SQL является еще одним важным языком для разработчиков, желающих создавать веб-сайты, управляемые данными. Однако многие разработчики незнакомы с различными аспектами SQL; поэтому в этой статье мы проанализируем десять важных советов.
1. Используйте правильный язык
Веб-разработчики часто имеют в своем распоряжении множество языков. Для разработчиков крайне важно использовать правильный язык для работы.
Давайте рассмотрим следующий код. В первом примере разработчик выбирает все столбцы и все строки из таблицы клиентов. Во втором примере разработчик выбирает только имя, фамилию и адрес из таблицы клиентов для одного клиента с идентификатором 1001. Второй запрос не только ограничивает возвращаемые столбцы, он также будет работать лучше.
|
1
|
SELECT * FROM customer;
|
|
1
|
SELECT firstName, lastName, shippingAddress FROM customer WHERE customerID = 1001;
|
Когда вы пишете код, убедитесь, что он работает эффективно.
Слишком многие разработчики удовлетворены кодом, который адекватно работает на 100 строках данных, и мало думают о том, когда в базе данных будет 10000 строк.

2. Защитите свой код
Базы данных хранят ценную информацию. Из-за этого базы данных часто являются главными объектами для атаки. Многие разработчики не знают, что их код имеет критические уязвимости безопасности, что является очень страшным фактом не только для клиентов, но и для вас. В настоящее время разработчики могут нести юридическую ответственность, если их личная небрежность приводит к риску безопасности базы данных, который затем используется.
Если вы не уверены в серьезности безопасности базы данных, эти две статьи должны помочь понять суть вопроса:
«ФБР и полиция штата Вирджиния разыскивают хакеров, которые требовали, чтобы государство выплатило им выкуп в размере 10 миллионов долларов в четверг за возвращение миллионов личных фармацевтических записей, которые, по их словам, украли из базы данных о рецептурных препаратах штата».
Прочитайте статью Washington Post«Лаборатория Касперского, московская охранная компания, сегодня признала, что база данных, содержащая информацию о клиентах, была раскрыта в течение почти 11 дней, и что она узнала о взломе, только когда румынские хакеры сообщили об этом фирме в прошлую субботу».
Прочитайте статью ComputerWorld
Давайте рассмотрим другой пример с использованием псевдокода.
|
1
2
3
4
5
6
|
// Theoretical code
txtUserName.setText(«eshafer’ OR 1=1»);
query = «SELECT username, password FROM users WHERE username = ‘» + txtUserName.getText() + «‘;»;
// Final statement
query = «SELECT username, password FROM users WHERE username = ejshafer OR 1=1;»
|
Надеюсь, вы посмотрели этот код выше и заметили уязвимость. В результате запроса будут выбраны все записи имени пользователя и пароля из таблицы, потому что 1 всегда равно 1. Теперь этот конкретный пример мало что делает для потенциального хакера. Тем не менее, есть практически безграничные возможности для дополнительного вредоносного кода, который может быть добавлен с катастрофическими результатами.
Как вы можете написать безопасный код?
Решение часто зависит от СУБД; то есть, это варьируется между MySQL, Oracle или SQL Server. Например, в PHP с MySQL перед отправкой SQL-запроса перед вызовом SQL обычно необходимо экранировать параметры, используя функцию mysql_real_escape_string. Кроме того, вы можете использовать подготовленные операторы для «подготовки» ваших запросов. Сделайте своей миссией понять СУБД, с которой вы работаете, и присущие им проблемы безопасности.
Внедрение SQL — не единственная уязвимость безопасности, о которой могут беспокоиться базы данных и разработчики, однако это один из самых распространенных методов атаки. Важно проверить свой код и ознакомиться с последними проблемами безопасности для вашей СУБД, чтобы защитить от атак.

3. Поймите соединения
Отдельные операторы SQL select довольно легко написать. Однако бизнес-требования часто диктуют необходимость написания более сложных запросов. Например, «найти все заказы для каждого клиента и отобразить продукты для каждого заказа». Теперь, в этой конкретной ситуации, вполне вероятно, что есть таблица клиента, таблица заказов и таблица order_line (последняя должна была бы разрешить возможное отношение записи «многие ко многим»). Для тех, кто немного более знаком с SQL, очевидно, что для этого запроса требуется объединение таблиц, фактически два объединения таблиц. Давайте посмотрим на пример кода.
|
1
2
3
4
5
6
|
SELECT customer.customerID, order.order_id, order_line.order_item
FROM customer
INNER JOIN order
ON customer.customerID = order.customerID
INNER JOIN order_line
ON order.orderID = order_line.orderID;
|
Хорошо, достаточно просто. Для тех, кто не знает, приведенный выше код является внутренним объединением. В частности, приведенный выше код является равноправным соединением.
Давайте определим различные типы соединений.
Внутренние объединения. Основная цель внутренних объединений — возвращать совпадающие записи.
Внешние объединения: Внешние объединения не требуют, чтобы каждая запись имела соответствующую запись.
- Внешнее левое соединение: внешнее левое соединение таблиц A и B вернет все совпадающие записи A и B, а также любые несопоставленные записи из левой таблицы, в данном случае A.
- Правое внешнее соединение: Правое внешнее соединение таблиц A и B вернет все совпадающие записи A и B, а также любые несопоставленные записи из правой таблицы, в данном случае B.
- Полное внешнее объединение: Полное внешнее объединение таблиц A и B вернет все совпадающие записи A и B, а также любые несопоставленные записи из обеих таблиц.
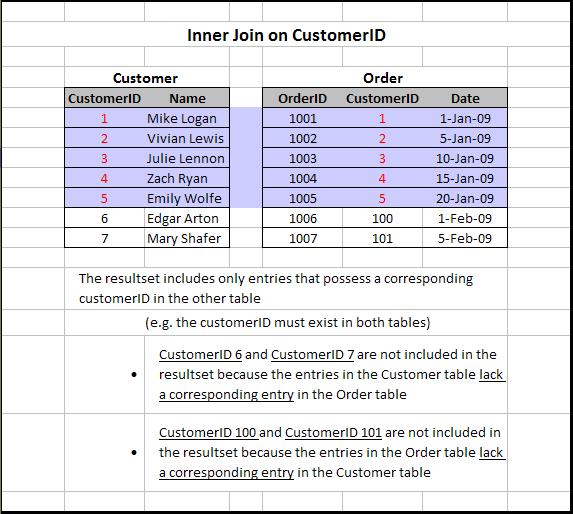
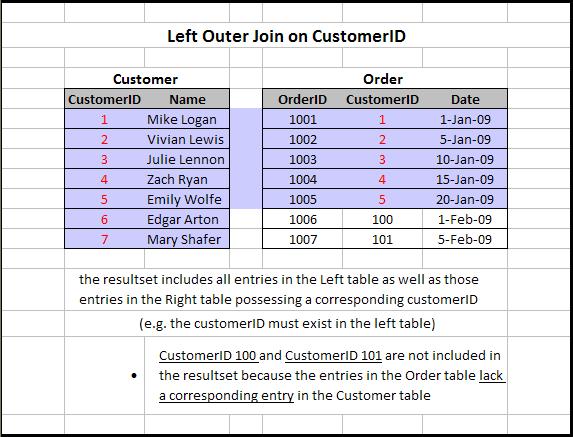
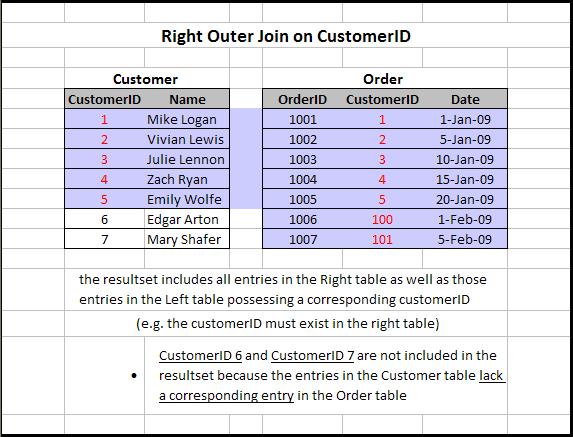
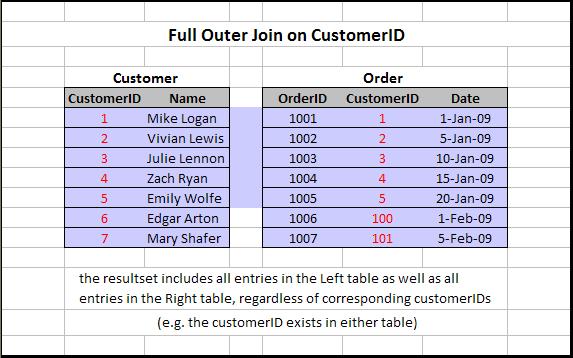
Отдельное спасибо Рональду Эрдей за фотографии.
Самостоятельно присоединяется
Существует один последний тип объединения, который необходимо учитывать, это самостоятельное соединение. Самостоятельное соединение — это просто соединение таблицы с самим собой.
|
1
2
3
|
EMPLOYEE TABLE
-EmployeeName
-SupervisorID
|
В этой ситуации для определения того, какие сотрудники контролируются данным сотрудником, потребуется самостоятельное объединение.
Надеемся, что это проясняет основные принципы объединений, поскольку они являются одной из основных функций SQL, что делает его таким мощным языком баз данных. Убедитесь, что вы используете правильное соединение для данной ситуации.

4. Знайте свои типы данных
В SQL обычно каждый столбец таблицы имеет связанный тип данных. Text, Integer, VarChar, Date и другие, как правило, являются доступными для разработчиков типами.
При разработке убедитесь, что вы выбрали правильный тип данных для столбца. Даты должны быть переменными DATE, числа должны быть числовым типом и т. Д. Это становится особенно важным, когда мы имеем дело с более поздней темой: индексация; но я продемонстрирую пример плохого знания типов данных ниже:
|
1
2
3
|
SELECT employeeID, employeeName
FROM employee
WHERE employeeID = 112457891;
|
Выглядит хорошо, основываясь на том, что мы в настоящее время знаем, правильно? Однако, что если employeeID на самом деле является строкой. Теперь у нас есть проблема, потому что СУБД может не найти соответствия (потому что строковые типы данных и целые числа являются разными типами).
Поэтому, если вы используете индексирование, вы, вероятно, будете озадачены тем, почему ваш запрос выполняется вечно, когда это должно быть простое сканирование индекса. По этой причине разработчики должны уделять особое внимание типам данных и их приложениям. Неключевые атрибуты, которые являются идентификаторами, часто являются строковыми типами, в отличие от целых чисел, из-за повышенной гибкости, которая предоставляется. Однако это также проблемная область для начинающих разработчиков, которые предполагают, что поля идентификаторов будут целыми числами.
Правильное использование типов данных имеет важное значение для правильного программирования баз данных, поскольку они напрямую приводят к эффективности запросов. Эффективные запросы необходимы для создания качественных, масштабируемых приложений.
5. Написать совместимый код
Все языки программирования имеют стандарты, которые должны знать веб-разработчики, и SQL не отличается. SQL был стандартизирован ANSI, а затем ISO, с новыми версиями языка, которые время от времени представляются. Последней версией является SQL: 2008, хотя самой важной версией, о которой должны знать разработчики, является SQL: 1999. В ревизии 1999 года представлены рекурсивные запросы, триггеры, поддержка PL / SQL и T-SQL и несколько новых функций. Также определено, что операторы JOIN должны выполняться в предложении FROM, а не в предложении WHERE.
При написании кода важно помнить, почему совместимый со стандартами код полезен. Существуют две основные причины, по которым используются стандарты. Первый — это ремонтопригодность, а второй — кроссплатформенная стандартизация. Как и в случае настольных приложений, предполагается, что веб-сайты будут иметь длительный срок службы и будут проходить различные обновления, чтобы добавить новые функциональные возможности и устранить проблемы. Как скажет любой системный аналитик, системы проводят большую часть своей жизни на этапе обслуживания. Когда другой программист получит доступ к вашему коду через 2, 5 или 10 лет, смогут ли они по-прежнему понимать, что делает ваш код? Стандарты и комментарии предназначены для обеспечения ремонтопригодности.
Другая причина — кроссплатформенность. Что касается CSS, то в настоящее время между Firefox, Internet Explorer, Chrome и другими браузерами ведется борьба за интерпретацию кода. Причиной применения стандартов SQL является предотвращение аналогичной ситуации между Oracle, Microsoft и другими вариантами SQL, такими как MySQL.
6. Нормализуйте свои данные
Нормализация баз данных — это методика организации содержимого баз данных. Без нормализации системы баз данных могут быть неточными, медленными и неэффективными. Сообщество специалистов по базам данных разработало серию руководств по нормализации баз данных. Каждый «уровень» нормализации называется формой, и всего существует 5 форм. Первая нормальная форма — это самый низкий уровень нормализации, вплоть до пятой нормальной формы, которая является самым высоким уровнем нормализации.
- Первая нормальная форма (1NF): самый базовый уровень нормализации данных, первая нормальная форма требует устранения всех повторяющихся столбцов в таблице, а также требует создания отдельных таблиц для связанных данных и идентификации каждой таблицы с помощью первичного ключа. атрибут.
- Вторая нормальная форма (2NF): удовлетворяет всем требованиям первой нормальной формы и создает связи между таблицами с использованием внешних ключей.
- Третья нормальная форма (3NF): отвечает всем требованиям второй и первой нормальных форм и удаляет все столбцы, которые не зависят от первичного ключа. Третья нормальная форма также удаляет все производные атрибуты, такие как возраст.
- Четвертая нормальная форма (4NF). Четвертая нормальная форма добавляет одно дополнительное требование, которое заключается в удалении любых многозначных зависимостей в отношениях.
- Пятая нормальная форма (5NF): Пятая нормальная форма является более редкой формой нормализации, и в этом случае зависимости соединения подразумеваются ключами-кандидатами (возможно, значениями первичного ключа).
В реальности разработки баз данных переход на 3NF — самый важный прыжок. 4NF и 5NF — немного больше роскоши (а иногда и неудобства) при разработке баз данных, и их редко можно увидеть на практике. Если вы боретесь с понятиями или вспоминаете первые три формы, существует простая связь. «Ключ, весь ключ и ничего, кроме ключа», который относится к 1NF, 2NF и 3NF.
Преимущества нормализации
Теперь, не углубляясь в теорию баз данных, давайте просто сосредоточимся на преимуществах нормализации. По мере того, как данные проходят через формы нормализации, они становятся чище, лучше организованы и быстрее. Теперь, с небольшой базой данных, которая имеет только 5 таблиц и 100 строк данных, это не будет очевидным. Однако по мере роста базы данных последствия нормализации станут намного более очевидными в отношении скорости и поддержания целостности данных. Однако в некоторых ситуациях нормализация не имеет смысла, например, при нормализации данных создаются чрезмерно сложные запросы, необходимые для возврата данных.
7. Полностью квалифицируйте имена объектов вашей базы данных.
Теперь, это обычно игнорируемый момент; на самом деле, весь пример кода, который я продемонстрировал в этом уроке, по сути нарушил этот совет. С точки зрения разработки базы данных полное имя объекта выглядит следующим образом: DATABASE.schema.TABLE. Теперь давайте посмотрим, почему важны полностью определенные имена и в каких ситуациях они необходимы. Целью полного имени объекта является устранение неоднозначности. Начинающие разработчики редко имеют доступ к нескольким базам данных и схемам, что усложняет проблемы в будущем. Когда конкретный пользователь имеет доступ к нескольким базам данных, нескольким схемам и таблицам в них, становится крайне важным напрямую указать, к чему пользователь пытается получить доступ. Если у вас есть таблица сотрудников, у вашего босса есть таблица сотрудников, а в схеме, на которой работает ваше веб-приложение, есть таблица сотрудников. К чему вы действительно пытаетесь получить доступ?
Логически полное имя будет выглядеть как DATABASE.SCHEMA.OBJECTNAME, однако синтаксически (т. Е. В выполнимых инструкциях) это будет просто SCHEMA.OBJECTNAME. Хотя разные СУБД имеют разные синтаксические различия, описанный выше стиль обычно применим.
|
1
2
|
— Not »SELECT * FROM table»
SELECT * FROM schema.TABLE
|
Полное определение имен баз данных важно при работе с базами данных большего размера, которые используются несколькими пользователями и содержат несколько схем. Тем не менее, это хорошая привычка.
8. Понимать индексирование
Индекс базы данных — это структура данных, которая повышает скорость операций с таблицей базы данных. Индексы могут быть созданы с использованием одного или нескольких столбцов таблицы базы данных, обеспечивая основу для быстрого случайного поиска и эффективного доступа к упорядоченным записям. Индексирование невероятно важно при работе с большими таблицами, однако иногда следует индексировать меньшие таблицы, если ожидается их рост. Небольшие таблицы, которые останутся маленькими, однако, не должны индексироваться (например, если ваша книга занимает 1 страницу, имеет ли смысл обратиться к указателю?)
Многие разработчики пишут свой код и тестируют его в таблице с 10 или 100 строками, и они удовлетворены, когда их код работает адекватно. Однако, когда таблица увеличивается до 10000 или 1000000 строк, код замедляется до скорости улитки, и клиент может с тем же успехом отправиться на обед в ожидании выполнения кода.
Когда запрос ищет в базе данных соответствующую запись, поиск можно выполнить двумя способами.
- Первый и самый медленный способ — это сканирование таблицы. При сканировании таблицы запрос ищет каждую запись в таблице в поисках совпадения.
- Второй и более быстрый способ — сканирование индекса. При сканировании индекса запрос выполняет поиск в индексе, чтобы найти запись. В терминах, не связанных с базой данных, сканирование таблицы будет эквивалентно чтению каждой страницы в книге в поисках слова, в то время как сканирование по индексу будет эквивалентно переключению на заднюю часть книги, нахождению слова, переключению на указанную странице, а затем читать слова на странице, чтобы найти слово.
Важно помнить, что индексы нужно время от времени перестраивать, так как данные добавляются в таблицу. Кроме того, хотя индексы увеличивают производительность доступа к данным, они замедляют изменение данных. Из-за этого большинство СУБД имеют возможность временно отключить индекс, чтобы облегчить массовое изменение данных, а затем разрешить его повторное включение и перестроение позднее.

9. Правильно использовать разрешения базы данных
При работе с базой данных, которая имеет несколько пользователей, важно правильно обрабатывать различные разрешения базы данных. Очевидно, что большинство баз данных имеют пользователя с правами администратора, но всегда ли имеет смысл выполнять ваши запросы от имени администратора? Кроме того, хотите ли вы предоставить всем вашим младшим разработчикам и пользователям учетные данные администратора для написания их запросов? Скорее всего нет. Различные возможные разрешения для вашей базы данных зависят от вашей СУБД, но между ними есть общие темы.
Например, в MySQL ввод «SHOW TABLES» покажет список таблиц в вашей базе данных, из которых вы, вероятно, заметите таблицу «user». Ввод «DESC user» покажет, что в пользовательской таблице есть различные поля. Помимо хоста, имени пользователя и пароля, существует также список привилегий, которые могут быть установлены для пользователя. Кроме того, существует таблица «db», которая управляет дополнительными привилегиями для конкретной базы данных.
SQL Server предоставляет операторы GRANT, DENY и REVOKE для предоставления или отмены разрешений пользователя или роли. Кроме того, SQL Server предоставляет такие роли, как db_writer, db_reader. Часто непознаваемые разработчики предоставляют эти роли (в отличие от создания своих собственных пользовательских ролей) другим пользователям, что приводит к общему снижению безопасности базы данных, а также к возможности выполнения пользователем нежелательной операции.
Правильное управление разрешениями пользователей вашей базы данных важно для управления не только безопасностью, но и основой для быстрой разработки и защиты целостности данных.
10. Знайте свои ограничения СУБД
Базы данных являются мощными инструментами, однако они не без ограничений. Oracle, SQL Server и MySQL имеют уникальные ограничения на такие вещи, как максимальный размер базы данных, максимальное количество таблиц и другие. Многие разработчики по незнанию выбирают решение СУБД для своего проекта, не планируя и не учитывая последующие требования к своей базе данных.
Информацию о различных ограничениях см. В руководстве по своей СУБД, например, ограничения SQL Server находятся на веб-сайте MSDN: http://msdn.microsoft.com/en-us/library/ms143432.aspx

Вывод
В этой статье мы рассмотрели 10 важных советов для разработчиков SQL. Однако есть много других полезных методов SQL, которые можно упомянуть; поэтому, пожалуйста, оставьте свои мысли в комментариях, считаете ли вы, что эта статья охватывает все основные темы, или вы считаете, что одна из них была исключена. Продолжайте разрабатывать и помните, что код, который вы пишете, поддерживает инфраструктуру интернета, и без вас интернет был бы не таким успешным, как он есть.
- Подпишитесь на нас в Твиттере или подпишитесь на RSS-канал NETTUTS, чтобы получать ежедневные обзоры и статьи о веб-разработке.