Давайте погрузимся прямо в! В предыдущем посте (часть I) мы настраивали контекст для этого блога. По сути, поскольку мы внедряем стратегию по внедрению микросервисов в нашу архитектуру, мы не можем и не должны нарушать текущие потоки запросов. Наши «монолитные» приложения обычно представляют большую ценность для бизнеса, и мы должны снизить риск негативного влияния на эти системы по мере итерации и расширения. Это приводит нас к часто пропускаемому факту: когда мы начнем исследовать путешествие от монолита к микросервису, мы быстро столкнемся с нежелательными, порой неприятными частями, которые мы не можем просто забыть. Я призываю вас вернуться и прочитать первую часть, если вы еще этого не сделали . Также прочитайте часть о том, когда НЕ делать микросервисы .
Следите за новостями ( @christianposta ) в твиттере или на сайте http://blog.christianposta.com, чтобы получать последние обновления и обсуждения.
Из предыдущей части, вот некоторые из соображений, которые мы хотим решить:
- Нам нужен надежный и последовательный способ построения наших услуг. Нам нужна система непрерывной доставки.
- Нам нужен способ проверить наши услуги / монолит / и т. Д.
- Нам нужен способ безопасного внесения любых изменений в производство, включая темные катера, канареек и т. Д.
- Нам нужен способ направить трафик к нашим новым изменениям или включить изменения (или отключить переключатель) любые новые функции / изменения
- Мы будем иметь дело со многими неприятными проблемами интеграции данных
технологии
Технологии, которые мы используем, чтобы помочь нам в этом путешествии:
- Фреймворки для разработчиков ( Spring Boot , WildFly , WildFly Swarm )
- Дизайн API ( APICur.io )
- Каркасы данных ( Spring Boot Teiid , Debezium.io )
- Инструменты интеграции ( Apache Camel )
- Сетка сервисная ( Istio Service Mesh )
- Инструменты миграции баз данных ( Liquibase )
- Темный запуск / фреймворк с признаками ( FF4J )
- Платформа развертывания / CI-CD ( Kubernetes / OpenShift )
- Инструменты разработчика Kubernetes ( Fabric8.io )
- Инструменты тестирования ( Arquillian , Pact / Arquillian Algeron , Hoverfly , тест Spring-Boot , RestAssured , Arquillian Cube )
Если вы хотите продолжить, пример проекта, который я использую, основан на руководстве TicketMonster на http://developers.redhat.com, но был изменен, чтобы показать эволюцию от монолита к микросервису. Вы можете найти код и документацию (документы еще в разработке!) Здесь, на github: https://github.com/ticket-monster-msa/monolith
Давайте шаг за шагом пройдем первую часть и посмотрим, как мы можем решить каждый шаг. Мы также приведем соображения из прошлого блога и рассмотрим их в этом контексте.
Встречайте монолит
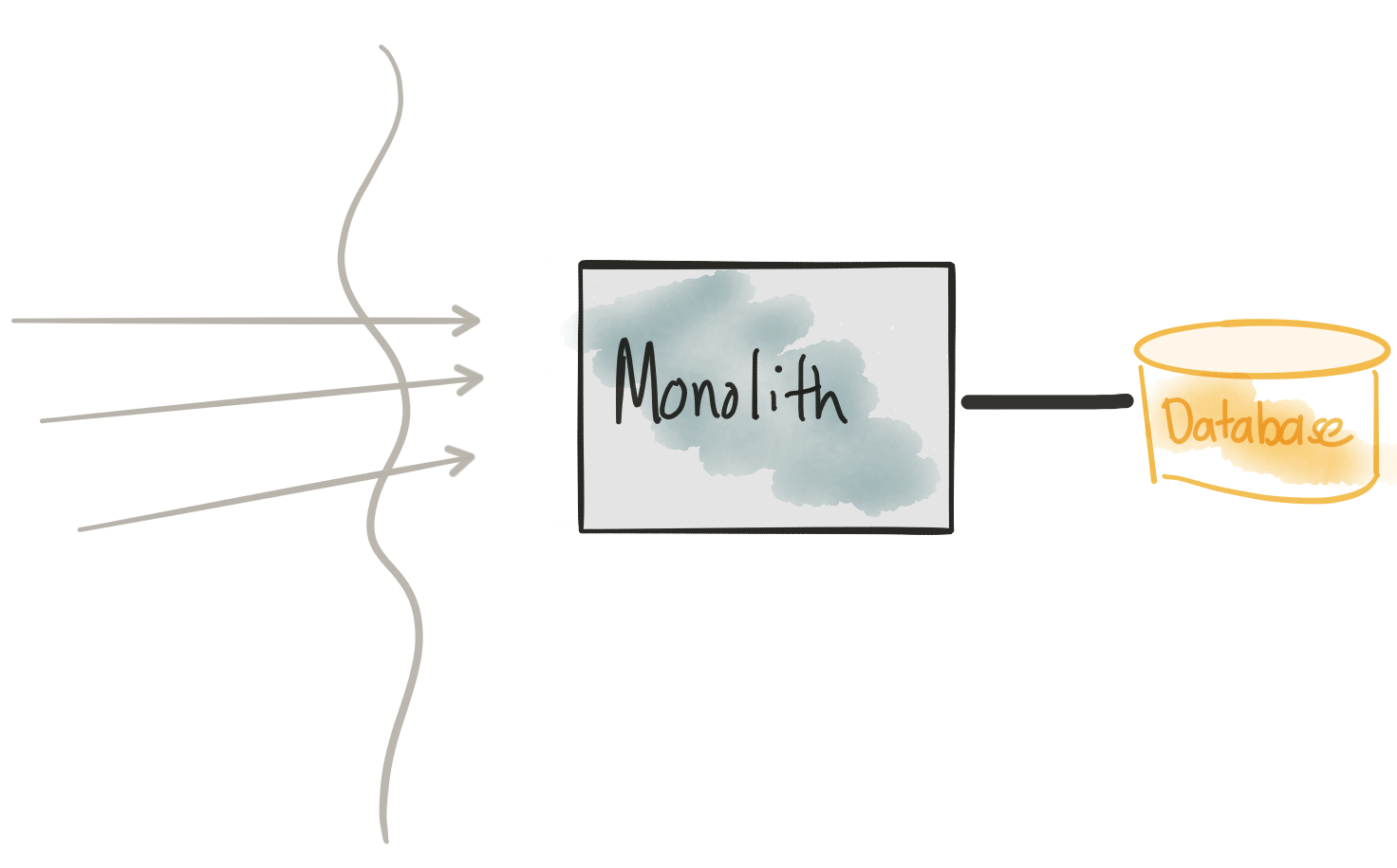
Пересмотреть соображения
- Монолит (схема кода и базы данных) трудно изменить
- Изменения требуют полного повторного развертывания и высокой координации между командами
- Нам нужно провести много тестов, чтобы поймать регрессии
- Нам нужен полностью автоматизированный способ развертывания
Это не всегда возможно, но если вы можете, напишите много тестов для вашего монолита. По мере того, как мы начинаем развивать монолит, добавляя новые функциональные возможности или заменяя существующие функциональные возможности, нам необходимо хорошо понимать влияние наших изменений. В своей книге о рефакторинге унаследованного кода Майкл Фезерс определяет «унаследованный код» как отсутствие тестов. Использование таких инструментов, как JUnit и Arquillian, очень помогает. С Arquillian вы можете получить как мелкое, так и крупное зерно, как вам нравится, и упаковать свое приложение так, как вам нужно (с правильной проверкой и т. Д.), Чтобы выполнить ту часть приложения, которую вы намереваетесь протестировать. Например, в нашем монолите (TicketMonster) мы можем определить микро-развертывание, которое заглушает базу данных для оперативной памяти, а также предварительно загружает базу данных с образцами данных. Arquillian хорошо работает для приложений Spring Boot, Java EE и т. Д. В этом случае мы тестируем монолит Java EE:
|
01
02
03
04
05
06
07
08
09
10
|
public static WebArchive deployment() { return ShrinkWrap .create(WebArchive.class, "test.war") .addPackage(Resources.class.getPackage()) .addAsResource("META-INF/test-persistence.xml", "META-INF/persistence.xml") .addAsResource("import.sql") .addAsWebInfResource(EmptyAsset.INSTANCE, "beans.xml") // Deploy our test datasource .addAsWebInfResource("test-ds.xml");} |
Еще интереснее то, что вы можете запускать свои тесты, встроенные во время выполнения, чтобы убедиться, что все компоненты работают внутри. Например, в одном из приведенных выше тестов мы можем просто добавить BookingService в наши тесты и запустить его напрямую:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
@RunWith(Arquillian.class)public class BookingServiceTest { @Deployment public static WebArchive deployment() { return RESTDeployment.deployment(); } @Inject private BookingService bookingService; @Inject private ShowService showService; @Test @InSequence(1) public void testCreateBookings() { BookingRequest br = createBookingRequest(1l, 0, new int[]{4, 1}, new int[]{1,1}, new int[]{3,1}); bookingService.createBooking(br); BookingRequest br2 = createBookingRequest(2l, 1, new int[]{6,1}, new int[]{8,2}, new int[]{10,2}); bookingService.createBooking(br2); BookingRequest br3 = createBookingRequest(3l, 0, new int[]{4,1}, new int[]{2,1}); bookingService.createBooking(br3); } |
Для полного примера посмотрите на BookingServiceTest от монолитного модуля TicketMonster .
Но как насчет развертывания?
Kubernetes стал де-факто платформой для развертывания контейнерных сервисов / приложений. Kubernetes обрабатывает такие вещи, как проверка работоспособности, масштабирование, перезапуски, балансировка нагрузки и т. Д. Для разработчиков на Java мы можем даже использовать такие инструменты, как fabric8-maven-plugin, чтобы автоматически создавать образы контейнеров / докеров и генерировать любые файлы ресурсов развертывания. OpenShift — это выпущенная RedHat версия Kubernetes, которая, помимо прочего, добавляет возможности разработчика, в том числе такие, как конвейеры CI / CD.
Kubernetes / OpenShift — это платформа для развертывания ваших приложений / услуг независимо от того, являются ли они микросервисами, монолитами или чем-то еще между ними (с возможностью обработки постоянных рабочих нагрузок, например, баз данных и т. Д.). С Arquillian, контейнерами и конвейерами OpenShift у нас есть надежный способ непрерывно вносить изменения в производство. Кстати … извлечение openshift.io, которое еще больше расширяет возможности разработчика: автоматические конвейеры CI / CD, интеграция SCM, рабочие пространства для разработчиков Eclipse Che , сканирование библиотек и т. Д.
В этот момент производственная нагрузка направлена на монолит. Если мы перейдем на его главную страницу, мы увидим что-то вроде этого: 
Давайте начнем вносить некоторые изменения …
Извлечь пользовательский интерфейс 
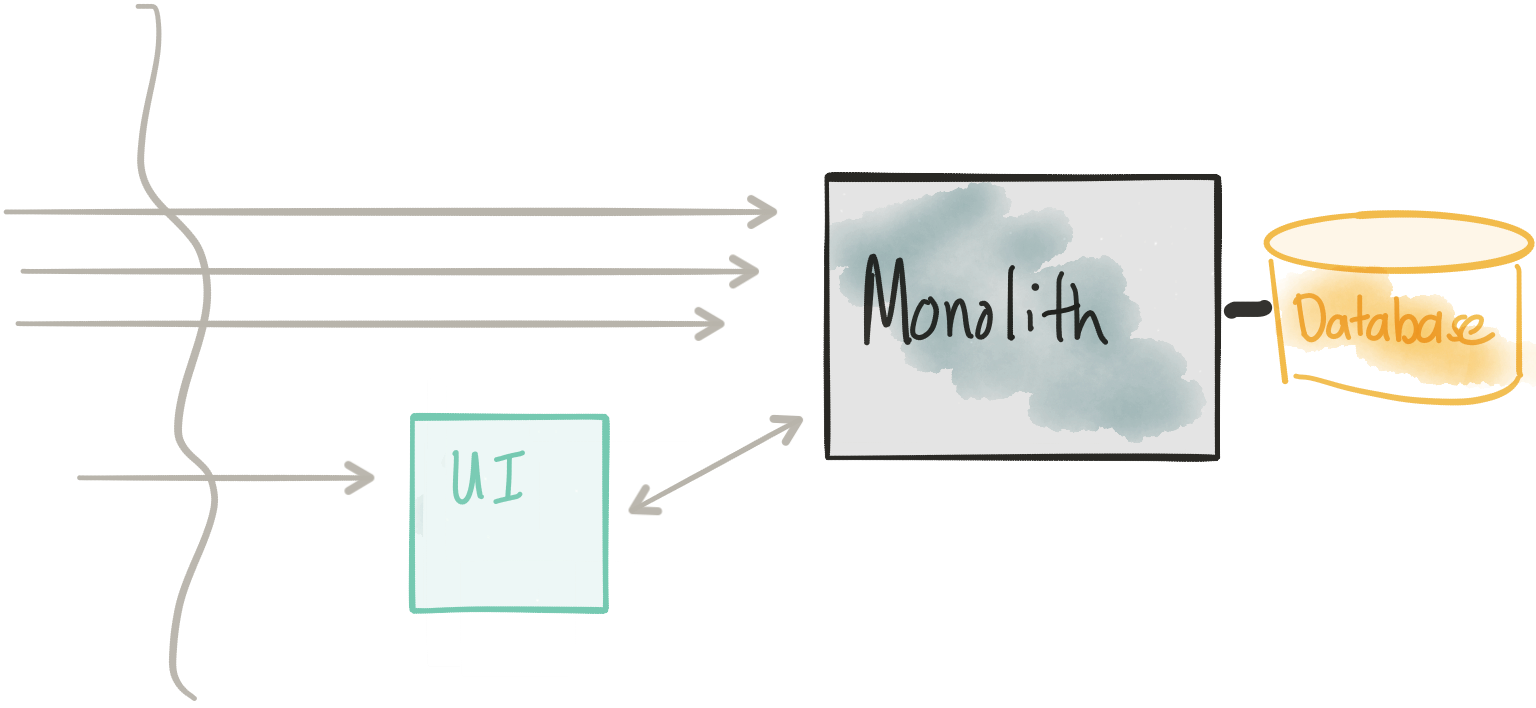
Пересмотреть соображения
- Не модифицируйте монолит для этого первого шага; просто скопируйте / мимо пользовательского интерфейса в отдельный компонент
- У нас должен быть разумный API удаленного взаимодействия между пользовательским интерфейсом и монолитом — это не всегда так
- Поверхность безопасности увеличивается
- Нам нужен способ управляемой маршрутизации / разделения трафика на новый пользовательский интерфейс и / или монолит напрямую для поддержки темного запуска / канареечного / скользящего выпуска
Если мы посмотрим на код TicketMonster UI v1, то увидим, что это очень просто. Мы переместили статические компоненты HTML / JS / CSS на собственный веб-сервер и упаковали их в контейнер. Таким образом, мы можем развернуть его отдельно от монолита и внести изменения / версии его независимо. Этот проект пользовательского интерфейса все еще должен будет общаться с Monolith для выполнения его функций, поэтому частью этой эволюции должно быть предоставление интерфейса REST, с которым пользовательский интерфейс может взаимодействовать. С некоторыми монолитами это легче сказать, чем сделать. Если вы сталкиваетесь с проблемами, связывая хороший REST API с устаревшим монолитным кодом, я настоятельно рекомендую взглянуть на Apache Camel, в частности на его REST DSL .
Интересная часть этого шага в том, что мы ничего не меняем в монолите. Этот код остается как есть, но наш новый пользовательский интерфейс также развернут. Если мы посмотрим в Kubernetes, то увидим два отдельных объекта Deployment и два отдельных модуля: один для монолита и один для пользовательского интерфейса.
|
1
2
3
4
5
|
ceposta@postamac$ kubectl get deployNAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGEmysql-backend 1 1 1 1 4dticket-monster 1 1 1 1 4dtm-ui-v1 1 1 1 1 4d |
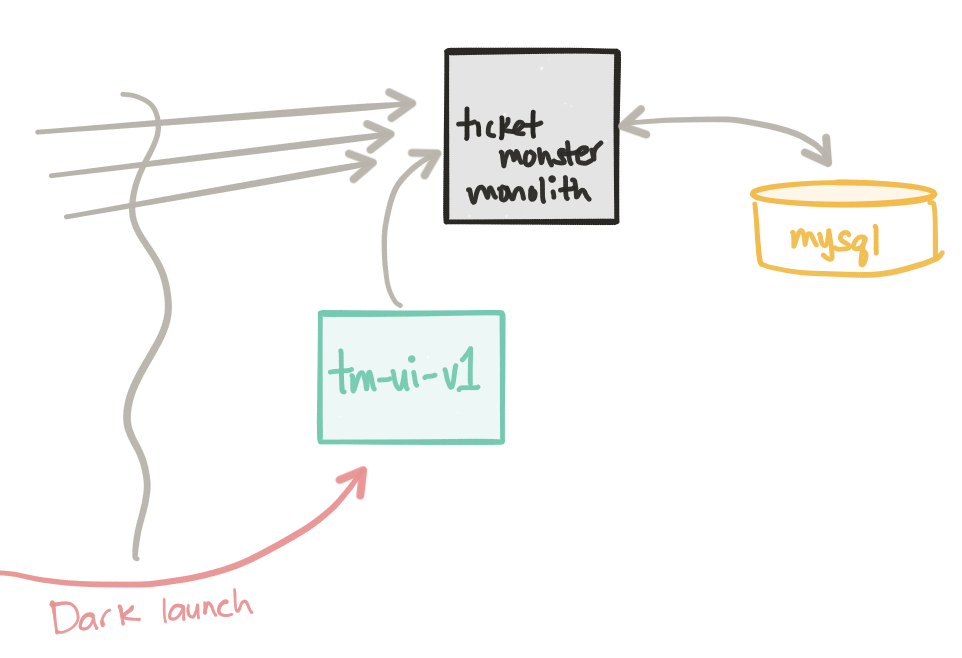
Несмотря на то, что мы развернули пользовательский интерфейс tm-ui-v1 , мы не видим, чтобы какой-либо трафик направлялся в этот новый компонент пользовательского интерфейса TicketMonster. Для простоты, даже если это развертывание не требует производственного трафика (в то время как монолит ticket-monster настоящее время занимает полный производственный трафик), мы все равно можем рассматривать это как простой темный запуск. Если мы перенесемся в интерфейс пользователя, мы все равно сможем добраться до него:
|
1
|
kubectl port-forward tm-ui-v1-3105082891-gh31x 8080:80 |
Мы используем инструменты kubectl с нашего локального ящика на конкретный модуль ( tm-ui-v1-3105082891-gh31x на его порту 80 и отображаем его на наш локальный порт 8080 Теперь, если мы перейдем на http: // localhost : 8080 мы должны перейти к новой версии нашего пользовательского интерфейса (обратите внимание на выделенный текст, указывающий, что это другой пользовательский интерфейс, но он указывает непосредственно на монолит) 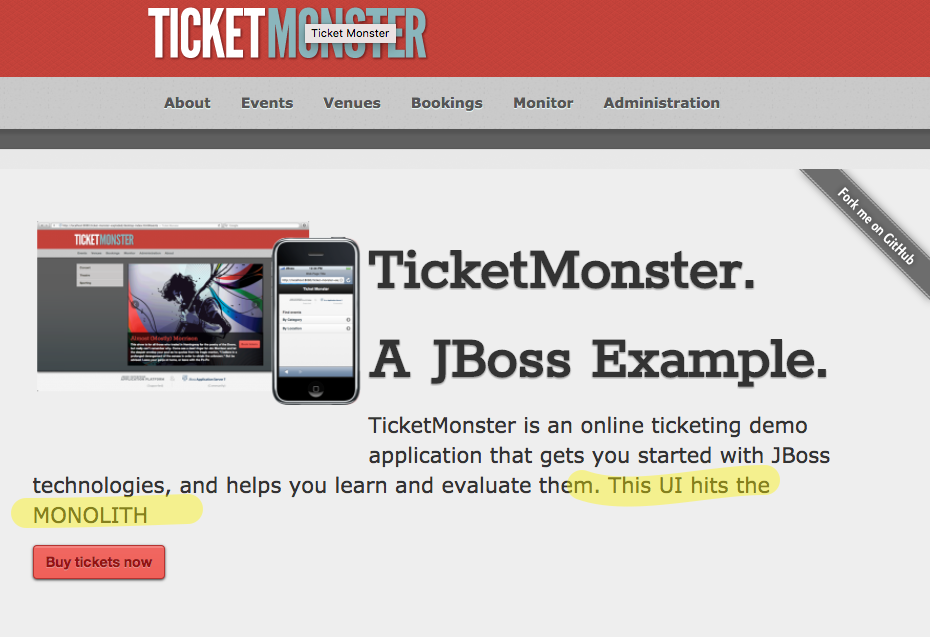
Если мы удовлетворены этой новой версией, мы можем начать направлять трафик на эту новую версию. Для этого мы будем использовать сервисную сетку Istio . Istio — это управляющая плоскость для управления сеткой, состоящей из точек входа и сервисных прокси. Я написал немного о сетке обслуживания и плоскостях данных, таких как Envoy . Я настоятельно рекомендую взглянуть на все его возможности. Мы будем повторять этот проект, пройдя следующие несколько разделов, чтобы изучить возможности Istio. Если вы еще больше не понимаете различие между плоскостью управления и плоскостью данных, взгляните на блог, написанный Мэттом Кляйном, в котором говорится, что
Мы начнем с использования Intio Ingress Controller . Этот компонент позволяет вам контролировать трафик в кластер Kubernetes, используя спецификацию Kubernetes Ingress . После установки Istio мы можем создать такой ресурс Ingress , который будет направлять трафик на службу Kubernetes пользовательского интерфейса Ticket Monster, tm-ui :
|
01
02
03
04
05
06
07
08
09
10
|
apiVersion: extensions/v1beta1kind: Ingressmetadata: name: tm-gateway annotations: kubernetes.io/ingress.class: "istio"spec: backend: serviceName: tm-ui servicePort: 80 |
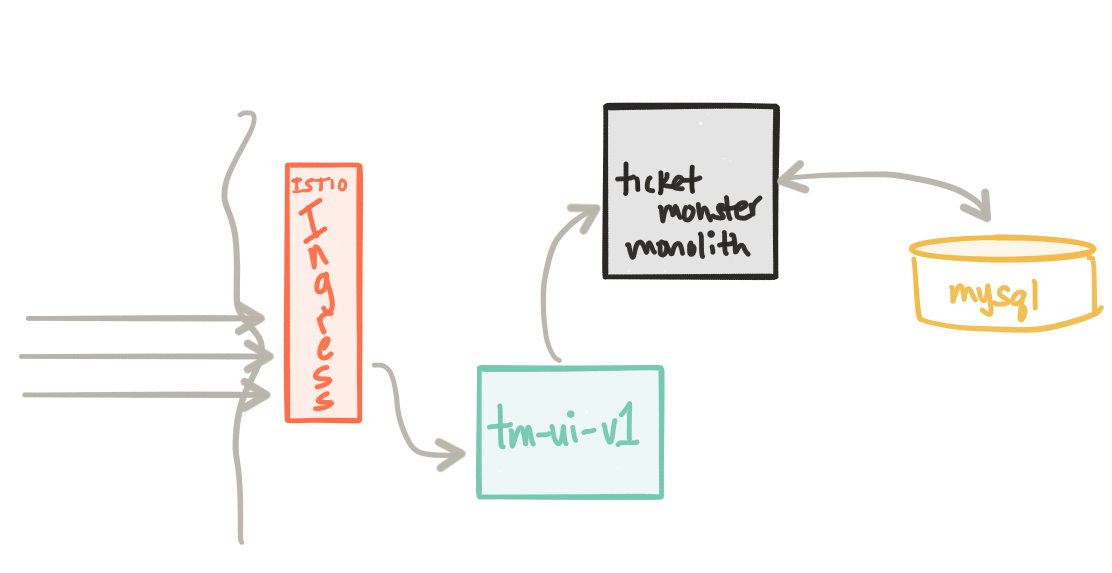
Как только у нас будет вход , мы можем начать применять правила маршрутизации Istio . Например, вот правило маршрута, которое гласит: «Каждый раз, когда кто-то пытается связаться со службой tm-ui работающей в Kubernetes, направьте его в v1 службы»:
|
01
02
03
04
05
06
07
08
09
10
11
|
apiVersion: config.istio.io/v1alpha2kind: RouteRulemetadata: name: tm-ui-defaultspec: destination: name: tm-ui precedence: 1 route: - labels: version: v1 |
Это позволит нам более точно контролировать трафик внутри и даже внутри кластера. Подробнее об этом чуть позже. В конце этого шага весь трафик идет в развертывание tm-ui-v1 которое, в свою очередь, напрямую обращается к монолиту.
Удалите пользовательский интерфейс из монолита 
Пересмотреть соображения
- Мы удаляем компонент пользовательского интерфейса из монолита
- Это требует (надеюсь) минимальных изменений в монолите (отмена / удаление / отключение пользовательского интерфейса, возможные обновления API REST)
- Опять же, мы используем подход управляемой маршрутизации / формирования, чтобы ввести это изменение без простоя
Этот шаг довольно прост. Мы обновляем монолит, удаляя из него статические компоненты пользовательского интерфейса (теперь они перемещены в развертывание tm-ui-v1 ). Мы также можем внести некоторые изменения API в это развертывание, поскольку теперь мы освободили приложение, чтобы оно стало монолитным сервисом с API, который пользовательский интерфейс может использовать и, возможно, другими приложениями. Поскольку мы можем внести некоторые изменения в API, мы также можем захотеть развернуть новую версию нашего пользовательского интерфейса. На этом этапе мы развернем наш сервис backend-v1 а также новый пользовательский интерфейс tm-ui-v2 который использует преимущества этого нового API в нашем сервисе backend .
Давайте посмотрим, что развернуто в нашем кластере Kubernetes:
|
1
2
3
4
5
6
|
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGEbackend-v1 1 1 1 1 4dmysql-backend 1 1 1 1 4dticket-monster 1 1 1 1 4dtm-ui-v1 1 1 1 1 4dtm-ui-v2 1 1 1 1 4d |
На этом этапе ticket-monster и tm-ui-v1 принимают оперативную нагрузку. backend-v1 и пользовательский интерфейс tm-ui-v2 не загружаются. Стоит отметить, что развертывание backend-v1 использует ту же базу данных, что и развертывание ticket-monster поскольку оно почти идентично, но имеет немного другой интерфейс API, обращенный наружу.
Наши новые компоненты backend-v1 и tm-ui-v2 были развернуты в производство. Сейчас хорошее время, чтобы сосредоточиться на простом, но важном факте: мы внедрили наши изменения в производство, но мы никому их не публиковали. У замечательных людей в turbinelabs.io есть отличный блог, в котором об этом говорится более подробно . У нас есть возможность сделать неформальный темный запуск. Может быть, мы хотим сначала медленно развернуть это развертывание для наших внутренних пользователей или, может быть, для группы пользователей в определенном регионе на определенном устройстве и т. Д. 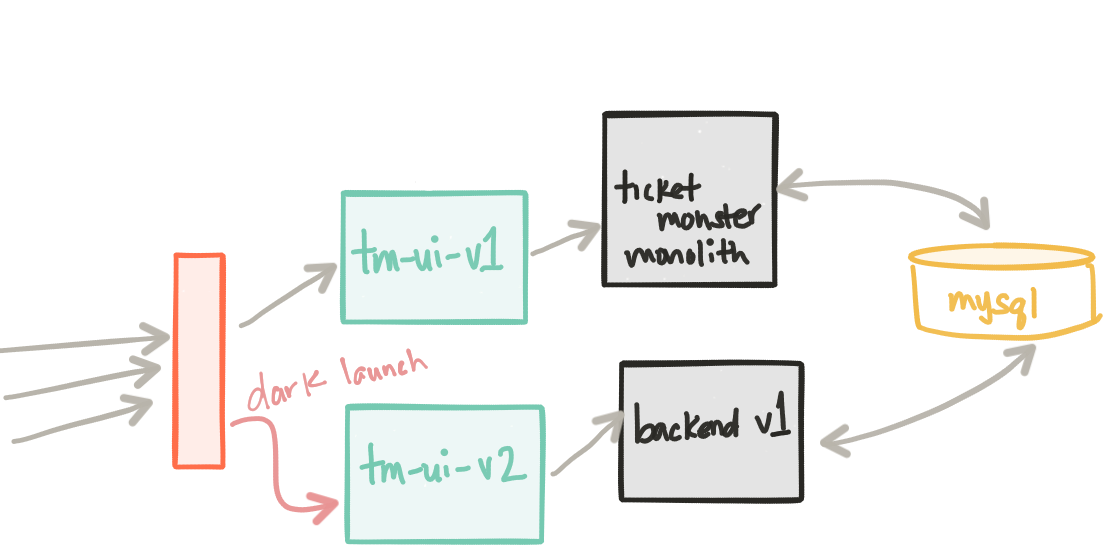
Поскольку теперь у нас есть Istio, давайте посмотрим, что он может сделать для нас. Мы хотим сделать темный запуск только для внутренних пользователей. Эти внутренние пользователи могут быть идентифицированы, как нам нравится (заголовки, IP и т. Д.), Но для этого примера мы скажем любой запрос с HTTP-заголовком x-dark-launch: v2 будет перенаправлен на наш новый backend-v1 и tm-ui-v2 сервис. Вот как выглядит правило маршрута istio:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
apiVersion: config.istio.io/v1alpha2kind: RouteRulemetadata: name: tm-ui-v2-dark-launchspec: destination: name: tm-ui precedence: 10 match: request: headers: x-dark-launch: exact: "v2" route: - labels: version: v2 |
Когда мы заходим на нашу главную страницу как любой пользователь, мы должны видеть текущее развертывание ( tm-ui-v1 говорит с монолитом ticket-monster ): 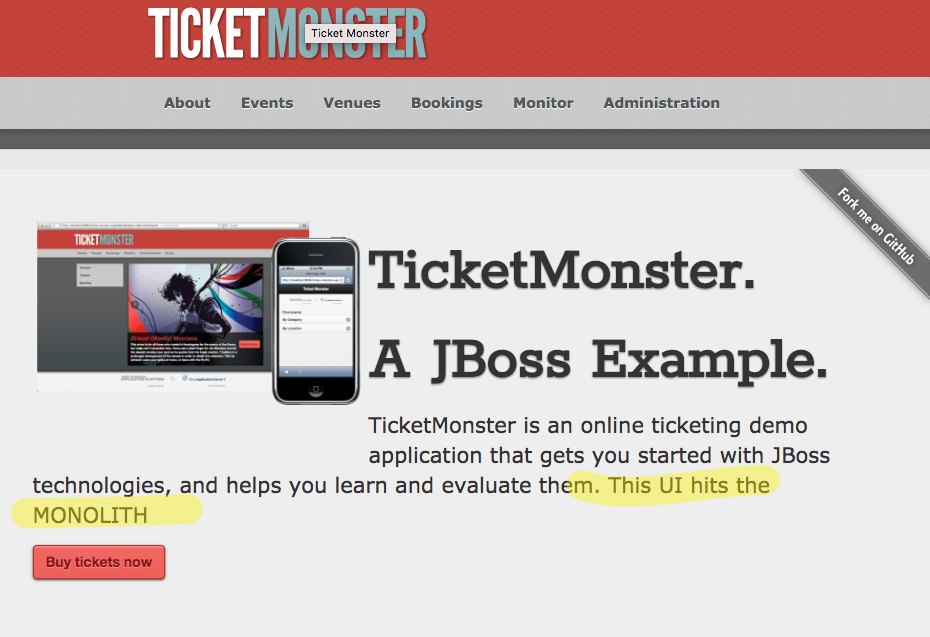
Теперь, если мы изменим заголовки в нашем браузере (например, с помощью инструмента Modify Headers Firefox или чего-то подобного), мы должны быть перенаправлены на наш набор темных сервисов ( tm-ui-v2 говорящий с backend-v1 ): 
Затем нажмите «Пуск», чтобы начать изменение заголовка и обновить страницу: 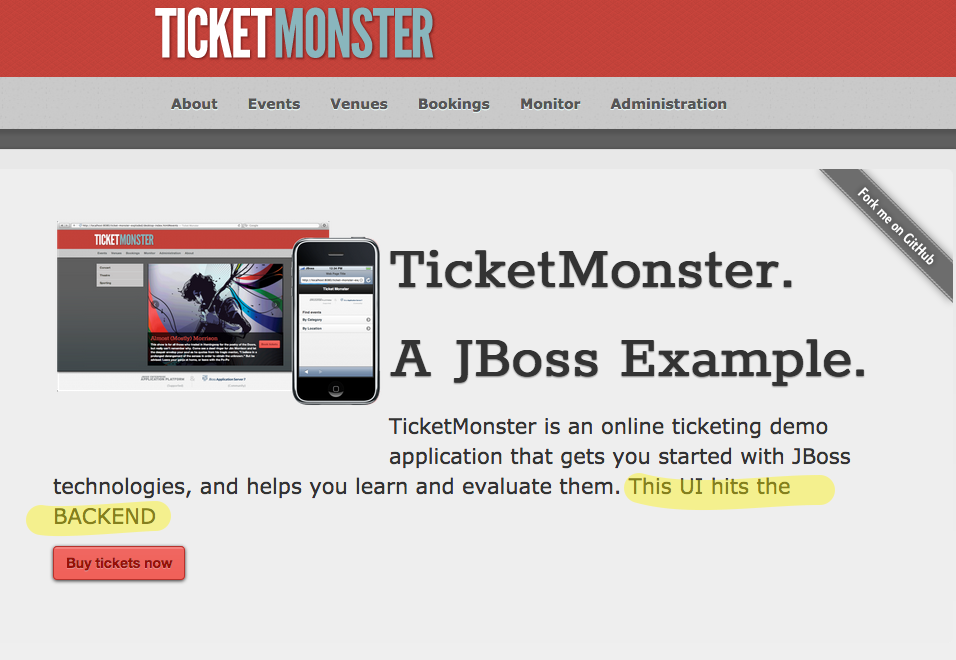
Мы видим, что теперь мы перенаправлены на темный запуск наших услуг. Отсюда мы можем начать выпуск для нашей клиентской базы, выполнив канареечный выпуск (возможно, мы делаем 1% живого трафика для нашего нового развертывания) и постепенно увеличивая нагрузку на трафик (5%, 10%, 50% и т. Д.), Если мы Видите, нет никаких побочных эффектов. Вот пример правила маршрута Istio, которое ограничивает трафик v2 на 1%:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
apiVersion: config.istio.io/v1alpha2kind: RouteRulemetadata: name: tm-ui-v2-1pct-canaryspec: destination: name: tm-ui precedence: 20 route: - labels: version: v1 weight: 99 - labels: version: v2 weight: 1 |
Возможность «увидеть» или «наблюдать» за эффектами этого релиза имеет решающее значение, и мы поговорим об этом чуть позже. Также обратите внимание, что этот подход к выпуску канареек в настоящее время осуществляется на грани нашей архитектуры, но межсервисное взаимодействие / взаимодействие может контролироваться с помощью istio для канареек. На следующих шагах мы начнем это видеть. 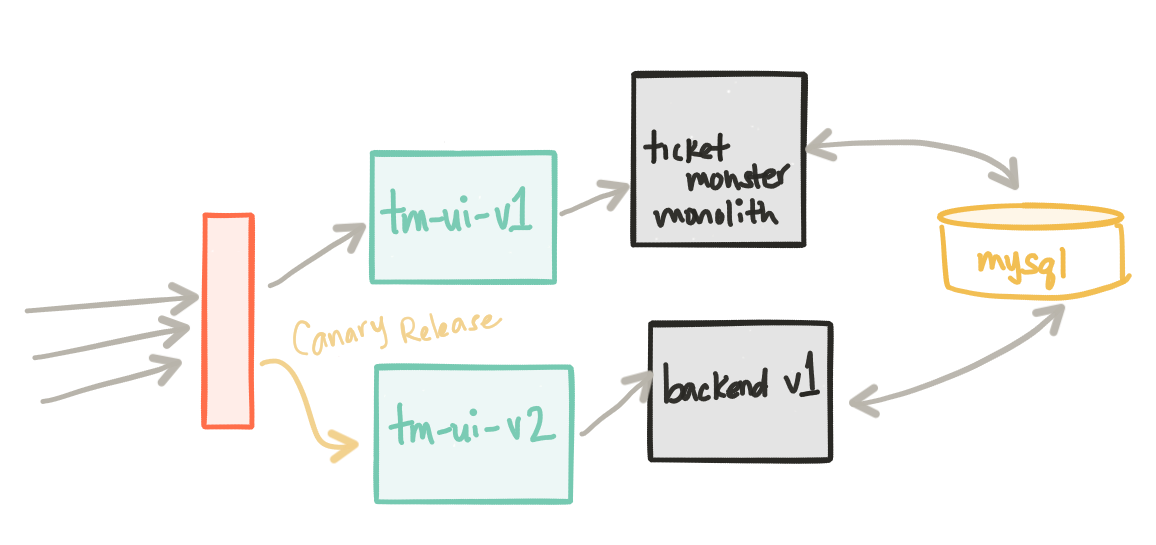
Ввести новый сервис 
Пересмотреть соображения
- Мы хотим сосредоточиться на разработке API / границе нашего извлеченного сервиса
- Это может быть переписать с того, что существует в монолите
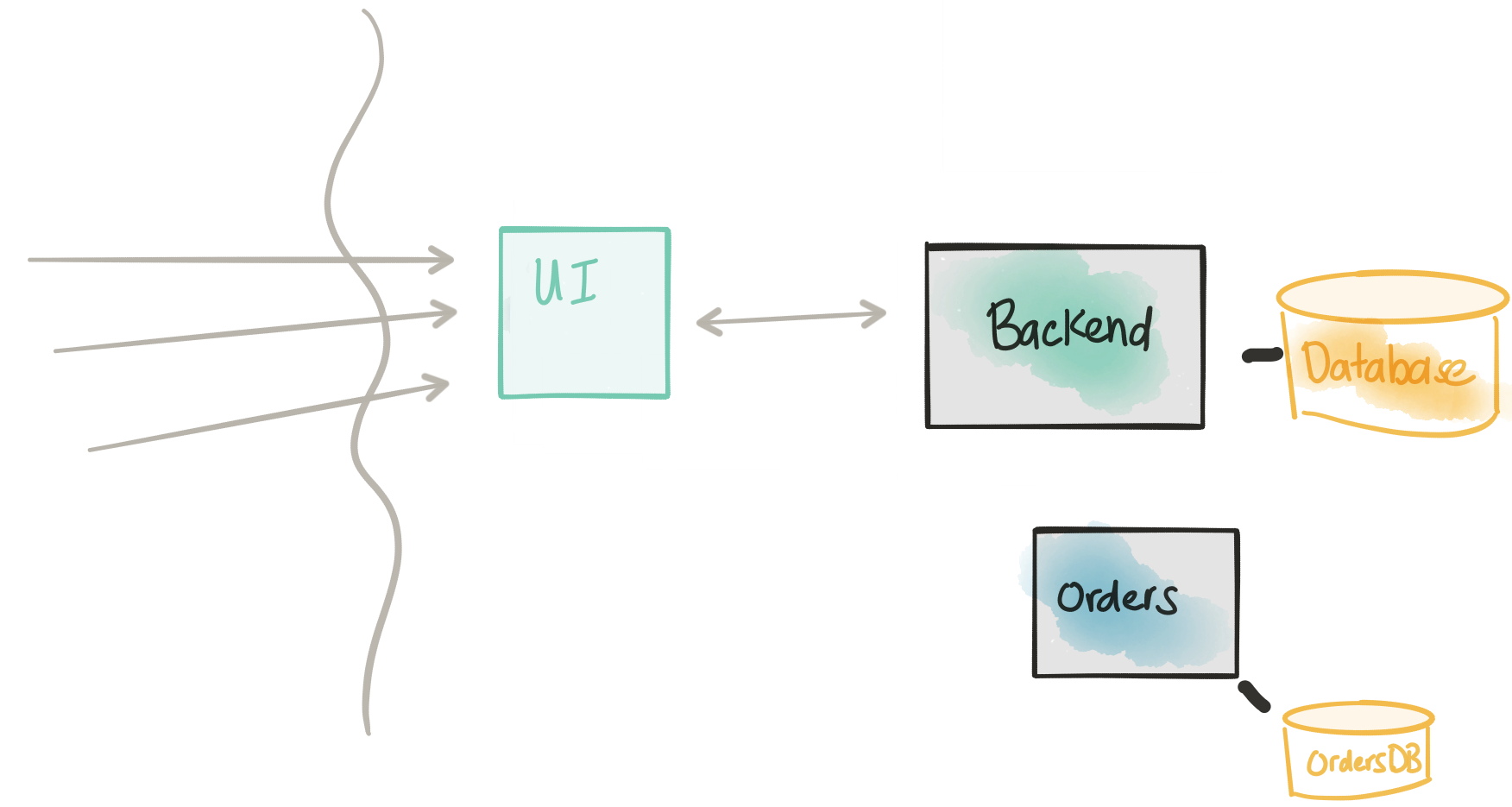
- Как только мы определились с API, мы внедрим простой каркас / заполнитель для сервиса
- Новая служба заказов будет иметь собственную базу данных
- Новая служба заказов не будет принимать никакого трафика в этот момент
На этом этапе мы начинаем разрабатывать API, который мы хотим для новой службы Orders, и это, скорее всего, будет в большей степени соответствовать границам, которые мы определяем с помощью некоторых проектов по управлению доменом. Вместо того чтобы прилагать огромные усилия для создания API-интерфейса заранее, чтобы потом выяснить, что его необходимо постоянно менять, мы можем использовать инструменты моделирования API-интерфейса для разработки API-интерфейса, развертывания его виртуализированной реализации и повторения его с нашими потребителями.
В случае нашего рефакторинга TicketMonster мы можем захотеть сохранить API-интерфейс, аналогичный тому, который есть у нас в монолите, чтобы изначально разложение было максимально безболезненным и с минимальным риском. В любом случае мы можем использовать два замечательных инструмента: веб-дизайнер API apicur.io и инструмент виртуализации тестирования / API Hoverfly . Hoverlfy — отличный инструмент для симуляции API или захвата существующего трафика API, поэтому его можно использовать для симуляции фиктивной конечной точки.
Если мы создаем новый интерфейс API или пытаемся представить, как выглядит наш API после итерации с использованием подхода, основанного на домене, мы можем использовать инструмент apicur.io для создания спецификации Swagger / Open API. 
В случае с TicketMonster мы использовали hoverfly для захвата трафика из нашего приложения в наши бэкэнд-сервисы, запустив hoverfly в режиме proxy и захватив трафик. Мы можем легко установить HTTP-прокси в настройках нашего браузера, чтобы отправлять весь трафик через hoverfly. Это сохраняет моделирование каждой пары запрос / ответ в файле JSON. Отсюда мы используем пары запрос / ответ в фиктивном или даже лучше, используем их, чтобы начать писать тесты, которые кодифицируют поведение, которое мы хотим в нашей реализации.
Для пар запрос / ответ, которые нас интересуют, мы можем создать схему JSON (см. Https://jsonschema.net/#/editor и использовать ее в нашем тесте.
Например, используя комбинацию Rest Assured и Hoverfly, мы можем вызвать наш макет hoverfly и утверждать, что ответы соответствуют нашей ожидаемой схеме JSON:
|
1
2
3
4
|
@Testpublic void testRestEventsSimulation(){ get("/rest/events").then().assertThat().body(matchesJsonSchemaInClasspath("json-schema/rest-events.json"));} |
Оформить заказ на тесты HoverflyTest.java из нового сервиса Orders .
Для получения дополнительной информации о тестировании микросервисов Java обратитесь к этой удивительной книге Мэннинга под названием «Тестирование микросервисов Java» от некоторых моих коллег Алекса Сото Буэно , Джейсона Портера и Энди Гумбрехта .
Поскольку эта запись в блоге уже становится очень длинной, я решил разделить последние части части III, которая касается управления данными между монолитом и микросервисом, тестирования потребительских контрактов и того, как выполнять маркировку функций / более сложную маршрутизацию istio, и т. д. Часть IV этой серии покажет записанную демонстрацию всего этого в действии с тестами моделирования нагрузки и инъекциями неисправностей. Оставайтесь с нами и следите за новостями в твиттере !
| Смотрите оригинальную статью здесь: Монолит с низким уровнем риска для Microservice Evolution Часть II
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |