Этот пост основан на докладе, который я дал на конференции Strata / Hadoop World в Сан-Хосе 31 марта 2016 года. Вы можете найти слайд здесь , а также в блоге dataArtisans здесь .
Непрерывный подсчет
В этом посте мы фокусируемся на кажущейся простой, чрезвычайно распространенной, но на удивление сложной (на самом деле, нерешенной) проблеме на практике: считать в потоках. По сути, у нас есть непрерывный поток событий (например, посещения, клики, метрики, показания датчиков, твиты и т. Д.), И мы хотим разделить поток по некоторому ключу и произвести скользящий подсчет за некоторый период времени (например, посчитать количество посетителей за последний час на страну).
Во-первых, давайте посмотрим, как решить эту проблему, используя классическую пакетную архитектуру, т. Е. Используя инструменты, работающие с конечными наборами данных. На диаграмме ниже представьте, как время течет слева направо. В пакетной архитектуре непрерывный подсчет состоит из этапа непрерывного приема (например, с помощью Apache Flume), который создает периодические файлы (например, в HDFS ). Например, если мы рассчитываем каждый час, мы создаем файл каждый час. Затем на эти файлы планируются периодические пакетные задания (с использованием любого типа пакетного процессора — например, MapReduce или Spark ), возможно, с помощью планировщика, такого как Oozie.
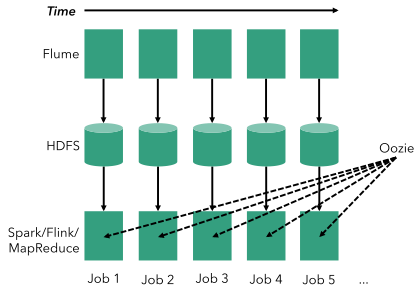
Хотя эту архитектуру можно заставить работать, она также может быть очень хрупкой и страдает от множества проблем:
- Высокая задержка: система основана на пакетной обработке, поэтому не существует простого способа реагировать на события с низкой задержкой (например, получить приблизительный или ранний подсчет заранее).
- Слишком много движущихся частей. Мы использовали три разные системы для подсчета событий во входящих данных. Все это связано с затратами на обучение и администрирование, а также с ошибками во всех различных программах.
- Неявная обработка времени: предположим, что мы хотим считать каждые 30 минут, а не час. Эта логика является частью логики планирования рабочего процесса (а не кода приложения), которая смешивает интересы разработчиков с бизнес-требованиями. Внесение этого изменения будет означать изменение задания Flume, логики Oozie и, возможно, заданий пакетной обработки, в дополнение к изменению характеристик нагрузки в кластере YARN (меньшие, более частые задания).
- Обработка событий не по порядку. Большинство реальных потоков поступают не по порядку, т. Е. В порядке, в котором события происходят в реальном мире (как указано временными метками, прикрепленными к событиям при их создании, например, измеренным временем). смартфоном, когда пользователь входит в приложение) отличается от порядка наблюдения событий в центре обработки данных. Это означает, что событие, которое принадлежит предыдущей почасовой партии, ошибочно подсчитывается в текущей партии. На самом деле нет простого способа решить эту проблему с помощью этой архитектуры; большинство людей предпочитают просто игнорировать существование этой реальности.
- Неясные границы партий: значение «почасовой» в этой архитектуре неоднозначно, так как оно действительно зависит от взаимодействия между различными системами. Почасовые партии в лучшем случае приблизительны, а события на краях партий заканчиваются либо текущей, либо следующей партией с очень небольшими гарантиями. Разделение потока данных на почасовые пакеты на самом деле является самым простым способом разделения времени. Предположим, что мы хотели бы производить агрегаты не для простых почасовых пакетов, а для сеансов активности (например, от входа в систему до выхода из системы или отсутствия активности). Не существует простого способа сделать это с вышеупомянутой архитектурой.
Для решения первой проблемы (высокая задержка) сообщество больших данных (и в частности сообщество Storm) предложило идею архитектуры Lambda, использующей потоковый процессор наряду с пакетной архитектурой для обеспечения ранних результатов. Эта архитектура выглядит следующим образом:

Нижняя часть рисунка — это та же пакетная архитектура, которую мы видели ранее. В дополнение к предыдущим инструментам мы добавили Kafka (для приема в потоковом режиме) и Storm, чтобы обеспечить ранние приблизительные результаты. Хотя это решает проблему задержки, остальная часть проблем остается, и она вводит еще две системы, а также дублирование кода: одну и ту же бизнес-логику необходимо выразить в Storm и пакетном процессоре с двумя очень разными API программирования, представляя два различные кодовые базы для поддержки с двумя различными наборами ошибок. Напомним, что некоторые проблемы с Lambda:
- Слишком много движущихся частей (как раньше и хуже)
- Дублирование кода: одна и та же логика приложения должна быть выражена в двух разных API (пакетный процессор и Storm), что почти наверняка приведет к двум различным наборам ошибок
- Неявная обработка времени (как и прежде)
- Внеочередная обработка событий (как прежде)
- Неясные границы партии (как и раньше)
Элегантным и простым решением всех этих проблем является потоковая архитектура. Там потоковый процессор (в нашем случае Flink, но может быть любым потоковым процессором с определенным набором функций) используется вместе с очередью сообщений (например, Kafka) для обеспечения подсчета:

Используя Flink, такое приложение становится тривиальным. Ниже приведен шаблон кода программы Flink для непрерывного подсчета, который не страдает ни от одной из вышеупомянутых проблем:
|
1
2
3
4
5
|
DataStream<LogEvent> stream = env.addSource(new FlinkKafkaConsumer(...)) // create stream from Kafka.keyBy("country") // group by country.timeWindow(Time.minutes(60)) // window of size 1 hour.apply(new CountPerWindowFunction()); // do operations per window
|
Стоит отметить, что принципиальное различие между потоковым и пакетным подходом заключается в том, что детализация подсчета (здесь 1 час) является частью самого кода приложения, а не частью общей проводки между системами. Мы вернемся к этому позже в этой статье, но сейчас дело в том, что изменение гранулярности от 1 часа до 5 минут требует только тривиального изменения в программе Flink (изменение аргумента оконной функции).
Подсчет иерархии потребностей
Иерархия потребностей Маслоу описывает «пирамиду» потребностей человека по мере того, как они эволюционируют от простых физиологических потребностей до самореализации. Вдохновленный этим (и использованием Мартином Клеппманом одной и той же параболы в контексте управления данными), мы опишем иерархию потребностей для нашего варианта использования подсчета:
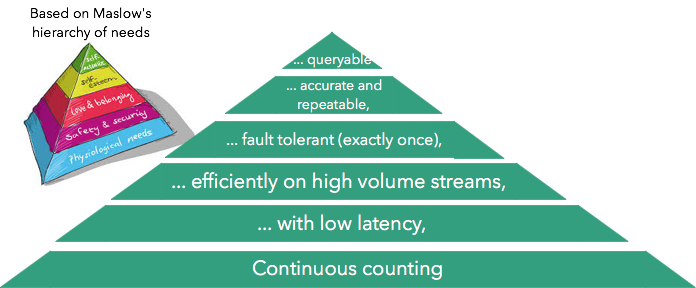
Давайте рассмотрим эти потребности, начиная снизу:
- Непрерывный подсчет относится к способности просто считать непрерывно
- Низкая задержка означает получение результатов с низкой (обычно не более секунды) задержкой
- Эффективность и масштабируемость означают хорошее использование аппаратных ресурсов и масштабирование до больших объемов ввода (обычно миллионы событий в секунду)
- Отказоустойчивость относится к способности правильно завершать вычисления при сбоях
- Точность и повторяемость относится к способности повторять детерминированные результаты
- Способность запрашивать относится к возможности запрашивать счетчики внутри потокового процессора.
Теперь давайте пройдемся по этой иерархии потребностей и посмотрим, как мы можем удовлетворить их, используя современное состояние дел с открытым исходным кодом. Мы уже установили, что потоковая архитектура (и, следовательно, система потоковой обработки) необходима для непрерывного подсчета, поэтому мы будем игнорировать системы пакетной обработки и сосредоточимся на потоковых процессорах. Мы рассмотрим наиболее популярные системы с открытым исходным кодом: Spark Streaming, Storm, Samza и Flink, которые могут рассчитывать непрерывно. Следующая последовательность показывает, как определенные потоковые процессоры исключаются на каждом этапе в пирамиде:
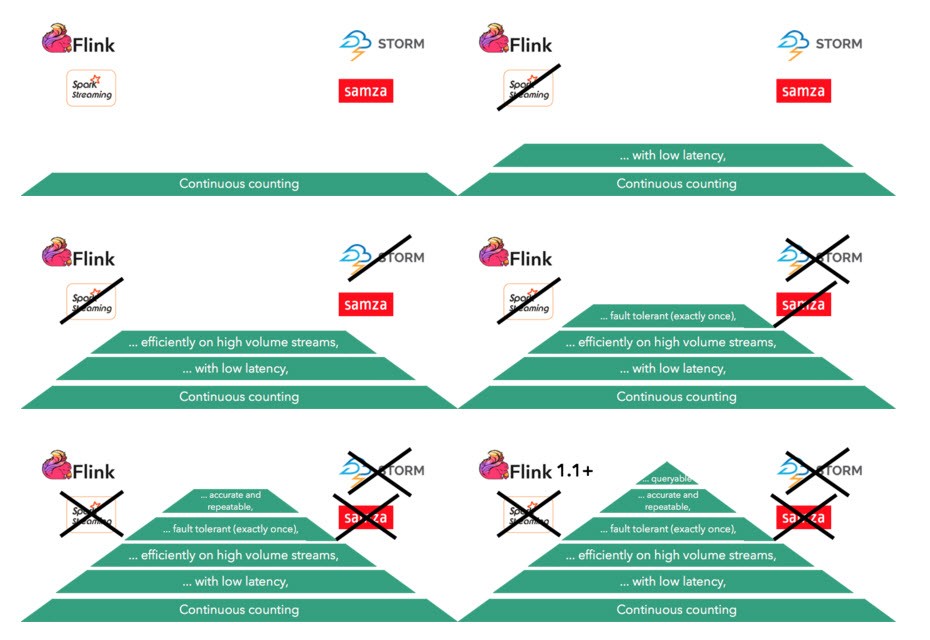
Поднимаясь в пирамиду, мы видим, как более сложные потребности в подсчете устраняют возможность использования определенных потоковых структур. Необходимость в низкой задержке исключает Spark Streaming (благодаря своей архитектуре микропакетирования). Необходимость эффективной обработки потоков очень большого объема исключает шторм. Необходимость предоставления строгих гарантий отказоустойчивости (ровно один раз) устраняет Самза (и Storm), а также необходимость предоставления точных и повторяемых результатов устраняет все структуры, кроме Flink. Конечная потребность — запрос результатов внутри потокового процессора без их экспорта во внешнюю базу данных — пока не удовлетворяется ни одним из потоковых процессоров (включая Flink), но эта функция должна появиться в Flink.
Далее мы детально рассмотрим все эти этапы и посмотрим, как определенные структуры устраняются на каждом этапе.
Задержка
Чтобы измерить задержку потоковых процессоров, команда Storm из Yahoo! опубликовано в декабре прошлого года сообщение в блоге и сравнительный анализ Apache Storm, Apache Spark и Apache Flink. Это был очень важный шаг для пространства, так как это был первый потоковый эталон, смоделированный после реального использования в Yahoo !. На самом деле задача эталонного теста по сути была подсчетом, и это тот случай использования, на котором мы также сосредоточили внимание в этом сообщении в блоге. В частности, работа делает следующее (из оригинального сообщения в блоге):
«Тест является простым рекламным приложением. Существует несколько рекламных кампаний и несколько рекламных объявлений для каждой кампании. Задача теста состоит в том, чтобы читать различные события JSON из Kafka, идентифицировать соответствующие события и сохранять в Redis количество окон соответствующих событий для каждой кампании в Redis. Эти шаги пытаются исследовать некоторые общие операции, выполняемые с потоками данных ».
Результаты, полученные Yahoo! Команда показала, что «Storm 0.10.0, 0.11.0-SNAPSHOT и Flink 0.10.1 показывают задержку в доли секунды при относительно высокой пропускной способности, при этом Storm имеет самую низкую задержку в 99-м процентиле. Spark Streaming 1.5.1 поддерживает высокую пропускную способность, но с относительно более высокой задержкой ». Это показано на диаграмме ниже:
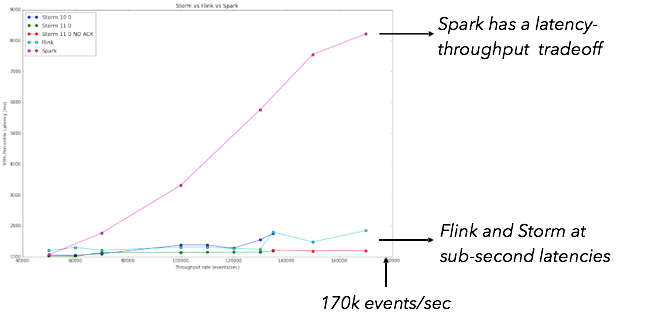
По сути, при использовании Spark Streaming существует компромисс между пропускной способностью и задержкой, тогда как Storm и Flink не показывают такой компромисс.
Эффективность и масштабируемость
В то время как Yahoo! Бенчмарк был отличной отправной точкой при сравнении производительности потоковых процессоров, он был ограничен в двух измерениях:
- Тест остановился на очень низкой пропускной способности (170 000 событий в секунду в совокупности).
- Все задания в тесте (для Storm, Spark и Flink) не были отказоустойчивыми.
Зная, что Flink может достичь гораздо более высокой пропускной способности , мы решили расширить эталонный тест следующим образом:
- Мы повторно внедрили задание Flink, чтобы использовать собственный механизм окон Flink, чтобы он предоставлял гарантии единовременно (задание Flink в исходном тесте Yahoo! не использовало исходное состояние Flink, а было смоделировано после задания Storm).
- Мы попытались увеличить пропускную способность, повторно внедрив генератор данных, чтобы ускорить откачку событий.
- Мы сосредоточились на Flink и Storm, так как это были единственные платформы, которые могли обеспечить приемлемую задержку в исходном тесте.
Используя тот же кластер (такое же количество машин, но более быстрое соединение), что и исходный тест, мы получили следующие результаты:
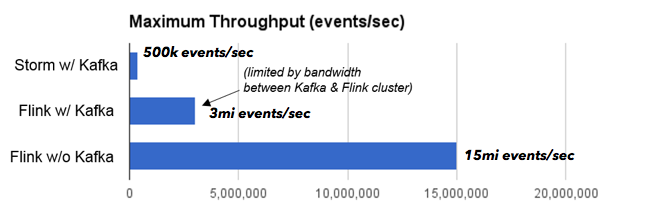
Нам удалось масштабировать Storm до более высокой пропускной способности (0,5 миллиона событий в секунду), чем исходный тест, благодаря более быстрому межсоединению. Flink при той же настройке масштабируется до 3 миллионов событий в секунду. Задание Storm было узким местом на процессоре, а задание Flink было узким местом на пропускной способности сети между компьютерами, на которых работает Kafka, и машинами, на которых работает Flink. Чтобы устранить это узкое место (которое не имело ничего общего с Kafka, а было просто доступной настройкой кластера), мы поместили генератор данных в кластер Flink. В этом случае Flink может масштабироваться до 15 миллионов событий в секунду.
Несмотря на то, что может быть возможно масштабировать Storm до больших объемов с использованием большего количества машин, стоит отметить, что эффективность (эффективное использование оборудования) так же важна, как масштабируемость , особенно когда аппаратный бюджет ограничен.
Отказоустойчивость и повторяемость
Говоря о отказоустойчивости, часто используются следующие термины:
- По крайней мере, один раз: это означает, что в нашем примере подсчета возможен перерасчет после сбоев
- Точно один раз: это означает, что количество совпадений с ошибками или без
- Конец в конец ровно один раз: это означает, что счетчики, опубликованные во внешнем приемнике, будут одинаковыми с ошибками или без них
Flink гарантирует ровно один раз с выбранными источниками (например, Kafka), и конец и конец ровно один раз для выбранных источников и приемников (например, Kafka → Flink → HDFS с появлением новых). Единственные рамки из рассмотренных в этом посте, которые гарантируют ровно один раз, — это Flink и Spark.
Не менее важно для предотвращения сбоев поддерживать эксплуатационные потребности для развертывания приложений в производстве и обеспечения их повторяемости. Flink внутренне обеспечивает отказоустойчивость благодаря механизму, называемому контрольными точками , по сути, периодически делая последовательный снимок вычислений, не останавливая вычислений. Недавно мы представили функцию, называемую точками сохранения, которая, по сути, делает этот механизм контрольных точек доступным непосредственно для пользователя. Точки сохранения — это контрольные точки Flink, которые запускаются пользователем извне, надежны и не имеют срока действия. Точки сохранения позволяют «создавать версии» приложений, делая последовательные снимки состояния в четко определенные моменты времени, а затем повторно запускать приложение (или другую версию кода приложения с этого момента времени). На практике точки сохранения важны для производственного использования, позволяя легко отлаживать, обновлять код (будь то приложение или сам Flink), моделирование «что если» и A / B-тестирование. Вы можете прочитать больше о точках сохранения здесь .
Явная обработка времени
Помимо возможности воспроизведения потокового приложения с четко определенного момента времени, повторяемость при обработке потока требует поддержки того, что называется временем события. Простой способ объяснить время события — это серия «Звездные войны»: время в самих фильмах (когда события произошли) называется временем события, тогда как время выхода фильмов в кинотеатрах называется временем обработки:
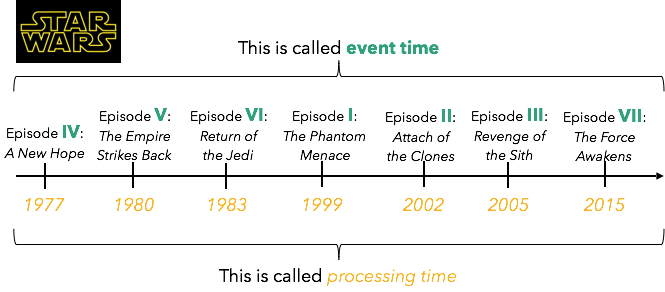
В контексте обработки потока время события измеряется временными метками, встроенными в сами записи, тогда как время, измеренное машинами, которые выполняют вычисления (когда мы видим записи), называется временем обработки. Поток выходит из строя, когда порядок времени события не совпадает с порядком времени обработки (например, серия «Звездные войны»).
Поддержка времени события важна во многих параметрах, включая предоставление правильных результатов в потоках не по порядку и обеспечение согласованных результатов при воспроизведении вычислений (например, в сценарии перемещения во времени, как мы видели ранее). Короче говоря, поддержка времени события делает вычисление повторяемым и детерминированным, поскольку результаты не зависят от времени дня, когда выполняется вычисление.
Из всех структур, рассмотренных в этом посте, только Flink поддерживает время события (в то время как другие создают частичную поддержку прямо сейчас).
Запрашиваемое состояние и что происходит в Flink
На вершине иерархической пирамиды была возможность запрашивать счетчики в потоковом процессоре. Мотивация этой функциональности заключается в следующем: мы увидели, что Flink может поддерживать очень высокую пропускную способность при подсчете и связанных приложениях. Однако эти подсчеты необходимо каким-то образом представить внешнему миру, т. Е. Нам нужна возможность запрашивать в реальном времени значение конкретного счетчика. Типичный способ сделать это — экспортировать счетчики в базу данных или хранилище значений ключей и запросить их там. Однако это может стать узким местом конвейера обработки. Поскольку Flink хранит эти значения уже во внутреннем состоянии, почему бы не запросить эти значения непосредственно во Flink? Это возможно прямо сейчас, используя пользовательский оператор Flink (см. Обработку потока с сохранением состояния Jamie Grier со скоростью в памяти ), но изначально не поддерживается. Мы работаем над тем, чтобы внедрить эту функциональность в Flink.
Несколько других функций, над которыми мы активно работаем:
- SQL на Flink для статических наборов данных и потоков данных с использованием Apache Calcite
- Динамическое масштабирование программ Flink: это дает пользователю возможность регулировать параллельность программы Flink во время ее работы
- Поддержка Apache Mesos
- Больше потоковых источников и приемников (например, Amazon Kinesis и Apache Cassandra )
закрытие
Мы увидели, что даже кажущиеся простыми случаи использования потоковой передачи (подсчета) имеют большую «глубину», когда речь идет о производительности и производственном использовании. Основываясь на «иерархии потребностей», мы увидели, как Flink обладает уникальной комбинацией функций и производительности в пространстве с открытым исходным кодом для эффективной поддержки этих вариантов использования на практике. ![]()
| Ссылка: | Подсчет в потоках: иерархия потребностей от нашего партнера JCG Чейза Хули в блоге Mapr . |