С выпуском Solr 5.0, самой последней основной версии этого замечательного поискового сервера, мы получили не только улучшения и изменения из библиотеки Lucene. Конечно, мы получили такие функции, как:
- контрольная сумма сегментов
- идентификаторы сегментов
- Lucene использует только классы из пакета Java NIO.2 для доступа к файлам
- уменьшено использование кучи из-за нового Lucene50Codec
… но эти функции исходят из самого ядра Lucene. Solr представил:
- улучшено удобство использования для сценариев запуска
- скрипты для установки и запуска сервиса Linux
- распределенный расчет IDF
- возможность регистрировать новые обработчики с помощью API (с помощью jar-загрузок)
- регулирование репликации
- …и так далее
Все эти функции поставляются с первым выпуском ветки 5 Solr, и от будущих выпусков мы можем ожидать еще большего — например, кросс-репликация в центрах обработки данных! Мы хотим начать делиться тем, что мы знаем об этих функциях, и сегодня мы начинаем с регулирования репликации.
Вариант использования
Представьте себе ситуацию, когда ваше развертывание Solr (независимо от того, является ли это SolrCloud или традиционным master-slave) содержит очень большие коллекции / индексы. Это даже легче проиллюстрировать в режиме «ведущий-ведомый» Представьте, что мы принудительно объединяем наш очень большой индекс в один сегмент. Что Solr сделает, это скопирует все индексные файлы с главного на подчиненное, потому что они все изменились. В этих ситуациях репликация может использовать всю пропускную способность сети. Конечно, это означает, что индекс / коллекция будут перенесены как можно скорее; но это также означает, что все запросы и операции индексации могут пострадать, потому что они могут быть замедлены репликацией с использованием всей полосы пропускания. В таких случаях регулирование репликации может быть очень полезным.
Тест
Чтобы проиллюстрировать, как регулирование репликации работает в Solr 5, мы решили использовать две простые конфигурации репликации в среде SolrCloud. В настройке используется коллекция с одним осколком и одной репликой. Осколок лидера содержал около 2 ГБ данных, не много, но более чем достаточно, чтобы показать вам, как это работает.
Репликация без регулирования
Первый тест был выполнен с конфигурацией репликации по умолчанию, которая выглядела следующим образом:
<requestHandler name="/replication" class="solr.ReplicationHandler"> </requestHandler>
Как видите, в этом нет ничего сложного — только конфигурация обработчика репликации по умолчанию. Вот что нам показал SPM Performance Monitoring , когда мы смотрели на показатели использования сети:
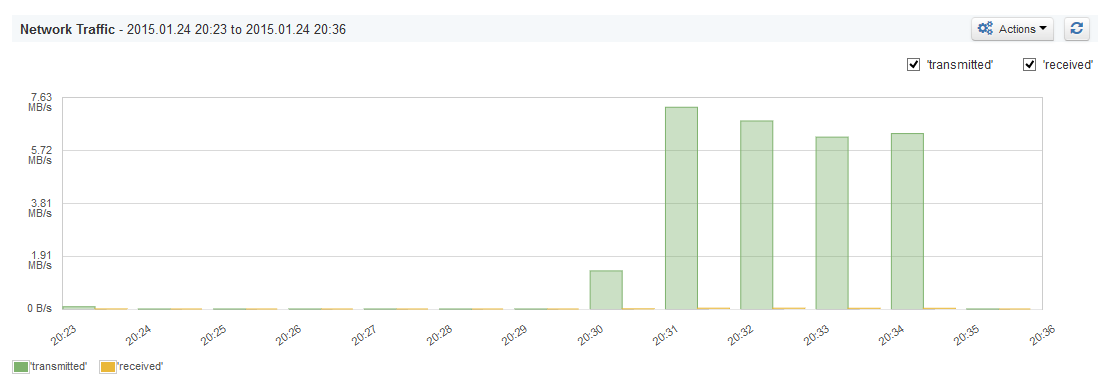
Почти 7,5 МБ / с использования полосы пропускания, и тест проводился в локальной сети, между двумя ПК, подключенными к одной и той же сети Wi-Fi. Если бы индекс составлял несколько сотен ГБ и его пришлось бы перенести, мы бы исчерпали пропускную способность нашей сети на несколько минут — по крайней мере!
Репликация с дросселированием
Второй тест был выполнен, чтобы мы могли увидеть, действительно ли работает регулирование, т. Е. Чтобы убедиться, что мы настроили обработчик репликации для использования полосы пропускания не более 100 КБ / с, что достаточно мало, чтобы увидеть разницу. Наша измененная конфигурация обработчика репликации выглядела следующим образом:
<requestHandler name="/replication" class="solr.ReplicationHandler"> <lst name="defaults"> <str name="maxWriteMBPerSec">0.1</str> </lst> </requestHandler>
Мы ввели свойство maxWriteMBPerSec в разделе по умолчанию конфигурации обработчика и установили его равным 0,1, что означает не более 100 КБ / с. Конечно, мы должны помнить, что это приблизительное значение, поэтому ожидается, что Solr может иногда передавать немного больше данных. Но, в целом, среднее значение не должно превышать установленное нами значение.
Мы снова посмотрели на визуализацию использования сети SPM и увидели следующее:

И это то, что мы ожидали. Мы видели, что почти все время Солр не передавал более 100 КБ / с.
Краткое резюме
Дросселирование репликации в Solr 5 работает; это факт. Далее мы хотели бы видеть API-интерфейс, который позволил бы нам динамически изменять регулирование, поэтому мы можем автоматизировать это в зависимости от наших потребностей, не передавая конфигурацию коллекции в ZooKeeper или перезагружая ядро при развертывании master-slave. Глядя в прошлое на то, как Solr изменился между 4.0 и 4.10, можно ожидать, что в следующих версиях 5.x будет выпущено много приятных функций.