Для новичков в Кассандре, вся терминология может сначала быть немного подавляющей. Если у вас есть опыт работы с реляционными базами данных, некоторые понятия, такие как «строка» или «первичный ключ», будут вам знакомы. Но другие термины, которые кажутся простыми, часто могут немного сбивать с толку, особенно в сочетании с некоторыми визуальными эффектами, которые вы видите, узнавая о Кассандре.
Например, взгляните на этот снимок экрана с помощью инструмента управления DataStax OpsCenter :
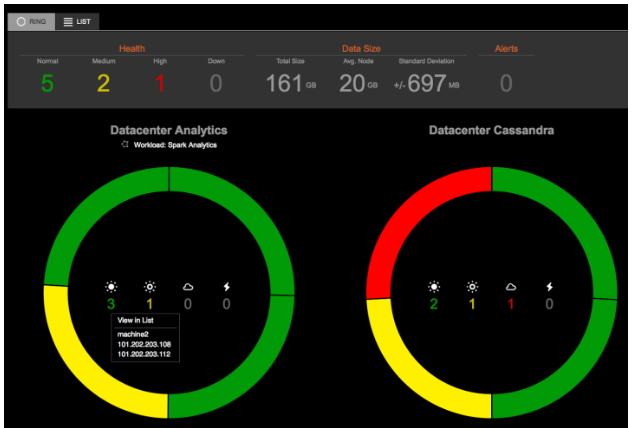
Теперь ответьте на эти вопросы:
- Сколько жетонов есть?
- Сколько кластеров там?
- Сколько центров обработки данных там?
Как насчет этого слайда, который я использую при представлении новых пользователей в Cassandra:
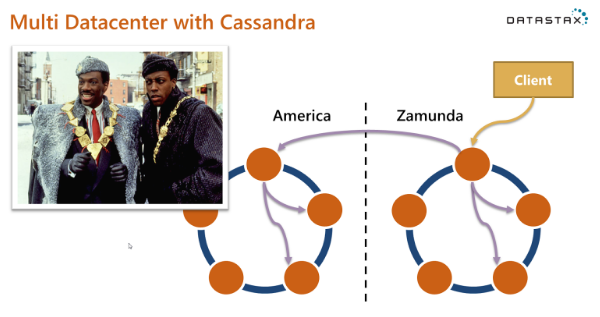
Если вам интересно, да, ваши данные на этой диаграмме «прибывают в Америку» (каламбур полностью предназначен). Теперь ответьте на те же вопросы:
- Сколько жетонов есть?
- Сколько кластеров там?
- Сколько центров обработки данных там?
Вы ответили два на все вопросы на обеих картинках? Если бы ты это сделал, ты бы не был одинок, но ты тоже не был бы прав. Это один пример, когда терминология может немного запутаться. Давайте пройдемся по этим терминам, начиная с последнего и продвигаясь назад.
Datacenters
Это термин, с которым большинство людей знакомо до того, как начать с Кассандры, и если вы ответили два на вопрос выше, то вы не только правы, но и хорошо понимаете эту концепцию. В компьютерном мире мы склонны думать о центре обработки данных как о физическом месте, где находятся наши компьютеры. То же самое может быть верно для центра обработки данных в Кассандре, но это не обязательно должно быть правдой.
В Кассандре центр обработки данных — это просто логическая группа узлов. Эта группировка может основываться на физическом местоположении ваших узлов. Например, у нас может быть центр обработки данных «США-Восток» и «США-Запад». Но это также может быть основано на чем-то, кроме физического местоположения. Например, мы могли бы установить «транзакционный» и «аналитический» центр обработки данных для запуска различных типов рабочих нагрузок, но узлы для этих центров обработки данных могли бы физически находиться в одном и том же месте.
Так как же Кассандре узнать, какие узлы принадлежат какому центру обработки данных? Ну, это немного выходит за рамки этого поста, но короткий ответ — это компонент в Кассандре, называемый Снитч. Если вы хотите больше узнать, есть отличное объяснение Snitch в DataStax Academy.
В большинстве случаев, когда мы смотрим на визуальные изображения Cassandra, как в OpsCenter или на моем слайде выше, узлы отображаются сгруппированными по центрам обработки данных.
Кластеры
Если вы ответили два на этот вопрос, я не виню вас. В конце концов, на английском языке кластер определяется как «группа вещей или людей, которые находятся близко друг к другу», и на обоих этих рисунках, похоже, есть две отдельные группы узлов, которые находятся близко друг к другу. Но, как мы только что установили, большую часть времени, когда мы видим такие изображения, мы видим узлы, сгруппированные по датацентру.
В Cassandra кластер относится ко всем узлам во всех центрах обработки данных, которые являются одноранговыми (то есть осведомлены друг о друге). Для обоих этих изображений у нас есть два центра обработки данных, в которых происходит репликация между ними. Таким образом, хотя есть два центра обработки данных, на обоих этих изображениях изображен только один кластер.
Token Rings
Это оставляет нас с вопросом о количестве жетонов. Я пытался быть конкретным, спрашивая о кольцах токенов, а не просто кольцах. Часто в Кассандре термин «кольцо» (сам по себе) используется взаимозаменяемо с «кластером» для обозначения всех узлов во всех центрах обработки данных. Но когда мы говорим Token Ring, мы обычно имеем в виду конкретную концепцию в Cassandra — распределение данных.
Если вы работали с Cassandra, то теперь вы знаете, что при создании таблицы вы выбираете первичный ключ. Часть этого первичного ключа (обычно первый столбец или иногда первая группа столбцов) называется ключом раздела. Например, взгляните на таблицу пользователей из KillrVideo :
|
1
2
3
4
5
6
7
8
|
CREATE TABLE users ( userid uuid, firstname text, lastname text, email text, created_date timestamp, PRIMARY KEY (userid)); |
Здесь ключом раздела является столбец идентификатора пользователя. Когда мы вставляем данные в эту таблицу, значение для идентификатора пользователя используется для определения того, какие узлы в Cassandra будут на самом деле хранить данные. Выбор первичного ключа важен (как выделено в недавнем сообщении в блоге ), но какое это имеет отношение к кольцам токенов?
Хорошо, когда Cassandra хочет знать, где разместить данные, она берет значение ключа разделения и запускает его через согласованную функцию хеширования . Хэш, который получается из этой последовательной функции хеширования, иногда называют токеном. А в Cassandra узлы в вашем кластере имеют диапазоны (или сегменты) всех возможных токенов.
Например, давайте представим, что у нас есть функция хеширования, которая выводит токены от 0 до 99. Распределение этих токенов по всем узлам в кластере из восьми узлов может выглядеть примерно так:
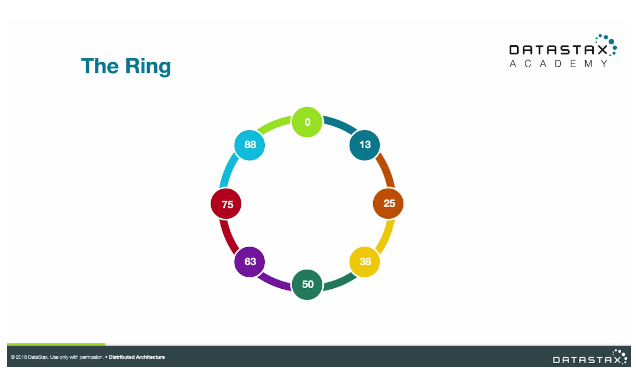
Теперь это действительно упрощенный пример из-за небольшого диапазона доступных токенов. В реальных развертываниях Cassandra большинство людей используют стандартный разделитель Murmur3, который выводит токены в диапазоне от -2 63 до 2 63 — 1, но даже при большем доступном диапазоне принцип тот же.
Общий диапазон доступных токенов и их распределение вокруг кластера часто называют кольцом токенов в Кассандре. И этот диапазон токенов распределен по кластеру, причем каждый узел владеет частью кольца токенов. Таким образом, даже если бы мы взяли наш кластер из 8 узлов выше и логически сгруппировали узлы в двух центрах обработки данных, все равно был бы только один токен-кольцо.
Это может быть очень трудно, чтобы обернуть ваш мозг, особенно когда вы видите картины, как две выше. На этих рисунках определенно есть два «кольца» в английском смысле этого слова. Но в терминах Cassandra есть только одно кольцо токенов (и только одно «кольцо», если мы используем этот термин взаимозаменяемо с «кластером»), даже если узлы сгруппированы и отображаются как два центра данных.
Вывод
Если вы боретесь с какой-то терминологией, когда начинаете работать с Cassandra, надеюсь, это поможет кое-что прояснить. Я настоятельно рекомендую ознакомиться с DS201: Основы Apache Cassandra в DataStax Academy, чтобы глубже погрузиться во многие из этих концепций. Такие вещи, как репликация (и стратегии репликации), все основаны на этом фундаменте, поэтому понимание этих концепций может иметь большое значение для становления гуру Кассандры.
| Ссылка: | Одно (жетонное) кольцо, чтобы управлять ими Все от нашего партнера JCG Люка Тиллмана в блоге Planet Cassandra . |