Итак, вы создали сервис с расширенным алгоритмом, который использует некую классификацию для обнаружения определенных событий. Как вы узнали бы, что ваши данные конфигурации являются оптимальными? Как бы вы измерили влияние на точность при каждом изменении алгоритма?
В следующем посте будет показано, как использовать комбинацию понятий из машинного обучения, статистики и исследований операций для максимизации набора конфигурации алгоритма.
Этот метод очень эффективен в механизме классификации на стороне клиента, который требует точности, но ему не хватает времени на обучение или вычислительной мощности, чтобы это сделать.
Предлагаемый метод делится на 4 этапа:
- Подготовка тестовых данных
- Запуск теста
- Измерение результата
- Анализ
- Определить победителя
Подготовка тестовых данных
Подготовьте файл CSV с данными, которые указывают на его правильность. Например, если алгоритм должен обнаруживать автомобили, у нас будут такие данные, как:
|
1
2
3
4
5
6
|
Toyota,1mouse,0Nissan,1keyboard,0Ford,1button,0 |
Где 0 указывает на то, что данные не являются автомобилем, а 1 указывает на то, что данные являются автомобилем.
Объем набора данных будет обсуждаться позже и, возможно, заслуживает отдельного поста, однако для упрощения предположим, что у нас есть 10 тестов с 5 правильными данными и 5 неверными данными.
Запуск теста
Создание теста для отправки данных в ваш алгоритм
Общая концепция ясна:
- Прочитайте данные теста
- Отправь это на свой алгоритм
- Запишите результат (т.е. правильно ли алгоритм идентифицировал данные)
Однако, поскольку мы хотим выяснить оптимальную конфигурацию, мы добавим дополнительный шаг перед отправкой данных в алгоритм:
Установите алгоритм с определенной конфигурацией, это означает, что параметры, используемые вашим алгоритмом, можно будет настраивать для каждого запуска.
Таким образом, шаги запуска высокого уровня должны быть:
- Прочитайте данные теста
- Подготовьте перестановки конфигурации алгоритма
- Отправьте данные в свой алгоритм для каждой перестановки конфигурации
- Запишите результат для каждого прогона
Несколько вещей, чтобы отметить:
- Ваш алгоритм должен всегда возвращать результат, независимо от того, идентифицировал ли он данные или нет, чтобы вы могли записывать истинный отрицательный и ложный отрицательный.
- Выведите внешнюю конфигурацию, включите ее для внешнего класса, как это требуется для каждого набора конфигурации.
- Перемешайте тестовые данные между каждым прогоном и выполните несколько прогонов для определенного набора конфигурации. Перестановка данных позволит уменьшить корреляцию с порядком данных, выполнение нескольких прогонов с одинаковой конфигурацией поможет уменьшить любое случайное стандартное отклонение.
Измерение результата
Когда ваш тест возвращает данные из алгоритма, сравните прогнозируемое условие алгоритма (положительное / отрицательное) с истинным условием на основе указания в данных теста.
Обязательно посчитайте следующее:
- TruePositive (TP) = правильно идентифицирован, хит!
Правильно классифицировано как положительное - Истинно отрицательный (TN) = правильно отклонено, эквивалентно правильному отклонению
Правильно классифицировано как негатив - Ложное срабатывание (FP) = неправильно идентифицировано, эквивалентно ложному срабатыванию (ошибка типа I)
Неправильно классифицировано как положительное - Ложноотрицательный (FN) = неправильно отклонен, промах (ошибка типа II)
Неправильно классифицировано как отрицательное
Точность алгоритма будет измеряться следующим образом:
|
1
|
Accuracy (ACC) = (TP + TN)/(TP + FP + FN + TN) |
Мне также нравится измерять следующее:
- Истинный положительный коэффициент (TPR), также известный как чувствительность : TPR = TP / (TP + FP). Если все ваши положительные данные были определены правильно, значение будет равно 1, поэтому чем ближе результат к 1, тем лучше.
- Истинный отрицательный коэффициент, также известный как специфичность : NPV = TN / (TN + FN). Если все отрицательные данные были определены правильно, значение будет равно 1, поэтому чем ближе результат к 1, тем лучше.
- Коэффициент ложных срабатываний (FPR), также известный как выпадение: FPR = FP / (FP + TN). Чем ближе значение к 0, тем меньше ложных срабатываний.
- Неверный отрицательный коэффициент (FNR): FNR = FN / (TP + FN). Чем ближе значение к 0, тем меньше пропущено.
Функция стоимости
Очень важно
Здесь вы можете количественно оценить статистический анализ и результаты в единую оценку, которая поможет определить, насколько хорош общий прогон / конфигурация, а также упростит сравнение между прогонами.
Формула функции стоимости будет выглядеть следующим образом:
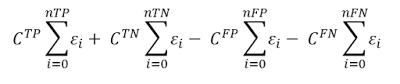
Где C TP — стоимость результатов True Positive, C TN — стоимость результатов True Positive и т. Д.
Упрощенно, вам нужно суммировать каждое вхождение на основе определенного веса.
Вам необходимо решить, какой вес дать каждому результату данных, то есть значение TP, TN, FP & FN.
Это может варьироваться в зависимости от потребностей каждого клиента, например, некоторые клиенты хотели бы, чтобы ваш алгоритм давал больше результатов за счет качества, поэтому вы бы меньше снижали штраф / вес на результат FP / FN. Другие будут очень чувствительны к ошибочным результатам, поэтому ваша функция стоимости даст более высокое значение / вес для FP.
Примечание. Я бы порекомендовал установить значение стоимости TP и TN как таковое, чтобы, если все результаты верны, ожидаемое значение суммы было бы круглым числом. Например, если у нас будет 10 тестов, 5 положительных и 5 отрицательных, мы дадим каждому TP & TN стоимостную стоимость 10, поэтому общий балл за полностью успешный прогон составит 100.
Сохраните в файле перестановку конфигурации и ее оценку.
Анализ
Положите все результаты запуска в Excel.
Очень легко найти максимальную оценку функции стоимости и ее набор конфигурации, однако, чтобы найти наиболее надежную конфигурацию, найдите значение конфигурации, которое имело наилучшее среднее значение среди других перестановок. Для этого создайте сводную таблицу, в которой все значения конфигурации находятся в разделе «Строки», и перетащите поле оценки функции стоимости в раздел «Сумма значений». Дублируйте поле оценки в разделе «Суммарное значение» и установите одно в качестве усредненной функции, а другое — в качестве максимальной.
Поскольку весь набор конфигурации находится в разделе строк в сводной таблице, его можно объединить, чтобы отображалось только первое значение.
Последний шаг — написать лучшее значение для средней оценки. Иногда лучший средний балл определенного значения конфигурации будет соответствовать максимальному максимальному баллу, однако иногда это не так.
На изображениях ниже вы можете увидеть демонстрацию определенного значения конфигурации и его среднего и максимального балла. Вы могли видеть, что не всегда существует корреляция между средней и максимальной оценкой.
На рисунке ниже определенная конфигурация алгоритма имеет значения 40, 50, 60 и 70.
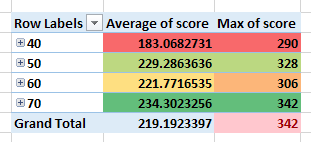
Значение 70 появляется в конфигурации перестановки максимальной оценки, а также имеет лучшее среднее значение. Наличие лучшего среднего означает, что установка значения 70 даст лучший средний балл для любых других конфигурационных перестановок. Это подразумевает надежность этой конфигурации.
На изображении ниже мы выбираем другой параметр конфигурации алгоритма со значениями 0,1 и 2.
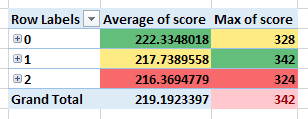
Мы сделали это, перетащив соответствующее поле параметра конфигурации в разделе «Строки» сводной таблицы в первую позицию.
Вы можете видеть, что наилучшая оценка функции средней стоимости предназначена для значения 0, а наилучшая оценка функции максимальной стоимости — для значения 1.
Определить победителя с помощью финального конкурса
В конце фазы анализа у вас будет набор конфигурации, который обеспечивает максимальную оценку, и набор конфигурации, который обеспечивает наилучшую среднюю оценку.
На этом этапе мы постараемся свести к минимуму любые последствия, которые может иметь алгоритм из-за тестовых данных, т.е. мы хотим исключить возможность смещения алгоритма на определенные тестовые данные.
Создайте тестовые данные со следующим:
- 80% положительных тестов
- 70% положительных тестов
- 30% положительных тестов
- 20% положительных тестов
Выполните все тестовые данные для каждого из максимального и среднего набора конфигурации.
Победитель будет основан на потребностях вашего клиента и заданном результате. Если между оценками прогонов нет большой разницы, это означает, что ваш алгоритм является надежным, и вы можете выбрать тот, который дал вам максимальную оценку, однако, если есть большая разница, это означает, что ваш алгоритм зависит от данных, и он работает для вашего клиента необходимо ли выбрать лучший средний или лучший максимум.
Дополнительный бонус при использовании этого метода:
- Проверьте, как ваш алгоритм использует ресурсы с течением времени (утечки памяти, загрузка процессора, дисковое пространство, …)
- Позволяет точно измерить изменения в алгоритме во времени между версиями.
Любые отзывы приветствуются.
Дальше хорошо читает
- http://www.chioka.in/class-imbalance-problem/
- https://en.wikipedia.org/wiki/Sensitivity_and_specificity
| Ссылка: | Увеличьте свою конфигурацию до предела — добавьте статистику от нашего партнера по JCG Гал Левински в блоге Гал Левински . |