В этом уроке я познакомлю вас с пандами . О, я имею в виду не панда животных, а библиотеку Python!
Как упоминалось на сайте панд :
pandas — это библиотека с открытым исходным кодом, лицензированная BSD, предоставляющая высокопроизводительные, простые в использовании структуры данных и инструменты анализа данных для языка программирования Python.
Таким образом, pandas — это библиотека анализа данных, в которой есть структуры данных, которые нам нужны для очистки необработанных данных в форму, пригодную для анализа (например, таблицы). Здесь важно отметить, что, поскольку pandas выполняет важные задачи, такие как выравнивание данных для сравнения и слияние наборов данных, обработка отсутствующих данных и т. Д., Она стала де-факто библиотекой для обработки данных высокого уровня в Python (т. Е. Статистики ). Ну, pandas изначально был разработан для обработки финансовых данных, при условии, что распространенной альтернативой является использование электронных таблиц (например, Microsoft Excel).
Базовая структура данных pandas называется DataFrame , которая представляет собой упорядоченную коллекцию столбцов с именами и типами, таким образом, она выглядит как таблица базы данных, где одна строка представляет один случай (пример), а столбцы представляют определенные атрибуты. Здесь следует отметить, что элементы в разных столбцах могут быть разных типов.
Итак, суть в том, что библиотека pandas предоставляет нам структуры данных и функции, необходимые для анализа данных.
Установка панд
Давайте теперь посмотрим, как мы можем установить pandas на наши машины и использовать их для анализа данных. Самый простой способ установить pandas и избежать любых проблем с зависимостями — использовать Anaconda, частью которой является pandas . Как уже упоминалось на странице загрузки Anaconda :
Anaconda — это абсолютно бесплатный дистрибутив Python (в том числе для коммерческого использования и распространения). Он включает в себя более 400 самых популярных пакетов Python для науки, математики, инженерии и анализа данных.
Дистрибутив Anaconda является кроссплатформенным, что означает, что он может быть установлен на OS X , Windows и Linux . Я собираюсь использовать установщик OS X, так как я работаю на компьютере Mac OS X El Capitan, но, конечно, вы можете выбрать подходящий установщик для вашей операционной системы. Я пойду с графическим установщиком (будьте осторожны, это 339 МБ).

После загрузки установщика просто пройдитесь по простым шагам мастера установки, и все готово!
Все, что нам нужно сделать сейчас, чтобы использовать pandas это импортировать пакет следующим образом:
|
1
|
import pandas as pd
|
Структуры данных Pandas
Я упомянул одну из трех структур данных pandas выше, DataFrame . Я опишу эту структуру данных в этом разделе в дополнение к другой структуре данных pandas , Series . Существует другая структура данных, называемая Panel , но я не буду описывать ее в этом руководстве, так как она используется не так часто, как упомянуто в документации . DataFrame — это двумерная структура данных, Series — это одномерная структура данных, а Panel — трехмерная и более высокая структура данных.
DataFrame
DataFrame — это DataFrame структура данных, которая состоит из упорядоченных столбцов и строк. Чтобы прояснить ситуацию, давайте рассмотрим пример создания DataFrame (таблицы) из словаря списков . В следующем примере показан словарь, состоящий из двух ключей, Name и Age , и соответствующий им список значений.
|
1
2
3
4
5
6
7
|
import pandas as pd
import numpy as np
name_age = {‘Name’ : [‘Ali’, ‘Bill’, ‘David’, ‘Hany’, ‘Ibtisam’],
‘Age’ : [32, 55, 20, 43, 30]}
data_frame = pd.DataFrame(name_age)
print data_frame
|
Если вы запустите приведенный выше скрипт, вы должны получить вывод, подобный следующему:
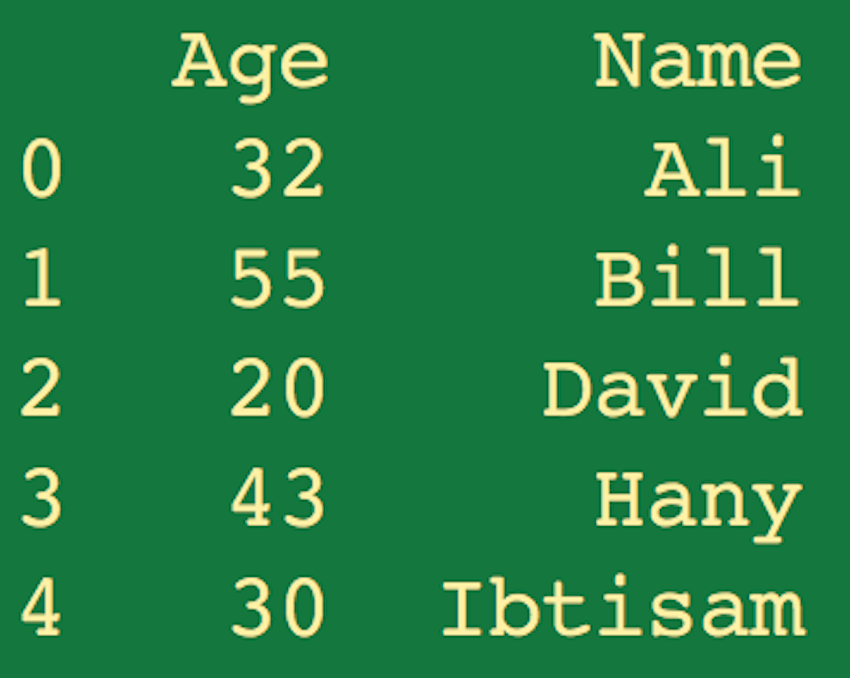
Обратите внимание, что конструктор DataFrame упорядочивает столбцы в алфавитном порядке. Если вы хотите изменить порядок столбцов, вы можете ввести следующее в data_frame выше:
|
1
|
data_frame_2 = pd.DataFrame(name_age, columns = [‘Name’, ‘Age’])
|
Чтобы просмотреть результат, просто введите: print data_frame_2 .
Скажем, вы не хотите использовать метки по умолчанию 0,1,2, … и хотите вместо этого использовать a, b, c, …. В этом случае вы можете использовать index в приведенном выше сценарии следующим образом:
|
1
|
data_frame_2 = pd.DataFrame(name_age, columns = [‘Name’, ‘Age’], index = [‘a’, ‘b’, ‘c’, ‘d’, ‘e’])
|
Это было очень мило, не так ли? Используя DataFrame , мы смогли увидеть наши данные в табличной форме.
Серии
Series — это вторая структура данных pandas о которой я собираюсь рассказать. Series — это одномерный (1D) объект, похожий на столбец в таблице. Если мы хотим создать Series для списка имен, мы можем сделать следующее:
|
1
2
3
|
series = pd.Series([‘Ali’, ‘Bill’, ‘David’, ‘Hany’, ‘Ibtisam’],
index = [1, 2, 3, 4, 5])
print series
|
Вывод этого скрипта будет следующим:

Обратите внимание, что мы использовали index для маркировки данных. В противном случае метки по умолчанию начнутся с 0,1,2 …
Функции панд
В этом разделе я покажу вам примеры некоторых функций, которые мы можем использовать с DataFrame и Series .
Голова и хвост
Функции head() и tail() позволяют нам просматривать образцы наших данных, особенно когда у нас большое количество записей. Количество отображаемых элементов по умолчанию — 5, но вы можете вернуть понравившийся вам номер.
Допустим, у нас есть Series состоящая из 20 000 случайных предметов (чисел):
|
1
2
3
|
import pandas as pd
import numpy as np
series = pd.Series(np.random.randn(20000))
|
Используя методы head() и tail() для наблюдения первого и последнего пяти элементов соответственно, мы можем сделать следующее:
|
1
2
|
print series.head()
print series.tail()
|
Вывод этого скрипта должен быть примерно таким: (обратите внимание, что у вас могут быть разные значения, так как мы генерируем случайные значения):

добавлять
Давайте рассмотрим пример функции add() , где мы попытаемся добавить два фрейма данных следующим образом:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
import pandas as pd
dictionary_1 = {‘A’ : [5, 8, 10, 3, 9],
‘B’ : [6, 1, 4, 8, 7]}
dictionary_2 = {‘A’ : [4, 3, 7, 6, 1],
‘B’ : [9, 10, 10, 1, 2]}
data_frame_1 = pd.DataFrame(dictionary_1)
data_frame_2 = pd.DataFrame(dictionary_2)
data_frame_3 = data_frame_1.add(data_frame_2)
print data_frame_1
print data_frame_2
print data_frame_3
|
Вывод вышеприведенного скрипта:

Вы также можете выполнить этот процесс добавления, просто используя оператор + : data_frame_3 = data_frame_1 + data_frame_2 .
описывать
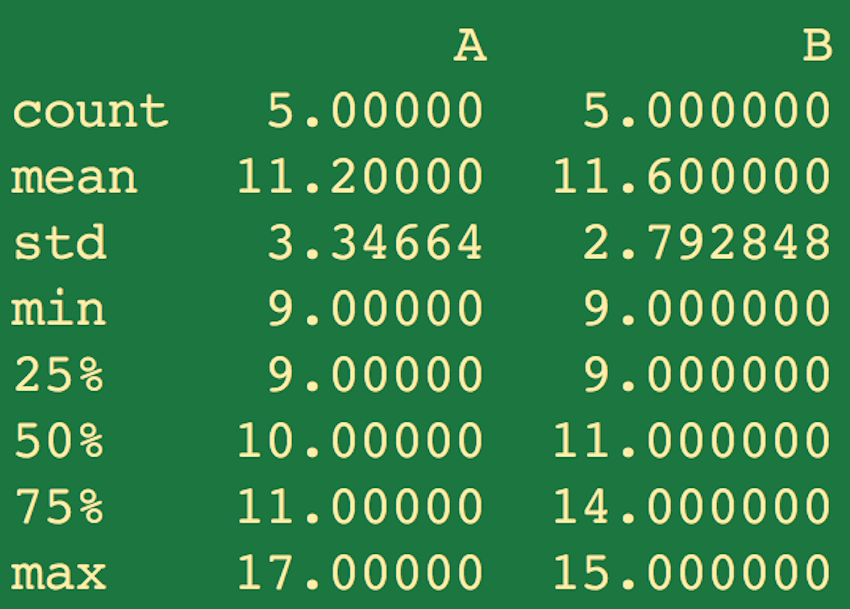
Очень хорошая функция pandas — describe() , которая генерирует различные сводные статистические данные для наших данных. Для примера в последнем разделе давайте сделаем следующее:
|
1
|
print data_frame_3.describe()
|
Результатом этой операции будет:
Дополнительные ресурсы
Это была просто царапина на поверхности pandas Python. Для получения более подробной информации вы можете проверить документацию для pandas , а также некоторые книги, такие как « Изучение панд» и « Освоение панд» .
Вывод
Ученым иногда необходимо выполнить некоторые статистические операции и отобразить некоторые аккуратные графики, которые требуют от них использования языка программирования. Но в то же время они не хотят тратить слишком много времени и не сталкиваются с серьезной кривой обучения при выполнении таких задач.
Как мы увидели в этом руководстве, pandas позволили нам представить данные в виде таблицы и выполнить некоторые операции с этими таблицами очень простым способом. Комбинируя pandas с другими библиотеками Python, ученые могут даже выполнять более сложные задачи, такие как построение специализированных графиков для своих данных.
Таким образом, pandas — это очень полезная библиотека и отправная точка для ученых, экономистов, статистиков и всех, кто желает выполнить некоторые задачи анализа данных.