Независимо от того, насколько тщательно или долго вы тестируете свое программное обеспечение, нет ничего лучше, чем производственная среда для выявления ошибок. Вне зависимости от того, вызвано ли это странным редким состоянием, которое происходит только при непредсказуемых шаблонах параллелизма живого трафика, или взрывом достоверности входных данных, вы никогда не сможете представить, что пользователь печатает, «бросание 500» — это большая проблема.
Сообщения об ошибках HTTP хорошо видны вашим пользователям, очень смущают бизнес и могут привести к репутационному ущербу за очень короткий промежуток времени. Кроме того, их отладка в вашей производственной среде может быть чрезвычайно сложной. Начнем с того, что огромное количество данных журнала может сделать задачу изолирования проблемного сеанса, такого как поиск иголки в стоге сена. Даже если вы собрали журналы всех компонентов, у вас может не хватить данных для понимания проблемы.5xx
При использовании NGINX в качестве обратного прокси-сервера или балансировщика нагрузки для вашего приложения существует ряд функций, которые могут помочь вам в отладке в производственной среде. В этой записи блога мы опишем конкретное использование error_pageдирективы, поскольку мы исследуем типичную инфраструктуру приложений обратного прокси-сервера с изюминкой.
Знакомство с сервером отладки
Суть в том, что мы собираемся настроить специальный сервер приложений — назовем его «Сервер отладки» — и отправлять на него только те запросы, которые вызвали ошибки на обычном сервере приложений. Мы используем преимущества того, как NGINX может обнаруживать ошибки, возвращаемые с сервера приложений верхнего уровня, и повторять ответственные запросы с другой группой восходящего потока, в нашем случае той, которая содержит сервер отладки. Это означает, что Debug Server будет получать только те запросы, которые уже вызвали ошибки, поэтому его файлы журнала содержат только ошибочные события, готовые к расследованию. Это сокращает область поиска игл от стога сена до всего лишь нескольких игл.5xx
В отличие от основных серверов приложений, сервер отладки не должен быть построен для производительности. Таким образом, вы можете включить все доступные средства регистрации и диагностики, которые есть в вашем распоряжении, такие как:
- Запуск вашего приложения в режиме отладки с включенной полной трассировкой стека
- Журнал отладки серверов приложений
- Профилирование приложения, чтобы можно было определить тайм-ауты между процессами
- Ведение журнала использования ресурсов сервера
Подобные инструменты отладки обычно зарезервированы для среды разработки, потому что производственные среды настроены на производительность. Однако, поскольку сервер отладки только когда-либо получает ошибочные запросы, вы можете безопасно включить режим отладки на как можно большем количестве компонентов.
Вот как выглядит наша прикладная инфраструктура.
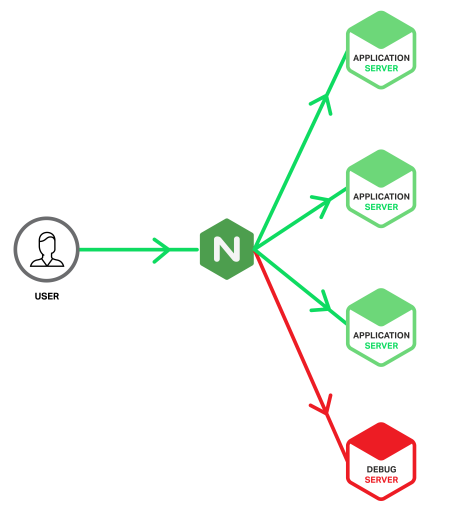
В идеале, подготовка и настройка Сервера отладки идентична серверам приложений, но есть также преимущества построения Сервера отладки как виртуальной машины, чтобы его можно было клонировать и копировать для автономного анализа. Однако это несет в себе риск того, что сервер может быть перегружен, если значительная проблема вызывает внезапный всплеск ошибок. С NGINX Plus вы можете защитить Debug Server от таких пиков, включив параметр в директиву, чтобы ограничить количество одновременных соединений, отправляемых на него (см. Пример конфигурации ниже).5xxmax_connsserver
Кроме того, поскольку сервер отладки загружен не так сильно, как основные серверы приложений, не все, что генерируется на сервере приложений, вызывает его на сервере отладки. Такие ситуации могут указывать на то, что вы достигли пределов масштабирования основных серверов приложений и что причиной является не исчерпание программного обеспечения, а исчерпание ресурсов. Независимо от первопричины, такие ситуации улучшают пользовательский опыт, сохраняя их от ошибок.5xx5xx
конфигурация
В следующем примере конфигурации NGINX показано, как настроить сервер отладки для получения запросов, которые уже сгенерировали ошибку на главном сервере приложений.5xx
upstream app_server {
server 172.16.0.1 max_fails=1 fail_timeout=10;
server 172.16.0.2 max_fails=1 fail_timeout=10;
server 172.16.0.3 max_fails=1 fail_timeout=10;
}
upstream debug_server {
server 172.16.0.9 max_fails=1 fail_timeout=30 max_conns=20;
}
server {
listen *:80;
location / {
proxy_pass http://app_server;
proxy_intercept_errors on;
error_page 500 503 504 = @debug;
}
location @debug {
proxy_pass http://debug_server;
access_log /var/log/nginx/access_debug_server.log detailed;
error_log /var/log/nginx/error_debug_server.log;
}
}Первое, что мы делаем, это указываем адреса наших серверов приложений в upstream app_serverблоке. Затем мы указываем один адрес нашего сервера отладки в upstream debug_serverблоке. Обратите внимание, что мы настроены max_failsна 1немедленную отправку ошибок на сервер отладки. Мы также установили для этого fail_timeoutпараметра значение 30 секунд (вместо 10 секунд по умолчанию), чтобы дать серверу отладки больше времени для обработки запросов до сбоя.
Первый locationблок настраивает простой обратный прокси-сервер, используя proxy_passдирективу для загрузки запросов балансировки между серверами приложений в нашей группе восходящего потока app_server (мы не указываем алгоритм балансировки нагрузки, поэтому используется алгоритм Round Robin по умолчанию). В proxy_intercept_errorsдирективе означает , что любой ответ с HTTP — кодом 300или выше обрабатываемые error_pageдирективами. В нашей конфигурации мы перехватываем только 500, 503и 504ошибки, и передать их в @debug место. Любые другие коды ответов, такие как 404s, отправляются обратно клиенту без изменений.
location @debugБлок делает две вещи. Во-первых, он передает все запросы в вышестоящую группу debug_server , которая, конечно же, содержит наш специальный Debug Server. Во-вторых, он записывает повторяющиеся записи журнала в отдельные файлы журнала доступа и ошибок. Изолируя сообщения, сгенерированные для ошибочных запросов на серверах приложений, от сообщений обычного доступа, вы можете легче соотнести ошибки с ошибками, сгенерированными на самом сервере отладки.
Обратите внимание, что access_logдиректива ссылается на специальный формат журнала, который называется подробным . Мы определяем формат, включив следующую log_formatдирективу в httpконтекст верхнего уровня .
log_format detailed '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent "$http_referer" '
'"$http_user_agent" $request_length $request_time '
'$upstream_response_length $upstream_response_time '
'$upstream_status';Подробный формат расширяет по умолчанию комбинированного формата с еще пятью переменными , которые предоставляют дополнительную информацию о запросах , направляемых в Debug Server , и его ответы.
$request_length— Общий размер запроса, включая заголовок и тело, в байтах$request_time— Время обработки запроса, в миллисекундах$upstream_response_length— длина ответа, полученного с сервера отладки, в байтах$upstream_response_time— Время, потраченное на получение ответа от сервера отладки, в миллисекундах$upstream_status— Код состояния ответа от сервера отладки
Эти дополнительные поля в журнале очень полезны при обнаружении как некорректных, так и длительных запросов. Последнее может указывать на тайм-ауты в приложении или другие проблемы межпроцессного взаимодействия.
Вывод
Бросать это 500большое дело. Используете ли вы модель DevOps, экспериментируете с непрерывной доставкой или просто хотите снизить риск модернизации большого взрыва, NGINX предоставляет вам инструменты, которые могут помочь вам лучше реагировать на возникающие проблемы.