1. Введение в репликацию MySQL
В крупномасштабной корпоративной системе согласованность данных и резервное копирование имеют первостепенное значение. Не менее важно распределить нагрузку на сервер базы данных, используя копии базы данных. Однако поддержка резервного копирования или дополнительных экземпляров является сложной задачей, особенно если вы пытаетесь повторно копировать всю базу данных. Репликация MySQL помогает нам точно решить эту проблему, постепенно создавая копию базы данных master в настроенные подчиненные базы данных. Репликация MySQL может использоваться для последовательного копирования основной базы данных в несколько ведомых баз данных.
Эта конфигурация имеет несколько преимуществ, таких как:
- Подчиненная база данных постепенно обновляется, что снижает нагрузку на основную базу данных для создания копии.
- Реплика базы данных может использоваться для тяжелых внутренних операций. Это позволяет достаточно хорошо поддерживать производительность и время отклика основной базы данных.
- Подчиненная база данных может использоваться для более быстрой доставки данных в разные регионы мира.
Содержание
- 1. Введение в MySQL Replication
- 2. Настройка серверов MySQL
- 3. Топологии репликации MySQL
- 4. Настройка серверов для репликации MySQL
- 5. Включение репликации Master-Slave
- 5.1 Настройка мастера
- 5.2 Конфигурация подчиненной базы данных
- 6. Источник данных от нескольких рабов
- 7. Настройка нескольких ведомых для базы данных с одним главным
- 8. Плюсы и минусы репликации
- 9. Вывод
2. Настройка серверов MySQL
Чтобы настроить репликацию MySQL, вам потребуется настроить как минимум два отдельных сервера. Они могут существовать на одной и той же машине, но с разными портами, или могут быть на разных машинах. В этом руководстве мы будем использовать две разные машины с простой установкой MySQL через порт 3306. Также возможно использовать одну и ту же машину с несколькими экземплярами сервера, работающими на одной машине. Однако процесс настройки нескольких экземпляров может показаться сложным и, следовательно, здесь не обсуждается. Вы можете изучить вариант по этой ссылке
IP-адреса, которые я бы использовал для машин, перечислены ниже:
- Мастер: 192.168.1.25
- Раб: 192.168.1.26
IP-адреса, перечисленные выше, являются IP-адресами моего локального устройства. В случае удаленных серверов MySQL вы можете использовать соответствующий публичный IP-адрес. Чтобы настроить сервер, следуйте инструкциям из моего предыдущего урока. После установки сервера на обеих машинах мы можем приступить к пониманию и настройке репликации базы данных MySQL.
3. Топологии репликации MySQL
Прежде чем продолжить процесс репликации, очень важно понять репликацию MySQL в деталях. Существует несколько типов конфигураций репликации MySQL. Независимо от используемой конфигурации основная цель репликации остается неизменной — снизить нагрузку на главный сервер во время интенсивных операций с базами данных, выполняемых в бэкэнде. Общим для каждой конфигурации является то, что база данных, настроенная для работы в качестве подчиненного, всегда является базой данных только для чтения для внешних пользователей, подключающихся к базе данных. По умолчанию репликация является асинхронным процессом, если не указано иное. В приведенных ниже топологиях одна из топологий включает синхронное копирование данных. Это обеспечивает лучшую согласованность данных, но увеличивает нагрузку на основные данные, так как необходимо дождаться создания копии.
Давайте подробно обсудим типы конфигураций репликации MySQL:
3.1 Мастер с конфигурацией ведомых
В конфигурации «ведущий с ведомыми» данные однонаправленно передаются от главного к нескольким ведомым и завершаются там. В такой конфигурации существует один главный сервер базы данных, настроенный для работы в качестве главного и обслуживания приложения, в то время как несколько резервных / подчиненных серверов выполняют операции с интенсивным использованием данных. Типичное изображение такой реализации показано ниже.
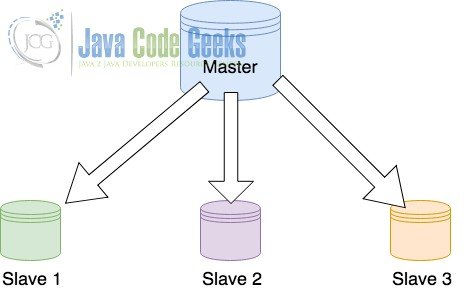
Мастер с рабами
Как показано на рисунке выше, ведомые устройства непрерывно получают данные по мере их обновления в базе данных master. Ведомые не несут ответственности за передачу данных другим подчиненным. Процесс передачи данных от главного к подчиненному полностью асинхронный.
3.2 Master с конфигурацией реле-подчиненных
Релейный подчиненный — это конфигурация, в которой один из подчиненных также несет ответственность за передачу данных другим подключенным подчиненным. В такой конфигурации мастер отправляет данные ограниченному количеству ведомых устройств, а не обслуживает несколько ведомых устройств данными реплики. Эта конфигурация сделана, чтобы уменьшить нагрузку на ведущем устройстве пересылки данных на ведомые устройства.
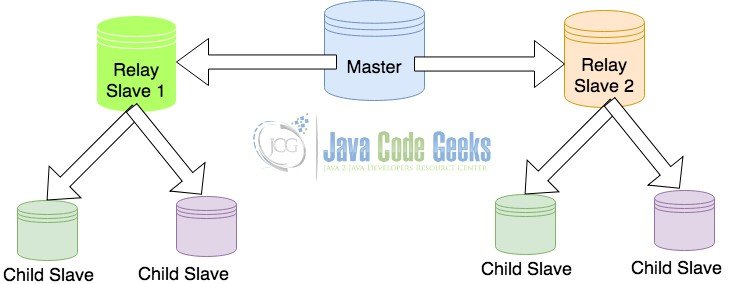
Мастер с эстафетами рабов
Этот тип конфигурации оказывает каскадное влияние на дочерние подчиненные устройства. Если связь между ведущим и одним из подчиненных ретрансляторов на некоторое время замедляется или замедляется, следовательно, это приведет к задержке репликации и в соответствующих дочерних подчиненных устройствах. Таким образом, этот тип репликации предпочтителен только в том случае, если задержки репликации приемлемы.
3.3 Круговая конфигурация Multi-Master
Конфигурация с несколькими главными устройствами обеспечивается пользовательскими интерфейсами конфигурации, в которых есть две основные базы данных, настроенные для работы в качестве подчиненных друг для друга в топологии кластера. Этот тип конфигурации, также известный как мастер с активной главной конфигурацией, предпочтителен, когда единственной целью является сохранение копии базы данных. Это экономит нам время и деньги, вложенные в настройку дополнительных подчиненных серверов для каждой основной базы данных.

Мастер с Активным мастером
3.4 Мастер с резервной конфигурацией мастера
Выше обсуждаемые топологии являются асинхронными топологиями. В асинхронной топологии база данных master просто отправляет данные ведомому и возобновляет свои операции. Не ждет отклика от раба. Таким образом, если данные будут потеряны или возникнут какие-либо проблемы при записи данных на диск, основная база данных не сможет их обработать. Мастер с резервной конфигурацией мастера точно, чтобы гарантировать нулевую потерю данных. В этом типе конфигурации мастер связывается с резервным мастером полусинхронно. Полусинхронная связь означает, что мастер ожидает, пока резервная база данных мастера не подтвердит обновление данных. Основная база данных возобновляет свою обработку, как только подтверждение получено, независимо от того, зафиксированы данные или нет. Однако это значительно снижает вероятность потери данных.
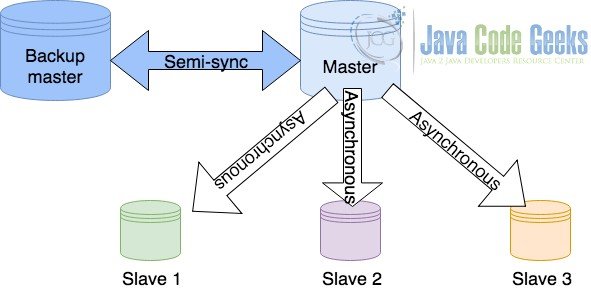
Мастер с резервным мастером
Такая конфигурация оказывает значительное влияние на производительность основной базы данных и, следовательно, она предпочтительна только тогда, когда потеря данных имеет решающее значение. Также важно отметить, что связь является полусинхронной только с базой данных резервного копирования, в то время как подчиненные устройства все еще взаимодействуют асинхронно.
3.5 Несколько мастеров — конфигурация с одним подчиненным
Это единственная в своем роде конфигурация, в которой подчиненное устройство засыпается данными от нескольких мастеров. Такая конфигурация реализуется, когда единственной целью является резервное копирование данных. Такая конфигурация обычно предпочитается хост-серверами для обеспечения бесперебойной работы и согласованности данных. Такая конфигурация так же проста, как и первая, если в ней нет конфликтующих таблиц. Описание этой конфигурации было показано ниже.
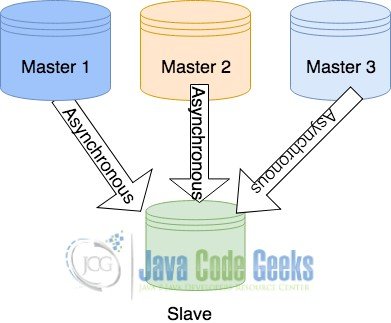
Мульти Мастер Топология
4. Настройка серверов для репликации MySQL
Теперь, когда у нас есть достаточное понимание возможных топологий репликации MySQL, давайте приступим к настройке серверов для репликации. Настройка серверов для репликации MySQL включает в себя настройку уникального идентификатора для каждого сервера, настройку главного и подчиненного с их соответствующими ролями и предоставление соответствующих разрешений ведомому в главной базе данных. В этом разделе будут подробно описаны соответствующие шаги.
Чтобы настроить идентификатор серверов, откройте файл конфигурации my.cnf из каталога конфигурации MySQL. Его можно найти по пути /etc/my.cnf в Linux, /usr/local/mysql/support-files/my.cnf в MacOS, а в случае Windows — в соответствующем базовом каталоге. Если файл не найден, вы можете создать его в соответствующем каталоге. В идеале, сервер MySQL должен быть в состоянии подобрать его. В случае MacOS, если вы установили сервер MySQL с помощью файла .dmg, вам может потребоваться выбрать файл конфигурации из системных настроек. Для остальной части ОС сервер MySQL обнаруживает файл конфигурации автоматически.
Получив файл, убедитесь, что в нем уже присутствуют следующие сведения.
|
1
2
3
4
5
|
[mysqld]log-bin=mysql-binbinlog-do-db=mynewdbserver-id=1innodb_flush_log_at_trx_commit=1 |
Из вышеперечисленных свойств один из наших интересов — server-id . Эта переменная используется для присвоения различных идентификаторов серверам, если на одном компьютере запущено несколько серверов или конфигурируется конфигурация главного подчиненного устройства. Для одного из компьютеров / серверов, которые вы используете, измените этот идентификатор на 2. Это поможет механизму репликации легко определить направление потока данных. Как только изменения в параметре будут выполнены и сохранены, у нас будет два экземпляра сервера — один с идентификатором 1 и другой с идентификатором 2. Перезапустите сервер MySQL, для которого был обновлен идентификатор. Теперь серверы готовы к настройке для репликации.
Теперь, понимая остальные свойства:
log-bin: это свойство определяет местоположение, где будут храниться журналы процесса репликации
binlog-do-db: это свойство определяет базу данных, которая будет реплицирована на подчиненный сервер баз данных
innodb_flush_log_at_trx_commit: это свойство используется для настройки очистки журнала в случае синхронной настройки, когда база данных master получает подтверждение коммита. В случае ведомого, журналы очищаются, когда обновление данных резервной копии было зафиксировано.
Как только следующие конфигурации будут выполнены как на клиенте, так и на сервере, перезапустите сервисы MySQL на обеих системах. Чтобы перезапустить службы, следуйте специальным подходам ОС, представленным ниже:
MacOSx: Перейдите в « Системные настройки»> «MySQL». Остановите работающий экземпляр сервера. Выберите соответствующий файл конфигурации на вкладке Конфигурация и снова запустите сервер. Это должно запустить сервер с настроенными свойствами. Если у вас возникли проблемы с запуском сервера, убедитесь, что свойства сохранены правильно, а порт не используется.
Linux: во всех вариантах Linux вы можете использовать приведенную ниже команду для перезапуска сервера. Команда будет полезна, если у вас есть одна система на сервер базы данных.
|
1
|
$ sudo service mysql restart |
Windows: В случае Windows вам необходимо остановить службу MySQL56. Для этого откройте окно поиска Windows и введите Services . В окне «Службы» найдите службу MySQL56 (имя по умолчанию). Щелкните правой кнопкой мыши службу и перезапустите ее, чтобы изменения были отражены.
5. Включение репликации Master-Slave
5.1 Настройка мастера
Первым шагом к включению репликации главного подчиненного является создание пользователя, который имеет доступ к основной базе данных для целей репликации. Пользователь будет использоваться ведомым для считывания данных с мастера для репликации. Для этого выполните приведенную ниже команду, которая создает пользователя с именем rep_user для репликации.
|
1
|
$ GRANT REPLICATION SLAVE ON *.* TO 'rep_user'@'192.168.1.26' IDENTIFIED BY 'password'; |
Приведенная выше команда отображает нового пользователя на подчиненный IP-адрес. Таким образом, он может использоваться исключительно конкретным рабом. Это обеспечивает правильное ведение журнала для целей аудита. Выполните указанную выше команду, а затем приведенную ниже команду, чтобы записать изменения в разрешениях.
|
1
|
$ FLUSH PRIVILEDGES |
Теперь, когда мы разрешили пользователю репликации из ведомой базы данных получать доступ ко всем базам данных с главного устройства, нам нужно выбрать, какая база данных фактически должна быть реплицирована. Выберите базу данных для репликации.
|
1
|
$ use mynewdb |
Чтобы мы могли отменить изменения, вам необходимо сделать резервную копию их текущего состояния. Для этого заблокируйте базу данных, используя команду ниже.
|
1
|
$ FLUSH TABLES WITH READ LOCK; |
Приведенная выше команда сбрасывает все ожидающие запросы в базе данных и блокирует изменения. Как только мы заблокировали его, сделайте резервную копию текущего состояния базы данных, а также проверьте текущее состояние, чтобы понять позицию, с которой начнется репликация. Чтобы сделать резервную копию, выполните следующую команду из командной строки или терминала.
|
1
|
$ mysqldump -u root -p --opt mynewdb > mynewdb.sql |
Помните, что это не командная строка MySQL и, следовательно, должна выполняться вне ее. Проверьте текущее состояние базы данных, чтобы получить информацию о текущем положении базы данных.
|
1
2
3
4
5
6
7
|
$ SHOW MASTER STATUS;+------------------+----------+--------------+------------------+| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |+------------------+----------+--------------+------------------+| mysql-bin.000001 | 104 | mynewdb | |+------------------+----------+--------------+------------------+1 row in set (0.00 sec) |
Обратите внимание на значение столбца позиции здесь, так как было бы полезно проверить успешную конфигурацию master-slave. Теперь, когда у нас есть необходимый дамп и информация о позиции, теперь база данных может быть разблокирована, и мы можем приступить к настройке подчиненной базы данных. Чтобы разблокировать таблицы, выполните следующую команду.
|
1
|
$ UNLOCK TABLES; |
5.2 Конфигурация подчиненной базы данных
Первым шагом к запуску с ведомой базой данных является создание базы данных с тем же именем, что и у основной базы данных репликации. После создания база данных должна быть импортирована в ведомое устройство, чтобы охватить данные, которые могут уже существовать в ведущем устройстве. Для этого выполните следующие понятные команды.
|
1
2
|
$ create database mynewdb;$ exit |
Выполните приведенную ниже команду импорта за пределами терминала MySQL.
|
1
|
$ mysql -u root -p mynewdb < /path/to/mynewdb.sql |
Когда база данных будет импортирована и готова к использованию, нам нужно начать с настройки ведомого. Чтобы настроить базу данных, откройте файл конфигурации в совместимом текстовом редакторе. Настройте следующие параметры в файле конфигурации. Если вы используете несколько серверов на одном компьютере, отредактируйте соответствующий файл my2.cnf, как указано в этом руководстве .
|
1
2
3
4
5
|
[mysqld]log-bin=mysql-binbinlog-do-db=mynewdbserver-id=2relay-log=/path/to/mysql-relay-bin.log |
Сохраните изменения и перезапустите сервер, чтобы изменения были отражены. Наконец, пришло время настроить главный сервер, чтобы он был главным в этой подчиненной базе данных. Снова откройте приглашение mysql и введите команду ниже, чтобы настроить подчиненную БД для чтения из позиции, указанной выше — 104.
|
1
|
CHANGE MASTER TO MASTER_HOST='192.168.1.25',MASTER_USER='repl_user', MASTER_PASSWORD='password', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS= 104; |
Таким образом, сервер базы данных в 192.168.1.25 будет действовать как главный сервер для моего подчиненного сервера базы данных в 192.168.1.26. Обратите внимание, что MASTER_LOG_POS=104 определяет позицию, с которой начнется чтение для репликации.
Переданные выше учетные данные — это учетные данные пользователя репликации, созданного в процессе настройки главной базы данных выше. Теперь ведомое устройство готово к репликации базы данных, поскольку в основную базу данных внесены изменения. Все, что осталось сделать, это запустить сервер в качестве ведомого устройства с помощью приведенной ниже команды, введенной в командной строке MySQL.
|
1
|
$ START SLAVE |
Теперь ведомое устройство считывает данные, чтобы автоматически их воспроизвести. В любой момент времени, чтобы проверить состояние чтения, вы можете выполнить приведенную ниже команду.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
$ mysql> SHOW SLAVE STATUS\G*************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: master Master_User: repl_user Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 931 Relay_Log_File: slave-relay-bin.000056 Relay_Log_Pos: 950 Relay_Master_Log_File: mysql-bin.000001 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 931 Relay_Log_Space: 1365 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: 0 |
\G в приведенной выше команде является аргументом форматирования. Он отображает данные в одной строке на каждый столбец формата. В случае каких-либо проблем при запуске ведомого устройства, вам, возможно, придется пропустить проблему, используя приведенную ниже команду.
|
1
|
SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1; SLAVE START; |
6. Источник данных от нескольких рабов
Теперь, когда мы настроили один источник и один ведомый, давайте попробуем настроить что-то сложное. Мастера в топологии с несколькими источниками должны быть настроены для использования одного из следующих:
- Глобальный идентификатор транзакции (GTID)
- Репликация на основе двоичного журнала
Чтобы настроить и использовать глобальный идентификатор транзакции, важно включить gtid_mode . Чтобы настроить каждый мастер с различным GTID, используйте команду ниже.
|
1
2
|
CHANGE MASTER TO MASTER_HOST='master1', MASTER_USER='repl_user', MASTER_PORT=3306, MASTER_PASSWORD='password', \MASTER_AUTO_POSITION = 104 FOR CHANNEL 'master-1'; |
Чтобы настроить мастер с другим GTID, просто измените значения приведенной выше команды на другое. Чтобы настроить несколько мастеров, используя двоичный параметр положения журнала, вы можете использовать приведенную ниже команду с соответствующим двоичным параметром журнала, полученным с помощью параметра SHOW MASTER STATUS;
|
1
2
|
$ CHANGE MASTER TO MASTER_HOST='master1', MASTER_USER='repl_user', MASTER_PORT=3306, MASTER_PASSWORD='password' \MASTER_LOG_FILE='master1-bin.000001', MASTER_LOG_POS=104 FOR CHANNEL 'master-1'; |
Как только эта конфигурация завершена, мастера готовы действовать как несколько источников. Следующим шагом является запуск ведомого устройства либо для определенного канала, либо для нескольких каналов. Чтобы запустить сервер для определенной репликации базы данных, запустите ведомую базу данных, используя приведенный ниже код.
|
1
|
$ START SLAVE thread_types FOR CHANNEL master-1; |
thread_types могут быть выбраны в соответствии с требуемыми типами нитей. Для получения дополнительной информации о том же, вы можете обратиться по ссылке ниже . Чтобы запустить репликацию для всех источников, используйте команду ниже.
|
1
|
$ START SLAVE thread_types; |
7. Настройка нескольких ведомых для базы данных с одним главным
До сих пор мы видели конфигурации для двух разных топологий. Один из них был Одиночным Главным Одиночным Ведомым, а другой — Мультимастерным Одиночным Рабом. Чтобы настроить топологию с несколькими подчиненными устройствами, необходимо выполнить очень простые шаги. Для настройки нескольких подчиненных вам необходимо следующее:
- Дополнительный пользователь для дополнительных подчиненных с необходимым разрешением репликации
- Раб с другим идентификатором сервера
При выполнении этих требований можно легко настроить дополнительного подчиненного устройства. Чтобы добавить нового пользователя репликации, используйте приведенную ниже команду с соответствующим IP-адресом сервера.
|
1
|
$ GRANT REPLICATION SLAVE ON *.* TO 'rep_user'@'xxx.xxx.xxx.xxx' IDENTIFIED BY 'password'; |
Имя пользователя и пароли могут отличаться при необходимости. Если вы планируете создать большое количество ведомых устройств, рекомендуется создать пользователя с глобальным доступом, чтобы избежать повторного создания пользователей. Пользователь с глобальным доступом может быть создан с помощью приведенной ниже команды.
|
1
|
$ GRANT REPLICATION SLAVE ON *.* TO 'rep_user'@'%' IDENTIFIED BY 'password'; |
Приведенная выше команда создаст пользователя репликации, который может использоваться любым настраиваемым ведомым устройством. Таким образом, пользовательскую конфигурацию для каждого ведомого не нужно запоминать. Следующим шагом является настройка другого server-id . Как уже объяснялось в приведенных выше разделах, его можно настроить с помощью файла конфигурации соответствующего сервера.
8. Плюсы и минусы репликации
Плюсы реализации репликации MySQL включают следующее:
- Снижение нагрузки на мастер для операций обработки данных
- Плавное распределение нагрузки для приложений с интенсивным использованием базы данных
- Более безопасное и согласованное резервное копирование данных
- Несколько копий данных позволяет быстрее обслуживать данные в каждом регионе
Несмотря на многочисленные преимущества репликации, это процесс, который следует делать осторожно. Ниже приведены несколько ожидаемых негативных последствий, если не позаботиться о них.
- Увеличьте основную нагрузку для передачи данных на ведомые устройства. Это бремя, когда число рабов пересекает оптимальный предел
- Асинхронная репликация не обеспечивает 100% согласованности. Таким образом, идеальная копия все еще не может быть гарантирована.
9. Вывод
В статье подробно рассказывается о настройке главного и подчиненного серверов репликации MySQL. Существует множество возможных конфигураций репликации. Выбор топологии полностью зависит от задачи, на которую вы нацелены. Существует множество преимуществ репликации, перечисленных выше. Тем не менее, репликация должна осуществляться осторожно и по мере необходимости. Репликация MySQL увеличивает нагрузку на сервер, если количество подчиненных устройств увеличивается. Таким образом, с правильно настроенным нужным числом ведомых устройств репликация MySQL помогает снизить нагрузку на главный сервер и также поддерживать резервное копирование данных.