Мы уже ввели несколько терминов синтаксического анализа, перечисляя основные инструменты и библиотеки, используемые для синтаксического анализа в Java , C # , Python и JavaScript . В этой статье мы более подробно представим концепции и алгоритмы, используемые при разборе, чтобы вы могли лучше понять этот захватывающий мир.
Мы постарались быть практичными в этой статье. Наша цель — помочь практикующим, а не объяснить полную теорию. Мы просто объясним, что вам нужно знать, чтобы понять и построить парсер.
После определения разбора статья делится на три части:
- Большая картина . Раздел, в котором мы описываем основные термины и компоненты синтаксического анализатора.
- Грамматика В этой части мы объясняем основные форматы грамматики и наиболее распространенные проблемы при их написании.
- Алгоритмы разбора . Здесь мы обсудим все наиболее используемые алгоритмы синтаксического анализа и скажем, для чего они хороши.
Определение синтаксического анализа
Анализ входа, чтобы организовать данные в соответствии с правилом грамматики
Есть несколько способов определения парсинга. Однако суть остается той же: синтаксический анализ означает нахождение базовой структуры данных, которые нам дают.
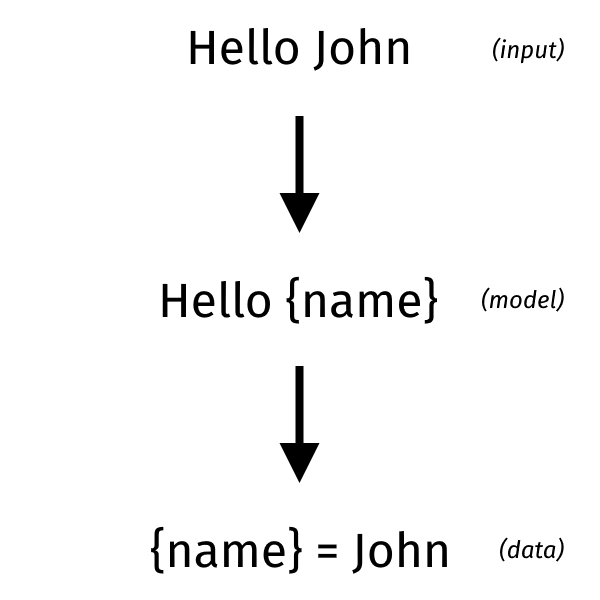
В некотором смысле синтаксический анализ может рассматриваться как обратный шаблону: определение структуры и извлечение данных. Вместо этого у нас есть структура, и мы заполняем ее данными. В случае разбора вы должны определить модель из необработанного представления. В то время как для создания шаблонов вы должны объединить данные с моделью, чтобы создать необработанное представление. Необработанное представление обычно представляет собой текст, но это также могут быть двоичные данные.
Фундаментальный анализ необходим, потому что разные сущности нуждаются в данных в разных формах. Синтаксический анализ позволяет преобразовывать данные так, чтобы их можно было понять конкретным программным обеспечением. Очевидным примером являются программы: они написаны людьми, но должны выполняться компьютерами. Таким образом, люди пишут их в форме, которую они могут понять, а затем программное обеспечение преобразует их так, чтобы их мог использовать компьютер.
Однако анализ может потребоваться даже при передаче данных между двумя программами, которые имеют разные потребности. Например, это необходимо, когда вам нужно сериализовать или десериализовать класс.
Большая картина

В этом разделе мы собираемся описать основные компоненты синтаксического анализатора. Мы не пытаемся дать вам формальные объяснения, но практические.
Обычные выражения
Последовательность символов, которые могут быть определены шаблоном
Регулярное выражение часто рекламируется как вещь, которую вы не должны использовать для разбора. Это не совсем правильно, потому что вы можете использовать регулярные выражения для анализа простого ввода. Проблема в том, что некоторые программисты знают только регулярные выражения. Поэтому они используют их, чтобы попытаться разобрать все, даже то, что не следует. Результатом обычно является взломанная вместе серия регулярных выражений, которые очень хрупки.
Вы можете использовать регулярные выражения для анализа некоторых более простых языков, но это исключает большинство языков программирования. Даже те, которые выглядят достаточно просто, как HTML. Фактически, языки, которые можно анализировать только с помощью регулярных выражений, называются регулярными языками. Существует формальное математическое определение, но это выходит за рамки данной статьи.
Хотя одним из важных следствий теории является то, что регулярные языки могут быть проанализированы или выражены также с помощью конечного автомата . То есть регулярные выражения и конечные автоматы одинаково мощны. Это причина, потому что они используются для реализации лексеров, как мы увидим позже.
Обычный язык может быть определен серией регулярных выражений, в то время как более сложные языки требуют чего-то большего. Простое правило: если грамматика языка имеет рекурсивные или вложенные элементы, это не обычный язык. Например, HTML может содержать произвольное количество тегов внутри любого тега, поэтому не является обычным языком и не может быть проанализирован с использованием исключительно регулярных выражений, независимо от того, насколько он умный.
Регулярные выражения в грамматике
Знакомство типичного программиста с регулярными выражениями позволяет их часто использовать для определения грамматики языка. Точнее, их синтаксис используется для определения правил лексера или парсера. Например, звезда Клини ( * ) используется в правиле, чтобы указать, что конкретный элемент может присутствовать ноль или бесконечное количество раз.
Определение правила не следует путать с реализацией фактического лексера или парсера. Вы можете реализовать лексер, используя механизм регулярных выражений, предоставляемый вашим языком. Однако обычно регулярные выражения, определенные в грамматике, преобразуются и преобразуются в конечный автомат для повышения производительности.
Структура парсера
Теперь, уточнив роль регулярных выражений, мы можем взглянуть на общую структуру синтаксического анализатора. Полный анализатор обычно состоит из двух частей: лексера , также известного как сканер или токенизатор , и правильного синтаксического анализатора. Для синтаксического анализатора нужен лексер, потому что он работает не с текстом, а с выводом, созданным лексером. Не все парсеры принимают эту двухэтапную схему: некоторые парсеры не зависят от отдельного лексера и объединяют два шага. Их называют сканерами без сканера .
Лексер и анализатор работают последовательно: лексер сканирует входные данные и выдает совпадающие токены, анализатор затем сканирует токены и выдает результат анализа.
Давайте посмотрим на следующий пример и представим, что мы пытаемся разобрать дополнение.
|
1
|
437 + 734 |
Лексер сканирует текст и находит 4 , 3 , 7 а затем пробел ( ) . Задача лексера — признать, что символы 437 составляют один токен типа NUM . Затем лексер находит символ + , который соответствует второму токену типа PLUS , и, наконец, он находит другой токен типа NUM . 
Парсер обычно объединяет токены, созданные лексером, и группирует их.
Определения, используемые лексерами и парсерами, называются правилами или продукцией . В нашем примере правило лексера будет указывать, что последовательность цифр соответствует токену типа NUM, а правило синтаксического анализатора будет указывать, что последовательность токенов типа NUM, PLUS, NUM соответствует выражению суммы .
Сейчас типично найти наборы, которые могут генерировать как лексер, так и парсер. В прошлом вместо этого было более распространенным объединять два разных инструмента: один для создания лексера и один для создания парсера. Например, это было в случае с почтенной парой lex & yacc: с помощью lex можно было сгенерировать лексер, а с помощью yacc можно было сгенерировать парсер
Сканеры без сканера
Парсеры без сканера работают по-разному, потому что они обрабатывают непосредственно исходный текст вместо обработки списка токенов, созданных лексером. То есть парсер без сканера работает как лексер и парсер вместе.
Хотя для целей отладки, безусловно, важно знать, является ли конкретный инструмент анализа синтаксическим анализатором без сканера или нет, во многих случаях не имеет смысла определять грамматику. Это потому, что вы обычно определяете шаблон, который группирует последовательность символов для создания (виртуальных) токенов; затем вы объединяете их для получения окончательного результата. Это просто потому, что так удобнее. Другими словами, грамматика синтаксического анализатора без сканера очень похожа на грамматику для инструмента с отдельными шагами. Опять же, вы не должны путать, как вещи определены для вашего удобства и как все работает за сценой.
грамматика
Формальная грамматика — это набор правил, которые синтаксически описывают язык
В этом определении есть две важные части: грамматика описывает язык, но это описание относится только к синтаксису языка, а не к семантике. То есть он определяет свою структуру, но не ее значение. Правильность значения ввода должна быть проверена, если необходимо, каким-либо другим способом.
Например, представьте, что мы хотим определить грамматику для языка, показанного в параграфе « Определение» .
|
1
2
3
|
HELLO: "Hello"NAME: [a-zA-Z]+greeting: HELLO NAME |
Эта грамматика принимает ввод, такой как "Hello Michael" и "Hello Programming" . Они оба синтаксически верны, но мы знаем, что «Программирование» — это не имя. Таким образом, это семантически неправильно. Грамматика не определяет семантические правила, и они не проверяются парсером. Вам нужно будет проверить достоверность предоставленного имени другим способом, например, сравнив его с базой данных действительных имен.
Анатомия Грамматики
Чтобы определить элементы грамматики, давайте рассмотрим пример в наиболее часто используемом формате для описания грамматики: форма Бэкуса-Наура (BNF) . Этот формат имеет много вариантов, включая расширенную форму Бэкуса-Наура . Расширенный вариант имеет то преимущество, что включает простой способ обозначения повторений. Другим известным вариантом является расширенная форма Бэкуса-Наура, которая в основном используется для описания протоколов двунаправленной связи.
Типичное правило в грамматике Бэкуса-Наура выглядит следующим образом:
|
1
|
<symbol> ::= __expression__ |
<Simbol> является нетерминалом , что означает, что его можно заменить на группу элементов справа, __expression__ . Элемент __expression__ может содержать другие нетерминальные или терминальные символы. Терминальные символы — это просто те, которые не отображаются в виде <символа> где-нибудь в грамматике. Типичным примером терминального символа является строка символов, например «Hello».
Правило также можно назвать производственным правилом . Технически это определяет преобразование между нетерминалом и множеством нетерминалов и терминалов справа.
Типы Грамматик
В основном при разборе используются два вида грамматик: обычные грамматики и контекстно-свободные грамматики . Обычно одному виду грамматики соответствует язык того же типа: обычная грамматика определяет обычный язык и так далее. Тем не менее, существует также более свежий вид грамматик, называемых грамматикой синтаксического анализа (PEG), который столь же эффективен, как и контекстно-свободные грамматики, и, следовательно, определяет язык без контекста. Разница между ними заключается в обозначениях и интерпретации правил.
Как мы уже упоминали, два типа языков находятся в иерархии сложности: обычные языки проще, чем контекстно-свободные языки.
Относительно простой способ различить две грамматики состоит в том, что __expression__ обычной грамматики, то есть правая часть правила, может быть только одним из:
- пустая строка
- один символ терминала
- один конечный символ, за которым следует нетерминальный символ
На практике это сложнее проверить, потому что конкретный инструмент может позволить использовать больше терминальных символов в одном определении. Тогда сам инструмент автоматически преобразует это выражение в эквивалентную серию выражений, все принадлежащие одному из трех упомянутых случаев.
Таким образом, вы можете написать выражение, которое несовместимо с обычным языком, но выражение будет преобразовано в правильную форму. Другими словами, инструмент может предоставить синтаксический сахар для написания грамматик.
В следующем параграфе мы подробнее обсудим различные виды грамматик и их форматы.
лексер
Лексер преобразует последовательность символов в последовательность токенов
Лексеры также известны как сканеры или токенизаторы . Лексеры играют роль в синтаксическом анализе, потому что они преобразуют начальный ввод в форму, которая более управляема соответствующим анализатором, который работает на более позднем этапе. Обычно лексеры легче писать, чем парсеры. Хотя есть особые случаи, когда оба довольно сложны, например, в случае с C (см. Рубрику lexer ).
Очень важной частью работы лексера является работа с пробелами. В большинстве случаев вы хотите, чтобы лексер отбрасывал пробелы. Это потому, что в противном случае парсер должен был бы проверять наличие пробелов между каждым токеном, что быстро становилось раздражающим.
Есть случаи, когда вы не можете сделать это, потому что пробел имеет отношение к языку, как в случае с Python, где используется для идентификации блока кода. Однако даже в этих случаях обычно именно лексер решает проблему отличия релевантного пробела от несущественного. Это означает, что вы хотите, чтобы лексер понимал, какие пробелы имеют отношение к разбору. Например, при разборе Python вы хотите, чтобы лексер проверил, определяют ли пробелы отступы (релевантные) или пробел между ключевым словом if и следующим выражением (неактуальным).
Где заканчивается Lexer и начинается парсер
Учитывая, что лексеры почти исключительно используются вместе с синтаксическими анализаторами, разделительная линия между ними может быть размыта время от времени. Это потому, что синтаксический анализ должен давать результат, который полезен для конкретной потребности программы. Таким образом, существует не только один правильный способ синтаксического анализа чего-либо, но вы заботитесь только о том, чтобы удовлетворить ваши потребности.
Например, представьте, что вы создаете программу, которая должна анализировать журналы сервера, чтобы сохранить их в базе данных. Для этой цели лексер определит последовательность чисел и точек и преобразует их в токен IPv4.
|
1
|
IPv4: [0-9]+ "." [0-9]+ "." [0-9]+ "." [0-9]+ |
Затем анализатор проанализирует последовательность токенов, чтобы определить, является ли это сообщением, предупреждением и т. Д.
Что бы произошло вместо этого, если бы вы разрабатывали программное обеспечение, которое должно было использовать IP-адрес для определения страны посетителя? Возможно, вы захотите, чтобы лексер идентифицировал октеты адреса для дальнейшего использования и сделал IPv4 элементом синтаксического анализатора.
|
1
2
3
4
|
DOT : "."OCTET : [0-9]+ ipv4 : OCTET DOT OCTET DOT OCTET DOT OCTET |
Это один из примеров того, как одна и та же информация может быть проанализирована по-разному из-за разных целей.
синтаксический анализатор
В контексте анализа синтаксический анализатор может относиться как к программному обеспечению, которое выполняет весь процесс, так и просто к соответствующему анализатору, который анализирует токены, генерируемые лексером. Это просто следствие того факта, что синтаксический анализатор заботится о самой важной и сложной части всего процесса синтаксического анализа. Под самым важным мы подразумеваем, что пользователь заботится о большинстве и будет на самом деле видит. На самом деле, как мы уже говорили, лексер работает как помощник для облегчения работы парсера.
В каком-то смысле вы имеете в виду синтаксический анализатор, его вывод — это организованная структура кода, обычно дерево. Дерево может быть деревом разбора или абстрактным синтаксическим деревом . Оба они являются деревьями, но отличаются тем, насколько близко они представляют реальный написанный код и промежуточные элементы, определенные синтаксическим анализатором. Граница между этими двумя временами может быть размытой, мы увидим их различия немного лучше в следующем параграфе.
Форма дерева выбрана потому, что это простой и естественный способ работы с кодом на разных уровнях детализации. Например, класс в C # имеет одно тело, это тело состоит из одного оператора, оператора блока, который представляет собой список операторов, заключенных в пару фигурных скобок, и так далее…
Синтаксическая и семантическая корректность
Парсер — это фундаментальная часть компилятора или интерпретатора, но, конечно, он может быть частью другого программного обеспечения. Например, в нашей статье « Создание диаграмм из исходного кода C # с использованием Roslyn» мы проанализировали файлы C # для создания диаграмм.
Синтаксический анализатор может проверять только синтаксическую корректность фрагмента кода, но компилятор может использовать свой вывод также в процессе проверки семантической достоверности того же фрагмента кода.
Давайте посмотрим на пример кода, который синтаксически правильный, но семантически неверный.
|
1
2
|
int x = 10int sum = x + y |
Проблема в том, что одна переменная ( y ) никогда не определяется и, следовательно, в случае ее выполнения программа завершится ошибкой. Однако синтаксический анализатор не может этого знать, потому что он не отслеживает переменные, он просто смотрит на структуру кода.
Вместо этого компилятор обычно сначала просматривает дерево разбора и хранит список всех определенных переменных. Затем он повторно просматривает дерево разбора и проверяет, все ли используемые переменные определены правильно. В этом примере их нет, и он выдаст ошибку. Так что это один из способов, которым дерево разбора может также использоваться для проверки семантики компилятором.
Парсер без сканера
Парсер без сканера , или реже парсер без лексера , — это парсер, который выполняет токенизацию (т. Е. Преобразование последовательности символов в токенах) и правильный синтаксический анализ за один шаг. Теоретически наличие отдельного лексера и анализатора является предпочтительным, поскольку оно позволяет более четко разделить цели и создать более модульный анализатор.
Сканер без сканера — лучший дизайн для языка, где четкое различие между лексером и парсером затруднено или не нужно. Примером является синтаксический анализатор для языка разметки, где в море текста вставляются специальные маркеры. Это также может облегчить работу с языками, в которых традиционный лексинг затруднен, например C. Это происходит потому, что анализатор без сканера может легче справляться со сложными токенизациями.
Проблемы с анализом реальных языков программирования
Теоретически современный синтаксический анализ предназначен для работы с реальными языками программирования, на практике возникают проблемы с некоторыми реальными языками программирования. По крайней мере, их было бы сложнее разобрать, используя обычные инструменты генератора разбора.
Контекстно-зависимые части
Инструменты синтаксического анализа традиционно предназначены для работы с контекстно-свободными языками, но иногда языки чувствительны к контексту. Это может быть в случае упрощения жизни программистов или просто из-за плохого дизайна. Я помню, как читал о программисте, который думал, что он может создать синтаксический анализатор для C за неделю, но потом он обнаружил так много угловых случаев, что через год он все еще работал над этим…
Типичным примером контекстно-зависимых элементов являются так называемые мягкие ключевые слова, то есть строки, которые в определенных местах могут рассматриваться как ключевые слова, но в противном случае могут использоваться в качестве идентификаторов).
Пробелы
Пробелы играют важную роль в некоторых языках. Наиболее известным примером является Python, где отступ оператора указывает, является ли он частью определенного блока кода.
В большинстве мест пробел не имеет значения даже в Python: пробелы между словами или ключевыми словами не имеют значения. Настоящая проблема — это отступ, который используется для идентификации блока кода. Самый простой способ справиться с этим — проверить отступ в начале строки и преобразовать в соответствующий токен, т. Е. Создать токен, когда отступ изменяется от предыдущей строки.
На практике пользовательские функции в лексере производят токены INDENT и DEDENT, когда отступ увеличивается или уменьшается. Эти токены играют роль, которую в C-подобных языках играют фигурные скобки: они указывают начало и конец блоков кода.
Этот подход делает лексинг контекстно-зависимым, а не контекстно-свободным. Это усложняет синтаксический анализ, и вы, как правило, не хотите этого делать, но вы вынуждены это делать в этом случае.
Несколько Синтаксисов
Другая распространенная проблема связана с тем фактом, что язык может фактически включать несколько различных синтаксисов. Другими словами, один и тот же исходный файл может содержать разделы кода, которые следуют другому синтаксису. В контексте эффективного анализа один и тот же исходный файл содержит разные языки. Наиболее известным примером является, вероятно, препроцессор C или C ++, который на самом деле является довольно сложным языком и может волшебным образом появляться внутри любого случайного кода C.
Более простым случаем являются аннотации, которые присутствуют во многих современных языках программирования. Среди прочего они могут быть использованы для обработки кода до его поступления в компилятор. Они могут дать команду процессору аннотаций каким-либо образом преобразовать код, например, для выполнения определенной функции перед выполнением аннотированной. Им легче управлять, потому что они могут появляться только в определенных местах.
Висячий остальное
Болтание else является распространенной проблемой при разборе, связанной с оператором if-then-else . Поскольку предложение else является необязательным, последовательность операторов if может быть неоднозначной. Например, этот.
|
1
2
3
4
|
if one then if two then twoelse ??? |
Неясно, принадлежит ли else первому if или второму.
Честно говоря, это по большей части проблема языкового дизайна. Большинство решений на самом деле не сильно усложняет синтаксический анализ, например, требует использования endif или использования блоков для разграничения оператора if когда он включает в себя предложение else.
Однако существуют также языки, которые не предлагают решения, то есть, которые разработаны неоднозначно, например (как вы уже догадались) C. Обычный подход заключается в том, чтобы связать else с ближайшим оператором if, что делает синтаксический анализ контекстно-зависимым.
Дерево синтаксического анализа и абстрактное синтаксическое дерево
Есть два термина, которые связаны между собой, и иногда они используются взаимозаменяемо: дерево разбора и абстрактное синтаксическое дерево (AST). Технически дерево синтаксического анализа также можно назвать конкретным синтаксическим деревом (CST), поскольку оно должно более конкретно отражать фактический синтаксис входных данных, по крайней мере, по сравнению с AST.
Концептуально они очень похожи. Они оба дерева : есть корень, в котором есть узлы, представляющие весь исходный код. Корень имеет дочерние узлы, которые содержат поддеревья, представляющие все меньшие и меньшие части кода, пока в дереве не появятся одиночные токены (терминалы).
Разница заключается в уровне абстракции: дерево разбора может содержать все токены, появившиеся в программе, и, возможно, набор промежуточных правил. Вместо этого AST является полированной версией дерева разбора, в котором поддерживается только информация, относящаяся к пониманию кода. Мы собираемся увидеть пример промежуточного правила в следующем разделе.
Некоторая информация может отсутствовать как в AST, так и в дереве разбора. Например, комментарии и символы группировки (то есть круглые скобки) обычно не представлены. Такие вещи, как комментарии, являются излишними для программы, а символы группировки неявно определяются структурой дерева.
От дерева разбора к абстрактному синтаксическому дереву
Дерево разбора — это представление кода, более близкого к конкретному синтаксису. Он показывает много деталей реализации парсера. Например, обычно каждое правило соответствует определенному типу узла. Дерево разбора обычно преобразуется в AST пользователем, возможно, с некоторой помощью генератора парсера. Общая справка позволяет аннотировать некоторые правила в грамматике, чтобы исключить соответствующие узлы из сгенерированного дерева. Еще один вариант — свернуть некоторые виды узлов, если у них только один дочерний узел.
Это имеет смысл, потому что дерево синтаксического анализа легче создать для синтаксического анализатора, поскольку оно является прямым представлением процесса синтаксического анализа. Однако AST проще и легче обрабатывать с помощью следующих шагов программы. Обычно они включают в себя все операции, которые вы можете выполнять над деревом: проверка кода, интерпретация, компиляция и т. Д.
Давайте посмотрим на простой пример, чтобы показать разницу между деревом разбора и AST. Давайте начнем с примера грамматики.
|
1
2
3
4
5
6
7
8
|
// lexerPLUS: '+'WORD_PLUS: 'plus'NUMBER: [0-9]+ // parser// the pipe | symbol indicate an alternative between the twosum: NUMBER (PLUS | WORD_PLUS) NUMBER |
В этой грамматике мы можем определить сумму, используя в качестве операторов символ плюс ( + ) или строку plus . Представьте, что вам нужно разобрать следующий код.
|
1
|
10 plus 21 |
Это могут быть результирующее дерево разбора и абстрактное синтаксическое дерево.
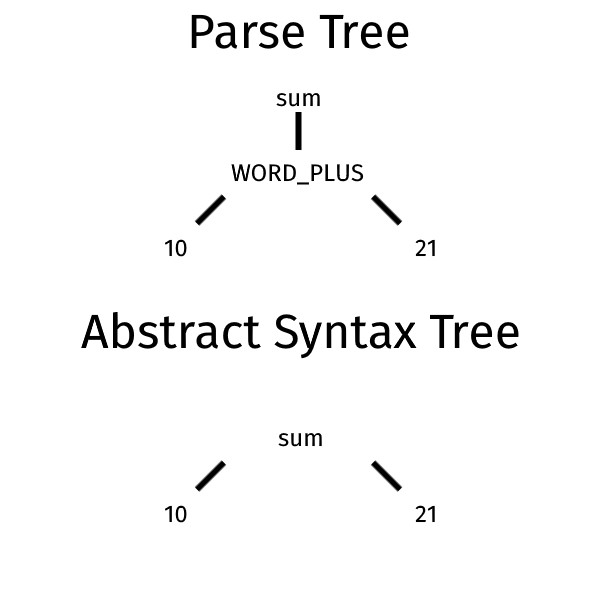
В AST индикация конкретного оператора исчезает, и остается только операция, которую нужно выполнить. Конкретный оператор является примером промежуточного правила.
Графическое представление дерева
Результатом синтаксического анализатора является дерево, но дерево также может быть представлено графическим способом. Это должно облегчить понимание для разработчика. Некоторые инструменты генератора синтаксического анализа могут выводить файл на языке DOT, языке, предназначенном для описания графов (дерево — это особый вид графов). Затем этот файл подается в программу, которая может создать графическое представление, начиная с этого текстового описания (например, Graphviz ).
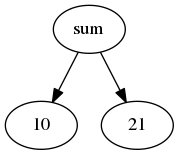
Давайте посмотрим текст .DOT, основанный на предыдущем примере суммы.
|
1
2
3
4
|
digraph sum { sum -> 10; sum -> 21;} |
Соответствующий инструмент может создать следующее графическое представление.
Если вы хотите больше узнать о DOT, вы можете прочитать нашу статью Протокол языкового сервера: языковой сервер для DOT с кодом Visual Studio . В этой статье мы покажем, как создать плагин кода Visual Studio, который может обрабатывать файлы DOT.
грамматики

Грамматика — это набор правил, используемых для описания языка, поэтому естественно изучать форматы правил. Однако есть также несколько элементов типичной грамматики, которые могут потребовать дальнейшего внимания. Некоторые из них связаны с тем, что грамматику также можно использовать для определения других обязанностей или выполнения некоторого кода.
Типичные грамматические проблемы
Сначала мы поговорим о некоторых специальных правилах или проблемах, с которыми вы можете столкнуться при разборе.
Недостающие токены
Если вы читаете грамматику, вы, вероятно, столкнетесь со многими, в которых определены только несколько токенов, но не со всеми. Как в этой грамматике:
|
1
2
|
NAME : [a-zA-Z]+greeting : "Hello" NAME |
Для токена "Hello" нет определения, но, поскольку вы знаете, что парсер работает с токенами, вы можете спросить себя, как это возможно. Ответ в том, что некоторые инструменты генерируют для вас соответствующий токен для строкового литерала, чтобы сэкономить ваше время.
Имейте в виду, что это может быть возможно только при определенных условиях. Например, с ANTLR вы должны определить все токены самостоятельно, если вы определяете отдельные грамматики лексера и синтаксического анализатора.
Леворекурсивные правила
В контексте синтаксических анализаторов важной особенностью является поддержка леворекурсивных правил. Это означает, что правило начинается со ссылки на себя. Иногда эта ссылка также может быть косвенной, то есть она может появиться в другом правиле, на которое ссылается первое.
Рассмотрим для примера арифметические операции. Дополнение может быть описано как два выражения (ий), разделенных символом плюс ( + ), но операнды дополнений могут быть другими дополнениями.
|
1
2
3
4
|
addition : expression '+' expressionmultiplication : expression '*' expression// an expression could be an addition or a multiplication or a numberexpression : multiplication | addition | [0-9]+ |
В этом примере выражение содержит косвенную ссылку на себя через правила сложения и умножения .
Это описание также соответствует нескольким дополнениям, таким как 5 + 4 + 3 . Это связано с тем, что его можно интерпретировать как expression (5) ('+') expression(4+3) (дополнение к правилу: первое выражение соответствует опции [0-9] +, второе — другое дополнение). И тогда само 4 + 3 можно разделить на две составляющие: expression(4) ('+') expression(3) (дополнение к правилу: как первое, так и второе выражение соответствует опции [0-9] +).
Проблема в том, что леворекурсивные правила не могут использоваться с некоторыми генераторами синтаксических анализаторов. Альтернатива — длинная цепочка выражений, которая заботится также о приоритете операторов. Типичная грамматика для парсера, который не поддерживает такие правила, будет выглядеть примерно так:
|
1
2
3
4
|
expression : additionaddition : multiplication ('+' multiplication)*multiplication : atom ('*' atom)*atom : [0-9]+ |
Как видите, выражения определены в обратном порядке приоритета. Таким образом, синтаксический анализатор поместил бы выражение с более низким приоритетом на самый низкий уровень из трех; таким образом, они будут казнены первыми.
Некоторые генераторы парсеров поддерживают прямые леворекурсивные правила, но не косвенные. Обратите внимание, что обычно проблема связана с самим алгоритмом синтаксического анализа, который не поддерживает леворекурсивные правила. Таким образом, генератор синтаксического анализатора может соответствующим образом преобразовывать правила, написанные как леворекурсивные, чтобы заставить его работать со своим алгоритмом. В этом смысле леворекурсивная поддержка может быть (очень полезным) синтаксическим сахаром.
Как трансформируются леворекурсивные правила
Конкретный способ преобразования правил варьируется от одного генератора синтаксического анализатора к другому, однако логика остается той же. Выражения разделены на две группы: с оператором и двумя операндами и атомарные. В нашем примере единственным атомарным выражением является число ( [0-9]+ ), но оно также может быть выражением в скобках ( (5 + 4) ). Это потому, что в математике круглые скобки используются для увеличения приоритета выражения.
Когда у вас есть эти две группы: вы поддерживаете порядок членов второй группы и меняете порядок членов первой группы. Причина в том, что люди рассуждают по принципу «первым пришел — первым обслужен»: легче написать выражения в порядке их старшинства.
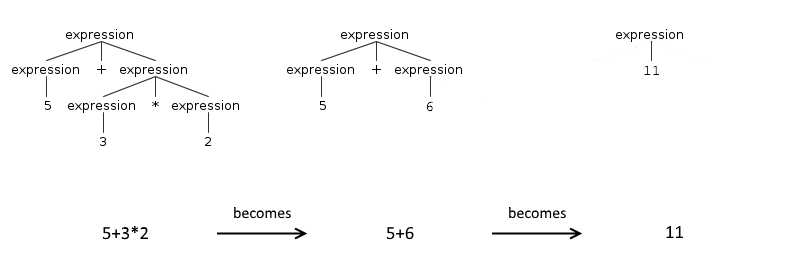
Однако окончательной формой разбора является дерево, которое работает по другому принципу: вы начинаете работать с листьями и поднимаетесь вверх. Чтобы в конце этого процесса корневой узел содержал конечный результат. Это означает, что в дереве синтаксического анализа атомарные выражения находятся внизу, а выражения с операторами отображаются в обратном порядке, в котором они применяются.
Предикаты
Предикаты , иногда называемые синтаксическими или семантическими предикатами , являются особыми правилами, которые сопоставляются только при соблюдении определенного условия. Условие определяется с помощью кода на языке программирования, поддерживаемом инструментом, для которого написана грамматика.
Их преимущество состоит в том, что они допускают некоторую форму контекстно-зависимого анализа, который иногда неизбежно соответствует определенным элементам. Например, их можно использовать для определения того, используется ли последовательность символов, которая определяет мягкое ключевое слово, в позиции, где это будет ключевое слово (например, за предыдущим токеном может следовать ключевое слово), или это простой идентификатор.
Недостатки в том, что они замедляют синтаксический анализ и делают грамматику зависимой от указанного языка программирования. Это потому, что условие выражено на языке программирования и должно быть проверено.
Встроенные действия
Внедренные действия идентифицируют код, который выполняется каждый раз, когда сопоставляется правило. У них есть явный недостаток, который затрудняет чтение грамматики, поскольку правила окружены кодом. Более того, так же, как и предикаты, они нарушают разделение между грамматикой, которая описывает язык, и кодом, который манипулирует результатами анализа.
Действия часто используются менее изощренными генераторами синтаксического анализа как единственный способ легко выполнить некоторый код при сопоставлении узла. используя эти поколения синтаксического анализатора, единственной альтернативой будет обход дерева и выполнение правильного кода самостоятельно. Вместо этого более продвинутые инструменты позволяют использовать шаблон посетителя для выполнения произвольного кода при необходимости, а также для управления обходом дерева.
Их также можно использовать для добавления определенных токенов или изменения сгенерированного дерева. Хотя это некрасиво, это может быть единственный практический способ справиться со сложными языками, такими как C, или конкретными проблемами, такими как пробелы в Python.
Форматы
Существует два основных формата грамматики: BNF (и его варианты) и PEG. Многие инструменты реализуют свои варианты этих идеальных форматов. Некоторые инструменты используют пользовательские форматы в целом. Частый пользовательский формат состоит из грамматики из трех частей: параметры вместе с пользовательским кодом, за которым следует раздел лексера и, наконец, синтаксический анализатор.
Учитывая, что BNF-подобный формат обычно является основой для контекстно-свободной грамматики, вы также можете увидеть ее идентифицированной как формат CFG.
Форма Бэкуса-Наура и ее варианты
Форма Бэкуса – Наура (BNF) является наиболее успешным форматом и даже была основой PEG. Однако это довольно просто, и, следовательно, это не часто используется в своей базовой форме. Обычно используется более мощный вариант.
Чтобы показать, почему эти варианты были необходимы, давайте покажем пример в BNF: описание персонажа.
|
1
2
3
|
<letter> ::= "a" | "b" | "c" | "d" | "e" | "f" | "g" | "h" | "i" | "j" | "k" | "l" | "m" | "n" | "o" | "p" | "q" | "r" | "s" | "t" | "u" | "v" | "w" | "x" | "y" | "z"<digit> ::= "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9"<character> ::= <letter> | <digit> |
Символ <буква> может быть преобразован в любую из букв английского алфавита, хотя в нашем примере допустимы только строчные буквы. Аналогичный процесс происходит с <цифрой> , которая может указывать любую из альтернативных цифр. Первая проблема заключается в том, что вы должны перечислить все альтернативы в отдельности; вы не можете использовать классы символов, как вы делаете с регулярными выражениями. Это раздражает, но обычно управляемо, если, конечно, вам не нужно перечислять все символы Unicode.
Гораздо сложнее проблема в том, что нет простого способа обозначить необязательные элементы или повторения. Поэтому, если вы хотите сделать это, вы должны полагаться на логическую логику и альтернативный символ ( | ).
|
1
|
<text> ::= <character> | <text> <character> |
Это правило гласит, что <текст> может состоять из символа или более короткого <текста>, за которым следует <символ> . Это будет дерево разбора для слова «собака».
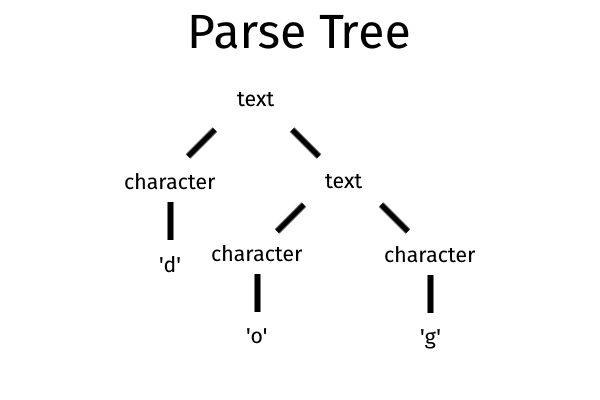
BNF имеет много других ограничений: он усложняет использование пустых строк или символов, используемых форматом (например, ::= ) в грамматике, имеет подробный синтаксис (например, вы должны включать терминалы между <и>), и т.п.
Расширенная форма Бэкуса-Наура
Чтобы решить некоторые из этих ограничений, Никлаус Вирт создал расширенную форму Бэкуса-Наура (EBNF), которая включает в себя некоторые концепции из собственной синтаксической нотации Вирта .
EBNF является наиболее используемой формой в современном инструменте синтаксического анализа, хотя инструменты могут отличаться от стандартных обозначений. EBNF имеет гораздо более четкую нотацию и принимает больше операторов для работы с конкатенацией или дополнительными элементами.
Посмотрим, как бы вы написали предыдущий пример в EBNF.
|
1
2
3
4
|
letter = "a" | "b" | "c" | "d" | "e" | "f" | "g" | "h" | "i" | "j" | "k" | "l" | "m" | "n" | "o" | "p" | "q" | "r" | "s" | "t" | "u" | "v" | "w" | "x" | "y" | "z" ;digit = "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9" ;character = letter | digit ;text = character , { character } ; |
Текстовый символ теперь описывается легче с помощью оператора конкатенации ( , ) и необязательного ( { .. } ). Результирующее дерево разбора также будет проще. Стандартный EBNF все еще представляет некоторые проблемы, такие как незнакомый синтаксис. Чтобы решить эту проблему, большинство инструментов синтаксического анализа используют синтаксис, основанный на регулярных выражениях, а также поддерживают дополнительные элементы, такие как классы символов.
Если вам нужен подробный обзор формата, вы можете прочитать нашу статью о EBNF .
ABNF
Дополненный BNF (ABNF) — это еще один вариант BNF, разработанный в основном для описания протоколов двунаправленной связи и формализованный IETF с несколькими документами (см. RFC 5234 и обновления).
ABNF может быть столь же продуктивным, как и EBNF, но у него есть некоторые особенности, которые ограничивают его использование за пределами интернет-протоколов. Например, до недавнего времени стандарт диктовал, что строки сопоставляются без учета регистра, что было бы проблемой для сопоставления идентификаторов во многих языках программирования.
ABNF имеет синтаксис, отличный от EBNF, например, альтернативный оператор — косая черта ( / ), а иногда он явно лучше. Например, нет необходимости в операторе конкатенации. Он также имеет несколько вещей, чем стандартный EBNF. Например, он позволяет вам определять числовые диапазоны, такие как %x30-39 что эквивалентно [0-9] . Это также используется самими дизайнерами для включения стандартных классов символов, таких как базовые правила, которые может использовать конечный пользователь. Примером такого правила является ALPHA, что эквивалентно [a-zA-Z] .
PEG
Грамматика синтаксического анализа (PEG) — это формат, представленный Брайаном Фордом в статье 2004 года . Технически это происходит от старой формальной грамматики, называемой сверху вниз синтаксическим языком (TDPL). Однако простой способ описать это: EBNF в реальном мире.
На самом деле он похож на EBNF, но также напрямую поддерживает такие вещи, как диапазоны символов (классы символов). Хотя он также имеет некоторые различия, которые на самом деле не настолько прагматичны, как использование более формального символа стрелки ( ← ) для назначения вместо более распространенного символа равенства ( = ). Предыдущий пример может быть написан таким образом с помощью PEG.
|
1
2
3
4
|
letter ← [a-z]digit ← [0-9]character ← letter / digittext ← character+ |
Как видите, это наиболее очевидный способ, которым программист написал бы это, используя классы символов и операторы регулярных выражений.Единственными аномалиями являются альтернативный оператор ( /) и символ стрелки, а на самом деле многие реализации PEG используют символ равенства.
Прагматичный подход является основой формализма PEG: он был создан для более естественного описания языков программирования. Это потому, что грамматика без контекста берет свое начало в работе по описанию естественных языков. Теоретически, CFG — это порождающая грамматика, а PEG — аналитическая грамматика.
Первый должен быть своего рода рецептом, чтобы генерировать только правильные предложения на языке, описанном грамматикой. Это не должно быть связано с алгоритмом синтаксического анализа. Вместо этого второй вид определяет непосредственно структуру и семантику синтаксического анализатора для этого языка.
PEG против CFG
Практические последствия этого теоретического различия ограничены: PEG более тесно связан с алгоритмом packrat , но это в основном так. Например, обычно PEG (packrat) не допускает рекурсии слева. Хотя сам алгоритм может быть изменен для его поддержки, это устраняет свойство синтаксического анализа за линейное время. Кроме того, PEG-парсеры, как правило, являются сканерами без сканирования.
Вероятно, самое важное различие между PEG и CFG заключается в том, что порядок выбора имеет смысл в PEG, но не в CFG. Если существует много возможных допустимых способов анализа входных данных, CFG будет неоднозначным и, таким образом, вернет ошибку. Обычно под неправильным пониманием подразумевается, что некоторые парсеры, которые принимают CFG, могут иметь дело с неоднозначными грамматиками. Например, предоставляя разработчику все возможные достоверные результаты и позволяя ему разобраться в этом. Вместо этого PEG устраняет неоднозначность в целом, потому что будет выбран первый применимый выбор, таким образом, PEG никогда не может быть неоднозначным.
Недостаток этого подхода заключается в том, что вы должны быть более осторожны при перечислении возможных альтернатив, потому что в противном случае у вас могут возникнуть непредвиденные последствия. То есть некоторые варианты никогда не могут быть сопоставлены.
В следующем примере dogeникогда не будет совпадения, так как собака идет первой, она будет выбрана каждый раз.
|
1
|
dog ← 'dog' / 'doge' |
Это открытая область исследования, может ли PEG описать все грамматики, которые могут быть определены с помощью CFG, но для всех практических целей они это делают.
Алгоритмы разбора

Теоретически анализ — это решаемая проблема, но эта проблема решается снова и снова. То есть существует множество различных алгоритмов, каждый из которых имеет свои сильные и слабые стороны, и они все еще совершенствуются учеными.
В этом разделе мы не собираемся учить, как реализовать каждый алгоритм синтаксического анализа, но мы собираемся объяснить их особенности. Цель состоит в том, чтобы вы могли с большей уверенностью выбирать, какой инструмент синтаксического анализа использовать или какой алгоритм лучше изучить и реализовать для своего пользовательского анализатора.
обзор
Начнем с общего обзора возможностей и стратегий всех парсеров.
Две стратегии
Есть две стратегии для разбора: сверху вниз разбора и снизу вверх разбора . Оба термина определены по отношению к дереву разбора, сгенерированному синтаксическим анализатором. Простым способом:
- анализатор, работающий сверху вниз, сначала пытается идентифицировать корень дерева разбора, затем он перемещается вниз по поддеревьям, пока не найдет листья дерева.
- анализ снизу вверх начинается с самой нижней части дерева, листьев и поднимается вверх, пока не определится корень дерева.
Давайте посмотрим на пример, начиная с дерева разбора.
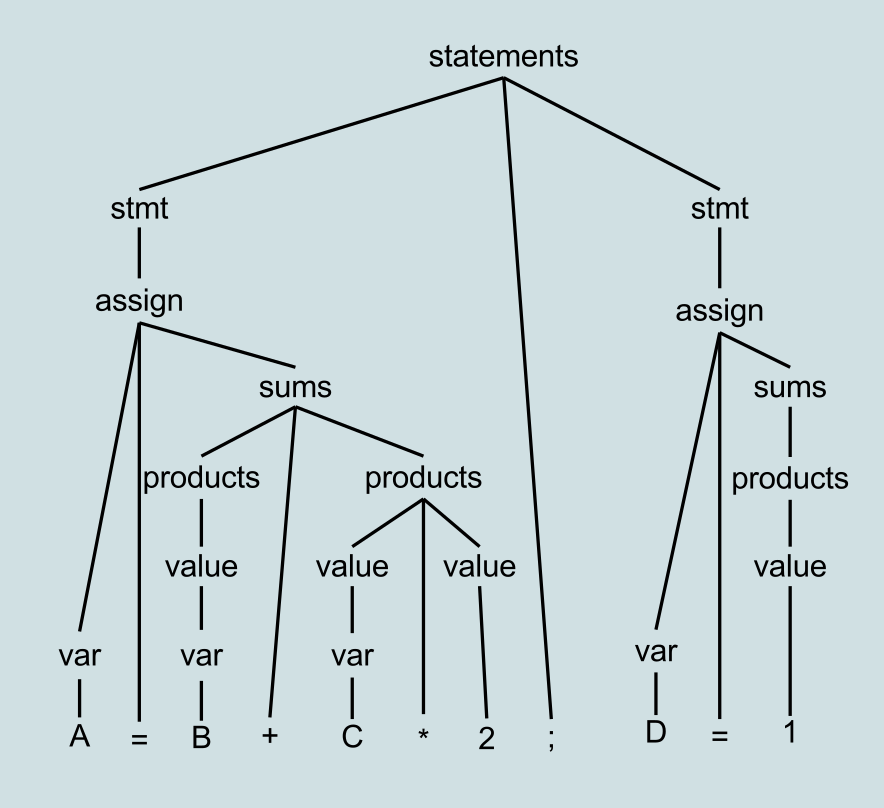
Пример дерева разбора из Википедии
{kind=link}
Одно и то же дерево будет сгенерировано в другом порядке с помощью синтаксического анализатора сверху вниз и снизу вверх. На следующих изображениях число указывает порядок, в котором создаются узлы.
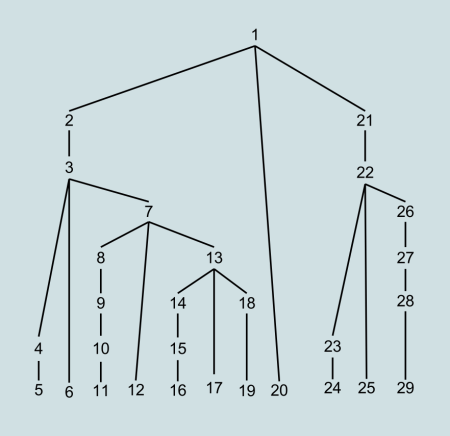
Нисходящий порядок генерации дерева (из Википедии)
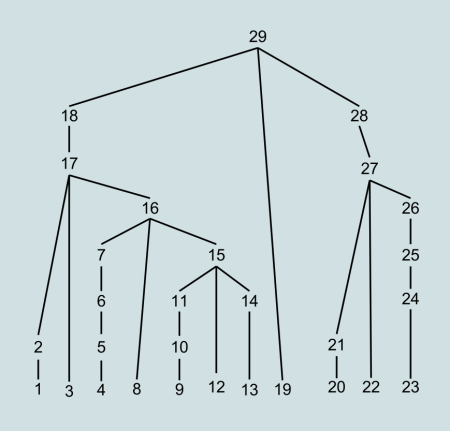
Порядок генерации дерева снизу вверх (из Википедии)
Традиционно синтаксические анализаторы создавались проще, но анализаторы снизу вверх были более мощными. Теперь ситуация более сбалансирована, главным образом, из-за продвижения стратегий синтаксического анализа сверху вниз.
Концепция деривации тесно связана со стратегиями. Вывод указывает порядок, в котором нетерминальные элементы, которые появляются в правиле справа, применяются для получения нетерминального символа слева. Используя терминологию BNF, он указывает, как элементы, которые появляются в __expression__, используются для получения <symbol>. Две возможности: крайний левый вывод и крайний правый вывод . Первые указывают, что правило применяется слева направо, а вторые указывают на обратное.
Простой пример: представьте, что вы пытаетесь разобрать символ, resultкоторый определен как таковой в грамматике.
|
1
2
3
|
expr_one = .. // stuffexpr_two = .. // stuffresult = expr_one 'operator' expr_two |
Вы можете применить сначала правило для символа, expr_oneа затем expr_twoили наоборот. В случае крайней левой деривации вы выбираете первый вариант, а для самой правой деривации — второй.
Важно понимать, что деривация применяется сначала по глубине или рекурсивно. То есть он применяется к начальному выражению, а затем снова применяется к полученному промежуточному результату. Таким образом, в этом примере, если после применения правила, соответствующего expr_oneновому нетерминалу, оно трансформируется первым. Нетерминал expr_twoприменяется только тогда, когда он становится первым нетерминалом и не следует порядку в исходном правиле.
Деривация связана с двумя стратегиями, потому что для синтаксического анализа снизу-вверх вы примените крайний справа вывод, а для синтаксического анализа сверху-вниз вы выберете крайний слева вывод. Обратите внимание, что это не влияет на конечное дерево синтаксического анализа, оно просто влияет на промежуточные элементы и используемый алгоритм.
Общие элементы
Парсеры, построенные с использованием стратегий сверху вниз и снизу вверх, разделяют несколько элементов, о которых мы можем говорить.
Взгляд в будущее и возвращение
Термины lookadhead и backtracking не имеют другого значения при разборе, чем те, которые они имеют в более широкой области информатики. Lookahead указывает количество элементов, следующих за текущим, которые принимаются во внимание, чтобы решить, какое текущее действие предпринять.
Простой пример: парсер может проверить следующий токен, чтобы решить, какое правило применить сейчас. Когда выбрано правильное правило, текущий токен используется, но следующий остается в очереди.
Возврат — это техника алгоритма. Он состоит в том, чтобы найти решение сложных проблем, попробовав частичное решение, а затем продолжить проверять наиболее перспективный. Если тот, который в данный момент проверен, дает сбой, то анализатор возвращается (то есть возвращается к последней позиции, которая была успешно проанализирована) и пробует другую.
Они особенно актуальны для алгоритмов синтаксического анализа LL , LR и LALR , потому что синтаксические анализаторы для языка, для которого нужен только один токен предпросмотра, легче построить и быстрее запустить. Токены предварительного просмотра, используемые такими алгоритмами, указываются в скобках после названия алгоритма (например, LL (1), LR ( k )). Обозначения (*) указывают на то, что алгоритм может проверять бесконечные маркеры предпросмотра, хотя это может повлиять на производительность алгоритма.
Парсеры Chart
Парсеры диаграмм — это семейство парсеров, которые могут быть восходящими (например, CYK) или нисходящими (например, Earley). Парсеры диаграмм, по сути, пытаются избежать обратного отслеживания, которое может быть дорогостоящим, с помощью динамического программирования . Динамическое программирование , или динамическая оптимизация, является общим методом для разбора более крупной проблемы в меньших подзадачах.
Распространенным алгоритмом динамического программирования, используемым анализатором диаграмм, является алгоритм Витерби . Цель алгоритма — найти наиболее вероятные скрытые состояния с учетом последовательности известных событий. Основываясь на известных нам токенах, мы пытаемся найти наиболее вероятные правила, которые их создали.
Синтаксический анализатор именной диаграммы происходит от того факта, что частичные результаты хранятся в структуре, называемой диаграммой (обычно диаграмма является таблицей). Конкретный метод хранения частичных результатов называется запоминанием . Мемоизация также используется другими алгоритмами, не связанными с синтаксическими анализаторами диаграмм, такими как packrat .
Автоматы
Прежде чем обсуждать алгоритмы синтаксического анализа, мы хотели бы поговорить об использовании автоматов в алгоритмах синтаксического анализа. Автоматы — это семейство абстрактных машин, среди которых есть известная машина Тьюринга .
Когда дело доходит до синтаксических анализаторов, вы можете использовать термин (детерминированный) Pushdown Automaton (PDA), а когда вы читаете о лексерах, вы услышите термин « детерминированный конечный автомат» (DFA). КПК более мощный и сложный, чем DFA (хотя все же проще, чем машина Тьюринга).
Поскольку они определяют абстрактные машины, обычно они не имеют прямого отношения к реальному алгоритму. Скорее, они формально описывают уровень сложности, с которым должен справляться алгоритм. Если кто-то говорит, что для решения проблемы X вам нужен DFA, он подразумевает, что вам нужен такой же мощный алгоритм, как и DFA.
Однако, так как DFA являются государственными машинами в случае лексера различия часто спорные. Это связано с тем, что конечные автоматы относительно просты в реализации (т. Е. Есть готовые к использованию библиотеки), поэтому большую часть времени DFA реализуется с помощью конечного автомата. Вот почему мы собираемся кратко рассказать о DFA и почему они часто используются для лексеров.
Лексинг с детерминированным конечным автоматом
DFA — это (конечный) конечный автомат, концепция, с которой мы предполагаем, что вы знакомы. По сути, конечный автомат имеет много возможных состояний и функцию перехода для каждого из них. Эти функции перехода определяют, как машина может переходить из одного состояния в другое в ответ на событие. Когда используется для лексизма, машина получает вводимые символы по одному, пока не достигнет принятого состояния (то есть, она может создать токен).
Они используются по нескольким причинам:
- было доказано, что они распознают именно набор регулярных языков, то есть они одинаково мощны как обычные языки
- Есть несколько математических методов для управления и проверки их свойств (например, могут ли они анализировать все строки или любые строки)
- они могут работать с эффективным онлайн-алгоритмом (см. ниже)
Онлайновый алгоритм — это тот, который не требует всего ввода для работы. В случае лексера это означает, что он может распознать токен, как только его символы будут видны алгоритмом. Альтернативой было бы то, что для идентификации каждого токена требовался весь ввод.
В дополнение к этим свойствам довольно легко преобразовать набор регулярных выражений в DFA, что позволяет вводить правила простым способом, знакомым многим разработчикам. Затем вы можете автоматически конвертировать их в конечный автомат, который может эффективно работать с ними.
Таблицы алгоритмов синтаксического анализа
Мы предоставляем таблицу с краткой информацией об основной информации, необходимой для понимания и реализации конкретного алгоритма синтаксического анализа. Вы можете найти больше реализаций, прочитав наши статьи, в которых представлены инструменты синтаксического анализа и библиотеки для Java , C # , Python и JavaScript .
В таблице перечислены:
- формальное описание, чтобы объяснить теорию, стоящую за алгоритмом
- более практичное объяснение
- одна или две реализации, обычно одна проще, а другая — профессиональный парсер. Иногда, однако, нет более простой или профессиональной версии.
Чтобы понять, как работает алгоритм синтаксического анализа, вы также можете взглянуть на синтаксический аналитический инструментарий . Это образовательный генератор синтаксического анализа, который описывает шаги, которые сгенерированный анализатор выполняет для достижения своей цели. Он реализует алгоритм LL и LR.
Во второй таблице приведено краткое описание основных особенностей различных алгоритмов синтаксического анализа и того, для чего они обычно используются.
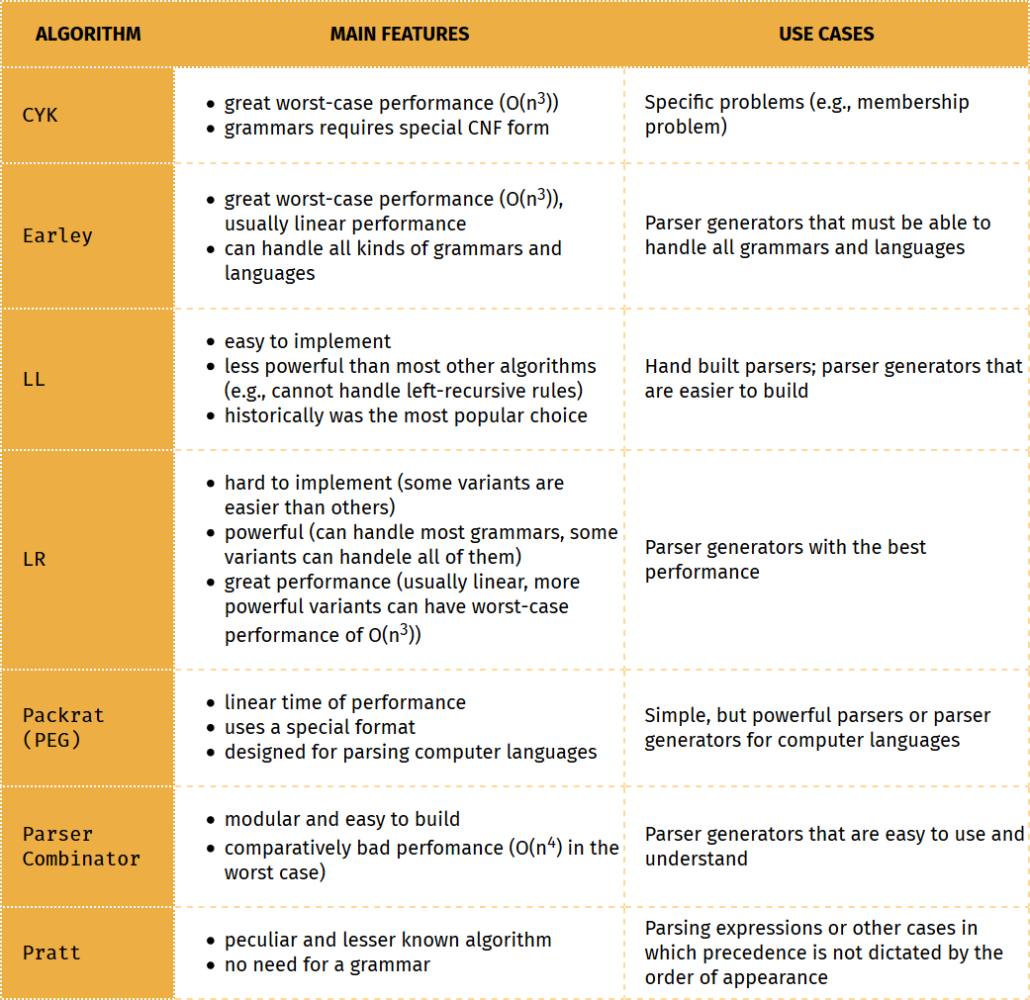
Нисходящие алгоритмы
Нисходящая стратегия является самой распространенной из двух стратегий, и есть несколько успешных алгоритмов, применяющих ее.
LL Parser
LL ( L EFT-направо чтения входного, L eftmost вывода) парсеры таблица синтаксических анализаторов на основе без возвратов, но с опережающим просмотром. Основанный на таблице означает, что они полагаются на таблицу анализа, чтобы решить, какое правило применить. Таблицу синтаксического анализа используют в качестве строк и столбцов нетерминалов и терминалов соответственно.
Чтобы найти правильное правило для применения:
- во-первых, парсер просматривает текущий токен и соответствующее количество лексем-ключей
- затем он пытается применить другие правила, пока не найдет правильное соответствие.
Концепция парсера LL относится не к конкретному алгоритму, а скорее к классу парсеров. Они определяются по отношению к грамматике. То есть синтаксический анализатор LL — это тот, который может анализировать грамматику LL. В свою очередь, грамматики LL определяются в зависимости от количества лексем, которые необходимы для их анализа. Это число указывается в скобках рядом с LL, поэтому в форме LL ( k ).
Синтаксический анализатор LL ( k ) использует k токенов предпросмотра и, таким образом, может анализировать не более грамматики, для которой необходимо проанализировать k токенов предпросмотра. Эффективно понятие LL ( k ) грамматики используется более широко, чем соответствующий парсер. Это означает, что грамматики LL ( k ) используются в качестве измерителя при сравнении различных алгоритмов. Например, вы прочитали бы, что PEG-парсеры могут обрабатывать грамматики LL (*).
Значение грамматик LL
Такое использование грамматик LL связано как с тем, что синтаксический анализатор LL широко используется, так и с тем, что он немного ограничен. Фактически, грамматика LL не поддерживает леворекурсивные правила. Вы можете преобразовать любую леворекурсивную грамматику в эквивалентную нерекурсивную форму, но это ограничение имеет значение по нескольким причинам: производительность и мощность.
Потеря производительности зависит от того, что вы должны написать грамматику особым образом, что требует времени. Мощность ограничена, потому что грамматика, которая может потребовать 1 токен упреждающего запроса, при написании с леворекурсивным правилом, может потребовать 2-3 токена упреждающего просмотра, если она написана не рекурсивным способом. Таким образом, это ограничение не просто раздражает, но оно ограничивает мощность алгоритма, то есть грамматики, для которой он может использоваться.
Потеря производительности может быть уменьшена с помощью алгоритма, который автоматически преобразует леворекурсивную грамматику в нерекурсивную. ANTLR — это инструмент, который может сделать это, но, конечно, если вы создаете свой собственный парсер, вы должны сделать это самостоятельно.
Существует два специальных вида грамматик LL ( k ): LL (1) и LL (*). В прошлом первые виды были единственными, которые считались практичными, потому что для них легко создавать эффективные парсеры. До того момента, что многие компьютерные языки были специально разработаны, чтобы описываться грамматикой LL (1). LL (*), также известный как LL-регулярный парсер, может работать с языками, используя бесконечное количество лексем.
В StackOverflow вы можете прочитать простое сравнение между анализаторами LL и анализаторами рекурсивного спуска или сравнение между анализаторами LL и анализаторами LR .
Эрли Парсер
Парсер Earley — это парсер диаграмм, названный в честь своего изобретателя Джея Эрли. Алгоритм обычно сравнивают с CYK, другим синтаксическим анализатором диаграмм, который проще, но также обычно хуже по производительности и памяти . Отличительной особенностью алгоритма Эрли является то, что, помимо сохранения частичных результатов, он реализует шаг прогнозирования, чтобы решить, какое правило будет пытаться соответствовать следующему.
Парсер Earley в основном работает путем разделения правила на сегменты, как в следующем примере.
|
1
2
3
4
5
6
7
8
9
|
// an example grammarHELLO : "hello"NAME : [a-zA-Z]+greeting : HELLO NAME // Earley parser would break up greeting like this// . HELLO NAME// HELLO . NAME// HELLO NAME . |
Затем, работая с этими сегментами, которые можно соединить с точкой ( .), пытается достичь завершенного состояния, то есть с точкой в конце.
Привлекательность синтаксического анализатора Earley заключается в том, что он гарантированно сможет анализировать все языки без контекста, в то время как другие известные алгоритмы (например, LL, LR) могут анализировать только их подмножество. Например, у него нет проблем с леворекурсивными грамматиками. В более общем смысле парсер Earley может также иметь дело с недетерминированными и неоднозначными грамматиками.
Это может сделать это с риском ухудшения производительности (O (n 3 )), в худшем случае. Однако он имеет линейную производительность по времени для обычных грамматик. Суть в том, что набор языков, анализируемых более традиционными алгоритмами, — это тот, который нас обычно интересует.
Есть также побочный эффект отсутствия ограничений: вынуждая разработчика писать грамматику определенным образом, синтаксический анализ может быть более эффективным. То есть, построение грамматики LL (1) может быть сложнее для разработчика, но анализатор может применять его очень эффективно. С Earley вы выполняете меньше работы, поэтому анализатор делает больше.
Короче говоря, Earley позволяет использовать грамматики, которые легче писать, но которые могут быть неоптимальными с точки зрения производительности.
Случаи использования Earley
Таким образом, парсеры Earley просты в использовании, но преимущество, с точки зрения производительности, в среднем случае может отсутствовать. Это делает алгоритм отличным для образовательной среды или в тех случаях, когда производительность важнее скорости.
В первом случае это полезно, например, потому что большую часть времени грамматики, которые пишут ваши пользователи, работают просто отлично. Проблема в том, что парсер будет выдавать на них неясные и, казалось бы, случайные ошибки. Конечно, ошибки не являются случайными, но они связаны с ограничениями алгоритма, которые ваши пользователи не знают или не понимают. Таким образом, вы заставляете пользователя понимать внутреннюю работу вашего парсера, чтобы использовать его, что должно быть ненужным.
Примером, когда производительность важнее скорости, может быть генератор синтаксического анализатора для реализации подсветки синтаксиса для редактора, который должен поддерживать множество языков. В аналогичной ситуации возможность быстрой поддержки новых языков может быть более желательной, чем как можно скорее выполнить задачу.
Пакрат (ПЭГ)
Packrat часто ассоциируется с формальной грамматикой PEG, поскольку они были изобретены одним и тем же человеком: Брайаном Фордом. Пакрат был описан первым в своей диссертации: « Анализ Пакрата: практический алгоритм линейного времени с обратным отслеживанием» . Название говорит почти обо всем, что нас волнует: оно имеет линейное время выполнения, в том числе и потому, что не использует возврат.
Другая причина его эффективности — это запоминание: сохранение частичных результатов в процессе анализа. Недостатком и причиной того, что метод не использовался до недавнего времени, является количество памяти, необходимое для хранения всех промежуточных результатов. Если требуемая память превышает доступную, алгоритм теряет свое линейное время выполнения.
Packrat также не поддерживает леворекурсивные правила, что является следствием того факта, что PEG требует всегда выбирать первый вариант. На самом деле некоторые варианты могут поддерживать прямые леворекурсивные правила, но за счет потери линейной сложности.
Парсер Packrat может работать с бесконечным количеством упреждений, если это необходимо. Это влияет на время выполнения, что в худшем случае может быть экспоненциальным.
Парсер рекурсивного спуска
Парсер рекурсивного спуска — это парсер, который работает с набором (взаимно) рекурсивных процедур, обычно по одной для каждого правила грамматики. Таким образом, структура синтаксического анализатора отражает структуру грамматики.
Термин предиктивный синтаксический анализатор используется несколькими различными способами: некоторые люди понимают его как синоним синтаксического анализатора сверху вниз, некоторые как синтаксический анализатор с рекурсивным спуском, который никогда не возвращается назад.
Противоположностью этому второму значению является парсер рекурсивного спуска, который выполняет возврат. То есть тот, который находит правило, которое совпадает с вводом, выполняя каждое из правил в последовательности, и затем оно возвращается каждый раз, когда терпит неудачу.
Обычно у синтаксического анализатора рекурсивного спуска возникают проблемы с разбором леворекурсивных правил, потому что алгоритм в конечном итоге будет вызывать одну и ту же функцию снова и снова. Возможное решение этой проблемы — использование хвостовой рекурсии. Парсеры, которые используют этот метод, называются хвостовыми рекурсивными парсерами .
Хвостовая рекурсия как таковая — это просто рекурсия, которая происходит в конце функции. Однако хвостовая рекурсия используется в сочетании с преобразованиями правил грамматики. Комбинация преобразования правил грамматики и помещения рекурсии в конец процесса позволяет работать с леворекурсивными правилами.
Пратт Парсер
Парсер Pratt является широко не используемым, но высоко ценимым (мало кто знает) алгоритмом синтаксического анализа, определенным Воганом Праттом в статье « Приоритет оператора сверху вниз» . Сама статья начинается с полемики о грамматиках БНФ, которые автор ошибочно утверждает, что они являются исключительной задачей парсинга исследований. Это одна из причин отсутствия успеха. Фактически алгоритм не опирается на грамматику, а работает непосредственно с токенами, что делает его необычным для экспертов по анализу.
Вторая причина заключается в том, что традиционные нисходящие парсеры прекрасно работают, если у вас есть значимый префикс, который помогает различать разные правила. Например, если вы получаете токен FOR, вы просматриваете оператор for . Поскольку это в основном относится ко всем языкам программирования и их операторам, легко понять, почему анализатор Pratt не изменил мир синтаксического анализа.
Где алгоритм Pratt сияет с выражениями. Фактически, концепция приоритета делает невозможным понимание структуры входных данных, просто взглянув на порядок, в котором представлены токены.
По сути, алгоритм требует, чтобы вы присваивали значение приоритета каждому токену оператора и пару функций, которые определяют, что делать, в соответствии с тем, что находится слева и справа от токена. Затем он использует эти значения и функции для связывания операций во время прохождения ввода.
Хотя алгоритм Пратта не был явно успешным, он используется для анализа выражений. Он также принят Дугласом Крокфордом (из известности JSON) для JSLint.
Parser Combinator
Комбинатор синтаксического анализатора — это функция высшего порядка, которая принимает функции синтаксического анализатора в качестве входных данных и возвращает новую функцию синтаксического анализатора в качестве выходных данных. Функция парсера обычно означает функцию, которая принимает строку и выводит дерево разбора.
Комбинатор синтаксического анализатора является модульным и простым в сборке, но он также медленнее ( сложность O (n 4 ) в худшем случае) и менее сложен. Они обычно используются для облегчения анализа или создания прототипов. В некотором смысле пользователь комбинатора синтаксического анализатора строит парсер частично вручную, но полагаясь на жесткое слово, сделанное тем, кто создал комбинатор синтаксического анализатора.
Обычно они не поддерживают левые рекурсивные правила, но есть более продвинутые реализации, которые делают именно это. См., Например, статью Parser Combinators для неоднозначных леворекурсивных грамматик , в которой также описывается алгоритм с полиномиальным временем выполнения.
Многие современные реализации называются монадическим синтаксическим анализатором , поскольку они основаны на структуре функционального программирования, называемой монадой . Монады — довольно сложное понятие, которое мы не можем надеяться объяснить здесь. Однако в основном монада способна комбинировать функции и действия, полагаясь на тип данных. Важной особенностью является то, что тип данных определяет, как его различные значения могут быть объединены.
Самый простой пример — монада Maybe . Это обертка вокруг нормального типа, такого как целое число, которое возвращает само значение, когда значение является действительным (например, 567), но специальное значение Nothing, когда это не так (например, undefined или деление на ноль). Таким образом, вы можете избежать использования нулевого значения и бесполезного сбоя программы. Вместо этого значение Nothing управляется обычным образом, как и любое другое значение.
Восходящие алгоритмы
Основным успехом стратегии «снизу вверх» является семейство множества различных анализаторов LR. Причина их относительной непопулярности заключается в том, что исторически их было сложнее построить, хотя синтаксический анализатор LR также более мощный, чем традиционные грамматики LL (1). Поэтому мы в основном концентрируемся на них, за исключением краткого описания парсеров CYK.
Это означает, что мы избегаем говорить о более универсальном классе парсера Shift-Reduce , который также включает парсеры LR.
Мы только говорим, что алгоритмы сдвига-уменьшения работают в два этапа:
- Shift : чтение одного токена из входа, который становится новым (на мгновение изолированным) узлом
- Сократить : как только будет найдено правильное правило, соедините результирующее дерево с существующим прецедентом.
В основном шаг сдвига считывает входные данные до завершения, в то время как редуктор соединяет поддеревья, пока не будет построено окончательное дерево разбора.
CYK Parser
Cocke-Younger-Kasami (CYK) был сформулирован независимо тремя авторами. Его известность обусловлена большой производительностью в худшем случае (O (n 3 )), хотя в большинстве распространенных сценариев ему мешает сравнительно плохая производительность.
Однако реальным недостатком алгоритма является то, что он требует, чтобы грамматика была выражена в нормальной форме Хомского .
Это потому, что алгоритм опирается на свойства этой конкретной формы, чтобы иметь возможность разделить входные данные пополам, чтобы попытаться сопоставить все возможности. Теперь, теоретически, любая не зависящая от контекста грамматика может быть преобразована в соответствующий CNF, но это редко бывает практично делать вручную. Представьте, что вас раздражает тот факт, что вы не можете использовать леворекурсивные правила, и вас просят выучить особый вид форм …
Алгоритм CYK используется в основном для конкретных задач. Например, проблема членства: определить, совместима ли строка с определенной грамматикой. Он также может быть использован при обработке естественного языка для поиска наиболее вероятного синтаксического анализа между многими опциями.
Для всех практических целей, если вам нужно проанализировать всю неконтекстную грамматику с большой производительностью в худшем случае, вы хотите использовать анализатор Earley.
LR Parser
LR ( L EFT-направо чтения входных, R ightmost вывода) являются анализаторы снизу вверх парсеры , которые могут обрабатывать детерминированные контекстно-свободные языки в линейное время, с упреждающей выборкой и без возвратов. Изобретение парсеров LR приписывается известному Дональду Кнуту.
Традиционно их сравнивали и сравнивали с LL-парсерами. Таким образом, существует аналогичный анализ, связанный с количеством ожидающих токенов, необходимых для анализа языка. Синтаксический анализатор LR ( k ) может анализировать грамматики, для анализа которых требуется k токенов предпросмотра. Однако грамматики LR менее строгие и, следовательно, более мощные, чем соответствующие грамматики LL. Например, нет необходимости исключать леворекурсивные правила.
Технически, грамматики LR — это расширенный набор грамматик LL. Одним из следствий этого является то, что вам нужны только грамматики LR (1), поэтому обычно ( k ) опускается.
Они также основаны на таблицах, как и LL-парсеры, но им нужны две сложные таблицы. В очень простых сроках:
- одна таблица сообщает парсеру, что делать в зависимости от текущего токена, состояния и токенов, которые могут следовать за текущим (l ookahead sets )
- другой сообщает парсеру, в какое состояние перейти
Парсеры LR мощны и имеют отличную производительность, так в чем же подвох? Таблицы, в которых они нуждаются, трудно построить вручную и могут вырасти очень большими для обычных компьютерных языков, поэтому обычно они в основном используются через генераторы парсеров. Если вам нужно собрать парсер вручную, вы, вероятно, предпочтете парсер сверху вниз.
Простой LR и Lookahead LR
Генераторы синтаксических анализаторов избегают проблемы создания таких таблиц, но они не решают проблему стоимости создания таких больших таблиц и навигации по ним. Таким образом, существуют более простые альтернативы синтаксическому анализатору Canonical LR (1) , описанному Кнутом. Эти альтернативы менее мощны, чем оригинал. Это: простой анализатор LR (SLR) и анализатор LR Lookahead (LALR). Таким образом, в порядке мощности мы имеем: LR (1)> LALR (1)> SLR (1)> LR (0).
Имена двух парсеров, оба изобретенных Фрэнком Деремером, несколько вводят в заблуждение: один на самом деле не так прост, а другой — не единственный, который использует упреждающий просмотр. Можно сказать, что один проще, а другой в большей степени полагается на предвкушение при принятии решений.
В основном они различаются по таблицам, которые они используют, в основном они меняют часть «что делать» и наборы прогнозных данных. Которые, в свою очередь, накладывают различные ограничения на грамматику, которую они могут анализировать. Другими словами, они используют разные алгоритмы для вывода таблиц синтаксического анализа из грамматики.
Парсер SLR довольно ограничен в практическом плане и не очень используется. Парсер LALR вместо этого работает для большинства практических грамматик и широко используется. На самом деле популярные инструменты yacc и bison работают с таблицами парсера LALR.
В отличие от грамматик LR, грамматики LALR и SLR не являются надмножеством грамматик LL. Их нелегко сопоставить: некоторые грамматики могут охватываться одним классом, а не другим, или наоборот.
Обобщенный парсер LR
Обобщенные парсеры LR (GLR) являются более мощными вариантами парсеров LR. Они были описаны Бернардом Лендом в 1974 году и впервые реализованы Масару Томита в 1984 году. Причиной существования GLR является необходимость анализа недетерминированных и неоднозначных грамматик.
Мощность синтаксического анализатора GLR не найдена в его таблицах, которые эквивалентны мощности традиционного синтаксического анализатора LR. Вместо этого он может перемещаться в разные состояния. На практике, когда возникает двусмысленность, он создает новый синтаксический анализатор (ы), который обрабатывает этот конкретный случай. Эти парсеры могут перестать работать на более позднем этапе и могут быть отброшены.
Наихудшая сложность GLR-синтаксического анализатора такая же, как и у Earley (O (n 3 )), хотя она может иметь лучшую производительность при лучшем случае детерминированных грамматик. Парсер GLR также сложнее построить, чем парнер Earley.
Резюме
В этой замечательной (или, по крайней мере, большой) статье мы надеемся, что большинство сомнений по поводу синтаксического анализа терминов и алгоритмов удалось решить. Что означают термины и зачем выбирать определенный алгоритм вместо другого. Мы не только объяснили их, но и дали несколько советов по распространенным проблемам с синтаксическим анализом языков программирования.
Из-за нехватки места мы не смогли предоставить подробное объяснение всех алгоритмов разбора. Таким образом, мы также предоставили несколько ссылок, чтобы получить более глубокое понимание алгоритмов: теория, лежащая в их основе, и объяснение того, как они работают. Если вы особенно заинтересованы в создании таких вещей, как компилятор и интерпретаторы, вы можете прочитать другую статью, чтобы найти ресурсы для создания языков программирования .
Если вы просто заинтересованы в синтаксическом анализе, вы можете прочитать « Технику синтаксического анализа» — книгу, которая является настолько же всеобъемлющей, насколько дорогой. Это, очевидно, гораздо глубже, чем мы могли бы, но оно также охватывает менее используемые алгоритмы синтаксического анализа.
| программы JCG . Смотреть оригинальную статью здесь: Руководство по синтаксическому анализу: алгоритмы и терминология
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |