколько строчных букв, цифр, подчеркиваний, точек или дефисов. Затем другая (экранированная) точка с расширением от двух до шести букв или точек. У меня от 2 до 6 из-за TLD для конкретной страны (.ny.us или .co.uk). Наконец, мы хотим конец строки ($).
Строка, которая соответствует:
john@doe.com
Строка, которая не соответствует:
john@doe.something (TLD слишком длинный)
6. Соответствие URL
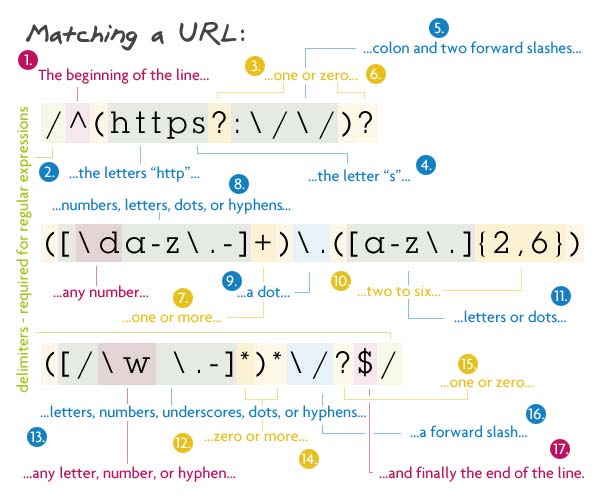
Шаблон:
|
1
|
/^(https?:\/\/)?([\da-z\.-]+)\.([az\.]{2,6})([\/\w \.-]*)*\/?$/
|
Описание:
Это регулярное выражение почти похоже на взятие конечной части приведенного выше регулярного выражения, добавление его между «http: //» и некоторой файловой структурой в конце. Звучит намного проще, чем есть на самом деле. Для начала мы ищем начало строки с кареткой.
Первая группа захвата — весь выбор. Это позволяет URL начинаться с «http: //», «https: //» или ни с одного из них. У меня есть знак вопроса после s, чтобы разрешить URL, которые имеют http или https. Чтобы сделать всю эту группу необязательной, я просто добавил знак вопроса в конце.
Далее следует доменное имя: одно или несколько цифр, букв, точек или переносов, за которыми следует еще одна точка, затем две-шесть букв или точек. В следующем разделе приведены необязательные файлы и каталоги. Внутри группы мы хотим сопоставить любое количество косых черт, букв, цифр, подчеркиваний, пробелов, точек или дефисов. Затем мы говорим, что эту группу можно сопоставить столько раз, сколько мы хотим. В значительной степени это позволяет сопоставить несколько каталогов вместе с файлом в конце. Я использовал звезду вместо знака вопроса, потому что звезда говорит ноль или больше , а не ноль или единицу . Если бы там использовался вопросительный знак, можно было бы сопоставить только один файл / каталог.
Затем подходит косая черта, но она может быть необязательной. Наконец мы заканчиваем с конца строки.
Строка, которая соответствует:
https://net.tutsplus.com/about
Строка, которая не соответствует:
http://google.com/some/file!.html (содержит восклицательный знак)
7. Соответствие IP-адреса
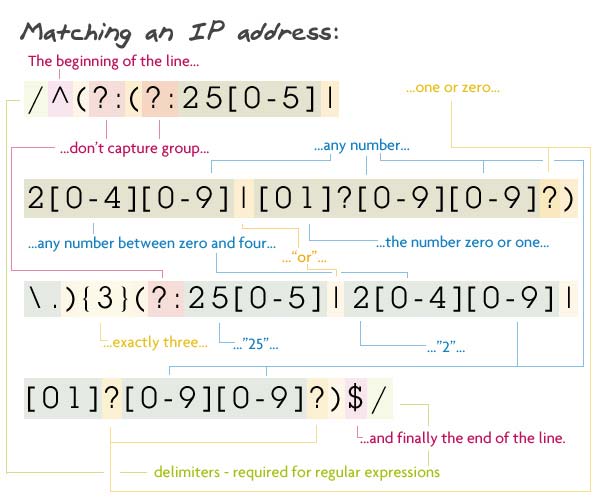
Шаблон:
|
1
|
/^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/
|
Описание:
Теперь я не собираюсь лгать, я не писал это регулярное выражение; Я получил это отсюда . Теперь, это не значит, что я не могу разорвать его на части.
Первая группа захвата действительно не захваченная группа, потому что
|
1
|
?:
|
был помещен внутрь, что говорит парсеру не захватывать эту группу (подробнее об этом в последнем регулярном выражении). Мы также хотим, чтобы эта не захваченная группа повторялась три раза — {3} в конце группы. Эта группа содержит другую группу, подгруппу и буквальную точку. Парсер ищет совпадение в подгруппе, а затем точку, по которой следует двигаться.
Подгруппа также является другой группой без захвата. Это просто набор символов (вещи в скобках): строка «25», за которой следует число от 0 до 5; или строка «2» и число от 0 до 4 и любое число; или необязательный ноль или один, за которым следуют два числа, причем второе является необязательным.
После того, как мы сопоставим три из них, мы перейдем к следующей группе без захвата. Вот что нужно: строка «25», за которой следует число от 0 до 5; или строка «2» с числом от 0 до 4 и другим числом в конце; или необязательный ноль или один, за которым следуют два числа, причем второе является необязательным.
Мы заканчиваем это запутанное регулярное выражение концом строки.
Строка, которая соответствует:
73.60.124.136 (нет, это не мой IP-адрес: P)
Строка, которая не соответствует:
256.60.124.136 (первая группа должна быть «25» и число от нуля до пяти )
8. Соответствие тегу HTML
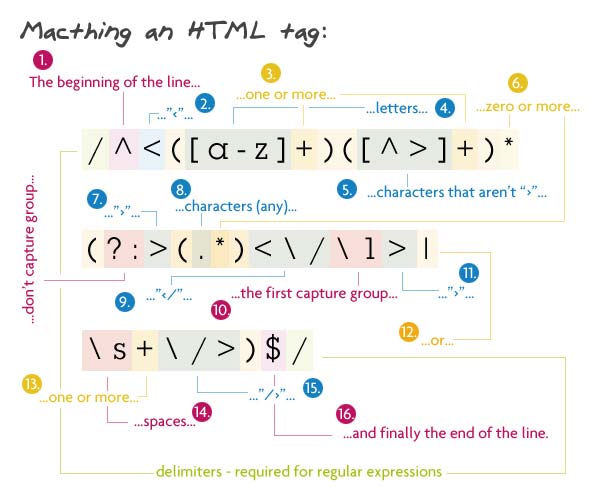
Шаблон:
|
1
|
/^<([az]+)([^<]+)*(?:>(.*)<\/\1>|\s+\/>)$/
|
Описание:
Одно из самых полезных регулярных выражений в списке. Соответствует любому тегу HTML с содержимым внутри. Как обычно, мы начинаем с начала строки.
Сначала идет имя тега. Это должна быть одна или несколько букв. Это первая группа захвата, она пригодится, когда нам нужно захватить закрывающий тег. Следующее — это атрибуты тега. Это любой символ, кроме знака «больше» (>). Поскольку это необязательно, но я хочу сопоставить более одного символа, используется звезда. Знак плюс образует атрибут и значение, а звезда говорит столько атрибутов, сколько вы хотите.
Далее идет третья группа без захвата. Внутри он будет содержать знак «больше», некоторый контент и закрывающий тег; или некоторые пробелы, косая черта и знак больше, чем. Первый вариант ищет знак «больше», за которым следует любое количество символов, и закрывающий тег. \ 1 используется, который представляет контент, который был захвачен в первой группе захвата. В данном случае это было имя тега. Теперь, если это невозможно, мы хотим найти самозакрывающийся тег (например, тег img, br или hr). Это должно иметь один или несколько пробелов с последующим «/>».
Регулярное выражение заканчивается концом строки.
Строка, которая соответствует:
Неттутс «> http://net.tutsplus.com/»> Неттутс +
Строка, которая не соответствует:
<img src = «img.jpg» alt = «Мое изображение>» /> (атрибуты не могут содержать больше знаков)
Вывод
Я надеюсь, что вы поняли идеи регулярных выражений немного лучше. Надеюсь, вы будете использовать эти регулярные выражения в будущих проектах! Много раз вам не нужно будет расшифровывать регулярное выражение за символом, но иногда, если вы делаете это, это помогает вам учиться. Просто помните, не бойтесь регулярных выражений, они могут не показаться вам, но они делают вашу жизнь намного проще. Просто попробуйте вытащить имя тега из строки без регулярных выражений!
Подпишитесь на нас в Твиттере или подпишитесь на RSS-канал NETTUTS, чтобы получать ежедневные обзоры и статьи о веб-разработке. И посмотрите на некоторые из этих приложений regex на Envato Market.