Задумывались ли вы о быстром способе рассказать, на чем сосредоточен какой-то документ? Какова его основная тема? Позвольте мне дать вам этот простой трюк. Перечислите уникальные слова, упомянутые в документе, а затем проверьте, сколько раз было упомянуто каждое слово (частота). Этот способ даст вам представление о том, о чем документ в основном. Но это не будет легко работать вручную, поэтому нам нужен какой-то автоматизированный процесс, не так ли?
Да, автоматизированный процесс сделает это намного проще. Давайте посмотрим, как мы можем перечислить различные уникальные слова в текстовом файле и проверить частоту каждого слова с помощью Python.
Тестовый файл
В этом уроке мы будем использовать test.txt в качестве нашего тестового файла. Идите и скачайте, но не открывайте! Давайте сделаем маленькую игру. Текст в этом тестовом файле взят из одного из моих руководств в Envato Tuts +. Основываясь на частоте слов, давайте догадаемся, из какого из моих руководств этот текст был извлечен.
Пусть игра начнется!
Регулярные выражения
Поскольку мы собираемся применить шаблон в нашей игре, нам нужно использовать регулярные выражения (регулярные выражения). Если «регулярные выражения» — это новый термин для вас, это хорошее определение из Википедии:
Последовательность символов, определяющих шаблон поиска, в основном для использования при сопоставлении с шаблоном или при сопоставлении строк, т. Е. Операции типа «найти и заменить». Эта концепция возникла в 1950-х годах, когда американский математик Стивен Клин формализовал описание обычного языка и стал широко использоваться в утилитах обработки текста Unix ed, редакторе и grep, фильтре.
Если вы хотите узнать больше о регулярных выражениях, прежде чем продолжить работу с этим учебником, вы можете посмотреть мой другой учебник Регулярные выражения в Python и вернуться снова, чтобы продолжить этот учебник.
Построение Программы
Давайте работать шаг за шагом над созданием этой игры. Первое, что мы хотим сделать, это сохранить текстовый файл в строковой переменной.
|
1
2
|
document_text = open(‘test.txt’, ‘r’)
text_string = document_text.read()
|
Теперь, чтобы упростить применение нашего регулярного выражения, давайте превратим все буквы в нашем документе в строчные буквы, используя функцию lower () , следующим образом:
|
1
|
text_string = document_text.read().lower()
|
Давайте напишем наше регулярное выражение, которое будет возвращать все слова с количеством символов в диапазоне [3-15] . Начиная с 3 мы избегаем слов, которые могут не заинтересовать нас в подсчете их частоты, например, если , в , и т. Д., И слова, длина которых превышает 15 могут быть неверными. Регулярное выражение для такого шаблона выглядит следующим образом:
|
1
|
\b[az]{3,15}\b
|
\b относится к границе слова . Для получения дополнительной информации о границе слова, вы можете проверить этот учебник .
Приведенное выше регулярное выражение можно записать следующим образом:
|
1
|
match_pattern = re.search(r’\b[az]{3,15}\b’, text_string)
|
Поскольку мы хотим просмотреть несколько слов в документе, мы можем использовать функцию findall :
Возвратите все неперекрывающиеся совпадения шаблона в строке в виде списка строк. Строка сканируется слева направо, и совпадения возвращаются в указанном порядке. Если в шаблоне присутствует одна или несколько групп, вернуть список групп; это будет список кортежей, если шаблон имеет более одной группы. Пустые совпадения включаются в результат, если они не касаются начала другого совпадения.
На этом этапе мы хотим найти частоту каждого слова в документе. Подходящей концепцией для использования здесь являются словари Python , поскольку нам нужны пары key-value , где key — это слово , а value представляет собой частоту слов, появившихся в документе.
Предполагая, что мы объявили пустой словарь frequency = { } , вышеприведенный абзац будет выглядеть следующим образом:
|
1
2
3
|
for word in match_pattern:
count = frequency.get(word,0)
frequency[word] = count + 1
|
Теперь мы можем увидеть наши ключи, используя:
|
1
|
frequency_list = frequency.keys()
|
Наконец, чтобы получить слово и его частоту (сколько раз оно появилось в текстовом файле), мы можем сделать следующее:
|
1
2
|
for words in frequency_list:
print words, frequency[words]
|
Давайте соберем программу в следующем разделе и посмотрим, как выглядит результат.
Собираем все вместе
Обсудив программу шаг за шагом, давайте теперь посмотрим, как выглядит программа:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
import re
import string
frequency = {}
document_text = open(‘test.txt’, ‘r’)
text_string = document_text.read().lower()
match_pattern = re.findall(r’\b[az]{3,15}\b’, text_string)
for word in match_pattern:
count = frequency.get(word,0)
frequency[word] = count + 1
frequency_list = frequency.keys()
for words in frequency_list:
print words, frequency[words]
|
Если вы запустите программу, вы должны получить что-то вроде следующего:
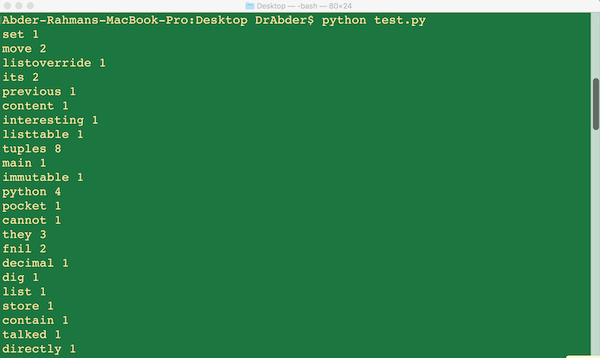
Вернемся к нашей игре. Говоря о частотах слов, как вы думаете, о чем говорил тестовый файл (с содержанием из моего другого учебника по Python)?
(Подсказка: проверьте слово с максимальной частотой).