BaDaS = Большой и Данные и Наука
В наши дни BaDaS в моде. И чтобы преуспеть в этом, вам нужен арсенал оружия, чтобы быстро понять огромное количество данных. И все больше и больше, я верю, что питон — это швейцарский армейский нож, используемый в полевых условиях. И если вы читали мой предыдущий блог , я считаю, что iPython Notebook (он же Jupyter) — отличный способ сотрудничать с другими людьми при проведении анализа данных.
Так…
Недавно, когда я анализировал пропускную способность / масштабируемость Kinesis и хотел отобразить график результатов, вместо того, чтобы обратиться к Excel для создания графика, я запустил старый iPython Notebook. (по общему признанию, я был также вдохновлен превосходным блогом @ AustinRochford о байесовском выводе )
Я был просто потрясен. Мне удалось перейти от файла журнала к видимому графику за считанные минуты. Вот как я это сделал …
После пары минут поиска в Google, я понял, что секретный соус был в matplotlib . Точнее, это был Pyplot FTW!
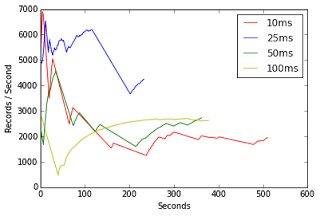
Чтобы приступить к работе, я сначала grep’d файлы журналов для каждого из моих прогонов, и создал файл журнала для каждого. Мне довелось поиграть с RecordBufferSizes в библиотеке Kinesis Producer (KPL), и я провел эксперимент с буфером 10 мс, 25 мс, 50 мс и 100 мс.
Затем я запустил верный ноутбук и начал взламывать.
Сначала я импортировал pyplot:
|
1
|
from matplotlib import pyplot as plt |
Затем я импортировал csv и dateutil для обработки данных…
|
1
2
3
|
import csvimport dateutil |
Наконец, все, что мне нужно было сделать, это написать некоторый Python для анализа каждого файла данных и создать репрезентативный набор данных. Пиплот позаботился обо всем остальном.
В приведенном ниже коде я перебираю каждый CSV-файл и собираю набор данных для этого файла. Набор данных — это словарь данных . Словарь содержит два списка, один для отметок времени, который станет осью y, и один для пропускной способности (aka recordsPerSecond), которая станет осью x.
Первый элемент каждой строки в CSV содержит время эпохи. Но поскольку я хотел график временных рядов, я не хотел использовать абсолютную метку времени. Вместо этого я просто вычисляю дельту по первой отметке времени, которую вижу. (Neato!)
В конце я помещаю каждый из словарей данных в общий словарь, который отображает имя файла в словарь данных, представляющий данные для этого файла.
Последние несколько строк указывают pyplot на график каждого из наборов данных. Там есть вуду, чтобы установить цвет (подсказка: «r» = красный, «y» = желтый и т. Д.)
В конце концов, вы нажимаете «Выполнить» в ячейке, и SHAZAM — это графически.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
%matplotlib inlinefiles = ['10ms.csv', '25ms.csv', '50ms.csv', '100ms.csv']datasets = {}for filename in files: data = { "timestamp": [], "recordsPerSecond": [] } with open(filename, 'rb') as csvfile: reader = csv.reader(csvfile, delimiter=',') starttime = None for row in reader: timestamp = dateutil.parser.parse(row[0]) if (starttime is None): starttime = timestamp delta = (timestamp - starttime).total_seconds() data["timestamp"].append(delta) data["recordsPerSecond"].append(row[1]) datasets[filename] = dataplt.plot( datasets["10ms.csv"]["timestamp"], datasets["10ms.csv"]["recordsPerSecond"], 'r', label='10ms')plt.plot(datasets["25ms.csv"]["timestamp"], datasets["25ms.csv"]["recordsPerSecond"], 'b', label="25ms")plt.plot(datasets["50ms.csv"]["timestamp"], datasets["50ms.csv"]["recordsPerSecond"], 'g', label="50ms")plt.plot(datasets["100ms.csv"]["timestamp"], datasets["100ms.csv"]["recordsPerSecond"], 'y', label="100ms")plt.ylabel('Records / Second')plt.xlabel('Seconds')plt.legend()plt.show<function matplotlib.pyplot.show> |
И FWIW, весь этот пост был написан изнутри Jupyter!
Если я доберусь до этого, я надеюсь опубликовать, каковы были реальные результаты, когда мы играли с размерами буфера с Kinesis. (СОВЕТ: будьте осторожны — размеры буфера определяют объем агрегации, который не только влияет на пропускную способность, но и на стоимость!)
| Ссылка: | BaDaS Arsenal: от grep до графика менее чем за 5 минут с Pyplot от нашего партнера по JCG Брайана ONeill в блоге |