Мы экспериментировали с CaffeOnSpark на 5-узловом кластере MapR 5.1 под управлением Spark 1.5.2 и поделимся своим опытом, трудностями и решениями в этом блоге.
Глубокое обучение и кафе
В последнее время глубокому изучению уделяется много внимания, так как AlphaGo обыграл лучшего игрока в мире в игре, которая считалась настолько сложной, что была недоступна для компьютеров всего пять лет назад. Глубокое обучение — это не только избиение людей в Go, но и почти во всех компьютерных играх Atari .
Но дело в том, что глубокое обучение также полезно для задач с понятными корпоративными приложениями в области классификации изображений и распознавания речи , искусственных чатов и машинного перевода , и это лишь некоторые из них.
Caffe — это система глубокого обучения на C ++ / CUDA, изначально разработанная Центром обучения и изучения Беркли (BVLC). Это особенно хорошо подходит для приложений, связанных с изображениями. Caffe может использовать мощь графических процессоров с поддержкой CUDA, таких как любые потребительские графические процессоры NVIDIA, а это означает, что любой, у кого есть игровой ПК, может выполнить самое современное глубокое обучение для себя. Здорово!
Более того, модели Caffe часто публикуются. Таким образом, мы можем попробовать для себя абсолютные современные модели, обученные на огромных наборах данных ведущими исследователями в этой области. Например, классификатор изображений Microsoft, победивший в 2015 году, доступен здесь .
Проект с открытым исходным кодом можно найти на GitHub и имеет домашнюю страницу со всеми необходимыми инструкциями, чтобы он работал на Linux и MacOS X, и даже имеет дистрибутив Windows .
CaffeOnSpark
Основная проблема с Caffe и глубоким обучением на уровне потребителя заключается в том, что они могут работать только на одном компьютере, который ограничен максимум четырьмя графическими процессорами. Для реальных корпоративных приложений наборы данных могут легко масштабироваться до сотен ГБ данных, что требует нескольких дней вычислений даже на самом быстром из возможных аппаратных узлов с одним узлом.
Google, Baidu и Microsoft располагают ресурсами для создания специализированных кластеров глубокого обучения, которые обеспечивают алгоритмам глубокого обучения уровень вычислительной мощности, который одновременно ускоряет обучение и повышает точность их модели. Такие вычислительные кластеры монстров стали необходимым условием для достижения наилучших результатов на уровне человека (или лучше ) с помощью моделей глубокого обучения.
Yahoo, однако, выбрала несколько иной подход, отойдя от выделенного кластера глубокого обучения и объединив Caffe со Spark. Программное обеспечение CaffeOnSpark команды ML Big Data позволило им запустить весь процесс построения и развертывания модели глубокого обучения в одном кластере. Это программное обеспечение было выпущено с открытым исходным кодом в конце прошлого года и теперь доступно на GitHub .
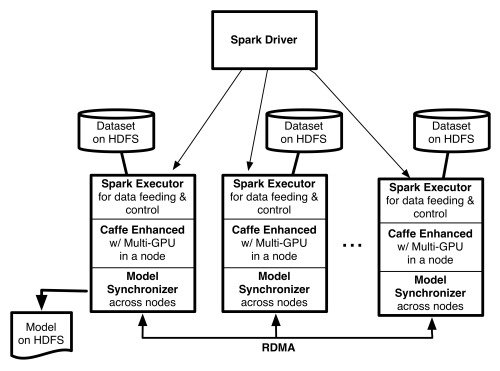
Запуск CaffeOnSpark на MapR
Наш кластер работал под управлением MapR 5.1 на 5 узлах, развернутых на экземплярах AWS EC2. Каждый узел представляет собой большой экземпляр m4.4x с 12 vcores и 30 ГБ памяти. Выбранная операционная система — Ubuntu 14.04. Версия Spark — это версия 1.5.2, поставляемая MapR, слегка измененная для учета высокопроизводительной файловой системы C-native MapR вместо HDFS.
Сначала мы установили Caffe на один из узлов, чтобы убедиться, что настройка действительно совместима с Caffe. Вики-страница с их Github была бесценным руководством по эксплуатации, которое позволяло достаточно простую установку. В нашем экземпляре нет графического процессора, но не установка CUDA может привести к ошибке компиляции при установке CaffeOnSpark, поэтому мы рекомендуем установить драйверы в любом случае. Мы установили версию CUDA 7.5, самую последнюю на момент написания этой статьи. Все шаги работали как есть. Установка PyCaffe не обязательна, но это хороший способ убедиться, что установка действительно идеальна.
Мы запустили компиляцию, выполнили тесты, а также выполнили пример задачи с цифрами MNIST.
Для этого примера из папки Caffe запустите data / mnist / get_mnisn.sh, затем examples / mnist / create_mnist.sh и, наконец, example / mnist / train_lenet.sh.
Вы можете проверить установку pycaffe, запустив make pycaffe, а затем перейдите в папку Caffe / python и откройте оболочку Python и введите. import caffe Если все импортирует, несмотря на несколько предупреждений Matplotlib, то установка прошла идеально.
После проверки правильности установки Caffe мы получили CaffeOnSpark и скомпилировали его, следуя инструкциям на вики-странице GitHub . Примечание: убедитесь, что вы также установили maven и zip (sudo apt-get install zip maven -y) перед началом компиляции, они обязательны! К счастью, если у вас их нет и вы все равно начинаете компиляцию, ошибка легко понимается, и установка недостающих битов, а также перезапуск компиляции также приводят к правильной установке.
Скопируйте папку CaffeOnSpark на все узлы. Это важно! Расположение папки должно быть везде одинаковым. Мы запустили все как root, но это, вероятно, не нужно.
В инструкциях упоминается:
|
1
2
|
export LD_LIBRARY_PATH=${CAFFE_ON_SPARK}/caffe-public/distribute/lib:${CAFFE_ON_SPARK}/caffe-distri/distribute/libexport LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/cuda-7.0/lib64:/usr/local/mkl/lib/intel64/ |
Очевидно, нам нужно обновить cuda-7.0 до cuda-7.5, а также удалить часть из MKL от Intel, поскольку мы ее не используем. Мы добавили это в файл .bashrc.
|
1
|
export LD_LIBRARY_PATH=${CAFFE_ON_SPARK}/caffe-public/distribute/lib:${CAFFE_ON_SPARK}/caffe-distri/distribute/lib:/usr/local/cuda-7.5/lib64 |
На самом деле, мы также добавили в наш .bashrc:
|
1
2
3
4
5
6
|
export JAVA_HOME=/usr/lib/jvm/java-7-oracle/export CUDA_HOME=/usr/local/cuda-7.5export CAFFE_HOME=/root/caffeexport CAFFE_ON_SPARK=/root/CaffeOnSparkexport SPARK_HOME=/opt/mapr/spark/spark-1.5.2export LD_LIBRARY_PATH=${CAFFE_ON_SPARK}/caffe-public/distribute/lib:${CAFFE_ON_SPARK}/caffe-distri/distribute/libexport LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/cuda-7.5/lib64 |
Запуск CaffeOnSpark
Автономный режим
Сначала мы запустили CaffeOnSpark на примере MNIST в автономном режиме, следуя инструкциям GitHub .
Успешный заезд подтолкнул нас попробовать его на YARN.
Кластерный режим YARN
Мы выполнили инструкции для YARN и вскоре смогли заставить его работать, но с оговоркой, что каждый работник использует только один vcore.
Способ работы CaffeOnSpark заключается в том, что работники кластера используются для параллельного обучения моделей Caffe, а затем модели собираются обратно с помощью REDUCE; модели усредняются, и новые задания отправляются обратно работникам с обновленными параметрами.
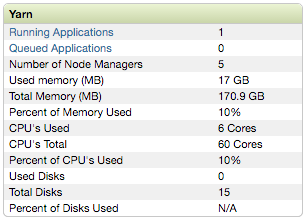
Только с 5 исполнителями, каждый с 1 vcore, плюс 1 vcore для драйвера, используя параметры командной строки, предложенные в инструкциях CaffeOnSpark, значительно используют мощность ЦП нашего кластера. Фактически, каждая итерация Caffe занимала около 18 секунд.
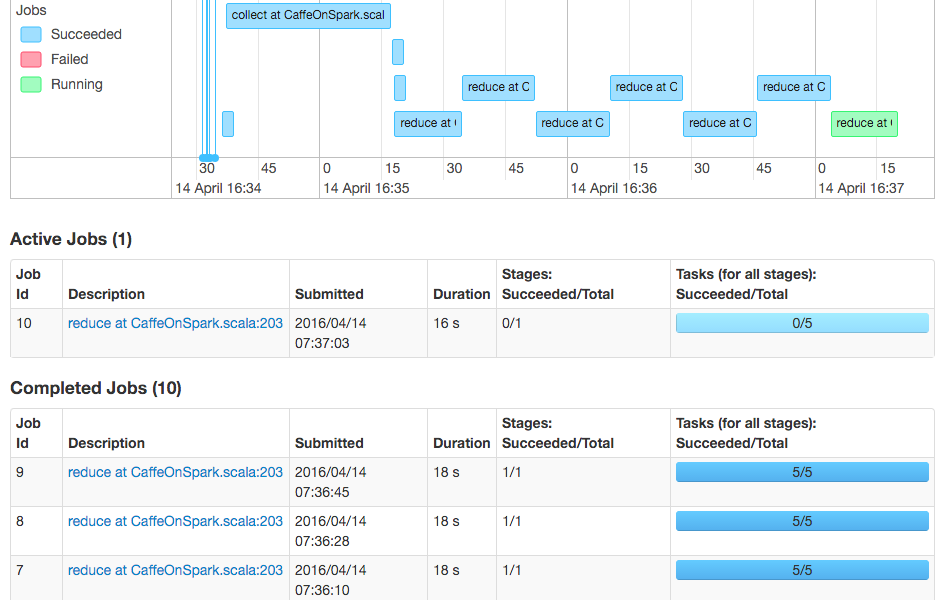
Работа с исключениями и настройкой производительности
У нас были случайные ошибки при попытке играть с параметром –num-executors; CaffeOnSpark выдает исключение из-за того, что исполнители не найдены в правильном номере. Мы могли бы заставить его работать иногда, если для параметра -num-executors задано пять, то же самое, что и число рабочих, но иногда это также приводило бы к исключению.
Эта проблема была решена с использованием следующих параметров:
|
1
2
|
--conf spark.scheduler.minRegisteredResourcesWaitingTime=30--conf spark.scheduler.minRegisteredResourcesRatio=1.0 |
YARN в кластерном режиме представляет драйвер как контейнер, и к тому времени, когда драйвер начинает выполняться, все рабочие исполнители могут быть не готовы и недоступны, поэтому, когда CaffeOnSpark проверяет правильное количество исполнителей, он находит неожиданное количество и выдает исключение. Предоставляя больше времени и требуя, чтобы все зарегистрированные ресурсы были доступны, эту ошибку можно исправить.
Исправив эту ошибку, мы смогли увеличить количество ядер, используя следующие параметры:
|
1
2
|
--num-executors X--executor-cores Y |
Где X — количество исполнителей, а Y — количество ядер на одного исполнителя. X * Y должно быть немного меньше, чем общее число доступных для YARN значений. В нашем случае у нас всего 60 vcores, поэтому мы поиграли с различными комбинациями X и Y и обнаружили, что X = 25 и Y = 2 производят самые быстрые итерации за 8 с, а X = 50 и Y = 1 максимально загружают процессор кластер, но с немного более длинными итерациями около 9 с.
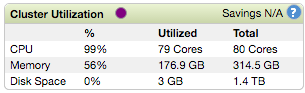
Мы знаем, что при глубоком обучении большая вычислительная мощность выгодна как для повышения точности, так и для сокращения времени обучения. Поэтому мы считаем, что по мере увеличения числа исполнителей точность окончательных моделей будет лучше, но время обучения, учитывая наше аппаратное и программное обеспечение и архитектуру CaffeOnSpark, ограничивает каждую итерацию в лучшем случае примерно 8 секундами.
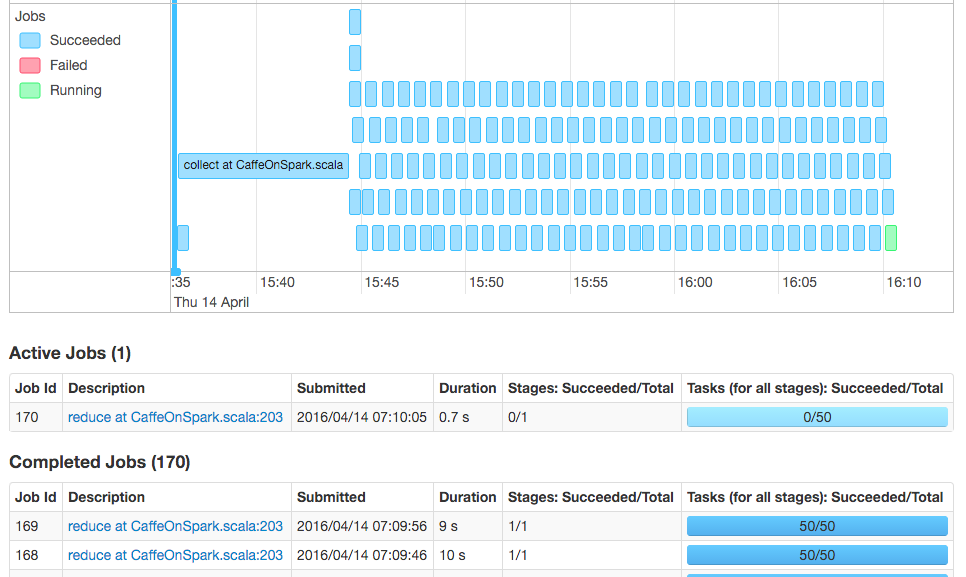
Задачи не ограничены в памяти, и кластер никогда не использует более 60% общей памяти. Узкое место ввода-вывода также довольно маловероятно, поскольку набор данных MNIST настолько мал, что составляет всего 60 МБ для набора поездов и 10 МБ для набора тестов. Наконец, анализ DAG из веб-интерфейса Spark показывает, что на ЦП приходится> 95% времени, затрачиваемого на каждое задание карты, поэтому неэффективность сети или распределения для этого набора данных, вероятно, также не является узким местом.
Еще одна вещь, которую мы заметили, заключается в том, что число итераций до конвергенции увеличивается с количеством исполнителей. Трудно сделать какой-либо вывод по этому поводу, потому что задача MNIST считается очень легкой на данный момент. Получение метрик точности и потерь в реальном наборе данных было бы поучительным для того, что именно здесь происходит.
Вывод
Реализация MapR Spark — отличная цель для запуска CaffeOnSpark. В качестве последующего проекта было бы целесообразно провести повторное тестирование в кластере с использованием экземпляров EC2 с графическими процессорами и увидеть разницу в производительности.
Причина, по которой Yahoo разрабатывает CaffeOnSpark в первую очередь, заключается в том, чтобы объединить их операции по глубокому обучению в одном кластере, и это очень важно. Платформа конвергентных данных MapR является идеальной платформой для этого проекта, предоставляя вам все возможности распределенного Caffe в кластере с надежностью корпоративного уровня, что позволяет вам использовать преимущества высокопроизводительной файловой системы MapR. ![]()
| Ссылка: | Распространение глубокого обучения с помощью Caffe с использованием кластера MapR от нашего партнера по JCG Матье Дюмулена в блоге Mapr . |