Патрик Макфадин, главный евангелист Apache Cassandra, DataStax 
Патрик считается одним из ведущих экспертов Apache Cassandra и методов моделирования данных. Будучи главным евангелистом Apache Cassandra и консультантом по DataStax, он помог построить некоторые из крупнейших в мире развертываний. До работы в DataStax он был главным архитектором в Hobsons, компании, предоставляющей образовательные услуги. Там он часто говорил о дизайне и производительности веб-приложений.
Название этой статьи действительно может стоять в одиночестве, но я не собираюсь на этом останавливаться! Да, это фундаментальное правило для Apache Cassandra, но я собираюсь занять некоторое время, чтобы объяснить, почему это утверждение верно. При моделировании реляционных данных вы можете начать с первичного ключа, но эффективные модели данных в СУБД гораздо больше касаются отношений внешнего ключа и реляционных ограничений между таблицами. Поскольку использование JOIN невозможно с Cassandra, нам гораздо проще создавать модели данных. Сложность компромисса для Apache Cassandra заключается в предварительном знании ваших запросов и схем доступа к данным. Я не буду вдаваться в то, как это сделать здесь. В Академии DataStax есть отличный курс по этой теме. Эта статья будет посвящена тому, как и почему лучше всего выбрать первичный ключ.
Основной первичный ключ
Давайте начнем с самой основной таблицы. Их можно назвать «Статическая таблица» или «Таблица сущностей», которые используются для хранения одной записи данных. Вот пример из примера приложения KillrVideo :
|
01
02
03
04
05
06
07
08
09
10
11
12
|
CREATE TABLE videos (
videoid uuid,
userid uuid, name varchar,
description varchar, location text,
location_type int, preview_thumbnails map<text,text>,
tags set<varchar>,
added_date timestamp,
PRIMARY KEY (videoid)
); |
ПЕРВИЧНЫЙ КЛЮЧ обозначение является самой простой формой. Единственный параметр, который идентифицирует одно видео, загруженное в нашу систему. Первый элемент в нашем ПЕРВИЧНОМ КЛЮЧЕ — это то, что мы называем ключом раздела. Ключ раздела имеет специальное применение в Apache Cassandra, помимо того, что он показывает уникальность записи в базе данных. Другая цель, которая очень важна в распределенных системах, это определение локальности данных.
Когда данные вставляются в кластер, первым шагом является применение хеш-функции к ключу раздела. Выходные данные используются для определения того, какой узел (и реплики) будут получать данные. Алгоритм, используемый Apache Cassandra, использует Murmur3, который принимает произвольный вход и создает непротиворечивое значение токена. Это значение токена будет в пределах диапазона токенов, принадлежащих одному узлу.
Проще говоря, ключ раздела всегда будет принадлежать одному узлу, и данные этого раздела всегда будут находиться на этом узле.
Почему это важно? Если бы не было абсолютного местоположения данных раздела, то это потребовало бы поиска ваших данных в каждом узле кластера. В небольшом кластере это может завершиться быстро, но в гораздо большем кластере это будет мучительно медленно. Мы хотим то, что показано ниже.

Сложный первичный ключ
Другой тип таблиц в Apache Cassandra — это то, что мы будем называть «Динамическая таблица». Давайте сначала посмотрим на другой пример из KillrVideo:
|
1
2
3
4
5
6
7
8
|
CREATE TABLE user_videos ( userid uuid, added_date timestamp, videoid uuid, name text, preview_image_location text, PRIMARY KEY (userid, added_date, videoid)); |
В этой таблице мы выполняем запрос «показать мне все видео, связанные с конкретным пользователем». Как видите, у PRIMARY KEY теперь больше, чем у ключа секционирования, теперь мы добавили больше элементов. Все столбцы, перечисленные после ключа раздела, называются столбцами кластеризации. Вот где мы делаем огромный перерыв в реляционных базах данных. Если ключ раздела важен для локальности данных, столбец кластеризации определяет порядок расположения данных внутри раздела. То, как мы читаем это слева направо:
- Первый пункт — это ключ раздела
- Второй пункт — первый столбец кластеризации. Added_date является меткой времени, поэтому порядок сортировки является хронологическим, по возрастанию.
- Третий пункт — это второй столбец кластеризации. Поскольку видеоид является UUID, мы включаем его, поэтому просто показываем, что он является частью уникальной записи.
После вставки данных вы должны ожидать, что ваш SELECT вернет данные в порядке возрастания добавленной даты для одного раздела в порядке возрастания.
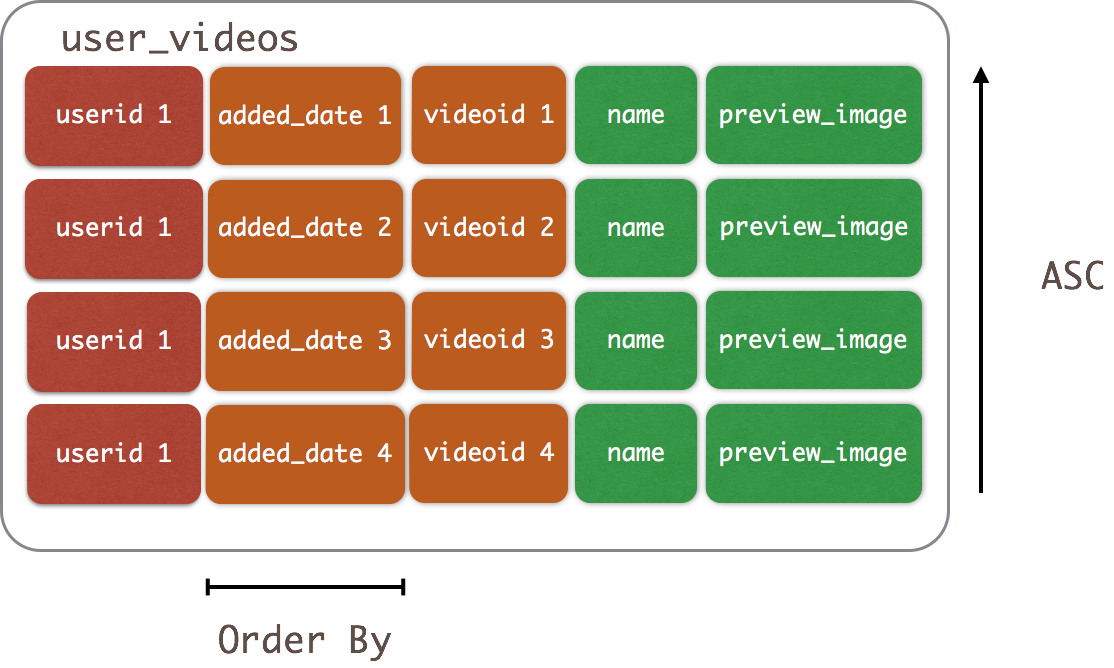
Управление порядком кластеризации столбцов
Поскольку столбцы кластеризации задают порядок в одном разделе, было бы полезно контролировать направленность сортировки. Мы могли бы достичь этого во время выполнения, добавив предложение ORDER BY в наш SELECT следующим образом:
|
1
2
3
4
|
SELECT *FROM user_videosWHERE userid = 522b1fe2-2e36-4cef-a667-cd4237d08b89ORDER BY added_date DESC; |
Что если мы хотим управлять порядком сортировки по умолчанию для модели данных? Мы можем указать это во время создания таблицы, используя предложение CLUSTERING ORDER BY :
|
1
2
3
4
5
6
7
8
|
CREATE TABLE user_videos ( userid uuid, added_date timestamp, videoid uuid, name text, preview_image_location text, PRIMARY KEY (userid, added_date, videoid)) WITH CLUSTERING ORDER BY (added_date DESC, videoid ASC); |
Теперь, когда мы вставляем данные в user_videos, данные будут предварительно отсортированы в add_date в порядке убывания.
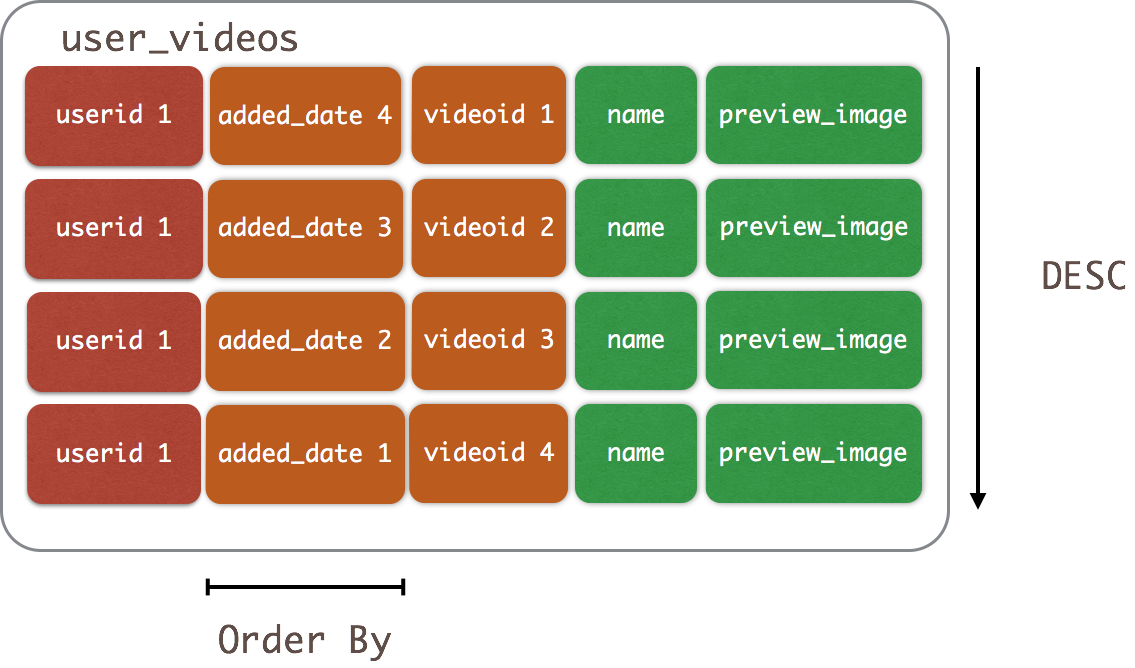
Это может показаться предварительной оптимизацией, но варианты использования, которые дает это дополнение, очень привлекательны. Когда CLUSTERING ORDER BY используется в моделях данных временных рядов, мы можем быстро получить доступ к последним N вставленным элементам. Например:
|
1
2
3
4
|
SELECT *FROM user_videosWHERE userid = 522b1fe2-2e36-4cef-a667-cd4237d08b89LIMIT 10; |
Этот запрос запрашивает «последние 10 видео, загруженных пользователем». Очень быстрый, полезный и эффективный запрос, включаемый простым добавлением предложения CLUSTERING ORDER BY . Вы можете увидеть, как это может быть очень полезно в случаях взаимодействия с пользователем или случаев мошенничества.
Вывод
В этом кратком обзоре отношений PRIMARY KEY , я надеюсь, вы увидите, насколько это важно не только для ваших запросов, но и как вы храните свои данные. Некоторое базовое понимание компонентов может помочь вам сделать осознанный выбор в вашей следующей модели данных. Например, теперь, когда вы понимаете, что ключ раздела управляет локальностью данных, вероятно, лучше не использовать только один! Экстремальный пример, но тот, который вы могли бы легко сделать, не зная причины этого. Теперь, когда вы знаете самое важное, что нужно знать в моделировании данных Cassandra, что вы собираетесь с ним делать? Создайте что-нибудь потрясающее!
| Ссылка: | Самая важная вещь, которую нужно знать при моделировании данных Cassandra: первичный ключ от нашего партнера по JCG Патрика Макфадина из блога Planet Cassandra . |