Несколько недель назад я натолкнулся на твит Шона Тейлора с просьбой предоставить набор данных о погоде с записью за несколько лет, и я с удивлением узнал, что в R уже есть такая вещь — пакет weatherData .
Победитель: @UTVilla ! библиотека (weatherData) df <- getWeatherForYear («SFO», 2013) ggplot (df, aes (x = дата, y = Mean_TemperaF)) + geom_line ()
— Шон Дж. Тейлор (@seanjtaylor) 22 января 2015 г.
WeatherData представляет собой тонкую оболочку API Wunderground и была именно тем, что я искал, чтобы сравнить встречу в лондонском NoSQL с погодными условиями того дня.
Первым шагом было загрузить соответствующие записи о погоде и сохранить их в файл CSV, чтобы мне не приходилось вызывать API.
Я подумал, что могу также скачать все доступные мне записи и написал следующий код, чтобы это произошло:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
library(weatherData) # London City AirportgetDetailedWeatherForYear = function(year) { getWeatherForDate("LCY", start_date= paste(sep="", year, "-01-01"), end_date = paste(sep="", year, "-12-31"), opt_detailed = FALSE, opt_all_columns = TRUE)} df = rbind(getDetailedWeatherForYear(2011), getDetailedWeatherForYear(2012), getDetailedWeatherForYear(2013), getDetailedWeatherForYear(2014), getWeatherForDate("LCY", start_date="2015-01-01", end_date = "2015-01-25", opt_detailed = FALSE, opt_all_columns = TRUE)) |
Затем я сохранил это в файл CSV:
|
1
|
write.csv(df, 'weather/temp_data.csv', row.names = FALSE) |
|
01
02
03
04
05
06
07
08
09
10
|
"Date","GMT","Max_TemperatureC","Mean_TemperatureC","Min_TemperatureC","Dew_PointC","MeanDew_PointC","Min_DewpointC","Max_Humidity","Mean_Humidity","Min_Humidity","Max_Sea_Level_PressurehPa","Mean_Sea_Level_PressurehPa","Min_Sea_Level_PressurehPa","Max_VisibilityKm","Mean_VisibilityKm","Min_VisibilitykM","Max_Wind_SpeedKm_h","Mean_Wind_SpeedKm_h","Max_Gust_SpeedKm_h","Precipitationmm","CloudCover","Events","WindDirDegrees"2011-01-01,"2011-1-1",7,6,4,5,3,1,93,85,76,1027,1025,1023,10,9,3,14,10,NA,0,7,"Rain",3122011-01-02,"2011-1-2",4,3,2,1,0,-1,87,81,75,1029,1028,1027,10,10,10,11,8,NA,0,7,"",3212011-01-03,"2011-1-3",4,2,1,0,-2,-5,87,74,56,1028,1024,1019,10,10,10,8,5,NA,0,6,"Rain-Snow",2492011-01-04,"2011-1-4",6,3,1,3,1,-1,93,83,65,1019,1013,1008,10,10,10,21,6,NA,0,5,"Rain",2242011-01-05,"2011-1-5",8,7,5,6,3,0,93,80,61,1008,1000,994,10,9,4,26,16,45,0,4,"Rain",2002011-01-06,"2011-1-6",7,4,3,6,3,1,93,90,87,1002,996,993,10,9,5,13,6,NA,0,5,"Rain",2812011-01-07,"2011-1-7",11,6,2,9,5,2,100,91,82,1003,999,996,10,7,2,24,11,NA,0,5,"Rain-Snow",1242011-01-08,"2011-1-8",11,7,4,8,4,-1,87,77,65,1004,997,987,10,10,5,39,23,50,0,5,"Rain",2302011-01-09,"2011-1-9",7,4,3,1,0,-1,87,74,57,1018,1012,1004,10,10,10,24,16,NA,0,NA,"",242 |
Если мы хотим прочитать это в будущем, мы можем сделать это с помощью следующего кода:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
weather = read.csv("weather/temp_data.csv")weather$Date = as.POSIXct(weather$Date) > weather %>% sample_n(10) %>% select(Date, Min_TemperatureC, Mean_TemperatureC, Max_TemperatureC) Date Min_TemperatureC Mean_TemperatureC Max_TemperatureC1471 2015-01-10 5 9 14802 2013-03-12 -2 1 41274 2014-06-27 14 18 22848 2013-04-27 5 8 10832 2013-04-11 6 8 10717 2012-12-17 6 7 91463 2015-01-02 6 9 131090 2013-12-25 4 6 7560 2012-07-13 15 18 201230 2014-05-14 9 14 19 |
Следующим шагом было объединение данных о погоде с данными о посещаемости собрания, которые у меня уже были.
Для простоты я сохранил их в файле CSV, так как мы можем просто прочитать их:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
timestampToDate <- function(x) as.POSIXct(x / 1000, origin="1970-01-01", tz = "GMT") events = read.csv("events.csv")events$eventTime = timestampToDate(events$eventTime) > events %>% sample_n(10) %>% select(event.name, rsvps, eventTime) event.name rsvps eventTime36 London Office Hours - Old Street 10 2012-01-18 17:00:00137 Enterprise Search London 34 2011-05-23 18:15:00256 MarkLogic User Group London: Jim Fuller 40 2014-04-29 18:30:00117 Neural Networks and Data Science 171 2013-03-28 18:30:00210 London Office Hours - Old Street 3 2011-09-15 17:00:00443 July social! 12 2014-07-14 19:00:00322 Intro to Graphs 39 2014-09-03 18:30:00203 Vendor focus: Amazon CloudSearch 24 2013-05-16 17:30:0017 Neo4J Tales from the Trenches: A Recommendation Engine Case Study 12 2012-04-25 18:30:0055 London Office Hours 10 2013-09-18 17:00:00 |
Теперь, когда у нас есть два готовых набора данных, мы можем построить простой график средней посещаемости и температуры, сгруппированных по месяцам:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
byMonth = events %>% mutate(month = factor(format(eventTime, "%B"), levels=month.name)) %>% group_by(month) %>% summarise(events = n(), count = sum(rsvps)) %>% mutate(ave = count / events) %>% arrange(desc(ave)) averageTemperatureByMonth = weather %>% mutate(month = factor(format(Date, "%B"), levels=month.name)) %>% group_by(month) %>% summarise(aveTemperature = mean(Mean_TemperatureC)) g1 = ggplot(aes(x = month, y = aveTemperature, group=1), data = averageTemperatureByMonth) + geom_line( ) + ggtitle("Temperature by month") g2 = ggplot(aes(x = month, y = count, group=1), data = byMonth) + geom_bar(stat="identity", fill="dark blue") + ggtitle("Attendance by month") library(gridExtra)grid.arrange(g1,g2, ncol = 1) |
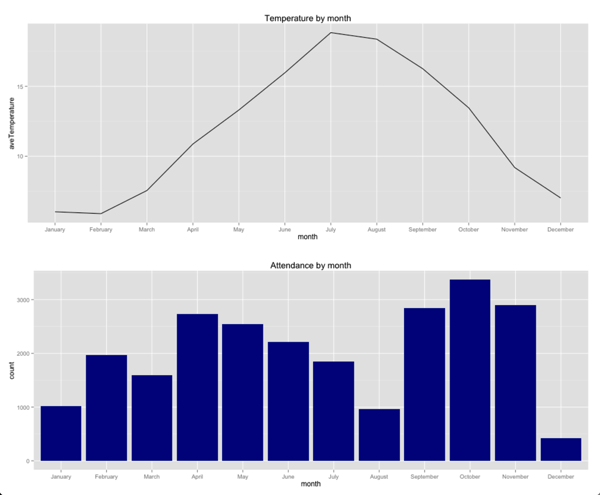
Мы можем видеть грубую обратную корреляцию между температурой и посещаемостью, особенно в период с апреля по август — по мере повышения температуры общая посещаемость уменьшается.
Но что делать, если мы сравниваем на более тонком уровне детализации, такой как конкретная дата? Мы можем сделать это, добавив столбец «день» к нашему фрейму данных о событиях и объединив его с погодным:
|
1
2
3
4
5
6
7
8
9
|
byDay = events %>% mutate(day = as.Date(as.POSIXct(eventTime))) %>% group_by(day) %>% summarise(events = n(), count = sum(rsvps)) %>% mutate(ave = count / events) %>% arrange(desc(ave))weather = weather %>% mutate(day = Date)merged = merge(weather, byDay, by = "day") |
Теперь мы можем построить график зависимости посещаемости от средней температуры для отдельных дней:
|
1
2
|
ggplot(aes(x =count, y = Mean_TemperatureC,group = day), data = merged) + geom_point() |
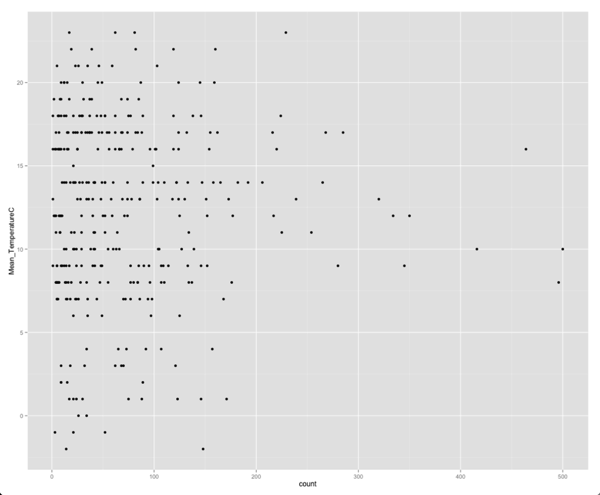
Интересно, что сейчас, кажется, нет никакой корреляции между температурой и посещаемостью. Мы можем подтвердить наши подозрения, запустив корреляцию:
|
1
2
|
> cor(merged$count, merged$Mean_TemperatureC)[1] 0.008516294 |
Даже 1% корреляция между значениями! Один из способов, которым мы могли бы подтвердить, что не корреляция — это построить график зависимости средней температуры от средней посещаемости, а не от общей посещаемости:
|
1
2
3
4
5
6
7
8
9
|
g1 = ggplot(aes(x = month, y = aveTemperature, group=1), data = averageTemperatureByMonth) + geom_line( ) + ggtitle("Temperature by month") g2 = ggplot(aes(x = month, y = ave, group=1), data = byMonth) + geom_bar(stat="identity", fill="dark blue") + ggtitle("Attendance by month") grid.arrange(g1,g2, ncol = 1) |
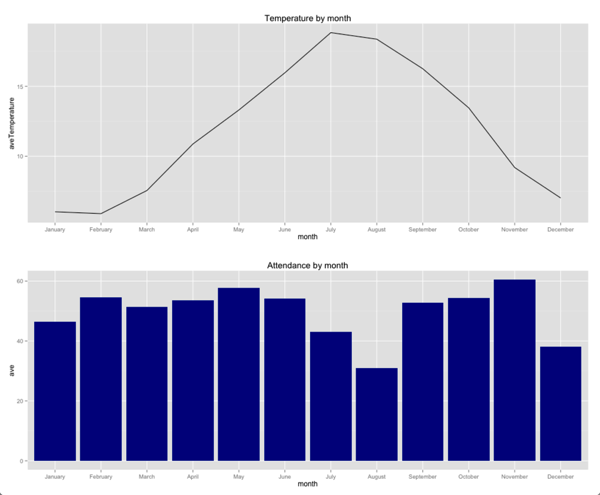
Теперь мы видим, что между температурой и месяцем не так уж много корреляции — фактически 9 месяцев имеют очень похожую среднюю посещаемость. Это только июль, декабрь и особенно август, где есть заметное падение.
Это может означать, что есть и другая переменная, кроме температуры, которая влияет на посещаемость в эти месяцы. Моя гипотеза состоит в том, что мы увидим более низкую посещаемость в течение недель школьных каникул — основные из них происходят в июле / августе, декабре и марте / апреле (что интересно, не показывает провал!)
Еще одна интересная вещь, на которую стоит обратить внимание, заключается в том, что причина снижения посещаемости не в отсутствии воли со стороны посетителей, а в том, что на самом деле нет мероприятий, на которые можно было бы пойти. Давайте построим график количества событий, проводимых каждый месяц, в зависимости от температуры:
|
1
2
3
4
5
6
7
8
9
|
g1 = ggplot(aes(x = month, y = aveTemperature, group=1), data = averageTemperatureByMonth) + geom_line( ) + ggtitle("Temperature by month") g2 = ggplot(aes(x = month, y = events, group=1), data = byMonth) + geom_bar(stat="identity", fill="dark blue") + ggtitle("Events by month") grid.arrange(g1,g2, ncol = 1) |
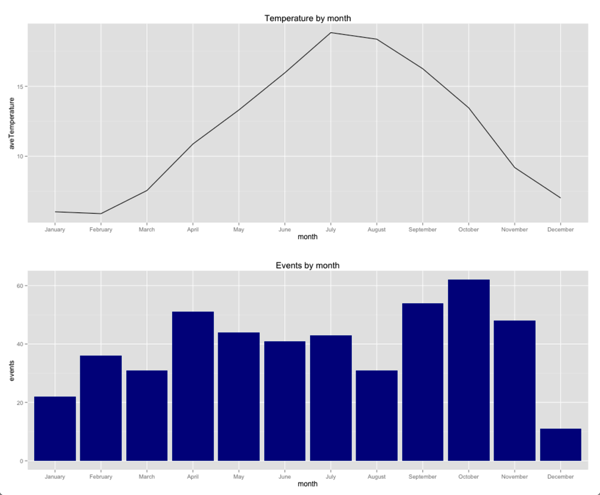
Здесь мы замечаем, что в декабре произошел большой спад — организаторы проводят меньше мероприятий, и мы знаем из нашего более раннего сюжета, что в среднем меньше людей посещают эти мероприятия. Множество событий проводится осенью, немного меньше весной и меньше в январе, марте и августе, в частности.
Опять же, нет никакой конкретной корреляции между температурой и количеством событий, проводимых в определенный день:
|
1
2
|
ggplot(aes(x = events, y = Mean_TemperatureC,group = day), data = merged) + geom_point() |
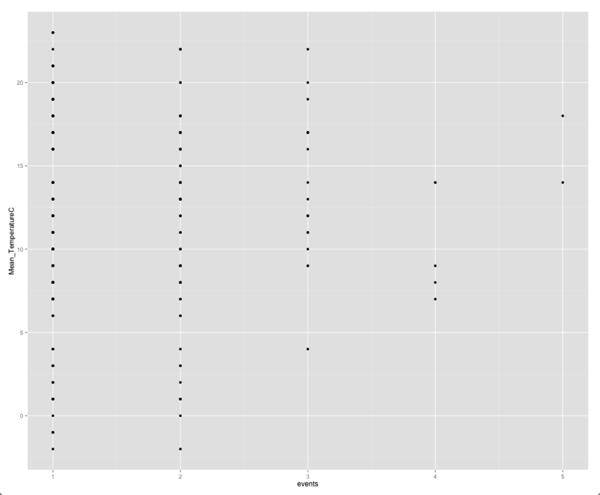
Нет никакой очевидной корреляции при взгляде на этот график, хотя мне трудно интерпретировать графики, где у нас все значения сгруппированы вокруг очень небольшого числа точек (часто факторных переменных) на одной оси и разнесены (непрерывные переменные) на другой. Давайте подтвердим наше подозрение, рассчитав корреляцию между этими двумя переменными:
|
1
2
|
> cor(merged$events, merged$Mean_TemperatureC)[1] 0.0251698 |
Тогда вернемся к чертежной доске для моей модели прогнозирования посещаемости!
Если у вас есть какие-либо предложения по более эффективному анализу или я допустил какие-либо ошибки, пожалуйста, дайте мне знать в комментариях, я все еще учусь, как исследовать, какие данные на самом деле говорят нам.
| Ссылка: | Р.: Погода и посещаемость встреч NoSQL от нашего партнера по JCG Марка Нидхэма в блоге Марка Нидхэма . |