В моем предыдущем посте я показал, как не имеет смысла сравнивать Scala с Java, и в заключение сказал, что когда дело доходит до производительности, вопрос, который вы должны задать, состоит в следующем: «Как Scala поможет мне, когда мои серверы переходят из-за непредвиденной нагрузки ?» В этом посте я постараюсь ответить на этот вопрос и показать, что Scala — действительно лучший язык для построения масштабируемых систем, чем Java.
Однако не ждите, что наше путешествие будет легким. Для начала, хотя очень легко сделать микро тесты, попытаться показать, как приложения реального мира справляются или не справляются с нагрузками, которые на них накладываются, очень сложно, потому что очень сложно создать приложение, достаточно маленькое для демонстрации. и объясните в одном посте, который в то же время достаточно большой, чтобы на самом деле показать, как приложения реального мира ведут себя под нагрузкой, а также очень сложно имитировать нагрузки реального мира. Итак, я собираюсь взять один небольшой аспект чего-то, что может пойти не так в реальном мире, и показать только один способ, которым Scala поможет вам, а Java — нет. Затем я объясню, что это только вершина айсберга, есть гораздо больше ситуаций и гораздо больше возможностей Scala, которые помогут вам в реальном мире.
Интернет-магазин
Для этого упражнения я реализовал интернет-магазин. Архитектура этого магазина представлена на схеме ниже:
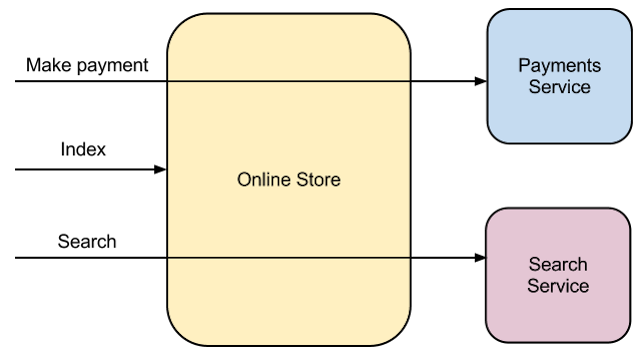
Как вы можете видеть, существует платежная служба и служба поиска, с которой магазин общается, и магазин обрабатывает три типа запросов: один для индексной страницы, не требующей доступа к каким-либо другим службам, другой для осуществления платежей, которые использует сервис платежей, а другой — для поиска в списке товаров магазинов, который использует сервис поиска. Интернет-магазин — это часть системы, которую я собираюсь сравнить, я буду реализовывать одну версию на Java, а другую — в Scala, и сравнивать их. Услуги поиска и оплаты не изменятся. Их фактической реализацией будут простые API-интерфейсы JSON, которые возвращают жестко закодированные значения, но каждый из них будет имитировать время обработки 20 мс.
Для реализации хранилища на Java я собираюсь сделать его максимально простым, используя прямые сервлеты для обработки запросов, HTTP-клиента Apache Commons для выполнения запросов и Jackson для анализа и форматирования JSON. Я разверну приложение в Tomcat и настрою Tomcat с разъемом NIO, используя ограничение по умолчанию 10000 и размер пула потоков 200.
Для реализации Scala я буду использовать Play Framework 2.1, используя API-интерфейс Play WS, поддерживаемый HTTP-клиентом Ning, для выполнения запросов, и API-интерфейс Play JSON, поддерживаемый Джексоном для обработки и анализа JSON. Play Framework построен с использованием Netty, у которого нет ограничения на подключение, и использует Akka для пула потоков, и я настроил его для использования размера пула потоков по умолчанию, который составляет один поток на процессор, а на моей машине их 4.
Тест, который я буду выполнять, будет использовать JMeter. Для каждого типа запроса (индекс, платежи и поиск) у меня будет 300 потоков, вращающихся в цикле, выполняющих запросы со случайной паузой 500-1500 мс между каждым запросом. Это дает среднюю максимальную пропускную способность 300 запросов в секунду на тип запроса или 900 запросов в секунду.
Итак, давайте посмотрим на результат теста Java:
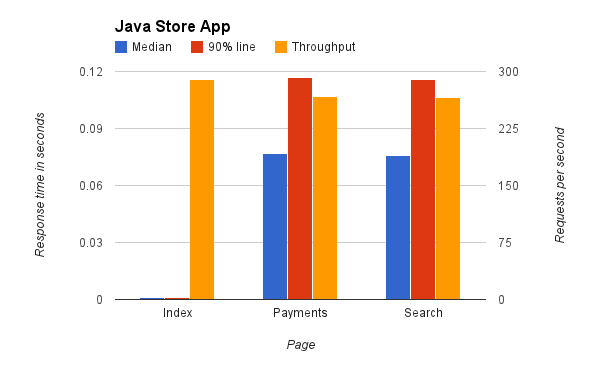
На этом графике я нанес 3 метрики для каждого типа запроса. Медиана — это среднее время запроса. Для страницы индекса это почти ничего, для запросов поиска и платежей — около 77 мс. Я также построил линию 90%, которая является общей метрикой в веб-приложениях, она показывает, что было под 90% запросов, и поэтому дает хорошее представление о том, на что похожи медленные запросы. Это снова показывает почти ничего для страницы индекса и 116мс для запросов поиска и платежей. Последний показатель — это пропускная способность, которая показывает количество запросов в секунду, которые были обработаны. Мы не слишком далеки от теоретического максимума: индекс показывает 290 запросов в секунду, а запросы на поиск и платежи поступают со скоростью около 270 запросов в секунду. Эти результаты хороши,наш Java-сервис без проблем справляется с нагрузкой, которую мы на него бросаем.
Теперь давайте посмотрим на тест Scala:
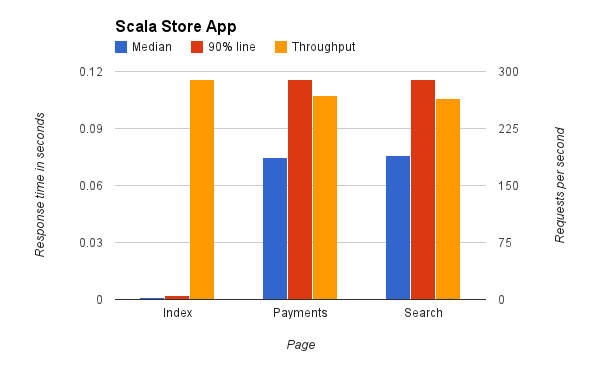
Как видите, он идентичен результатам Java. Это неудивительно, поскольку и реализация Java, и Scala интернет-магазина выполняют абсолютно минимальный рабочий код, большая часть времени уходит на выполнение запросов к удаленным сервисам.
Что-то идет не так
Итак, мы видели две счастливые реализации одной и той же вещи в Scala и Java, игнорируя нагрузку, которую я им предоставляю. Но что происходит, когда все не так хорошо и модно? Что произойдет, если одна из служб, с которой они разговаривают, выйдет из строя? Допустим, поисковая служба начинает отвечать за 30 секунд, после чего возвращает ошибку. Это не является необычной ситуацией сбоя, особенно если вы балансируете нагрузку через прокси-сервер, прокси-сервер пытается подключиться к сервису и через 30 секунд происходит сбой, что приводит к ошибке шлюза. Давайте посмотрим, как наши приложения справляются с нагрузкой, которую я на них сейчас бросаю. Мы ожидаем, что поисковый запрос займет не менее 30 секунд, но как насчет остальных? Вот результаты Java:
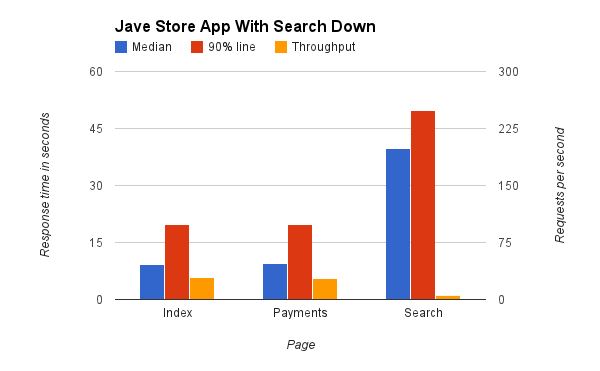
Ну, у нас больше нет счастливого приложения. Поисковые запросы, естественно, занимают много времени, но платежному сервису сейчас требуется в среднем 9 секунд, линия 90% — 20 секунд. Не только это, но и страница индекса подвержена аналогичным последствиям — пользователи не будут ждать так долго, если они заходят на ваш сайт, чтобы показать домашнюю страницу. И пропускная способность каждого снизилась до 30 запросов в секунду. Это нехорошо, потому что ваша поисковая служба вышла из строя, весь ваш сайт теперь практически не работает, и вы скоро начнете терять клиентов и деньги.
Так как же наше приложение Scala справедливо? Давай выясним:
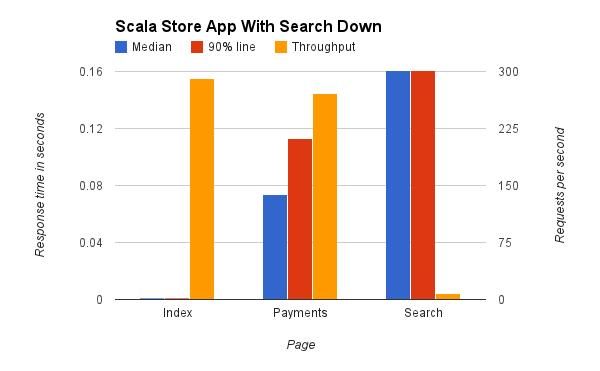
Теперь, прежде чем я скажу что-нибудь еще, позвольте мне отметить, что я ограничил время ответа 160 мс — поисковым запросам на самом деле требуется около 30 секунд, но на графике, с 30 секундами рядом с другими значениями, они вряд ли зарегистрировать строку высотой в пиксель. Итак, что мы видим здесь, так это то, что, хотя поиск непригоден, время и пропускная способность наших платежей и запросов на индексирование остаются неизменными . Очевидно, что клиенты не будут довольны тем, что не могут выполнять поиск, но, по крайней мере, они по-прежнему могут использовать другие части вашего сайта, просматривать вашу домашнюю страницу со специальными предложениями и даже по-прежнему оплачивать товары. И, эй, Google не выключен, они всегда могут использовать Google для поиска вашего сайта. Таким образом, вы можете потерять часть бизнеса, но влияние ограничено.
Итак, в этом тесте мы видим, что Scala выигрывает. Когда что-то пойдет не так, приложение Scala быстро справится с этим, предоставив вам максимум возможностей, в то время как Java-приложение, скорее всего, просто рухнет.
Но я могу сделать это на Java
Теперь начинается бит, где я противостою многим ожидаемым критическим замечаниям, которые люди сделают из этого эталона. И первое, и наиболее очевидное, заключается в том, что в моем решении Scala я использовал асинхронный ввод-вывод, тогда как в своем решении Java я этого не делал, поэтому их нельзя сравнивать. Это правда, я мог бы реализовать асинхронное решение в Java, и в этом случае результаты Java были бы идентичны результатам Scala. Однако, хотя я мог бы это сделать, Java-разработчики этого не делают. Дело не в том, что они не могут, а в том, что они этого не делают. Я написал много веб-приложений на Java, которые делают вызовы в другие системы, и очень редко, и только в особых случаях, я когда-либо использовал асинхронный ввод-вывод. И позвольте мне показать вам, почему.
Допустим, вам нужно выполнить серию вызовов для ряда удаленных сервисов, каждый из которых зависит от данных, полученных из предыдущего. Вот старое доброе синхронное решение в Java:
User user = getUserById(id); List<Order> orders = getOrdersForUser(user.email); List<Product> products = getProductsForOrders(orders); List<Stock> stock = getStockForProducts(products);
Приведенный выше код прост, легок для чтения и кажется вполне естественным для написания Java-разработчиком. Для полноты давайте посмотрим на то же самое в Scala:
val user = getUserById(id) val orders = getOrdersForUser(user.email) val products = getProductsForOrders(orders) val stock = getStockForProducts(products)
Теперь давайте посмотрим на тот же код, но на этот раз, предполагая, что мы делаем асинхронные вызовы и возвращаем результаты в обещаниях. Как это выглядит в Java?
Promise<User> user = getUserById(id);
Promise<List<Order>> orders = user.flatMap(new Function<User, List<Order>>() {
public Promise<List<Order>> apply(User user) {
return getOrdersForUser(user.email);
}
}
Promise<List<Product>> products = orders.flatMap(new Function<List<Order>, List<Product>>() {
public Promise<List<Product>> apply(List<Order> orders) {
return getProductsForOrders(orders);
}
}
Promise<List<Stock>> stock = products.flatMap(new Function<List<Product>, List<Stock>>() {
public Promise<List<Stock>> apply(List<Product> products) {
return getStockForProducts(products);
}
}
Итак, во-первых, приведенный выше код не читабелен, на самом деле за ним гораздо сложнее следить, существует огромный уровень шума для реального кода, который делает вещи, и, следовательно, очень легко совершать ошибки и пропускать вещи. Во-вторых, писать утомительно, ни один разработчик не хочет писать такой код, я ненавижу это делать. Любой разработчик, который хочет написать все свое приложение таким безумным. И, наконец, это просто не кажется естественным, это не то, как вы делаете вещи в Java, это не идиоматично, это не очень хорошо сочетается с остальной частью экосистемы Java, сторонние библиотеки плохо интегрируются с этим стилем , Как я уже говорил, разработчики Java могут писать код, который делает это, но они этого не делают , и, как вы можете видеть, они не делают этого по уважительной причине.
Итак, давайте посмотрим на асинхронное решение в Scala:
for {
user <- getUserById(id)
orders <- getOrdersForUser(user.email)
products <- getProductsForOrders(orders)
stock <- getStockForProducts(products)
} yield stock
В отличие от асинхронного решения Java, это решение полностью читаемо, так же, как и синхронные решения Scala и Java. И это не просто странная функция Scala, которую большинство разработчиков Scala никогда не трогают, это то, как типичный разработчик Scala пишет код каждый день . Библиотеки Scala предназначены для работы с использованием этих идиом, это естественно, язык работает с вами . Забавно писать такой код в Scala!
Этот пост не о том, как на одном языке вы можете написать высоко настроенное приложение для производительности, которое быстрее, чем то же приложение, написанное на другом языке, высоко настроенном для производительности. В этом посте рассказывается о том, как Scala помогает создавать приложения, которые по умолчанию масштабируются, используя естественный, читаемый и идиоматический код. Точно так же, как у шара в лужайках есть предвзятость, у Scala есть склонность помогать вам писать масштабируемые приложения, где Java заставляет вас плыть по течению.
Но масштабирование означает гораздо больше, чем это
Приведенный мною пример хорошо масштабируемого Scala, где нет Java, является очень конкретным примером, но тогда какой ситуации, когда ваше приложение терпит неудачу при высокой нагрузке, нет? Позвольте мне привести несколько других примеров, когда гораздо более приятная поддержка асинхронного ввода-вывода в Scala помогает вам писать масштабируемый код:
- Используя Akka, вы можете легко определять участников для разных типов запросов и распределять их по разным ресурсам. Таким образом, если определенные части вашего отдельного приложения начинают испытывать трудности или получают неожиданную нагрузку, эти части могут перестать отвечать на запросы, но остальная часть вашего приложения может оставаться работоспособной.
- Scala, Play и Akka упрощают обработку отдельных запросов, используя несколько потоков, выполняющихся параллельно, выполняя различные операции, что позволяет получать запросы, которые выполняют много задач за очень короткое время. Klout написал отличную статью о том, как они сделали это в своем API.
- Поскольку асинхронный ввод-вывод настолько прост, выгрузка обработки на другие машины может быть безопасно выполнена без привязки потоков на первом компьютере.
Java 8 сделает асинхронный ввод-вывод простым в Java
Java 8, вероятно, будет включать в себя поддержку некоторых замыканий, что является отличной новостью для мира Java, особенно если вы хотите выполнять асинхронный ввод-вывод. Тем не менее, синтаксис все еще не будет доступен для чтения, как код Scala, который я показал выше. И когда выйдет Java 8? Java 7 была выпущена в прошлом году, и потребовалось 5 лет, чтобы выпустить это. Java 8 запланирована на лето 2013 года, но даже если она прибудет по графику, сколько времени потребуется экосистеме, чтобы наверстать упущенное? И сколько времени потребуется разработчикам Java, чтобы переключиться с синхронного мышления на асинхронное? На мой взгляд, Java 8 слишком мало, слишком поздно.
Так это все об асинхронном вводе-выводе?
Пока что все, о чем я говорил и показал, это то, как легко Scala делает асинхронный ввод-вывод, и как это помогает вам масштабироваться. Но это не останавливается там. Позвольте мне выбрать еще одну особенность Scala — неизменность.
Когда вы начинаете использовать несколько потоков для обработки отдельных запросов, вы начинаете делиться состоянием между этими потоками. И здесь все становится очень грязно, потому что мир общего состояния в компьютерной системе — это безумный мир, в котором происходят невозможные вещи. Это мир тупиков, мир обновления памяти в одном потоке, но другой поток не видит этих изменений, мир условий гонки и мир узких мест производительности, потому что вы с энтузиазмом пометили некоторые методы как синхронизированные.
Тем не менее, это не так уж и плохо, потому что есть очень простое решение, сделать все ваше состояние неизменным. Если все ваше состояние неизменно, то ни одна из вышеперечисленных проблем не может возникнуть. И это снова, где Scala помогает вам много времени, потому что в Scala вещи неизменны по умолчанию. API коллекции являются неизменяемыми, вы должны явно запросить изменяемую коллекцию, чтобы получить изменяемые коллекции.
Теперь в Java вы можете сделать вещи неизменными. Есть несколько библиотек, которые помогают вам (хотя и неуклюже) работать с неизменяемыми коллекциями. Но так легко случайно забыть сделать что-то изменчивое. Java API и сам язык не облегчают работу с неизменяемыми структурами, и если вы используете стороннюю библиотеку, весьма вероятно, что она не использует неизменяемые структуры и часто требует использования изменяемых структур, например JPA требует этого.
Давайте посмотрим на некоторый код. Вот неизменный класс в Scala:
case class User(id: Long, name: String, email: String)
Эта структура неизменна. Более того, он автоматически генерирует средства доступа к свойствам. Давайте посмотрим на соответствующую Java:
public class User {
private final long id;
private final String name;
private final String email;
public User(long id, String name, String email) {
this.id = id;
this.name = name;
this.email = email;
}
public long getId() {
return id;
}
public String getName() {
return name;
}
public String getEmail() {
return email
}
}
Это огромное количество кода! А что если я добавлю новое свойство? Я должен добавить новый параметр в мой конструктор, который сломает существующий код, или я должен определить второй конструктор. В Scala я могу просто сделать это:
case class User(id: Long, name: String, email: String, company: Option[Company] = None)
Весь мой существующий код, который вызывает этот конструктор, все еще будет работать. А как насчет того, когда этот объект вырастет до 10 элементов в конструкторе, его создание становится кошмаром! Решением этой проблемы в Java является использование шаблона компоновщика, который более чем удваивает объем кода, который вы должны написать для объекта. В Scala вы можете называть параметры, поэтому легко увидеть, какой параметр какой, и они не обязательно должны быть в правильном порядке. Но, возможно, я захочу просто изменить одно свойство. Это можно сделать в Scala следующим образом:
mail: String, company: Option[Company] = None) {
def copy(id: Long = id, name: String = name, email: String = email, company: Option[Company] = company) = User(id, name, email, company)
}
val james = User(1, "James", "james@jazzy.id.au")
val jamesWithCompany = james.copy(company = Some(Company("Typesafe")))
Приведенный выше код является естественным, простым, читаемым, так разработчики Scala пишут код каждый день и неизменны. Он подходит для параллельного кода и позволяет безопасно писать системы, которые масштабируются. То же самое можно сделать на Java, но это утомительно и совсем не радостно писать. Я большой сторонник неизменного кода на Java, и я написал много неизменных классов на Java, и это больно, но это меньше, чем два. В Scala требуется больше кода для использования изменяемых объектов, чем для использования неизменяемого. Опять же, Scala склонен помогать вам масштабироваться.
Вывод
Я не могу подробно описать все способы, которыми Scala помогает вам масштабировать, а Java — нет. Но я надеюсь, что я дал вам представление о том, почему Scala на вашей стороне, когда речь идет о написании масштабируемых систем. Я показал некоторые конкретные метрики, я сравнил решения Java и Scala для написания масштабируемого кода, и я показал, что не системы Scala всегда будут масштабироваться лучше, чем системы Java, а скорее то, что Scala — это язык, который используется в вашей системе. сторона при написании масштабируемых систем. Он смещен в сторону масштабирования, он поощряет практики, которые помогают вам масштабироваться. Java, напротив, затрудняет вам реализацию этих методов, она работает против вас.
Если вас интересует мой код для интернет-магазина, вы можете найти его в этом репозитории GitHub . Цифры из моего теста производительности можно найти в этой таблице .