Если вам нужно проанализировать язык или документ из Java, есть три основных способа решения проблемы:
- использовать существующую библиотеку, поддерживающую этот конкретный язык: например, библиотеку для анализа XML
- создание собственного пользовательского парсера вручную
- инструмент или библиотека для генерации парсера: например, ANTLR, который вы можете использовать для создания парсера для любого языка
Использовать существующую библиотеку
Первый вариант является лучшим для хорошо известных и поддерживаемых языков, таких как XML или HTML . Хорошая библиотека обычно включает также API для программной сборки и изменения документов на этом языке. Обычно это больше того, что вы получаете от базового парсера. Проблема в том, что такие библиотеки не так распространены и поддерживают только самые распространенные языки. В других случаях вам не повезло.
Создание собственного пользовательского парсера вручную
Возможно, вам придется пойти на второй вариант, если у вас есть конкретные потребности. В том смысле, что язык, который вам нужно проанализировать, не может быть проанализирован с помощью традиционных генераторов синтаксического анализатора, или у вас есть особые требования, которые вы не можете удовлетворить с помощью типичного генератора синтаксического анализатора. Например, потому что вам нужна наилучшая производительность или глубокая интеграция между различными компонентами.
Инструмент или библиотека для генерации парсера
Во всех остальных случаях третьим вариантом должен быть вариант по умолчанию, поскольку он наиболее гибкий и имеет более короткое время разработки. Вот почему в этой статье мы концентрируемся на инструментах и библиотеках, которые соответствуют этой опции.
Инструменты для создания парсеров
Мы увидим:
- инструменты, которые могут генерировать парсеры, используемые из Java (и, возможно, из других языков)
- Библиотеки Java для создания парсеров
Инструменты, которые можно использовать для генерации кода для анализатора, называются генераторами синтаксического анализатора или компилятором компилятора . Библиотеки, которые создают парсеры, известны как комбинаторы парсеров .
Генераторы синтаксических анализаторов (или комбинаторы синтаксических анализаторов) не являются тривиальными: вам нужно некоторое время, чтобы научиться использовать их, и не все типы генераторов синтаксических анализаторов подходят для всех типов языков. Именно поэтому мы подготовили список самых известных из них с кратким введением для каждого из них. Мы также концентрируемся на одном целевом языке: Java. Это также означает, что (обычно) сам парсер будет написан на Java.
Перечислить все возможные инструменты и библиотеки парсера для всех языков было бы довольно интересно, но не так полезно. Это потому, что будет слишком много вариантов, и мы все потеряемся в них. Концентрируясь на одном языке программирования, мы можем обеспечить сравнение между яблоками и помочь вам выбрать один вариант для вашего проекта.
Полезные сведения о парсерах
Чтобы убедиться, что этот список доступен для всех программистов, мы подготовили краткое объяснение терминов и понятий, с которыми вы можете столкнуться при поиске парсера. Мы не пытаемся дать вам формальные объяснения, но практические.
Структура парсера
Парсер обычно состоит из двух частей: лексера , также известного как сканер или токенизатор , и правильного парсера. Не все парсеры принимают эту двухэтапную схему: некоторые парсеры не зависят от лексера. Их называют сканерами без сканера .
Лексер и синтаксический анализатор работают последовательно: лексер сканирует входные данные и выдает совпадающие токены, анализатор сканирует токены и выдает результат синтаксического анализа.
Давайте посмотрим на следующий пример и представим, что мы пытаемся разобрать математическую операцию.
|
1
|
437 + 734 |
Лексер сканирует текст и находит «4», «3», «7», а затем пробел ». Задача лексера — распознать, что первые символы составляют один токен типа NUM. Затем лексер находит символ «+», который соответствует второму токену типа PLUS , и, наконец, он находит другой токен типа NUM . 
Парсер обычно объединяет токены, созданные лексером, и группирует их.
Определения, используемые лексерами или парсерами, называются правилами или продукцией . Правило лексера будет указывать, что последовательность цифр соответствует токену типа NUM , а правило синтаксического анализатора будет указывать, что последовательность токенов типа NUM, PLUS, NUM соответствует выражению.
Сканеры без сканера отличаются тем, что обрабатывают непосредственно исходный текст вместо обработки списка токенов, созданных лексером.
Сейчас типично найти наборы, которые могут генерировать как лексер, так и парсер. В прошлом вместо этого было более распространенным объединять два разных инструмента: один для создания лексера и один для создания парсера. Это был, например, случай с почтенной парой lex & yacc: lex создал лексер, а yacc — парсер.
Дерево синтаксического анализа и абстрактное синтаксическое дерево
Есть два термина, которые связаны между собой, и иногда они используются взаимозаменяемо: дерево разбора и Abstract SyntaxTree (AST).
Концептуально они очень похожи:
- они оба дерева : есть корень, представляющий весь проанализированный фрагмент кода. Затем существуют меньшие поддеревья, представляющие части кода, которые становятся меньше, пока в дереве не появятся одиночные токены.
- Разница заключается в уровне абстракции: дерево разбора содержит все токены, появившиеся в программе, и, возможно, набор промежуточных правил. Вместо этого AST — это отполированная версия дерева разбора, где удаляется информация, которая может быть получена или не важна для понимания фрагмента кода.
В AST некоторая информация теряется, например, комментарии и символы группировки (круглые скобки) не представлены. Такие вещи, как комментарии, являются излишними для программы, а символы группировки неявно определяются структурой дерева.
Дерево разбора — это представление кода, более близкого к конкретному синтаксису. Он показывает много деталей реализации парсера. Например, обычно правила соответствуют типу узла. Они обычно преобразуются в AST пользователем с некоторой помощью генератора парсера.
Графическое представление AST выглядит следующим образом.
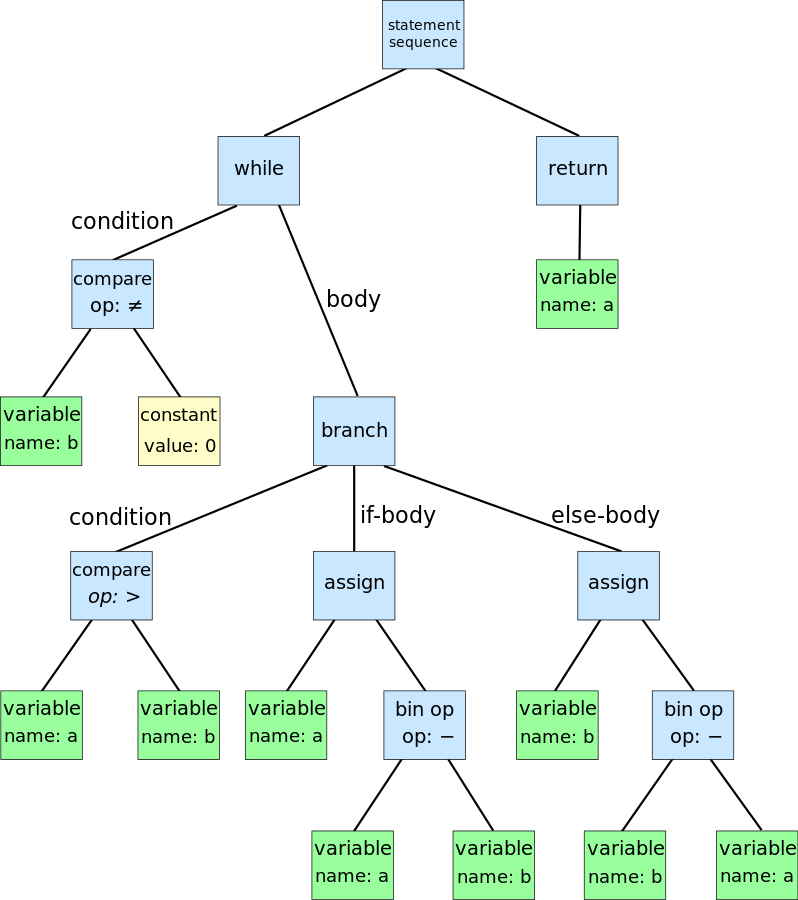
Иногда вы можете захотеть начать создавать дерево разбора, а затем получить из него AST. Это может иметь смысл, потому что дерево синтаксического анализа легче создать для синтаксического анализатора (это прямое представление процесса синтаксического анализа), но AST проще и легче обрабатывать с помощью следующих шагов. Под следующими шагами мы подразумеваем все операции, которые вы можете выполнять над деревом: проверка кода, интерпретация, компиляция и т. Д.
грамматика
Грамматика — это формальное описание языка, которое можно использовать для распознавания его структуры.
Простыми словами, это список правил, которые определяют, как каждая конструкция может быть составлена. Например, правило для оператора if может указывать, что оно должно начинаться с ключевого слова «if», за которым следуют левая скобка, выражение, правая скобка и оператор.
Правило может ссылаться на другие правила или типы токенов. В примере оператора if ключевое слово «if», левая и правая скобки были типами токенов, а выражение и оператор — ссылками на другие правила.
Наиболее используемый формат для описания грамматик — это форма Бэкуса-Наура (BNF) , которая также имеет много вариантов, включая расширенную форму Бэкуса-Наура . Преимущество расширенного варианта состоит в том, что он включает простой способ обозначения повторений. Типичное правило в грамматике Бэкуса-Наура выглядит следующим образом:
|
1
|
<symbol> ::= __expression__ |
<simbol> обычно является нетерминальным, что означает, что его можно заменить на группу элементов справа, __expression__ . Элемент __expression__ может содержать другие нетерминальные или терминальные символы. Терминальные символы — это просто те, которые не отображаются в виде <symbol> где-либо в грамматике. Типичным примером терминального символа является строка символов, например «класс».
Леворекурсивные правила
В контексте синтаксических анализаторов важной особенностью является поддержка леворекурсивных правил. Это означает, что правило может начинаться со ссылки на себя. Эта ссылка может быть также косвенной.
Рассмотрим для примера арифметические операции. Дополнение может быть описано как два выражения (ий), разделенных символом плюс (+), но выражение также может содержать другие дополнения.
|
1
2
3
4
|
addition ::= expression '+' expressionmultiplication ::= expression '*' expression// an expression could be an addition or a multiplication or a numberexpression ::= addition | multiplication |// a number |
Это описание также соответствует множественным сложениям, таким как 5 + 4 + 3. Это потому, что его можно интерпретировать как выражение (5) (‘+’), выражение (4 + 3). И тогда само 4 + 3 можно разделить на две составляющие.
Проблема в том, что такого рода правила не могут быть использованы с некоторыми генераторами синтаксического анализатора. Альтернативой является длинная цепочка выражений, которая учитывает также приоритет операторов.
Некоторые генераторы парсеров поддерживают прямые леворекурсивные правила, но не косвенные.
Типы языков и грамматик
В основном мы заботимся о двух типах языков, которые можно анализировать с помощью генератора синтаксических анализаторов: обычные языки и языки без контекста s. Мы могли бы дать вам формальное определение в соответствии с иерархией языков Хомского , но оно не будет таким полезным. Давайте рассмотрим некоторые практические аспекты.
Обычный язык может быть определен серией регулярных выражений, тогда как контекстно-свободный требует чего-то большего. Простое практическое правило заключается в том, что если грамматика языка имеет рекурсивные элементы, это не обычный язык. Например, как мы уже говорили в другом месте, HTML не является обычным языком . Фактически, большинство языков программирования являются языками без контекста.
Обычно какому-то языку соответствует один и тот же вид грамматики. То есть существуют регулярные грамматики и контекстно-свободные грамматики, которые соответствуют соответственно обычным и контекстно-свободным языкам. Но чтобы усложнить ситуацию, существует относительно новый (созданный в 2004 году) вид грамматики, называемый грамматикой синтаксического анализа (PEG). Эти грамматики столь же мощны, как и контекстно-свободные грамматики, но, по словам их авторов, они более естественным образом описывают языки программирования.
Различия между PEG и CFG
Основное различие между PEG и CFG заключается в том, что порядок выбора имеет смысл в PEG, но не в CFG. Если существует много возможных допустимых способов анализа входных данных, CFG будет неоднозначным и, следовательно, неправильным. Вместо этого с PEG будет выбран первый применимый выбор, и это автоматически решит некоторые неясности.
Другое отличие состоит в том, что в PEG используются синтаксические анализаторы без сканера: им не требуется отдельный лексер или фаза лексического анализа.
Традиционно и PEG, и некоторые CFG были не в состоянии справиться с леворекурсивными правилами, но некоторые инструменты нашли обходные пути для этого. Либо путем изменения основного алгоритма синтаксического анализа, либо с помощью инструмента, автоматически переписывающего леворекурсивное правило нерекурсивным способом. Любой из этих способов имеет свои недостатки: либо делает сгенерированный парсер менее понятным, либо ухудшает его производительность. Однако на практике преимущества более простой и быстрой разработки перевешивают недостатки.
Генераторы парсеров
Основной рабочий процесс инструмента генератора синтаксического анализатора довольно прост: вы пишете грамматику, которая определяет язык или документ, и запускаете инструмент для генерации синтаксического анализатора, используемого из вашего кода Java.
Синтаксический анализатор может создать AST, который вам может потребоваться пройти самостоятельно, или вы можете перейти с помощью дополнительных готовых к использованию классов, таких как слушатели или посетители . Вместо этого некоторые инструменты дают возможность встраивать код в грамматику, которая будет выполняться каждый раз, когда определенное правило соответствует.
Обычно вам нужна библиотека времени выполнения и / или программа, чтобы использовать сгенерированный парсер.
Обычный (Лексер)
Инструменты, которые анализируют обычные языки, как правило, лексеры.
JFlex
JFlex — генератор лексического анализатора (лексера), основанный на детерминированных конечных автоматах (DFA). Лексер JFlex сопоставляет входные данные в соответствии с определенной грамматикой (называемой спецификацией) и выполняет соответствующее действие (встроенное в грамматику).
Он может использоваться как самостоятельный инструмент, но будучи генератором лексера, предназначен для работы с генераторами синтаксического анализатора: обычно он используется с CUP или BYacc / J. Он также может работать с ANTLR.
Типичная грамматика (спецификация) разделена на три части, разделенные символом «%%»:
- код пользователя, который будет включен в сгенерированный класс,
- опции / макросы,
- и наконец правила лексера.
Файл спецификации JFlex
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
// taken from the documentation/* JFlex example: partial Java language lexer specification */import java_cup.runtime.*; %% // second section %class Lexer %unicode %cup [..] LineTerminator = \r|\n|\r\n %% // third section /* keywords */<YYINITIAL> "abstract" { return symbol(sym.ABSTRACT); }<YYINITIAL> "boolean" { return symbol(sym.BOOLEAN); }<YYINITIAL> "break" { return symbol(sym.BREAK); } <STRING> { \" { yybegin(YYINITIAL); return symbol(sym.STRING_LITERAL, string.toString()); } [..]} /* error fallback */[^] { throw new Error("Illegal character <"+ yytext()+">"); } |
Без контекста
Давайте посмотрим инструменты, которые генерируют парсеры без контекста.
ANTLR
ANTLR , пожалуй, самый используемый генератор синтаксических анализаторов для Java. ANTLR основан на новом алгоритме LL, разработанном автором и описанном в этой статье: Адаптивный анализ LL (*): сила динамического анализа (PDF) .
Он может выводить парсеры на многих языках. Но настоящая добавленная ценность огромного сообщества — это большое количество доступных грамматик . Версия 4 поддерживает прямые леворекурсивные правила.
Он предоставляет два способа обхода AST вместо встраивания действий в грамматику: посетители и слушатели. Первый подходит, когда вам нужно манипулировать элементами дерева или взаимодействовать с ними, а второй полезен, когда вам просто нужно что-то сделать, когда правило соответствует.
Типичная грамматика разделена на две части: правила лексера и правила парсера. Деление является неявным, поскольку все правила, начинающиеся с заглавной буквы, являются правилами лексера, а правила, начинающиеся со строчной буквы, являются правилами синтаксического анализатора. В качестве альтернативы грамматики лексера и синтаксического анализатора могут быть определены в отдельных файлах.
Очень простая грамматика ANTLR
|
1
2
3
4
5
6
7
|
grammar simple; basic : NAME ':' NAME ; NAME : [a-zA-Z]* ; COMMENT : '/*' .*? '*/' -> skip ; |
Если вы заинтересованы в ANTLR, вы можете заглянуть в этот гигантский учебник ANTLR, который мы написали.
APG
APG — это синтаксический анализатор с рекурсивным спуском, использующий вариацию Augmented BNF , которую они называют Superset Augmented BNF. ABNF — это особый вариант BNF, разработанный для лучшей поддержки протокола двунаправленной связи. APG также поддерживает дополнительные операторы, такие как синтаксические предикаты и пользовательские функции сопоставления, определенные пользователем.
Он может генерировать парсеры в C / C ++, Java и JavaScript. Поддержка последнего языка кажется превосходной и более современной: она имеет несколько дополнительных функций и выглядит более обновленной. Фактически в документации говорится, что она разработана так, чтобы иметь внешний вид JavaScript RegExp.
Поскольку он основан на ABNF, он особенно хорошо подходит для анализа языков многих технических спецификаций Интернета и фактически является предпочтительным анализатором для ряда крупных телекоммуникационных компаний.
Грамматика APG очень чистая и понятная.
Грамматика APG
|
1
2
3
4
5
6
7
8
|
// example from a tutorial of the author of the tool available herephone-number = ["("] area-code sep office-code sep subscriberarea-code = 3digit ; 3 digitsoffice-code = 3digit ; 3 digitssubscriber = 4digit ; 4 digitssep = *3(%d32-47 / %d58-126 / %d9) ; 0-3 ASCII non-digitsdigit = %d48-57 ; 0-9 |
BYACC / Дж
BYACC — это Yacc, который генерирует код Java. Вот и вся идея, и она определяет ее достоинства и недостатки. Хорошо известно, что это позволяет легче конвертировать Yacc и C-программу в Java-программу. Хотя вам, очевидно, все еще нужно преобразовать весь код C, встроенный в семантические действия, в код Java. Еще одним преимуществом является то, что вам не нужно отдельное время выполнения, сгенерированный парсер это все что вам нужно.
С другой стороны, он старый и мир разбора сделал много улучшений. Если вы опытный разработчик Yacc с кодовой базой для обновления, это хороший выбор, в противном случае есть много более современных альтернатив, которые вы должны рассмотреть.
Типичная грамматика состоит из трех разделов, разделенных «%%»: ДЕКЛАРАЦИИ, ДЕЙСТВИЯ и КОД. Второй содержит правила грамматики, а третий — пользовательский код пользователя.
Грамматика BYacc
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
// from the documentation%{ import java.lang.Math;import java.io.*;import java.util.StringTokenizer;%} /* YACC Declarations */%token NUM %left '-' '+' %left '*' '/' %left NEG /* negation--unary minus */ %right '^' /* exponentiation */ /* Grammar follows */%% input: /* empty string */ | input line ; line: '\n' | exp '\n' { System.out.println(" " + $1.dval + " "); } ;%% public static void main(String args[]){ Parser par = new Parser(false); [..]} |
Кокосовый / Р
Coco / R — это генератор компиляторов, который принимает атрибутированную грамматику и генерирует сканер и парсер рекурсивного спуска. Приписанная грамматика означает, что правила, написанные в варианте EBNF, могут быть аннотированы несколькими способами для изменения методов сгенерированного синтаксического анализатора.
Сканер включает в себя поддержку таких вещей, как директивы компилятора, называемые прагмами. Они могут быть проигнорированы парсером и обработаны пользовательским кодом. Сканер также можно отключить и заменить на созданный вручную.
Технически все грамматики должны быть LL (1), то есть синтаксический анализатор должен иметь возможность выбрать правильное правило только на один символ впереди. Но Coco / R предоставляет несколько методов, чтобы обойти это ограничение, включая семантические проверки, которые в основном являются пользовательскими функциями, которые должны возвращать логическое значение. В руководстве также приведены некоторые рекомендации по рефакторингу вашего кода для соблюдения этого ограничения.
Грамматика Coco / R выглядит следующим образом.
Коко / R грамматика
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
[Imports] // ident is the name of the grammar"COMPILER" ident // this includes arbitrary fields and method in the target language (eg. Java)[GlobalFieldsAndMethods]// ScannerSpecification CHARACTERS [..] zero = '0'. zeroToThree = zero + "123" . octalDigit = zero + "1234567" . nonZeroDigit = "123456789". digit = '0' + nonZeroDigit . [..] TOKENS ident = letter { letter | digit }.[..]// ParserSpecification PRODUCTIONS// just a rule is shownIdentList = ident <out int x> (. int n = 1; .) {',' ident (. n++; .) } (. Console.WriteLine("n = " + n); .) . // end"END" ident '.' |
Coco / R имеет хорошую документацию с несколькими примерами грамматики. Он поддерживает несколько языков, включая Java, C # и C ++.
CookCC
CookCC — это генератор парсера LALR (1), написанный на Java. Грамматики можно указывать тремя разными способами:
- в формате Yacc: он может читать грамматику, определенную для Yacc
- в своем собственном формате XML
- в коде Java, используя специальные аннотации
Уникальной особенностью является то, что он также может выводить грамматику Yacc. Это может быть полезно, если вам нужно взаимодействовать с инструментом, поддерживающим грамматику Yacc. Как какая-то старая программа на C, с которой вы должны поддерживать совместимость.
Для генерации парсера требуется Java 7, но он может работать на более ранних версиях.
Типичный парсер, определенный с аннотациями, будет выглядеть следующим образом.
Парсер CookCC
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
// required importimport org.yuanheng.cookcc.*; @CookCCOption (lexerTable = "compressed", parserTable = "compressed")// the generated parser class will be a parent of the one you define// in this case it will be "Parser"public class Calculator extends Parser{ // code // a lexer rule @Shortcuts ( shortcuts = { @Shortcut (name="nonws", pattern="[^ \\t\\n]"), @Shortcut (name="ws", pattern="[ \\t]") }) @Lex (pattern="{nonws}+", state="INITIAL") void matchWord () { m_cc += yyLength (); ++m_wc; } // a typical parser rules @Rule (lhs = "stmt", rhs = "SEMICOLON") protected Node parseStmt () { return new SemiColonNode (); }} |
Для стандарта генераторов синтаксического анализатора, использующего аннотации Java, это особый выбор. По сравнению с такой альтернативой, как ANTLR, между грамматикой и действиями, безусловно, нет четкого разделения. Это может усложнить поддержку синтаксического анализатора для сложных языков. Также портирование на другой язык может потребовать полного переписывания.
С другой стороны, этот подход позволяет смешивать грамматические правила с действиями, выполняемыми при их сопоставлении. Кроме того, он имеет преимущество в том, что интегрируется в IDE по вашему выбору, поскольку это просто код Java.
КРУЖКА
CUP — это аббревиатура построения полезных анализаторов, и это генератор синтаксических анализаторов LALR для Java. Он просто генерирует правильную парсерную часть, но он хорошо подходит для работы с JFlex. Хотя очевидно, что вы также можете создать лексер вручную для работы с CUP. Грамматика имеет синтаксис, похожий на Yacc, и позволяет встраивать код для каждого правила.
Он может автоматически генерировать дерево разбора, но не AST.
У него также есть плагин Eclipse, который поможет вам в создании грамматики, поэтому он имеет собственную IDE.
Типичная грамматика похожа на YACC.
CUP грамматика
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
// example from the documentation// CUP specification for a simple expression evaluator (w/ actions) import java_cup.runtime.*; /* Preliminaries to set up and use the scanner. */init with {: scanner.init(); :};scan with {: return scanner.next_token(); :}; /* Terminals (tokens returned by the scanner). */terminal SEMI, PLUS, MINUS, TIMES, DIVIDE, MOD;terminal UMINUS, LPAREN, RPAREN;terminal Integer NUMBER; /* Non-terminals */non terminal expr_list, expr_part;non terminal Integer expr; /* Precedences */precedence left PLUS, MINUS;precedence left TIMES, DIVIDE, MOD;precedence left UMINUS; /* The grammar */expr_list ::= expr_list expr_part | expr_part; expr_part ::= expr:e {: System.out.println("= " + e); :} SEMI ;[..] |
Grammatica
Grammatica является генератором синтаксического анализатора C # и Java (компилятор компилятора). Он читает файл грамматики (в формате EBNF) и создает хорошо прокомментированный и читаемый исходный код C # или Java для синтаксического анализатора. Он поддерживает грамматику LL (k), автоматическое восстановление после ошибок, читаемые сообщения об ошибках и четкое разделение между грамматикой и исходным кодом.
Описание на веб-сайте Grammatica само по себе является хорошим представлением Grammatica: простое в использовании, хорошо документированное, с большим количеством функций. Вы можете создать слушателя, создав подклассы сгенерированных классов, но не посетителя. Есть хорошая ссылка, но примеров не так много.
Типичная грамматика Grammatica состоит из трех разделов: заголовок, токены и продукция. Это также чисто, почти столько же, сколько ANTLR. Он также основан на аналогичном Extended BNF, хотя формат немного отличается.
Грамматика грамматики
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
%header% GRAMMARTYPE = "LL" [..] %tokens% ADD = "+"SUB = "-"[..]NUMBER = <<[0-9]+>>WHITESPACE = <<[ \t\n\r]+>> %ignore% %productions% Expression = Term [ExpressionTail] ; ExpressionTail = "+" Expression | "-" Expression ; Term = Factor [TermTail] ; [..] Atom = NUMBER | IDENTIFIER ; |
JACC
Jacc похож на BYACC / J, за исключением того, что он написан на Java, и поэтому он может работать везде, где может работать ваша программа. Как правило, он разработан как более современная версия Yacc. Автор описывает небольшие улучшения в таких областях, как сообщения об ошибках, модульность и поддержка отладки.
Если вы знаете Yacc и у вас нет базы кода для обновления, это может быть отличным выбором.
JavaCC
JavaCC — другой широко используемый генератор синтаксических анализаторов для Java. Файл грамматики содержит действия и весь пользовательский код, необходимый вашему анализатору.
По сравнению с ANTLR файл грамматики намного менее чист и содержит много исходного кода Java.
Грамматика JavaCC
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
javacc_options// "PARSER_BEGIN" "(" <IDENTIFIER> ")"PARSER_BEGIN(SimpleParser)public final class SimpleParser { // Standard parser class setup... public static void main(String args[]) { SimpleParser parser; java.io.InputStream input; }PARSER_END(SimpleParser) // the rules of the grammar// token rulesTOKEN :{ < #DIGIT : ["0"-"9"] >| < #LETTER : ["A"-"Z","a"-"z"] >| < IDENT : <LETTER> (<LETTER> | <DIGIT>)* >[..]} SKIP : { " " | "\t" | "\n" | "\r" } // parser rules [..] void IdentDef() : {}{ <IDENT> ("*" | "-")?} |
Благодаря своей длинной истории он используется в важных проектах, таких как JavaParser. Это оставило некоторые странности в документации и использовании. Например, технически сама JavaCC не создает AST, но поставляется с инструментом, который делает это, JTree, поэтому для практических целей это так.
Существует хранилище грамматики , но в нем мало грамматик. Требуется Java 5 или более поздняя версия.
ModelCC
ModelCC — это генератор синтаксических анализаторов на основе модели, который отделяет спецификацию языка от языковой обработки [..]. ModelCC получает концептуальную модель в качестве входных данных вместе с ограничениями, которые ее аннотируют.
В практическом плане вы определяете модель вашего языка, которая работает как грамматика в Java, используя аннотации. Затем вы передаете ModelCC созданную вами модель для получения анализатора.
С ModelCC вы определяете свой язык способом, который не зависит от используемого алгоритма синтаксического анализа. Вместо этого следует наилучшее концептуальное представление языка. Хотя, под капотом, он использует традиционный алгоритм разбора. Таким образом, грамматика сама по себе использует форму, независимую от любого алгоритма синтаксического анализа, но ModelCC не использует магию и создает обычный синтаксический анализатор.
Существует четкое описание намерений авторов инструментов, но ограниченная документация. Тем не менее, есть доступные примеры, включая следующую модель калькулятора, частично показанную здесь.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
public abstract class Expression implements IModel { public abstract double eval();} [..] public abstract class UnaryOperator implements IModel { public abstract double eval(Expression e);} [..] @Pattern(regExp="-")public class MinusOperator extends UnaryOperator implements IModel { @Override public double eval(Expression e) { return -e.eval(); }} @Associativity(AssociativityType.LEFT_TO_RIGHT)public abstract class BinaryOperator implements IModel { public abstract double eval(Expression e1,Expression e2);} [..] @Priority(value=2)@Pattern(regExp="-")public class SubtractionOperator extends BinaryOperator implements IModel { @Override public double eval(Expression e1,Expression e2) { return e1.eval()-e2.eval(); }} [..] |
SableCC
SableCC — это генератор синтаксических анализаторов, созданный для дипломной работы и имеющий целью быть простым в использовании и предлагая четкое разделение между грамматикой и кодом Java. Версия 3 также должна предлагать готовый способ пройти AST с помощью посетителя. Но это все в теории, потому что практически нет документации, и мы не знаем, как использовать любую из этих вещей.
Кроме того, версия 4 была запущена в 2015 году и, по-видимому, заброшена.
UrchinCC
Urchin (CC) — это генератор парсера, который позволяет вам определить грамматику, называемую определением парсера Urchin. Затем вы генерируете парсер Java из него. Urchin также генерирует посетителя из UPD.
Существует исчерпывающее руководство, которое также используется для объяснения работы Urchin и ее ограничений, но оно ограничено.
UPD разделен на три раздела: терминалы, токен и правила.
Файл UPD
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
terminals { Letters ::= 'a'..'z', 'A'..'Z'; Digits ::= '0'..'9';} token { Space ::= [' ', #8, #9]*1; EOLN ::= [#10, #13]; EOF ::= [#65535]; [..] Identifier ::= [Letters] [Letters, Digits]*;} rules { Variable ::= "var", Identifier; Element ::= Number | Identifier; PlusExpression ::= Element, '+', Expression; [..]} |
PEG
После парсеров CFG пришло время увидеть парсеры PEG, доступные на Java.
балдахин
Canopy — это компилятор парсера, ориентированный на Java, JavaScript, Python и Ruby. Он берет файл, описывающий грамматику синтаксического анализа, и компилирует его в модуль синтаксического анализа на целевом языке. Сгенерированные парсеры не имеют зависимости во время выполнения от самого Canopy.
Это также обеспечивает легкий доступ к узлам дерева разбора.
Грамматика Canopy имеет удобную функцию использования аннотации действий для использования пользовательского кода в синтаксическом анализаторе. В практическом плане. вы просто пишете имя функции рядом с правилом, а затем реализуете функцию в своем исходном коде.
Грамматика навеса с действиями
|
1
2
3
4
5
6
7
|
// the actions are prepended by %grammar Maps map <- "{" string ":" value "}" %make_map string <- "'" [^']* "'" %make_string value <- list / number list <- "[" value ("," value)* "]" %make_list number <- [0-9]+ %make_number |
Файл Java, содержащий код действия.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
[..]import maps.Actions;[..] class MapsActions implements Actions { public Pair make_map(String input, int start, int end, List<TreeNode> elements) { Text string = (Text)elements.get(1); Array array = (Array)elements.get(3); return new Pair(string.string, array.list); } [..]} |
Лая
Laja — это двухфазный генератор синтаксического анализатора обратного отслеживания без поддержки сканера с поддержкой правил грамматики во время выполнения.
Laja — генератор кода и генератор синтаксического анализатора, и он в основном предназначен для создания внешних DSL. Это означает, что у него есть некоторые особенности. С Laja вы должны указать не только структуру данных, но и то, как данные должны отображаться в структуры Java. Эти структуры обычно являются объектами иерархической или плоской организации. Короче говоря, он позволяет очень легко анализировать файлы данных, но он менее подходит для универсального языка программирования.
Параметры Laja, такие как выходной каталог или входной файл, задаются в файле конфигурации.
Грамматика Лая разделена на раздел правил и раздел отображения данных. Похоже на это.
Лая грамматика
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
// this example is from the documentationgrammar example { s = [" "]+; newline = "\r\n" | "\n"; letter = "a".."z"; digit = "0".."9"; label = letter [digit|letter]+; row = label ":" s [!(newline|END)+]:value [newline]; example = row+; Row row.setLabel(String label); row.setValue(String value); Example example.addRow(Row row);} |
мышь
Мышь — это инструмент для преобразования PEG в исполняемый синтаксический анализатор, написанный на Java.
Он не использует packrat и, следовательно, он использует меньше памяти, чем обычный PEG-парсер (руководство явно сравнивает мышь с крысами!).
У него нет хранилища грамматики, но есть грамматики для Java 6-8 и C.
Грамматика мыши довольно чистая. Чтобы включить пользовательский код, функцию, называемую семантическими предикатами, вы делаете нечто похожее на то, что вы делаете в Canopy. Вы включаете имя в грамматику, а затем, в файле Java, на самом деле пишете пользовательский код.
Грамматика мыши
|
1
2
3
4
5
6
7
8
9
|
// example from the manual// the semantics are between {}Sum = Space Sign Number (AddOp Number)* !_ {sum} ;Number = Digits Space {number} ;Sign = ("-" Space)? ;AddOp = [-+] Space ;Digits = [0-9]+ ;Space = " "* ; |
Крысы!
Крысы! является частью генератора синтаксического анализатора xtc (eXTensible Compiler). Он основан на PEG, но использует «дополнительные выражения и операторы, необходимые для генерации реальных анализаторов». Поддерживает леворекурсивное производство. Он может автоматически генерировать AST.
Требуется Java 6 или более поздняя версия.
Грамматика может быть довольно чистой, но вы можете вставлять собственный код после каждого производства.
Крысы! грамматика
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
// example from Introduction to the Rats! Parser Generator/* module intro */module Simple;option parser(SimpleParser); /* productions for syntax analysis */public String program = e:expr EOF { yyValue = e; } ;String expr = t:term r:rest { yyValue = t + r; } ;String rest = PLUS t:term r:rest { yyValue = t + "+" + r; } / MINUS t:term r:rest { yyValue = t + "-" + r; } / /*empty*/ { yyValue = ""; } ;String term = d:DIGIT { yyValue = d; } ; /* productions for lexical analysis */void PLUS = "+";void MINUS = "-";String DIGIT = [0-9];void EOF = ! ; |
Parser Combinators
Они позволяют вам создавать синтаксический анализатор просто с помощью кода Java, комбинируя различные функции сопоставления с образцом, которые эквивалентны грамматическим правилам. Они, как правило, считаются подходящими для более простого анализа. Поскольку они являются просто библиотеками Java, вы можете легко ввести их в свой проект: вам не требуется какой-либо конкретный шаг генерации, и вы можете написать весь свой код в своем любимом редакторе Java. Их основным преимуществом является возможность интеграции в ваш традиционный рабочий процесс и IDE.
На практике это означает, что они очень полезны для всех небольших проблем с анализом, которые вы обнаружите. Если типичный разработчик сталкивается с проблемой, которая слишком сложна для простого регулярного выражения, эти библиотеки обычно являются решением. Короче говоря, если вам нужно создать синтаксический анализатор, но вы на самом деле этого не хотите, то комбинатор синтаксического анализатора может быть вашим лучшим вариантом.
Jparsec
Jparsec — это порт библиотеки парсек Haskell.
Парсеры-комбинаторы обычно используются в одной фазе, то есть без лексера. Это просто потому, что он может быстро стать слишком сложным, чтобы управлять всеми цепями комбинаторов непосредственно в коде. Сказав это, у jparsec есть специальный класс для поддержки лексического анализа.
Он не поддерживает леворекурсивные правила, но предоставляет специальный класс для наиболее распространенного варианта использования: управление приоритетом операторов.
Типичный парсер, написанный на jparsec, похож на этот.
Парсер калькулятора с Jparsec
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
// from the documentationpublic class Calculator { static final Parser<Double> NUMBER = Terminals.DecimalLiteral.PARSER.map(Double::valueOf); private static final Terminals OPERATORS = Terminals.operators("+", "-", "*", "/", "(", ")"); [..] static final Parser<?> TOKENIZER = Parsers.or(Terminals.DecimalLiteral.TOKENIZER, OPERATORS.tokenizer()); [..] static Parser<Double> calculator(Parser<Double> atom) { Parser.Reference<Double> ref = Parser.newReference(); Parser<Double> unit = ref.lazy().between(term("("), term(")")).or(atom); Parser<Double> parser = new OperatorTable<Double>() .infixl(op("+", (l, r) -> l + r), 10) .infixl(op("-", (l, r) -> l - r), 10) .infixl(Parsers.or(term("*"), WHITESPACE_MUL).retn((l, r) -> l * r), 20) .infixl(op("/", (l, r) -> l / r), 20) .prefix(op("-", v -> -v), 30) .build(unit); ref.set(parser); return parser; } public static final Parser<Double> CALCULATOR = calculator(NUMBER).from(TOKENIZER, IGNORED);} |
обданный кипяток
Parboiled предоставляет реализацию синтаксического анализатора PEG с рекурсивным спуском, которая работает с указанными вами правилами PEG.
Цель Parboiled — предоставить простой в использовании и понять способ создания небольших DSL в Java. Он оказался между простым набором регулярных выражений и генератором парсера промышленного уровня, таким как ANTLR. Пропаркованная грамматика может включать действия с пользовательским кодом, включенным непосредственно в код грамматики или через интерфейс.
Пример парофилированного парсера
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
// example parser from the parboiled repository// CalculatorParser4.java package org.parboiled.examples.calculators; [..] @BuildParseTreepublic class CalculatorParser4 extends CalculatorParser<CalcNode> { @Override public Rule InputLine() { return Sequence(Expression(), EOI); } public Rule Expression() { return OperatorRule(Term(), FirstOf("+ ", "- ")); } [..] public Rule OperatorRule(Rule subRule, Rule operatorRule) { Var<Character> op = new Var<Character>(); return Sequence( subRule, ZeroOrMore( operatorRule, op.set(matchedChar()), subRule, push(new CalcNode(op.get(), pop(1), pop())) ) ); } [..] public Rule Number() { return Sequence( Sequence( Optional(Ch('-')), OneOrMore(Digit()), Optional(Ch('.'), OneOrMore(Digit())) ), // the action uses a default string in case it is run during error recovery (resynchronization) push(new CalcNode(Double.parseDouble(matchOrDefault("0")))), WhiteSpace() ); } //**************** MAIN **************** public static void main(String[] args) { main(CalculatorParser4.class); }} |
Он не создает AST для вас, но предоставляет дерево разбора и некоторые классы, чтобы упростить его построение.
Документация очень хорошая, она объясняет особенности, показывает пример, сравнивает идеи, стоящие за этим, с другими вариантами. В репозитории есть несколько примеров грамматик, в том числе для Java.
Он используется несколькими проектами, в том числе такими важными, как neo4j .
PetitParser
PetitParser объединяет идеи от синтаксического анализа без сканера, комбинаторов синтаксического анализа, грамматики синтаксического анализа и синтаксических анализаторов пакетов до грамматических моделей и синтаксических анализаторов как объекты, которые можно динамически реконфигурировать.
PetitParser представляет собой нечто среднее между комбинатором парсера и традиционным генератором парсера. Вся информация записана в исходном коде, но исходный код разделен на два файла. В одном файле вы определяете грамматику, а в другом вы определяете действия, соответствующие различным элементам. Идея состоит в том, что это должно позволить вам динамически переопределять грамматики. В то время как он бойко инженерии, это спорно, если он также бойко разработан. Вы можете видеть, что пример грамматики JSON более длинный, чем можно ожидать.
Выдержка из файла примера грамматики для JSON.
Пример грамматики PetitParser
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
package org.petitparser.grammar.json; [..] public class JsonGrammarDefinition extends GrammarDefinition { // setup code not shown public JsonGrammarDefinition() { def("start", ref("value").end()); def("array", of('[').trim() .seq(ref("elements").optional()) .seq(of(']').trim())); def("elements", ref("value").separatedBy(of(',').trim())); def("members", ref("pair").separatedBy(of(',').trim())); [..] def("trueToken", of("true").flatten().trim()); def("falseToken", of("false").flatten().trim()); def("nullToken", of("null").flatten().trim()); def("stringToken", ref("stringPrimitive").flatten().trim()); def("numberToken", ref("numberPrimitive").flatten().trim()); [..] }} |
Выдержка из примера файла определения синтаксического анализатора (который определяет действия для правил) для JSON.
Файл определения парсера для PetitParser
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
package org.petitparser.grammar.json; import org.petitparser.utils.Functions; public class JsonParserDefinition extends JsonGrammarDefinition { public JsonParserDefinition() { action("elements", Functions.withoutSeparators()); action("members", Functions.withoutSeparators()); action("array", new Function<List<List<?>>, List<?>>() { @Override public List<?> apply(List<List<?>> input) { return input.get(1) != null ? input.get(1) : new ArrayList<>(); } }); [..] }} |
Существует версия, написанная на Java, но есть также версии на Smalltalk, Dart, PHP и TypeScript.
Документация отсутствует, но есть примеры доступных грамматик.
Библиотеки Java, которые разбирают Java: JavaParser
Существует один особый случай, который требует дополнительных комментариев: случай, когда вы хотите проанализировать код Java в Java. В этом случае мы должны предложить использовать библиотеку с именем JavaParser . Кстати, мы вносим большой вклад в JavaParser, но это не единственная причина, по которой мы его предлагаем. Дело в том, что JavaParser — это проект с десятками участников и тысячами пользователей, поэтому он довольно устойчивый.
Быстрый список возможностей:
- он поддерживает все версии Java от 1 до 9
- он поддерживает лексическое сохранение и красивую печать: это означает, что вы можете анализировать код Java, изменять его и распечатывать обратно либо с оригинальным форматированием, либо с довольно печатным
- это может использоваться с JavaSymbolSolver , который дает вам разрешение символа. Т.е. он понимает, какие методы вызываются, с какими ссылками связаны объявления, вычисляет тип выражений и т. Д.
Будучи убеждена? Вы все еще хотите написать свой собственный анализатор Java для Java?
Резюме
Разбор в Java — это широкая тема, и мир парсеров немного отличается от обычного мира программистов. Вы найдете лучшие инструменты, поступающие непосредственно из научных кругов, что, как правило, не относится к программному обеспечению. Некоторые инструменты и библиотеки были запущены для дипломной работы или исследовательского проекта. Плюс в том, что инструменты, как правило, легко и свободно доступны. Недостатком является то, что некоторые авторы предпочитают иметь хорошее объяснение теории того, что делают их инструменты, а не хорошую документацию о том, как их использовать. Кроме того, некоторые инструменты заканчиваются тем, что авторы заканчивают работу над магистром или доктором наук.
Мы часто используем генераторы парсеров: ANTLR — наш любимый, и мы широко используем JavaCC в нашей работе над JavaParser. Мы не очень часто используем комбинаторы парсеров. Это не потому, что они плохие, у них есть свое применение, и на самом деле мы написали статью об одном в C # . Но из-за проблем, с которыми мы сталкиваемся, они обычно приводят к менее управляемому коду. Однако с ними может быть легче начать, так что вы можете рассмотреть их. Особенно, если до сих пор вы взламывали что-то ужасное, используя регулярные выражения и наполовину запеченный парсер, написанный вручную.
Мы не можем точно сказать вам, какое программное обеспечение вы должны использовать. То, что лучше для пользователя, может быть не лучшим для кого-то еще. И все мы знаем, что наиболее технически правильное решение может быть не идеальным в реальной жизни со всеми его ограничениями. Но мы искали и пробовали много подобных инструментов в нашей работе, и что-то вроде этой статьи помогло бы нам сэкономить время. Поэтому мы хотели поделиться тем, что мы узнали о лучших вариантах синтаксического анализа в Java.
| Ссылка: | Разбор в Java: все инструменты и библиотеки, которые вы можете использовать от нашего партнера JCG блоге . |