В этой статье я упомяну первую статью, в которой представлен Spark , Spark: Кластерные вычисления с рабочими наборами . Этот пост будет одним из базовых постов о моем проекте GSoC. Вы можете прочитать сообщение о моем принятом предложении здесь: GSoC 2015 Acceptance for Apache GORA .
MapReduce и его варианты успешны для крупномасштабных вычислений. Тем не менее, большинство из этих вариантов основаны на ациклической модели потока данных, которая не подходит для многих приложений. Spark представляет решение для повторного использования рабочего набора данных в нескольких параллельных операциях. Итеративные приложения машинного обучения и интерактивный анализ данных являются такими задачами. Spark поддерживает их, сохраняя масштабируемость и отказоустойчивость MapReduce.
Когда мы посмотрим ближе на эти два варианта использования:
- Итерационные задания. Многие алгоритмы машинного обучения используют один и тот же набор данных и неоднократно применяют одну и ту же функцию для оптимизации параметра. Когда каждое задание определяется как задание MapReduce, каждое задание должно перезагружать данные с диска, что вызывает проблемы с производительностью.
- Интерактивная аналитика: при работе с Hadoop каждый запрос является отдельным заданием и считывает данные с диска. Таким образом, это также вызывает другую проблему с производительностью.
Spark интегрируется в Scala, который является статически типизированным языком программирования высокого уровня для Java VM. Разработчики пишут программу, называемую драйвером, для использования Spark для параллельного выполнения операций. Spark предоставляет две основные абстракции для параллельного программирования: RDD (Resilient Distributed Datasets) и параллельные операции (функции передаются для применения к набору данных). Кроме того, Spark имеет два ограниченных типа общих переменных, которые можно использовать в функции, выполняемой в кластере.
Эластичные распределенные наборы данных (RDD)
СДР являются одним из основных отличий в Spark. Они представляют собой набор объектов только для чтения, которые не должны находиться в физическом хранилище, и RDD всегда могут быть восстановлены в случае сбоя узлов.
Каждый СДР представлен объектом Scala, и программисты могут создавать СДР четырьмя способами:
- Из файла в общей файловой системе
- Распараллеливая коллекцию Scala
- Преобразуя существующий СДР
- Изменяя постоянство существующего RDD.
Стойкость СДР можно изменить двумя способами. Во-первых, это действие кэширования, которое оставляет набор данных ленивым, но позволяет кешировать набор данных после первого вычисления. Второе — это действие сохранения, которое позволяет набору данных оценивать и записывать в распределенную файловую систему. Действие кеша работает аналогично идее виртуальной памяти. Если памяти недостаточно, Spark пересчитает все разделы набора данных.
Там может быть применено несколько параллельных операций на RDD: уменьшить, собрать и предвидеть.
Общие переменные
В Spark есть два ограниченных типа общих переменных: широковещательные переменные и аккумуляторы . Широковещательные переменные подходят для работы с большими переменными только для чтения и хотят распространять их. Аккумуляторы подходят для дополнительных задач.
Реализация
Spark построен на Mesos, которая является кластерной операционной системой и позволяет нескольким параллельным приложениям совместно использовать кластер.
Ядром Spark являются СДР. Вот пример использования СДР:
|
1
2
3
4
5
|
val file = spark.textFile("hdfs://...")val errs = file.filter(_.contains("ERROR"))val cachedErrs = errs.cache()val ones = cachedErrs.map(_ => 1)val count = ones.reduce(_+_) |
Ключевым моментом является то, что эти наборы данных хранятся в виде цепочки объектов, которые фиксируют происхождение каждого RDD. Ниже приведена цепочка линий данного примера:
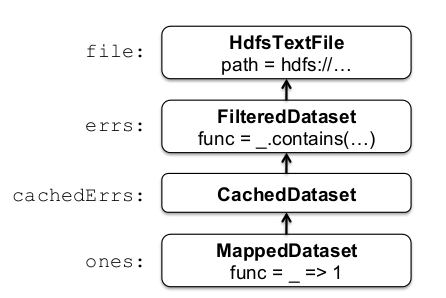
ошибки и ленивые RDD. Когда вызывается уменьшение , входные блоки сканируются потоковым способом, чтобы оценить их , они добавляются для выполнения локального уменьшения, и локальные отсчеты отправляются драйверу. Эта парадигма похожа на MapReduce.
Отличие Spark заключается в том, что некоторые промежуточные наборы данных могут сохраняться при выполнении операций. ошибки могут быть использованы таким образом:
|
1
|
val cachedErrs = errs.cache() |
который создает кэшированный RDD, и на нем можно запускать параллельные операции. После первого вычисления он может быть использован повторно и помогает ускорить работу.
Каждый объект RDD реализует три операции:
- getPartitions, возвращает список идентификаторов разделов
- getIterator (раздел), перебирает раздел
- getPreferredLocations (section), используется для планирования задач для достижения локальности данных.
Различные типы СДР различаются в том, как они реализуют интерфейс СДР, как, например, HdfsTextFile, MappedDataset и CachedDataset.
Производительность
Когда логистическая регрессия реализуется как в Spark, так и в Hadoop, что требует итеративной вычислительной нагрузки, ниже приведены результаты:
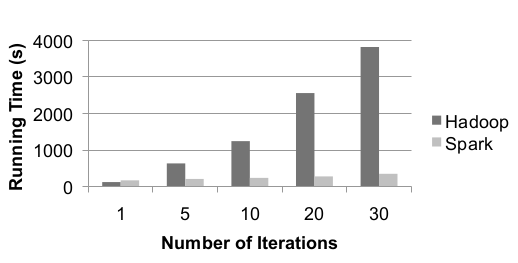
Видно, что на первой итерации Hadoop более вероятно благодаря использованию Scala вместо Java. Однако последующие итерации занимают всего 6 секунд из-за повторного использования кэшированных данных. Это представляет силу Spark по сравнению с Hadoop.
Вывод
В этом посте рассматриваются Spark и кластерные вычисления. Считается, что Spark является первой системой, которая позволяет интерактивно использовать эффективный язык программирования общего назначения для обработки больших наборов данных в кластере. Его основной особенностью являются RDD, а также есть две другие абстракции — широковещательные переменные и аккумуляторы. Результаты показывают, что Spark может работать в 10 раз быстрее, чем Hadoop, благодаря своему внутреннему дизайну.
| Ссылка: | Spark and Cluster Computing от нашего партнера JCG Фуркана Камачи в блоге FURKAN KAMACI . |